基于 AI Agent 的童话编剧与绘本生成器(二)——爬虫篇
上一篇文章发表后,组内成员说不用写那么长的代码介绍,建议我只对实现的核心功能进行概括。
一、实现的爬虫脚本
在第4、5周实现了“从公开网页(目前选则 Storyberries)拉取童话/绘本类文本”的爬虫,为后面的「编剧 / 绘本生成」提供语料或参考素材。
在文件头写明了两个目标站点及正文所在 DOM(文档对象模型) 区域。
二、环境与依赖
Python 标准库为主:urllib、argparse、csv、pathlib、re 等,不引入 requests。童话站点多半是服务端渲染或传统 HTML,用 html.parser + CSS 选择器足够;标准库 urllib 降低依赖冲突,和爬虫场景匹配。
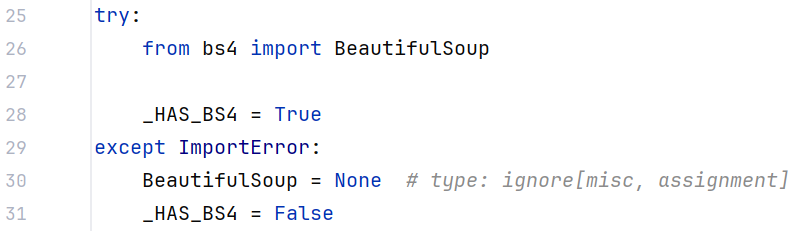
环境依赖:必须安装 BeautifulSoup4:解析 HTML;若未安装,脚本在 main() 里会直接退出并提示 pip install beautifulsoup4。
三、主要模块职责介绍表
| 逻辑区块 | 代表函数/常量 | 职责 |
| 全局配置 | BASE_URL、UA、DEFAULT_CATEGORY_RANGE |
站点根地址、合规 UA、默认分类 ID 范围 |
| HTTP 基础设施 | build_http_opener、http_get、http_get_bytes、decode_body |
代理、重试退避、超时、正文/二进制下载、编码探测 |
| Storynook 链接发现 | normalize_site_url、extract_story_ids_from_html、collect_story_urls |
从首页与 /story/list/{分类}/{页} 收集 /story/{id} |
| Storynook 正文解析 | parse_story_page | 标题 + #storyContent / .article-content 纯文本 |
| Storyberries 列表与正文 | collect_storyberries_story_urls、parse_storyberries_article |
分类翻页、h2.entry-title a、.entry-content 与插图 URL |
| 插图辅助 | _parse_srcset_best、_img_best_url、extension_for_image |
srcset 取最大宽度图、扩展名推断 |
| 运行与 CLI | 运行与 CLI | 探针模式、两站点分支、写 txt + stories_metadata.csv |
四、HTTP 层:单独写 http_get 和 decode_body
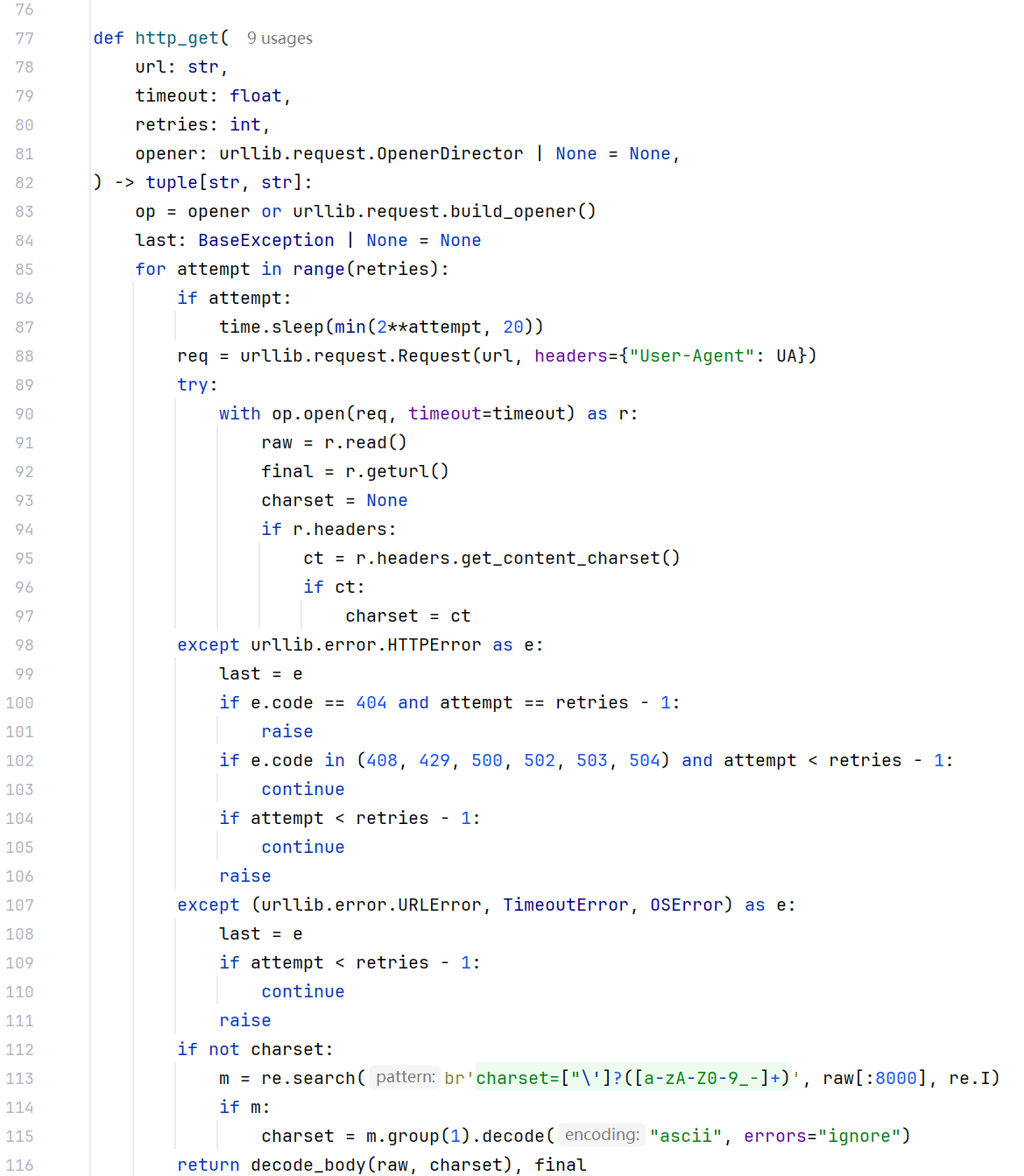
1. 编码
网页 charset 可能不准或缺失。decode_body 先信响应头/提示,再依次尝试 utf-8、gbk、utf-8-sig,最后用 replace 兜底,避免中文乱码或整段解析失败。
2. 重试与退避
对 408/429/5xx 和部分网络错误做有限次重试,间隔 min(2**attempt, 20),减轻对目标站压力,也提高弱网下的成功率。
3. 用户提示print_timeout_hint 在超时类错误时打印可操作提示。
五、Storynook:从「发现 URL」到「存 txt」
1. URL 发现策略
- 先抓首页,用正则 +
normalize_site_url收集形如/story/数字的链接(排除列表页等)。 - 若未加
--no-list-crawl,再按分类 ID 区间遍历列表页;若连续两页没有新 ID 则提前停止,避免无意义翻页。
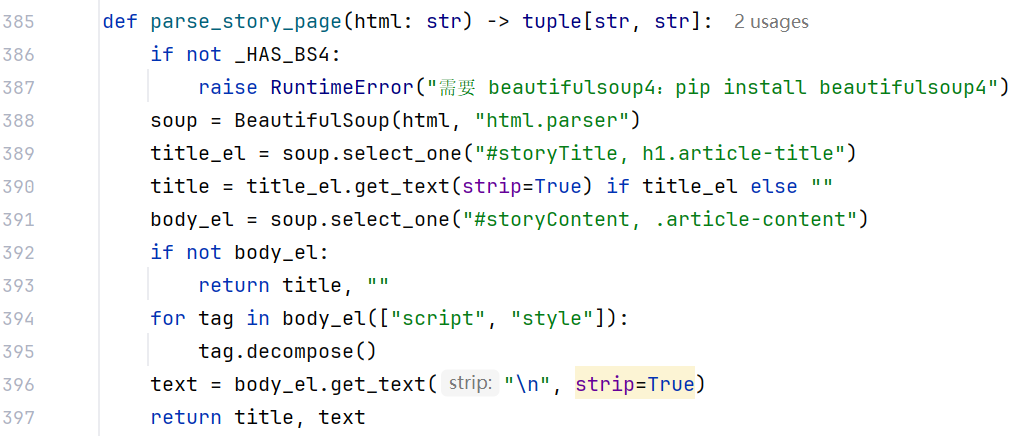
2. 正文解析
标题:#storyTitle 或 h1.article-title;正文:#storyContent 或 .article-content;去掉 script/style 后 get_text("\n", strip=True),得到适合后续 NLP 或 Agent 的纯文本段落。
3. 落盘与元数据
每篇一个 {序号}_{标题}.txt,根目录下 stories_metadata.csv(UTF-8-SIG 方便 Excel),字段含 title、url、text_chars、local_txt 等;失败时 status 记录 fetch_error / parse_error / text_too_short,便于批量跑完后统计质量。
六、Storyberries:绘本站点的额外复杂度(插图)
1. 列表页
WordPress 分类支持 /page/N/;用 h2.entry-title a[href] 收集文章链接,并规范到 www.storyberries.com,避免重复。
2. 正文与图
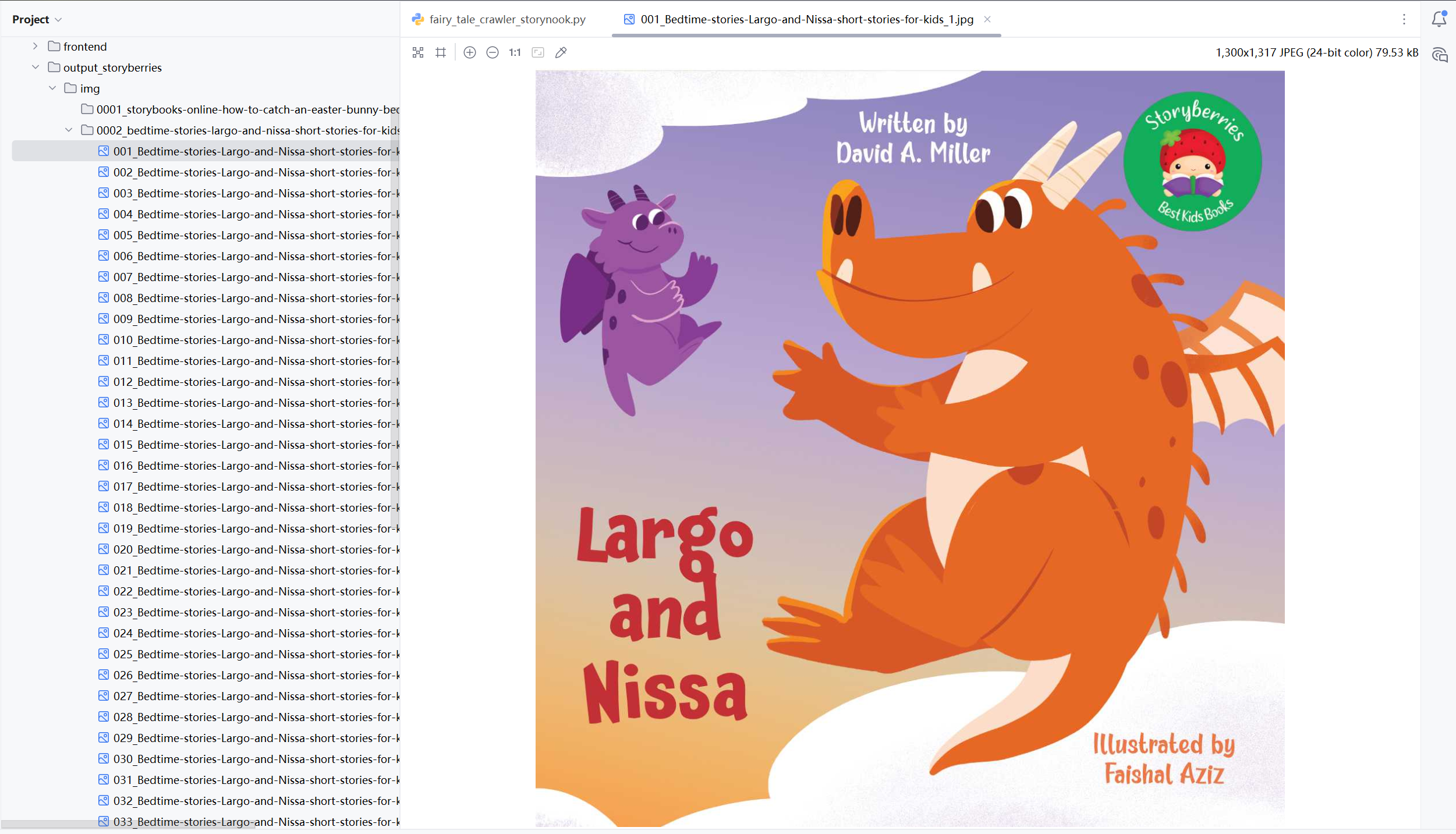
正文仍在 .entry-content;插图从 img 上取 URL,优先解析 srcset 里宽度最大的候选(现代站点常用响应式多图),再回退 data-src / src;过滤 gravatar、/emoji/ 等非内容图。
3. 可选下载--no-images 时只存文本;否则按篇建子目录,用 http_get_bytes 写文件,扩展名由 URL 或 Content-Type 推断。
七、当前成果总结
- 双站点统一 CLI;Storynook 爬取“短篇文本语料”,Storyberries爬取“带图绘本页”。
- 重试、延迟、代理、探针模式齐全。
爬取效果大致如下。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)