给大模型套上缰绳:从 Prompt 到 Harness,彻底搞懂 AI Agent
一、LLM 大语言模型
-
本质:大模型本质上是一个磁盘上的超大参数文件
-
不同产品形态:
-
将参数文件加载到显卡内存 + HTTP 接口 → 大模型 API 服务
-
加上聊天界面 → 聊天 AI(如 ChatGPT、Claude)
-
加上代码编辑器 → AI IDE(如 Cursor、Claude Code)
-
-
工作原理:基于当前输入的内容,预测下一个字词大概率是什么。本质上是在"猜"你想要什么——如果指令太宽泛,预测的答案就会非常发散
二、Function Calling
-
定义:Agent 和大模型之间沟通的约定
-
目的:让大模型的回答符合一定的格式,方便程序解析和处理
-
作用:使大模型能够"调用函数",将自然语言指令转化为结构化的函数调用
三、MCP(Model Context Protocol,模型上下文协议)
-
定义:Agent 和工具服务之间调用的约定
-
目的:像接口文档一样约定:
-
怎么调用工具
-
怎么传参
-
怎么接收返回值
-
-
意义:提供标准化的工具集成方式,让 Agent 可以无缝对接各种外部服务和插件
四、LangChain
-
定义:纯编程的形式来实现 Agent 流程
-
特点:
-
全部是硬编码,流程固定
-
优点:特别稳定,行为可预期
-
缺点:很难包容一些小问题,缺乏灵活性
-
五、Workflow(工作流)
-
定义:将 LangChain 的程序控制流程替换为低代码的拖拽形式
-
特点:
-
可视化编排
-
流程仍然是预先定义好的
-
实质上与 LangChain 一样,只是实现方式不同(低代码 vs 纯代码)
-
六、Skill(技能)
-
定义:把 LangChain 和 Workflow 这种由程序控制的流程走向,变成由智能体自行控制
-
实现方式:提前写好说明文档和可直接运行的脚本
-
特点:
-
存在一定的灵活调整空间
-
同时又不至于变得特别不可控
-
规定了在什么场景下、按什么顺序、组合使用哪些工具(MCP 插件、本地 Script 脚本)
-
七、Agent(智能体)
-
定义:可以随时根据自己的判断进行流程调整的程序
-
本质:Agent 就是一个 for 循环——思考 → 行动 → 观察 → 再思考...
-
这套"一边思考一边行动"的循环,就是所谓的 ReAct(Reasoning + Acting)
-
大模型越强,Agent 外壳就可以做得越薄
-
-
公式:Agent = 大模型 + Harness(驾驭工程)
-
特点:
-
灵活性最高
-
但也会因此变得不可控
-
循环一长,上下文一定会膨胀,即使上下文工程做得再好也可能会腐化
-
八、Prompt Engineering(提示词工程)
什么是提示词工程?
-
有意识地调整和设计提示词,让模型稳定地朝着你预期的内容和格式输出的技术手段
-
它解决的是大模型"无引导、乱说话"的问题
为什么需要提示词工程?
-
大模型本质上是"猜"下一个词,如果输入太宽泛,输出就会非常发散
-
通过精心设计的提示词,可以约束模型的行为,获得更精准的结果
九、Context Engineering(上下文工程)
什么是上下文?
-
打包到一起发给大模型的所有信息都叫"上下文"
-
提示词只是上下文的一部分
上下文窗口(Context Window)
-
大模型一次性能处理的上下文有最大限制,这个限制叫"上下文窗口"
上下文腐化(Context Corruption)
-
随着对话轮次增多,上下文窗口很容易被打满
-
需要通过一些策略去压缩或丢弃部分信息
-
在这个过程中,不可避免地会丢失关键信息,破坏上下文的完整性和准确性
-
表现:模型开始记不住、回答前后不一致
上下文工程要解决的问题
怎么才能在合适的时候,将合适的内容,塞入到有限的上下文中?
上下文工程的三个步骤
| 步骤 | 含义 | 涉及技术 |
|---|---|---|
| 召回 | 获得什么信息 | RAG、Memory 等 |
| 压缩 | 让信息变小 | 如将信息分开发给大模型做总结 |
| 组装 | 调整信息的位置和顺序 | 信息放置位置和顺序直接影响模型理解和输出(越靠后越容易被关注) |
总结
-
提示词是上下文的一部分 → 提示词工程也是上下文工程的一部分
-
上下文工程一般通过外部程序实现(如 Cursor、Claude Code、Trae 等 Coding Agent)
十、Harness Engineering(驾驭工程)
定义
一套包裹着大模型的工程外壳,让 Agent 能够持续、稳定、按规范执行任务并最终交付
四大核心层
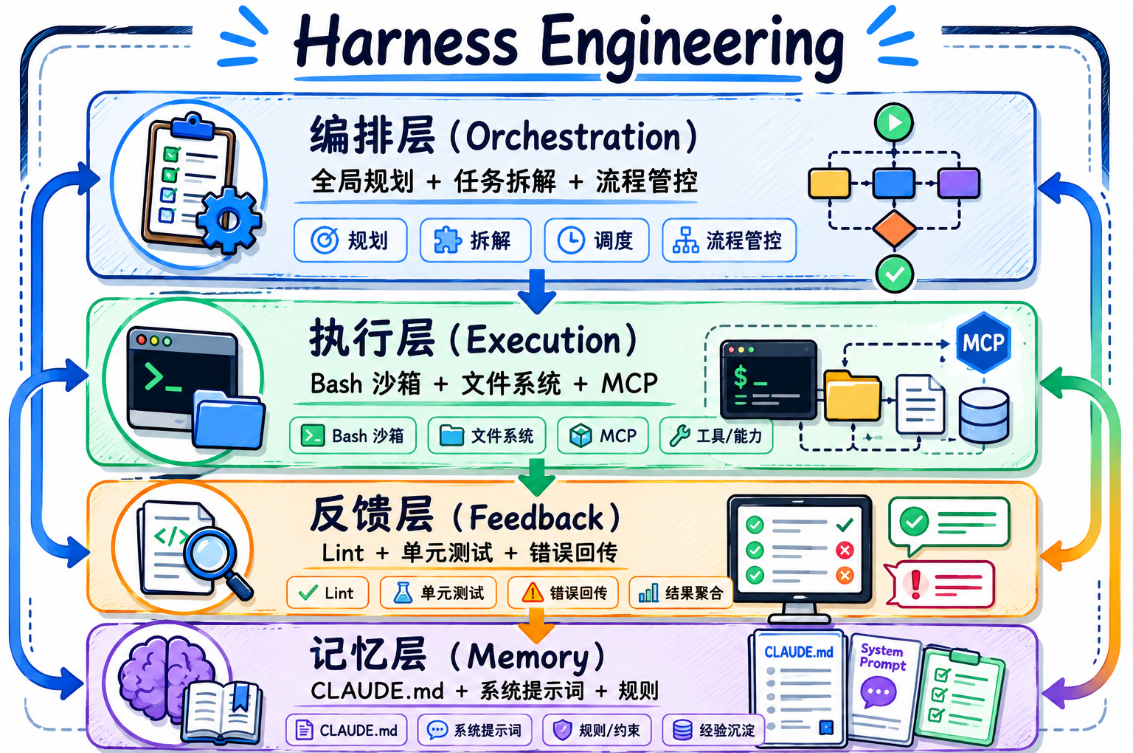
1. 记忆层(Memory Layer)
-
问题:随着 Agent 看过的文件越来越多,拿到的信息越来越杂,前面约定好的目标和约束后面可能慢慢被冲淡,理解越来越偏
-
解决方案:保证每次给大模型的上下文中,都包含一些可复用的核心信息
-
实现:
-
核心信息单独写成文件,固定在代码仓库里(如
CLAUDE.md) -
这些文件在调用大模型时,作为系统提示词自动注入上下文
-
与提示词工程和上下文工程配合,形成记忆层
-
2. 执行层(Execution Layer)
-
给大模型加上 Bash 沙箱(安全隔离的命令执行环境)、文件系统、MCP 等能力
-
让大模型能像人一样操作外部工具、读写代码文件、执行命令做测试
3. 反馈层(Feedback Layer)
-
Agent 写代码 → 跑 Lint(静态代码分析)和单元测试 → 将测试输出和报错加入上下文 → 驱动 Agent 在下一轮循环中自动修复
-
这套"通过校验结果回传错误来实现自动修复"的能力,形成了反馈层
4. 编排层(Orchestration Layer)
-
问题:Agent 的循环如果缺乏全局规划和清晰的结束目标,很容易跑偏,甚至陷入无效死循环
-
解决方案:将大任务拆解为具有明确执行标准的多个子任务
-
以全局规划为核心,对任务做拆解与全流程管控,形成编排层
核心认知
Agent = 大模型 + Harness 只要不是大模型的那部分,都属于 Harness Engineering 的范畴 大模型越强,外壳就可以做得越薄——但无论怎么样,这层外壳都得有
十一、Harness Engineering 如何落地?
方式一:轻量级——直接写 CLAUDE.md
Claude Code 等工具本身已原生支持 Harness 的四层能力,只需在 CLAUDE.md 文件中写清楚:
-
项目背景是什么
-
你希望大模型做什么
-
别做什么
-
做完之后要跑哪些 Lint、单测和 CI
-
执行哪些 Skill
方式二:插件扩展——Spec-Driven Development(SDD)
-
引入插件(如 spec-kit 等扩展),根据项目将需求拆成多个阶段
-
每个阶段都可能会更新一次
CLAUDE.md -
这样,每一阶段注入上下文的,尽可能都是核心信息
-
本质上做的事情就是 Harness Engineering 的落地
十二、总结:三层工程的关系
| 工程层级 | 解决什么问题 | 核心目标 |
|---|---|---|
| 提示词工程 | 大模型无引导、乱说话 | 让大模型明白你的具体需求和输出标准 |
| 上下文工程 | 上下文腐化、信息丢失 | 给大模型注入精准有效的上下文 |
| 驾驭工程 | Agent 跑偏、死循环、不可控 | 让大模型持续按规范执行任务并最终交付 |
三者关系:
-
提示词工程 ⊂ 上下文工程(提示词是上下文的一部分)
-
上下文工程 ⊂ 驾驭工程(上下文管理是记忆层的核心手段)
-
Harness Engineering 是所有非模型部分的总称,覆盖编排、执行、反馈、记忆四大层
核心理念:大模型本身只是"预测下一个词"的概率引擎。从让它能稳定输出(提示词工程),到让它在有限的上下文中保持精准(上下文工程),再到让它能自主完成复杂任务(驾驭工程)——每一步都是在给这个概率引擎套上越来越完整的外壳,使其从"会聊天"变成"能干活"
十三、知识概览图


这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)