【清华代码熊】DeepSeek OCR V2 开源|技术报告&代码解析!
·
📌 25年10月份的时候我们介绍过 DeepSeek OCR V1,时隔三个月官方又放出 V2 版本,相比于 V1,核心改进在于:
🌟 使用自回归架构的 LM Vision Encoder 替代主流 CLIP-ViT,通过语义重排序(而非空间位置编码)使视觉特征更适配LLM的单向解码模式。
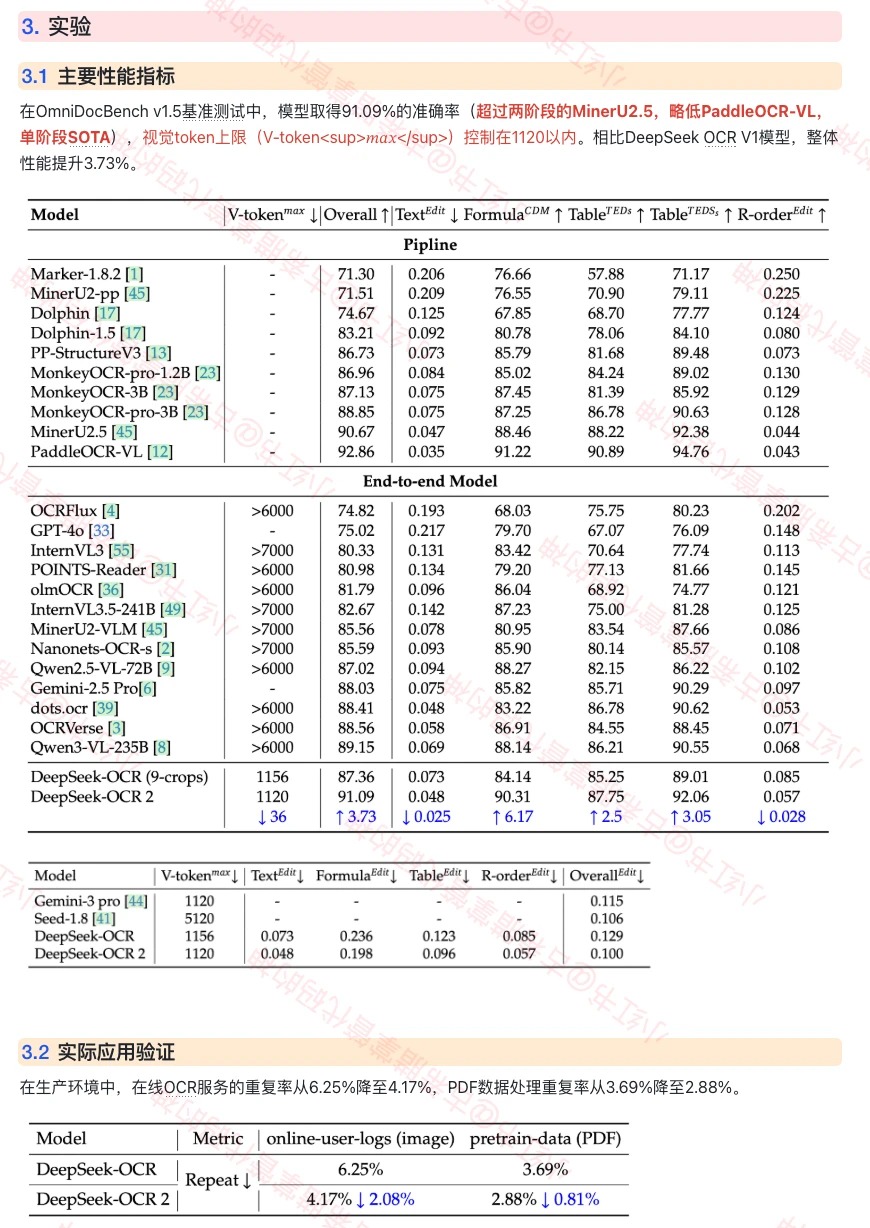
🌟 在OmniDocBench v1.5上,模型表现超过两阶段的 MinerU2.5,略差于两阶段的PaddleOCR-VL,对比单阶段Baselines达到SOTA。







这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)