大模型部署新趋势:从 Ollama 到 vLLM 的必然之路
【大模型框架选择指南:Ollama与vLLM深度对比】 本文详细对比了两种主流LLM框架的核心差异与应用场景: 核心定位 Ollama:轻量级本地工具,适合快速原型开发与隐私敏感场景 vLLM:高性能推理引擎,专为生产级高吞吐量场景优化 关键差异 • 性能:vLLM的PagedAttention技术将内存浪费控制在4%以下,吞吐量可达Ollama的3.23倍 • 扩展性:vLLM支持多GPU并行,
大型语言模型(LLMs)正在改变我们与技术的互动方式,从聊天机器人到代码助手,功能无所不包。但要高效运行这些模型可不是件小事,尤其是在需要速度、可扩展性和高吞吐量应用的稳定性时。如果你一直在用Ollama进行本地LLM实验,现在想转向vLLM以获得生产级性能,这篇文章的主要目的是讲解这两个框架的区别,探讨选择正确框架的重要性,并提供一步步的指导。
1. 为什么选择合适的LLM框架很重要
把部署LLM想象成开餐厅。如果只是给小家庭做晚餐,家里厨房的基本工具(比如Ollama)就够用了。但如果是为500人的婚礼提供餐饮,你得用工业级设备(比如vLLM)来应对需求,不然就得累垮了。选错LLM应用的框架可能导致:
-
• 响应慢:用户等太久才能得到聊天机器人回复或代码补全,体验很差。
-
• 成本高:GPU内存使用效率低,导致云计算账单飙升。
-
• 系统崩溃:框架无法承受高流量,导致宕机。
-
• 安全风险:敏感环境下因配置不当导致数据泄露。
选对框架能确保你的LLM应用快速、成本效益高、可扩展且安全。Ollama适合本地测试、原型开发和注重隐私的项目,而vLLM专为高吞吐量、生产级环境设计。了解它们的优势能帮你选出最适合的工具。
2. vLLM和Ollama是什么?基础知识了解一下
Ollama:新手友好的LLM运行工具
Ollama就像你手机上的一个简单易用的app,直观、设置简单。它是一个开源工具,旨在让在本地运行LLM变得尽可能简单,不管你用的是MacBook、Windows PC还是Linux服务器。
核心功能:
-
• 跨平台:支持macOS、Windows和Linux。
-
• CLI和REST API:提供简单的命令行工具和与OpenAI兼容的API,方便集成。
-
• 模型库:支持Llama 3、Mistral、Gemma等热门模型,可通过注册表下载。
-
• 硬件支持:支持CPU、NVIDIA GPU和Apple Silicon(Metal)。
-
• 注重隐私:数据保存在本地,适合医疗或研究等敏感应用。
使用场景:开发者在笔记本上开发聊天机器人原型,或研究者在离线环境下分析私有数据集。
vLLM:高性能推理引擎
vLLM就像一辆赛车,为高要求环境下的速度和效率而生。由UC Berkeley的Sky Computing Lab开发,vLLM是一个开源库,专为高吞吐量LLM推理优化,特别适合NVIDIA GPU。
核心功能:
-
• PagedAttention:一种内存管理技术,将GPU内存浪费降到4%以下。
-
• Continuous Batching:动态处理请求,最大化GPU利用率。
-
• 可扩展性:支持多GPU设置和跨服务器分布式推理。
-
• OpenAI兼容API:无缝集成现有工具和工作流。
-
• GPU中心化:为NVIDIA GPU和CUDA优化,CPU支持有限。
使用场景:企业部署客服聊天机器人,实时处理每分钟数千条查询。
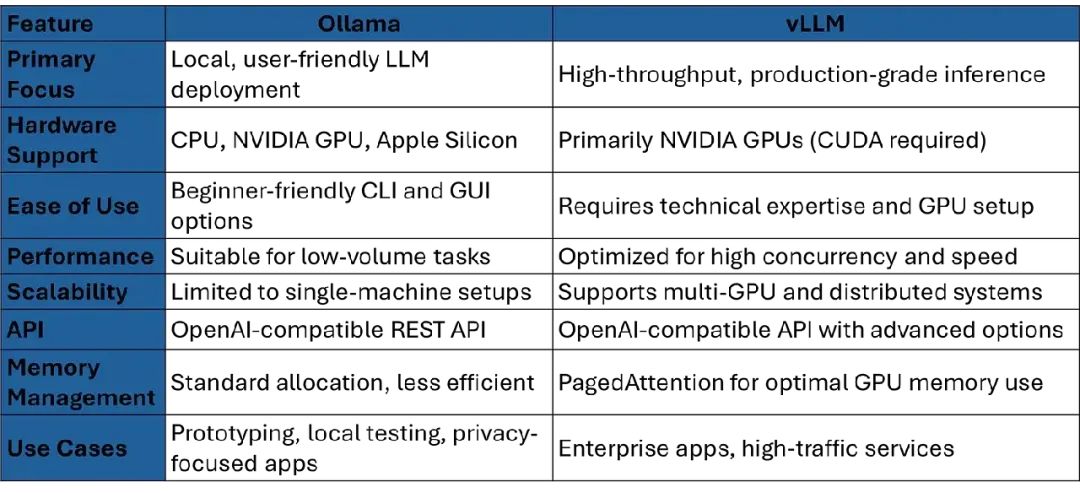
3. vLLM和Ollama的区别
要选择vLLM还是Ollama,你得搞清楚它们的核心差异。以下是详细对比:
类比
-
• Ollama:像自行车,简单好用,适合短途,但不适合高速路。
-
• vLLM:像跑车,速度快、动力强,但需要熟练的司机和好的路(GPU基础设施)。
4. 性能:速度、内存和可扩展性
在性能上,vLLM和Ollama差别很大。我们来分解它们在速度、内存使用和可扩展性上的差异,并举例说明。
速度
-
• Ollama:在消费级硬件上运行小型模型(比如7B参数)性能不错。比如,在16GB RAM的MacBook上运行Mistral 7B,单用户约7 token/秒。
-
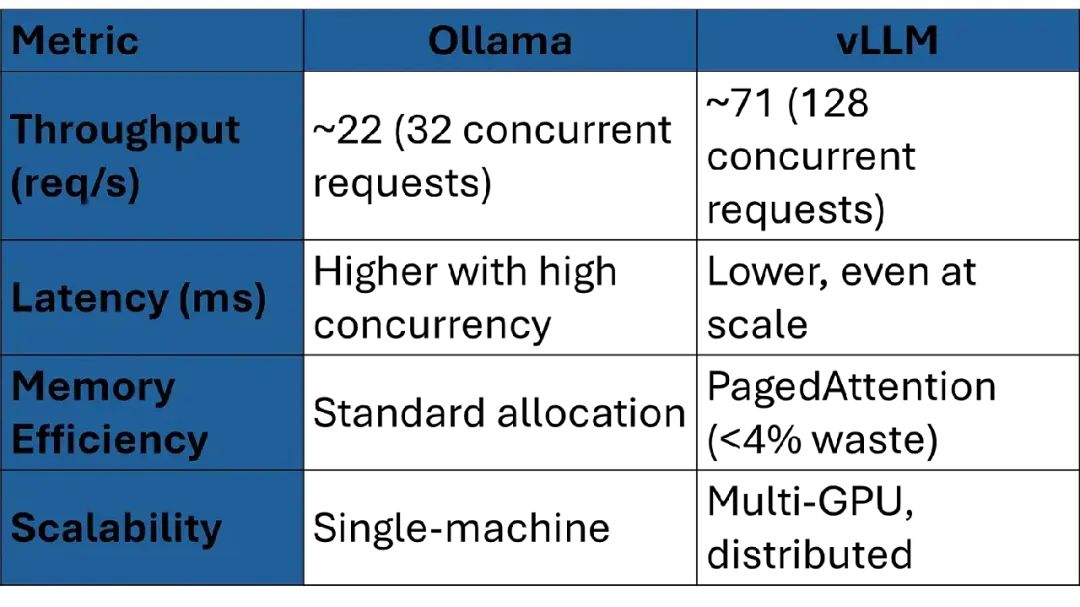
• vLLM:在高吞吐量场景中表现卓越。基准测试显示,vLLM在128个并发请求下比Ollama快3.23倍,在NVIDIA A100 GPU系统上达到约71请求/秒。
例子:假设你建一个聊天机器人,回复“写一首短诗”。用Ollama,单用户可能要2-3秒得到回复。而vLLM通过continuous batching并行处理请求,多个用户同时查询也能在1秒内得到回复。
内存
-
• Ollama:使用标准内存分配,对大模型效率较低。13B模型至少需要16GB RAM或GPU内存,每个序列完全分配内存,限制并发。
-
• vLLM:使用PagedAttention,将key/value缓存分成小块,内存浪费降到4%以下。这让vLLM能在相同硬件上处理更大模型或更多并发请求。
例子:在NVIDIA A100 GPU上运行Llama 3 8B,vLLM因动态内存分配能处理更多并发请求,而Ollama为每个请求预留整块内存,限制吞吐量。
可扩展性
-
• Ollama:适合单机设置,高并发时(比如超过32个同时请求)延迟增加,吞吐量无提升。
-
• vLLM:专为可扩展性设计,支持tensor parallelism(模型权重分布在多个GPU上)和pipeline parallelism(计算阶段分布)。适合多GPU云虚拟机。
例子:一个初创公司用单GPU服务器运行Ollama,服务小团队内部工具。而一家处理百万用户的科技公司用vLLM在多GPU上每分钟处理数千请求。
性能对比表:
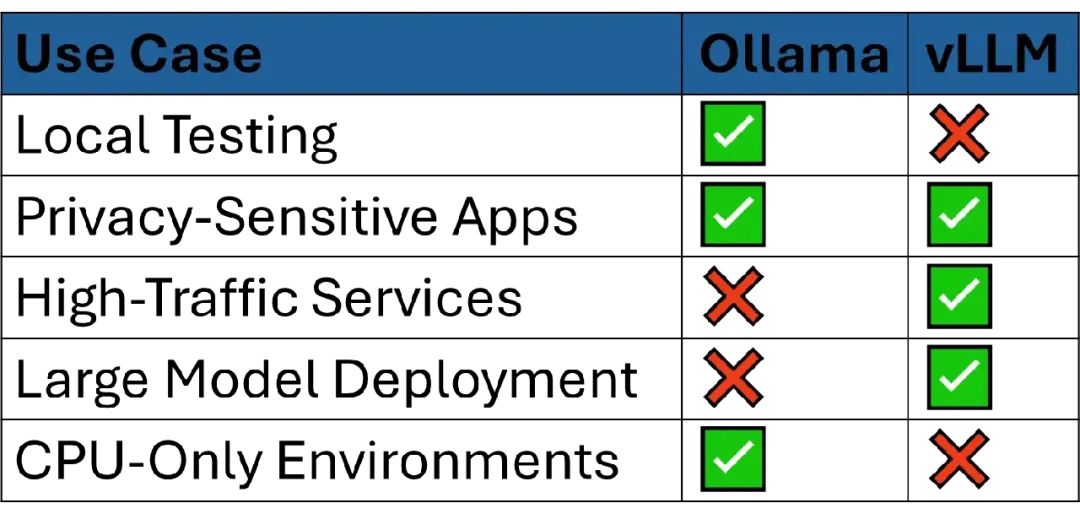
5. 使用场景:什么时候用vLLM,什么时候用Ollama
什么时候用Ollama
-
• 原型开发:在笔记本上测试新聊天机器人或代码助手。
-
• 隐私敏感应用:在隔离环境(比如政府、医疗或法律)运行模型。
-
• 低流量工作负载:小型团队或个人项目,少量用户。
-
• 资源受限硬件:在没有CUDA的CPU或低端GPU上运行。
例子:学生用Ollama在MacBook上运行Llama 3做研究项目,保持敏感数据离线。
什么时候用vLLM
-
• 高流量服务:聊天机器人或API同时服务数千用户。
-
• 大型模型:部署像DeepSeek-Coder-V2(236B参数)这样的大模型,跨多GPU。
-
• 生产环境:需要低延迟和高吞吐量的应用。
-
• 可扩展部署:多NVIDIA GPU的云设置。
例子:公司用vLLM在8个A100 GPU的云虚拟机上建实时翻译服务,每分钟处理数千次翻译。
使用场景决策矩阵:
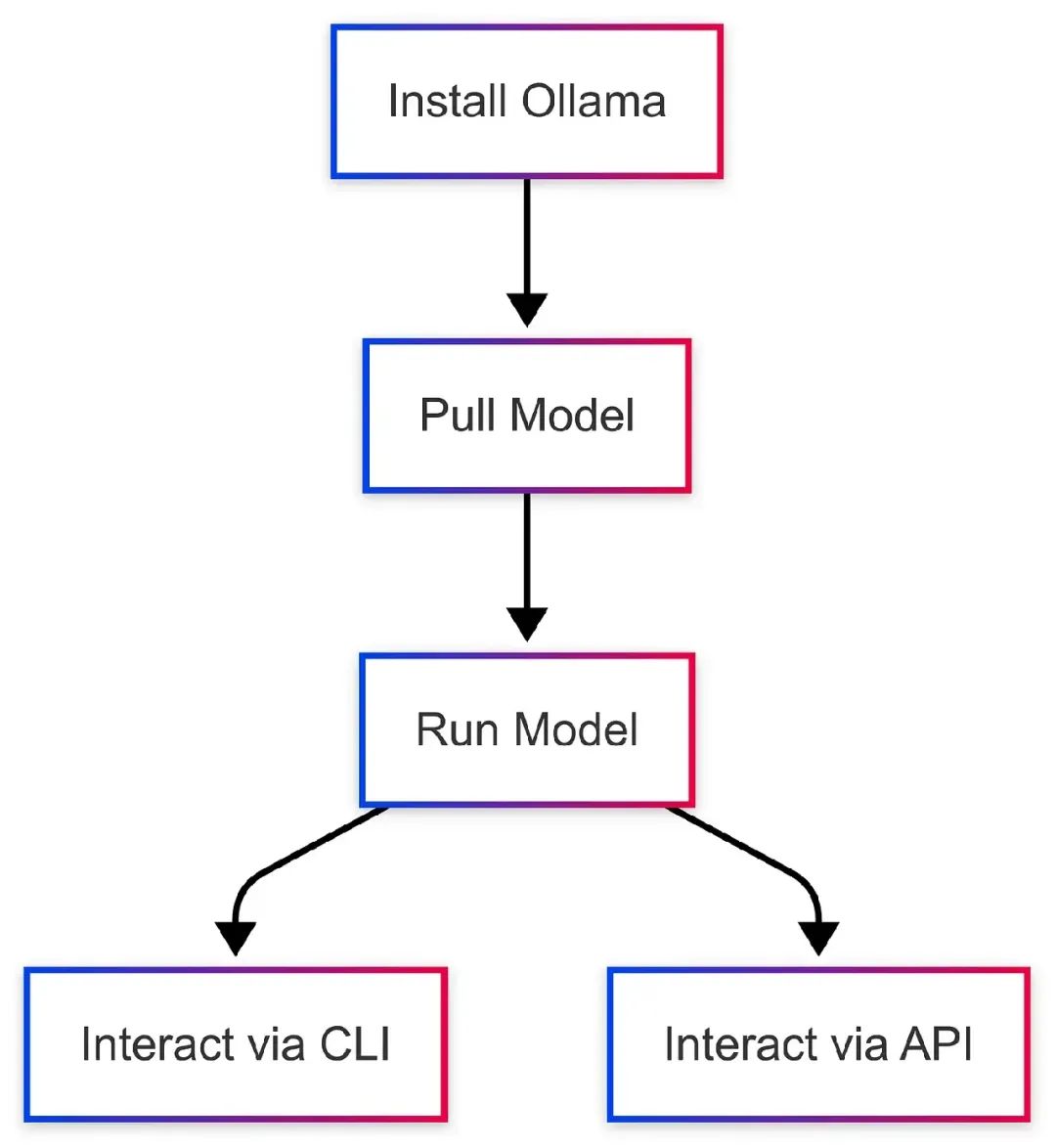
6. 开始使用Ollama:一步步指南
我们来在本地机器上设置Ollama运行Mistral 7B。假设你从零开始。
步骤1:安装Ollama
-
• 下载:访问Ollama官网,下载适用于你的操作系统的安装程序(macOS、Windows或Linux)。
- • 安装:运行安装程序。对于Linux,使用:
输出:Ollama安装完成,准备使用。curl -fsSL https://ollama.ai/install.sh | sh
步骤2:拉取模型
下载Mistral 7B:
ollama pull mistral:7b输出:模型(4GB)下载并存储在/.ollama/models。
步骤3:运行模型
启动模型:
ollama run mistral:7b输出:打开交互式提示。输入:
讲个笑话。回复:
为什么稻草人成了励志演讲家?因为他在自己的领域里太出色了!步骤4:使用REST API
Ollama提供与OpenAI兼容的API,方便集成。以下是Python示例:
import requests
response = requests.post("http://localhost:11434/api/generate", json={
"model": "mistral",
"prompt": "讲个笑话"
})
print(response.json()['response'])输出:
为什么程序员不用暗黑模式?因为亮色模式会吸引bug。步骤5:验证设置
检查运行中的模型:
ollama ps输出:
NAME ID SIZE PROCESS PORT
mistral:7b abc123 4.1 GB running 11434工作流图表:
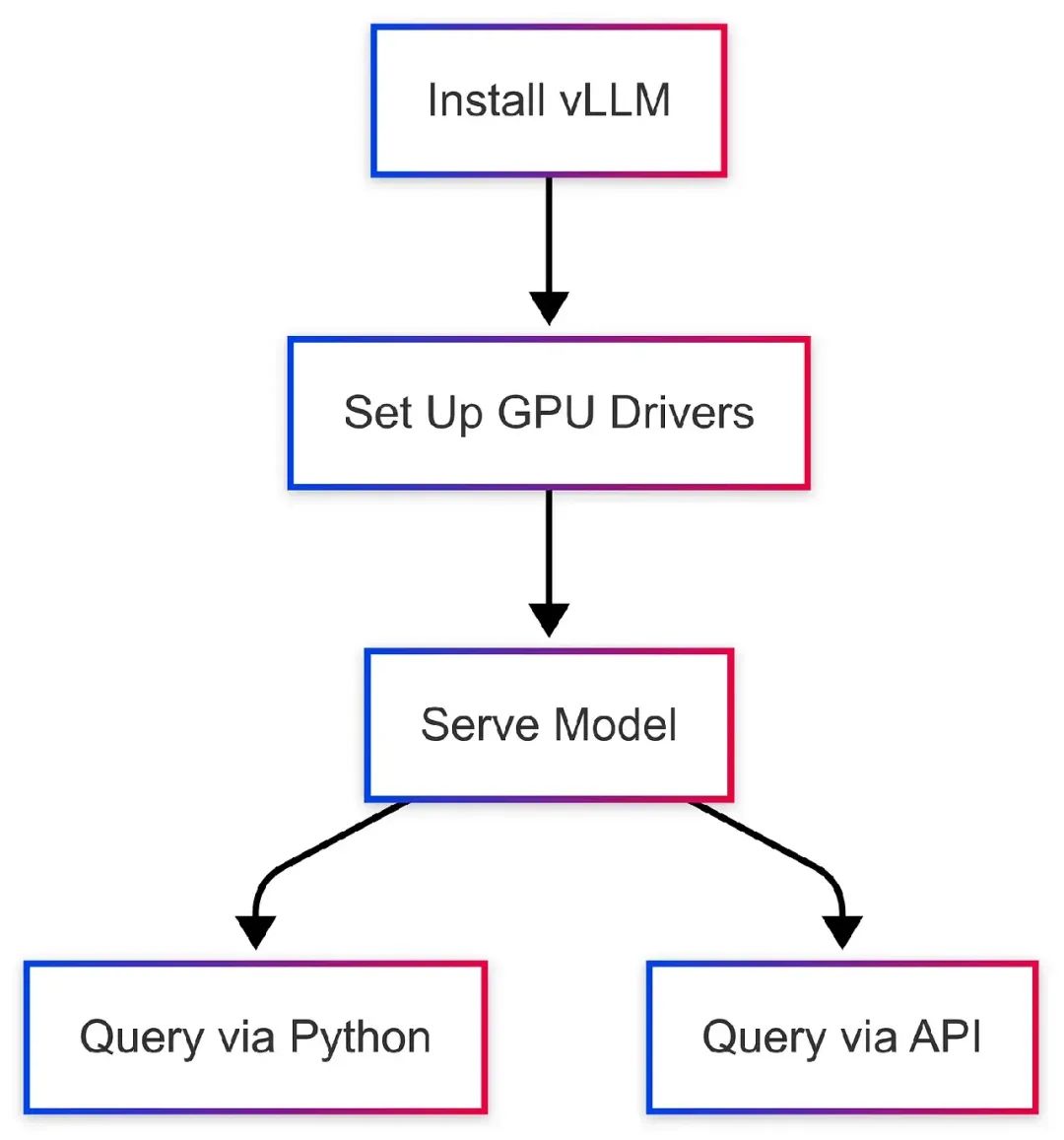
7. 开始使用vLLM:一步步指南
vLLM需要更多设置,但在GPU支持的系统上性能更优。我们来运行Llama 3 8B。
步骤1:准备工作
-
• 硬件:NVIDIA GPU支持CUDA(比如A100、RTX 4090)。
-
• 软件:Python 3.8+、NVIDIA驱动、CUDA 11.8+和pip。
步骤2:安装vLLM
通过pip安装vLLM:
pip install vllm输出:vLLM及依赖(如PyTorch、transformers)安装完成。
步骤3:运行模型
服务Llama 3 8B:
vllm serve meta-llama/Llama-3-8b --gpu-memory-utilization 0.9输出:服务器启动,地址为http://localhost:8000。
步骤4:查询模型
用Python与vLLM交互:
from vllm import LLM
llm = LLM(model="meta-llama/Llama-3-8b")
output = llm.generate("vLLM是什么?")
print(output)输出:
vLLM是一个开源库,用于高效LLM推理,通过PagedAttention优化GPU内存,continuous batching实现高吞吐量。步骤5:测试API
使用curl查询OpenAI兼容API:
curl -X POST http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-3-8b", "prompt": "你好,世界!", "max_tokens": 50}'输出:
{
"choices": [
{
"text": "你好!今天我能帮你什么?世界充满可能性,我们一起探索吧!"
}
]
}工作流图表:
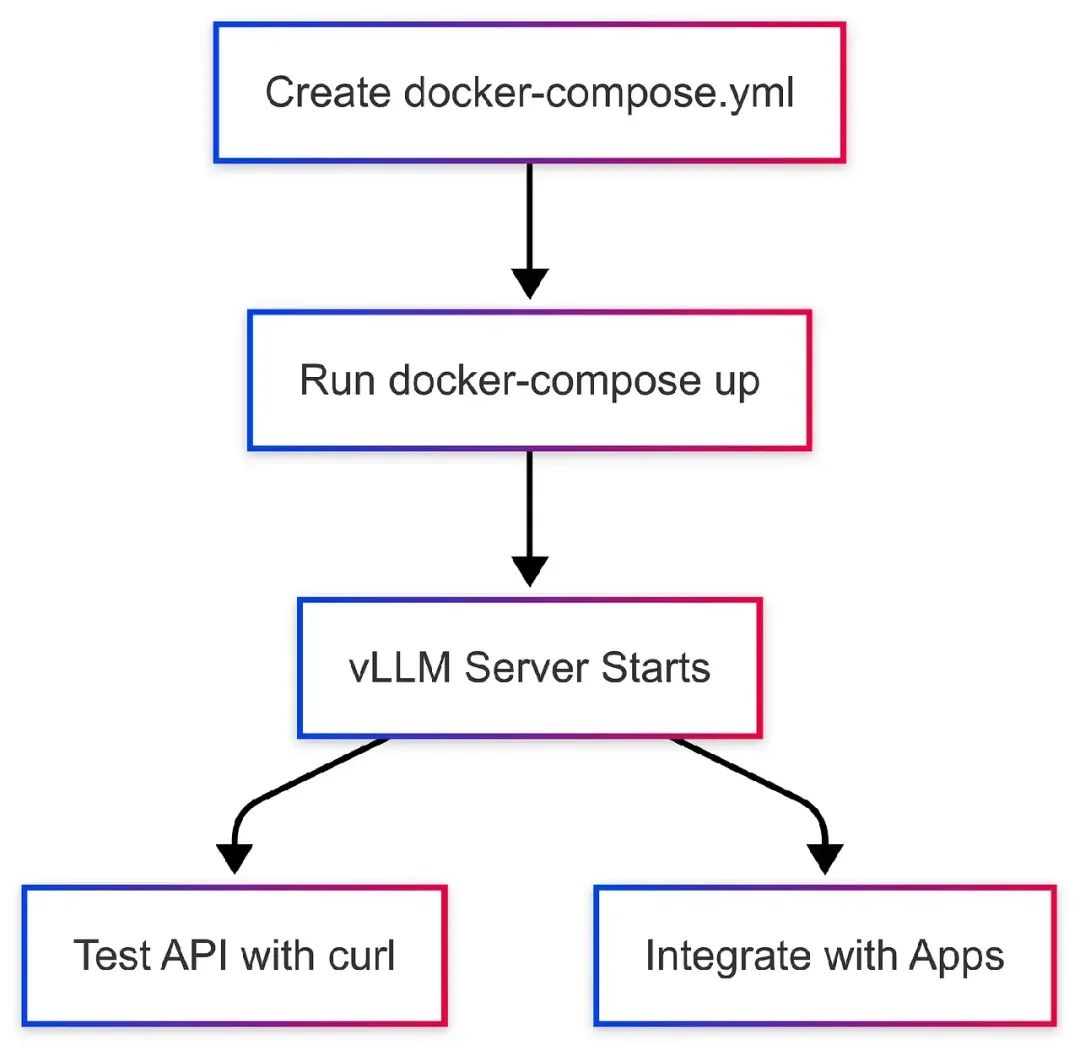
8. 使用Docker Compose设置vLLM
Docker Compose能简化vLLM的生产部署。以下是设置方法。
步骤1:创建Docker Compose文件
创建docker-compose.yml:
version: '3.8'
services:
vllm:
image:vllm/vllm-openai:latest
deploy:
resources:
reservations:
devices:
-driver:nvidia
count:1
capabilities: [gpu]
ports:
-"8000:8000"
environment:
-MODEL_NAME=meta-llama/Llama-3-8b
-GPU_MEMORY_UTILIZATION=0.9
volumes:
- ./models:/models步骤2:运行Docker Compose
docker-compose up -d输出:vLLM服务器在分离模式下启动,可通过http://localhost:8000访问。
步骤3:测试API
curl -X POST http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-3-8b", "prompt": "Docker是什么?", "max_tokens": 50}'输出:
{
"choices": [
{
"text": "Docker是一个容器化平台,让应用在不同环境中以隔离依赖的方式一致运行。"
}
]
}步骤4:监控容器
检查容器状态:
docker-compose ps输出:
Name Command State Ports
vllm_vllm_1 /usr/bin/vllm serve ... Up 0.0.0.0:8000->8000/tcpDocker Compose工作流图表:
9. 处理故障和调整
部署LLM可能会遇到问题。以下是Ollama和vLLM的常见问题及解决方法。
Ollama故障
- • 内存不足:在<16GB RAM系统上运行13B模型会导致崩溃。
解决:使用更小模型(比如7B)或启用交换空间:sudo fallocate -l 8G /swapfile sudo chmod 600 /swapfile sudo mkswap /swapfile sudo swapon /swapfile -
• GPU不兼容:老旧GPU可能不支持Ollama的CUDA要求。
解决:切换到CPU模式(OLLAMA_NO_GPU=1 ollama run mistral)或升级硬件。 -
• 模型下载问题:网络慢或服务器超时。
解决:重试ollama pull mistral或换其他模型。
vLLM故障
-
• CUDA错误:缺少或不兼容的NVIDIA驱动。
解决:用nvidia-smi检查驱动版本(确保CUDA 11.8+)。从NVIDIA官网更新驱动。 -
• 高内存使用:大模型耗尽GPU内存。
解决:降低--gpu-memory-utilization(比如0.8)或使用quantization(见第12节)。 -
• API超时:高并发压垮服务器。
解决:增加批次大小(--max-num-batched-tokens 4096)或添加更多GPU。
示例修复:如果vLLM因CUDA错误崩溃,验证驱动:
nvidia-smi输出:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.60.13 Driver Version: 525.60.13 CUDA Version: 12.0 |
|-----------------------------------------------------------------------------|
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 NVIDIA A100 40GB Off | 00000000:00:04.0 Off | 0 |
| N/A 35C P0 43W / 300W | 0MiB / 40536MiB | 0% Default |
+-----------------------------------------------------------------------------+10. 多GPU内存共享 vs. NGINX负载均衡
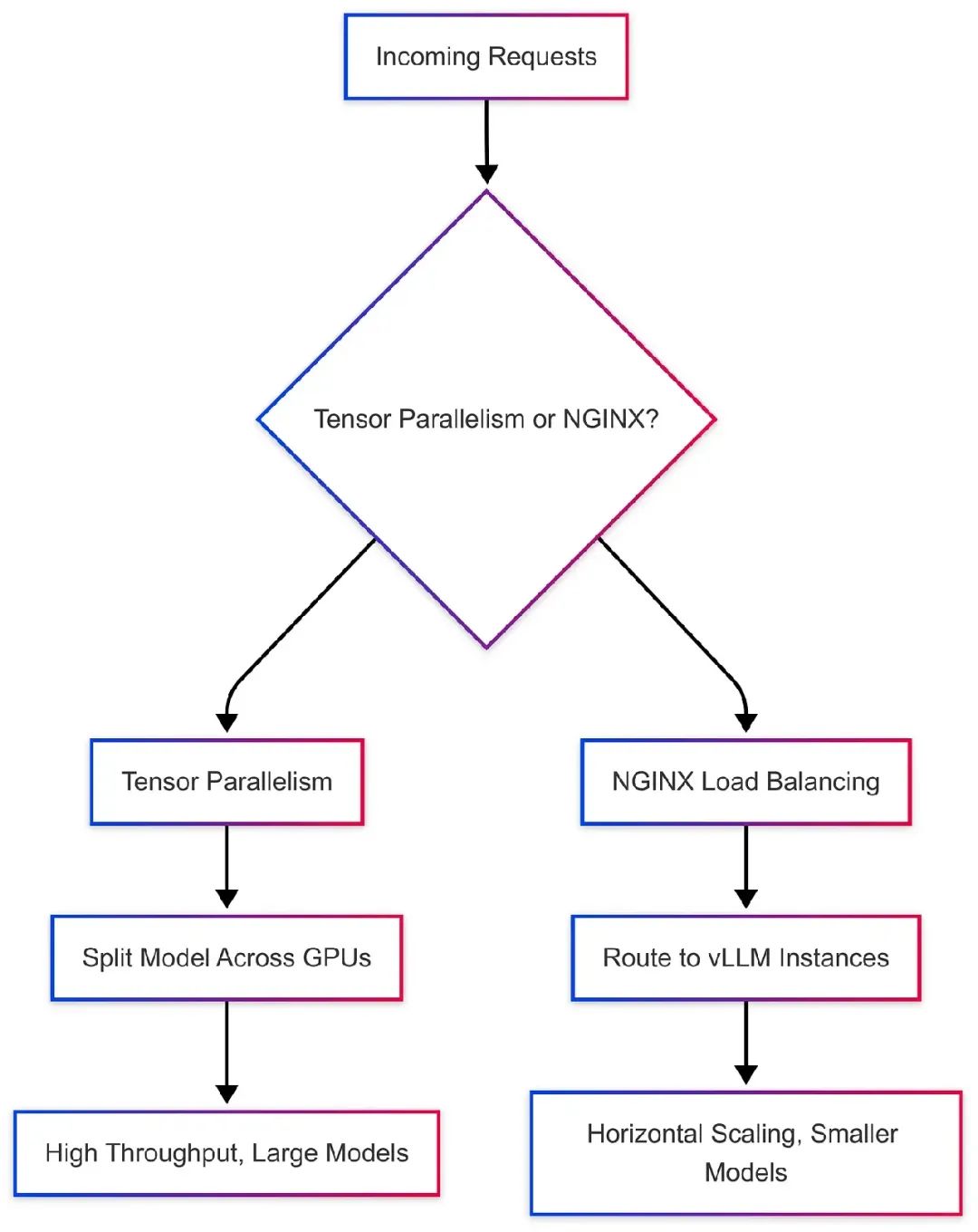
为高吞吐量应用扩展vLLM,需要选择多GPU内存共享还是NGINX负载均衡。我们来比较这两种方式。
多GPU内存共享
vLLM的tensor parallelism和pipeline parallelism将模型权重和计算分布到多个GPU上,共享内存以处理大模型或高并发。
工作原理:Tensor parallelism将模型层分配到不同GPU,pipeline parallelism分割计算阶段。PagedAttention确保高效内存分配。
优点:
-
• 处理超大模型(比如236B参数)。
-
• 最大化GPU利用率,内存浪费极低。
缺点: -
• 需要高速GPU互连(比如NVLink)。
-
• 设置和配置复杂。
例子:在8个A100 GPU上部署DeepSeek-Coder-V2(236B):
vllm serve DeepSeek/DeepSeek-Coder-V2-Instruct --tensor-parallel-size 8输出:模型跨所有GPU运行,处理请求并行,高吞吐量。
NGINX负载均衡
NGINX将请求分发到多个vLLM实例,每个实例运行在单独的GPU或服务器上。
工作原理:NGINX作为反向代理,根据负载或轮询策略将请求路由到可用vLLM服务器。
优点:
-
• 设置比tensor parallelism简单。
-
• 通过添加更多服务器实现水平扩展。
缺点: -
• 每个vLLM实例需要自己的模型副本,增加内存使用。
-
• 对超大模型效率较低。
NGINX配置示例(nginx.conf):
http {
upstream vllm_servers {
server vllm1:8000;
server vllm2:8000;
}
server {
listen 80;
location / {
proxy_pass http://vllm_servers;
}
}
}启动NGINX:
nginx -c /path/to/nginx.conf输出:NGINX将请求路由到vllm1:8000和vllm2:8000,平衡负载。
比较表:
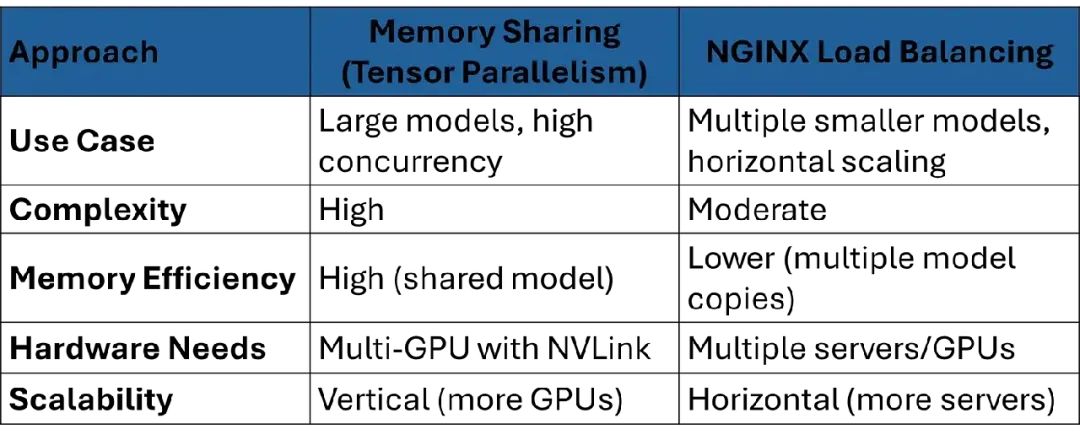
推荐:对于大模型(比如>70B参数)在带NVLink的多GPU服务器上使用内存共享。对于较小模型或通过加服务器扩展更可行时用NGINX。
工作流图表:
11. 其他考虑:安全性、社区和生态系统
安全性
-
• Ollama:本地运行,数据暴露风险小。适合无网络连接的隔离系统(比如政府)。检查后台服务(
ollama serve)以确保敏感环境安全。 -
• vLLM:支持安全部署,但云设置需小心配置。使用HTTPS和API认证配合NGINX:
server {
listen 443 ssl;
ssl_certificate /etc/nginx/ssl/cert.pem;
ssl_certificate_key /etc/nginx/ssl/key.pem;
location / {
proxy_pass http://vllm_servers;
}
}社区和支持
-
• Ollama:社区活跃,文档丰富,模型注册表用户友好。适合初学者和小型项目。
-
• vLLM:社区在增长,由UC Berkeley和Red Hat支持。更技术化但适合企业,GitHub讨论活跃。
生态系统
-
• Ollama:可与OpenWebUI集成,提供类似ChatGPT的界面。支持多模态模型(比如Llama 3.2 Vision处理文本和图像)。
-
• vLLM:与Hugging Face集成,支持高级解码(比如beam search),优化用于LangChain或LlamaIndex等生产管道。
12. 高级话题:量化和多模态模型
量化
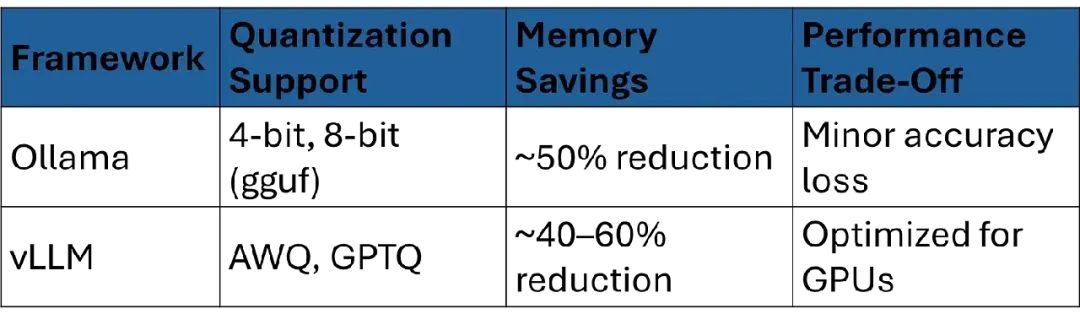
量化通过降低数值精度(比如从FP16到INT8)减少模型大小和内存使用。两个框架都支持,但有差异:
- • Ollama:支持通过gguf文件进行4位和8位量化。示例:
输出:下载量化后的Mistral 7B模型(约2GB,FP16为4GB)。ollama pull mistral:7b-q4 - • vLLM:支持AWQ、GPTQ等量化方式加速GPU:
好处:减少内存占用,支持在有限GPU上运行更大模型。vllm serve meta-llama/Llama-3-8b --quantization awq
多模态模型
- • Ollama:支持视觉语言模型,如Llama 3.2 Vision。示例:
输出:处理文本和图像输入(比如“描述这张图片”配合本地文件)。ollama run llama3.2:vision - • vLLM:多模态支持有限,但扩展中(比如LLaVA模型)。示例:
注意:视觉处理需额外设置。vllm serve llava-hf/llava-13b --trust-remote-code
量化比较表:
13. 结论:为LLM需求做出正确选择
从Ollama过渡到vLLM就像从家里厨房搬到商业厨房。Ollama适合本地实验、注重隐私的应用和资源受限环境。它的简单性和跨平台支持非常适合初学者和小型项目。vLLM凭借PagedAttention和continuous batching,专为高吞吐量、生产级应用打造,速度和可扩展性至关重要。
-
• 选择Ollama:用于原型开发、离线应用或基于CPU的设置。
-
• 选择vLLM:用于高流量服务、大型模型或多GPU部署。
之前商界有位名人说过:“站在风口,猪都能吹上天”。这几年,AI大模型领域百家争鸣,百舸争流,明显是这个时代下一个风口!
那如何学习大模型&AI产品经理?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以点扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 19
19 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)