一文搞懂大模型的部署(Ollama和vLLM),大模型入门到精通,收藏这篇就足够了!
Ollama是一款专注于简化大型语言模型本地部署和运行的开源框架,基于Go语言实现,支持跨平台运行,并以“开箱即用”为核心理念,适合个人开发者和轻量化场景。
Ollama是一款专注于简化大型语言模型本地部署和运行的开源框架,基于Go语言实现,支持跨平台运行,并以“开箱即用”为核心理念,适合个人开发者和轻量化场景。
而vLLM是一个高效的大模型推理与服务引擎,基于PyTorch构建,创新性地引入了PagedAttention技术,旨在解决大模型服务中的显存效率与吞吐量瓶颈,支持张量并行和流水线并行,可横向扩展至多机多卡集群。

一、Ollama
****Ollama是什么?****Ollama 是一个专注于本地运行大型语言模型(LLM)的工具,支持macOS/Linux/Windows,ARM架构设备友好,提供简洁的命令行接口,适合个人开发者和研究者快速体验模型。

Ollama以“开箱即用”为核心理念,专为个人开发者和轻量化场景设计。
Ollama基于Go语言实现,通过模块化封装将模型权重、依赖库和运行环境整合为统一容器。这种设计使得用户无需关注底层依赖,仅需一条命令行即可启动模型服务。
Ollama的优势在于开发友好性,但生产部署时面临性能、稳定性和运维能力的全方位挑战。对于关键业务系统,建议仅将其作为实验阶段的验证环节,而非最终部署方案。
# Linux/macOS 一键安装脚本
curl -fsSL https:
//ollama.com/install.sh | sh
# 拉取 DeepSeek-R1 模型
ollama pull DeepSeek-R1
# 启动 DeepSeek-R1 模型
ollama run DeepSeek-R1
# 启动交互式对话
# 通过 API 调用 DeepSeek-R1 模型
curl http:
//localhost:11434/api/generate -d '{
"model"
:
"DeepSeek-R1"
,
"prompt"
:
"为什么天空是蓝色的?"
}
'
二、vLLM
******vLLM(Vectorized Large Language Model Serving System)是什么?******vLLM 是一个高效的大模型推理与服务引擎,旨在解决大模型服务中的显存效率与吞吐量瓶颈,适合生产环境部署。
# 安装 vLLM
pip install vllm
# 需要 Python 3.8+ 和 CUDA 11.8+
#启动 vLLM 推理服务,并使用 DeepSeek-R1 模型
# 单卡启动 DeepSeek-R1
python -m vLLM.entrypoints.api_server \
--model deepseek/DeepSeek-R1 \
--tensor-parallel-size 1
# 使用 curl 命令调用 DeepSeek-R1 模型的推理服务
curl http://localhost:8000/generate \
-H
"Content-Type: application/json"
\
-d
'{"prompt": "解释量子纠缠", "max_tokens": 200}'
# 使用 vLLM 的 Python SDK 调用 DeepSeek-R1 模型
from
vllm
import
LLM
llm = LLM(
"deepseek/DeepSeek-R1"
)
outputs = llm.generate([
"AI 的未来发展方向是"
])
print
(outputs)
分页注意力机制(PagedAttention)是什么?分页注意力机制借鉴了计算机操作系统中的内存分页管理,通过动态分配和复用显存空间,显著提升大模型推理的效率和吞吐量。
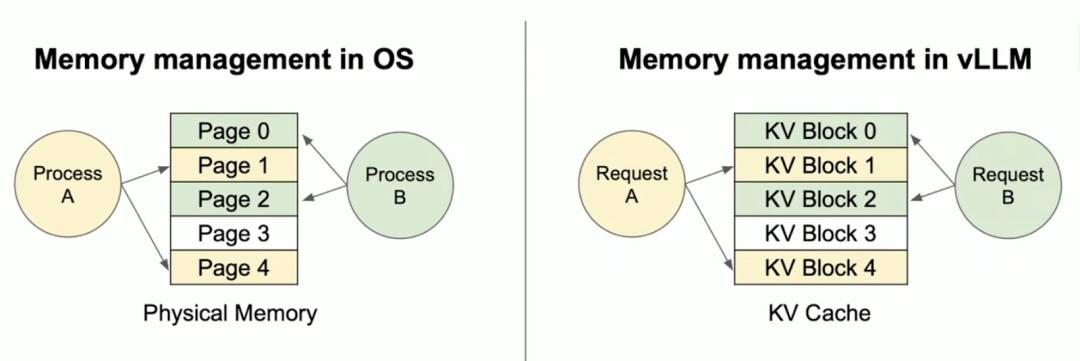
在传统的大模型推理中,注意力机制(Transformer的自注意力层)需要为每个请求的序列分配连续的显存块,存储以下数据:
(1)键值缓存(Key-Value Cache,KV Cache):存储历史token的键值对,用于生成后续token。
(2)中间激活值:计算注意力权重时的中间结果。
vLLM基于PyTorch构建,创新性地引入了PagedAttention技术。该技术借鉴操作系统的虚拟内存分页机制,将注意力键值对(KV Cache)存储在非连续显存空间,显著提高了显存利用率。
PagedAttention通过分块管理显存、动态按需分配和跨请求共享内存,解决了传统方法中显存碎片化、预留浪费和并发限制三大瓶颈。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 4
4 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)