【MiniMind】从零开始训练大模型:开源LLM实践指南
🔗GitHub 地址MiniMind 项目提供了从数据处理到训练、微调的完整流程,核心亮点包括:✔轻量级模型:基础版本参数量仅 25.8M,适合个人开发者。✔全流程开源:包含数据预处理、预训练、监督微调(SFT)、LoRA 微调、DPO(直接偏好优化)等完整代码。✔原生 PyTorch 实现:方便二次开发,深入理解 LLM 训练原理。✔支持多模态扩展:官方还推出了视觉语言模型 MiniMind-
💡 引言
大语言模型(LLM)已成为AI领域的热门话题,但传统模型如GPT-3和LLaMA的训练成本高昂,令个人开发者望而却步。如何在有限计算资源下,搭建自己的大模型?MiniMind 开源项目给出了答案!
MiniMind 是一个轻量级 LLM 训练框架,支持从零训练小型语言模型,甚至在单张 NVIDIA 3090 显卡上实现高效训练。本篇文章将带你快速上手 MiniMind,了解 LLM 训练的完整流程!

🚀 MiniMind 开源项目简介
🔗 GitHub 地址:https://github.com/jingyaogong/minimind
MiniMind 项目提供了 从数据处理到训练、微调 的完整流程,核心亮点包括:
✔ 轻量级模型:基础版本参数量仅 25.8M,适合个人开发者。
✔ 全流程开源:包含数据预处理、预训练、监督微调(SFT)、LoRA 微调、DPO(直接偏好优化)等完整代码。
✔ 原生 PyTorch 实现:方便二次开发,深入理解 LLM 训练原理。
✔ 支持多模态扩展:官方还推出了视觉语言模型 MiniMind-V!
📢 实际测试:使用 NVIDIA RTX 3090 训练 25.8M 规模模型,成本低至 3 元人民币,训练时间约 2 小时!
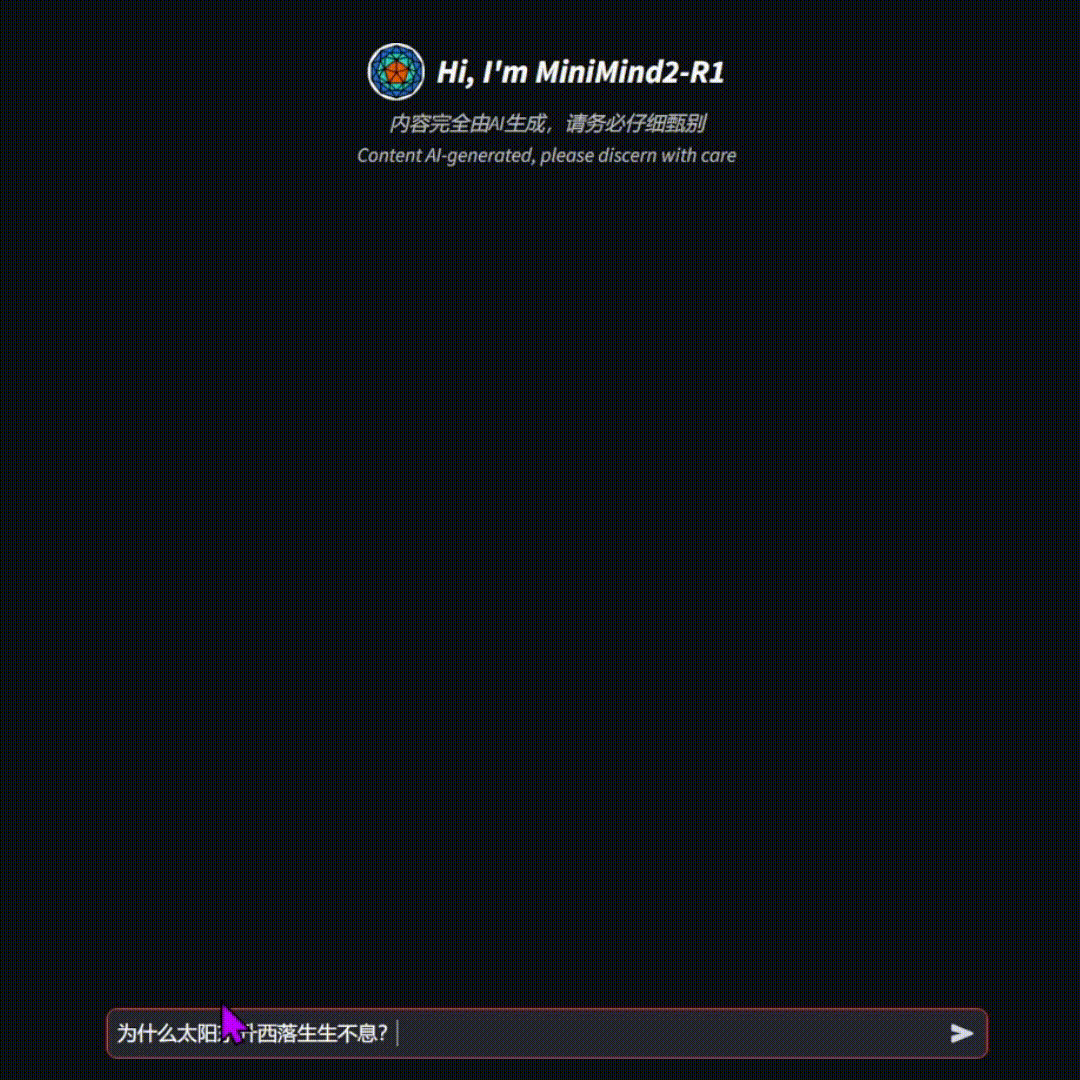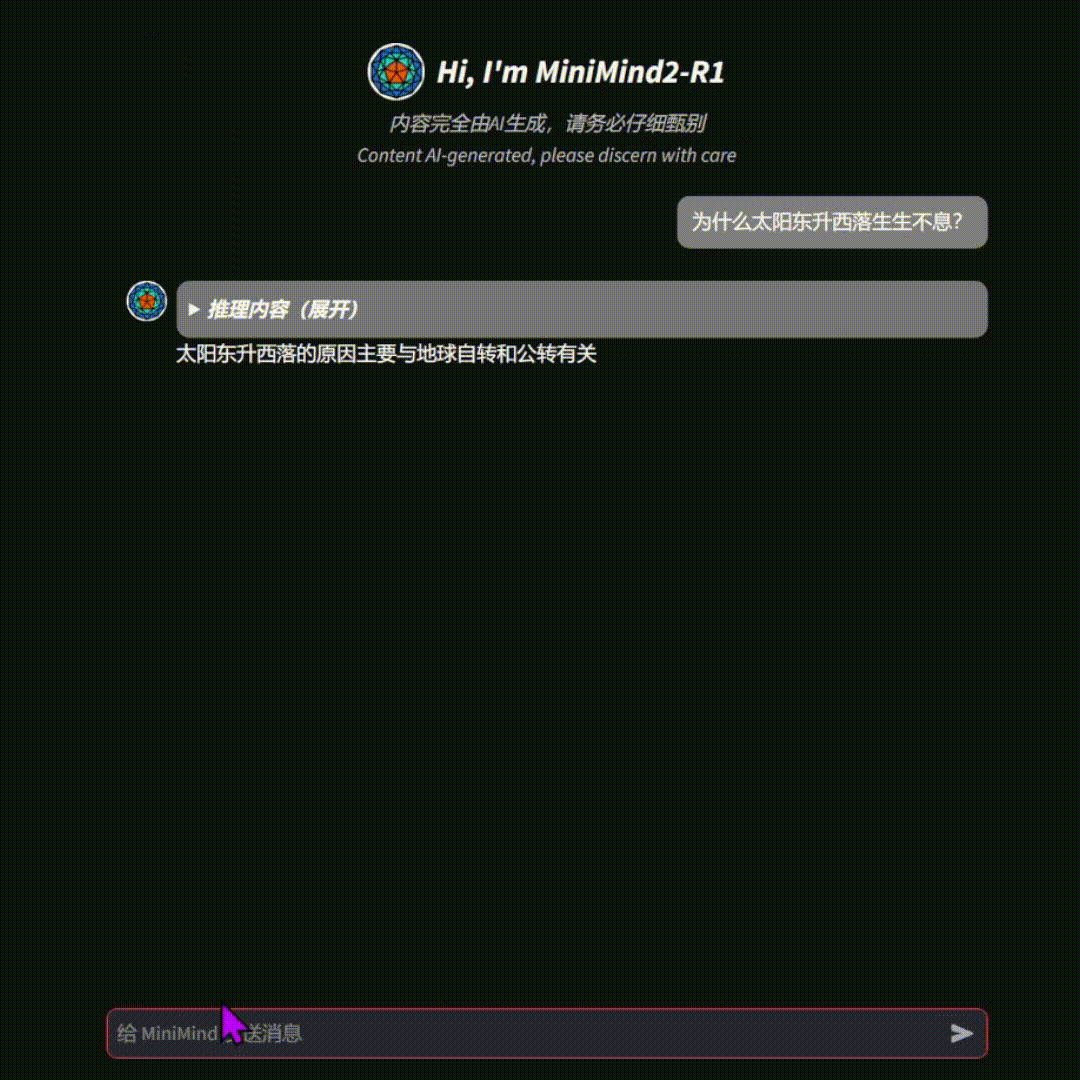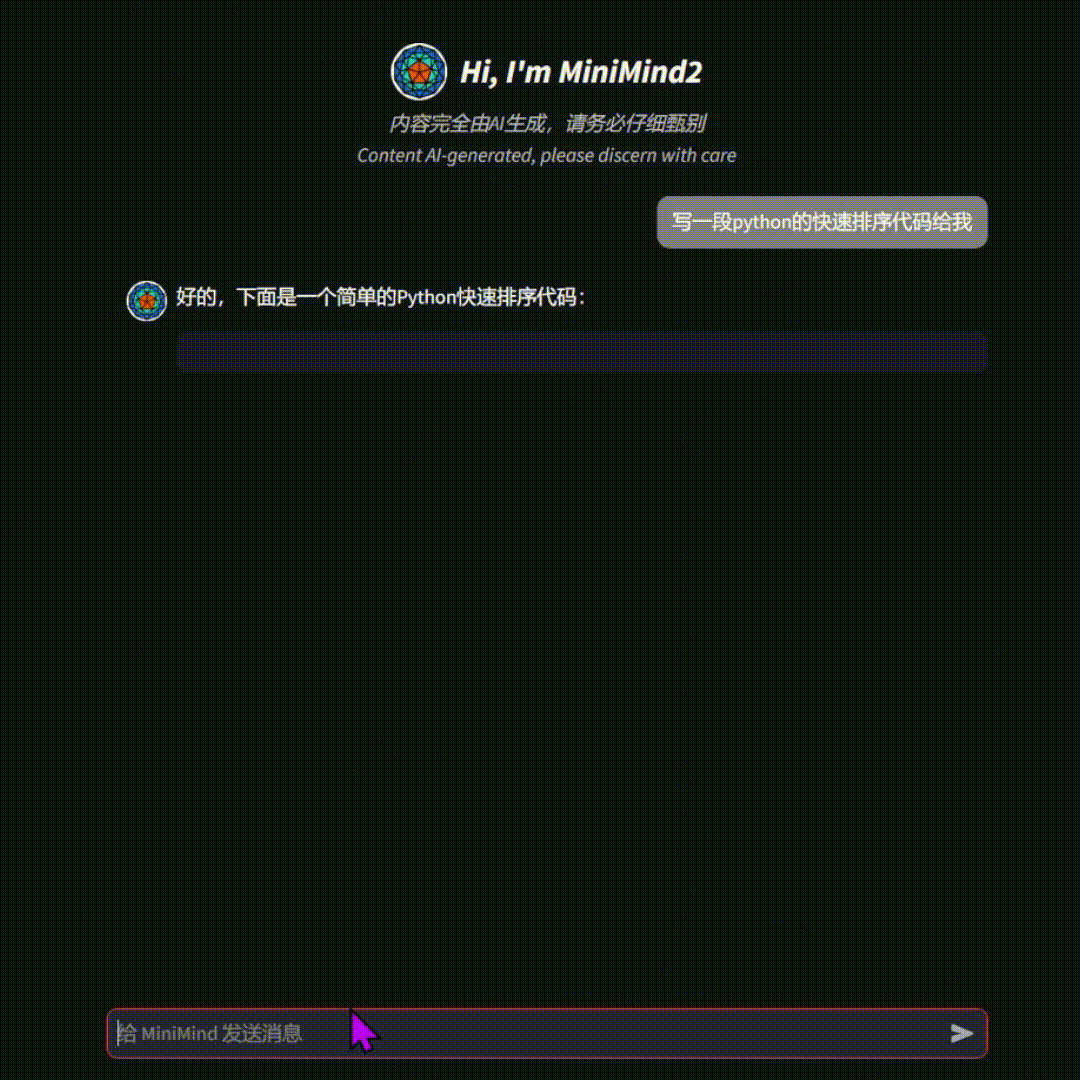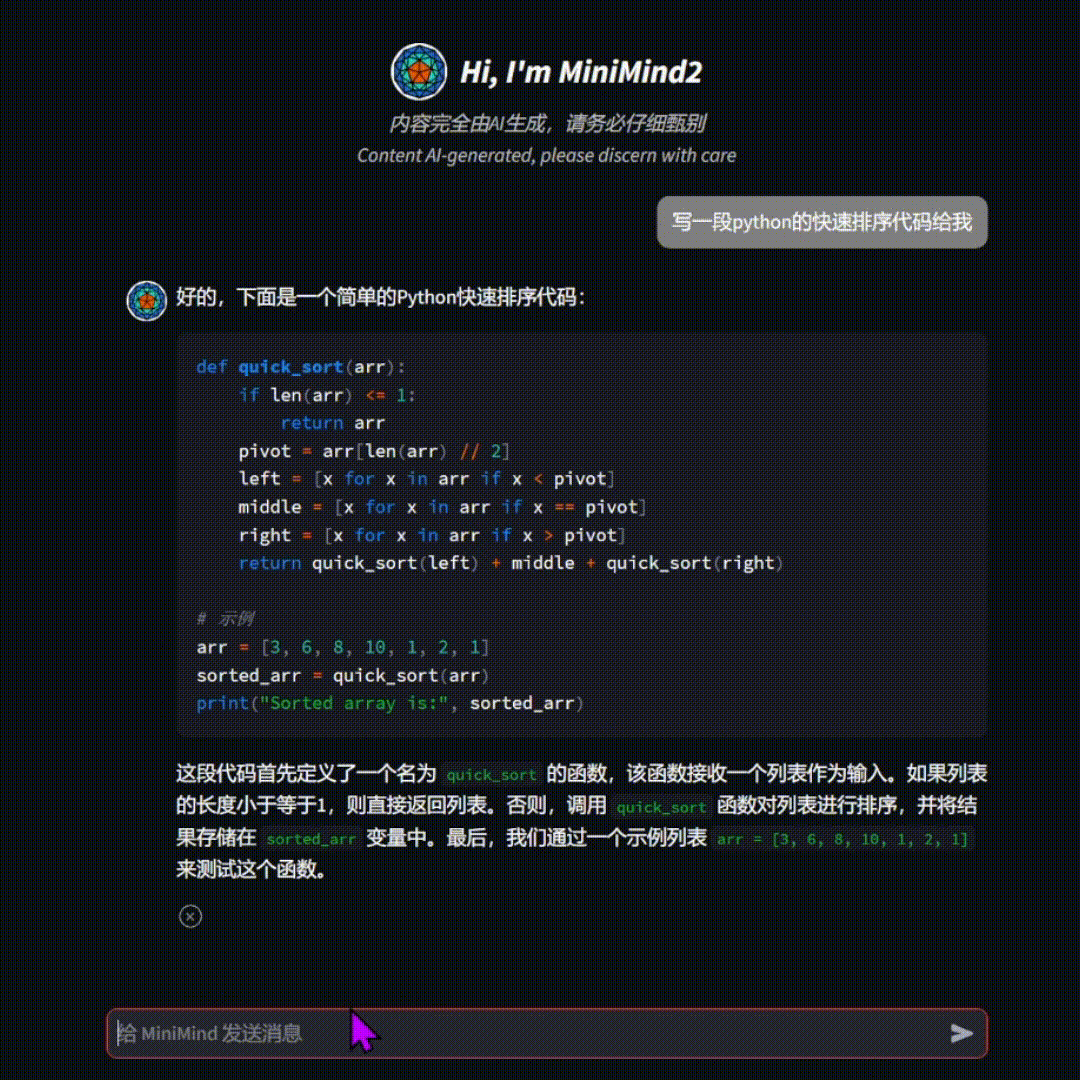
🛠️ 环境搭建
首先,确保本地环境满足以下条件:
-
Python:3.8 及以上
-
PyTorch:GPU 版本(建议使用 CUDA)
-
GPU:NVIDIA 3090 及以上(更高算力可加速训练)
📌 1. 克隆 MiniMind 仓库
git clone https://github.com/jingyaogong/minimind.git
cd minimind📌 2. 安装依赖
pip install -r requirements.txt📊 从零开始训练 LLM
1️⃣ 数据预处理
LLM 训练的第一步是 清洗训练数据。MiniMind 提供了自动数据处理工具,可以对数据集进行去重、分词等操作:
python preprocess.py --config configs/data_config.json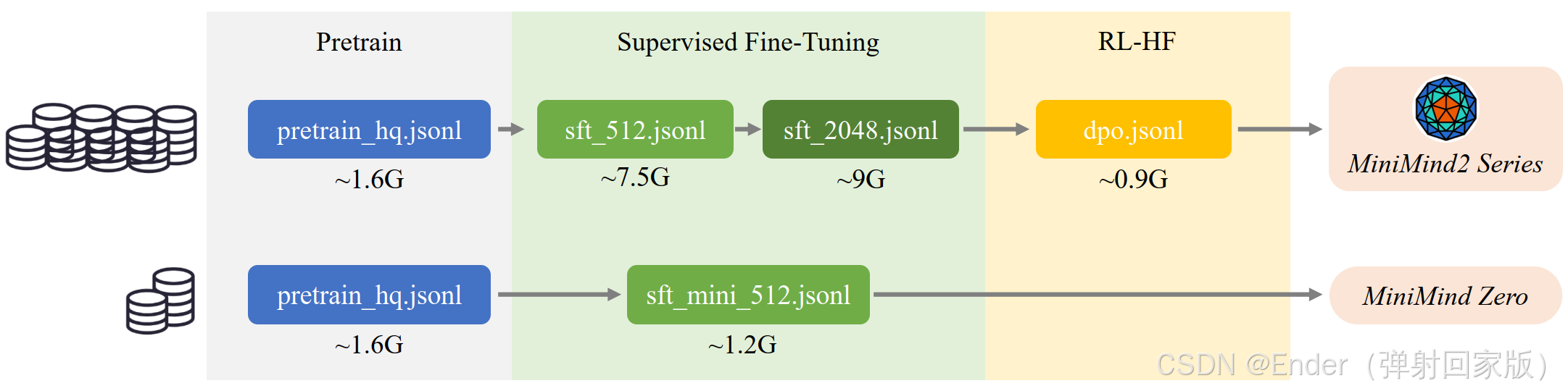
2️⃣ 预训练(Pretrain)
在处理好的数据集上,使用 Transformer 结构进行预训练:
python pretrain.py --config configs/pretrain_config.json⏳ 训练时长:单卡 3090 约 2 小时完成基础模型训练。
3️⃣ 监督微调(SFT)
为了让模型更符合人类指令需求,我们使用 监督微调(Supervised Fine-tuning, SFT) 方法优化模型:
python sft.py --config configs/sft_config.json4️⃣ LoRA 低秩适配微调
LoRA(Low-Rank Adaptation)是一种高效微调技术,可以 在不改变原模型参数的情况下,添加适配层,极大降低计算开销。MiniMind 内置了 LoRA 支持,执行如下命令进行训练
python lora_finetune.py --config configs/lora_config.json5️⃣ 直接偏好优化(DPO)
DPO(Direct Preference Optimization)用于 优化 LLM 生成结果,使其更加符合人类偏好。MiniMind 也实现了该功能:
python dpo.py --config configs/dpo_config.json🔍 模型评估
训练完成后,可以使用 MiniMind 提供的评估工具测试模型效果:
python evaluate.py --config configs/eval_config.json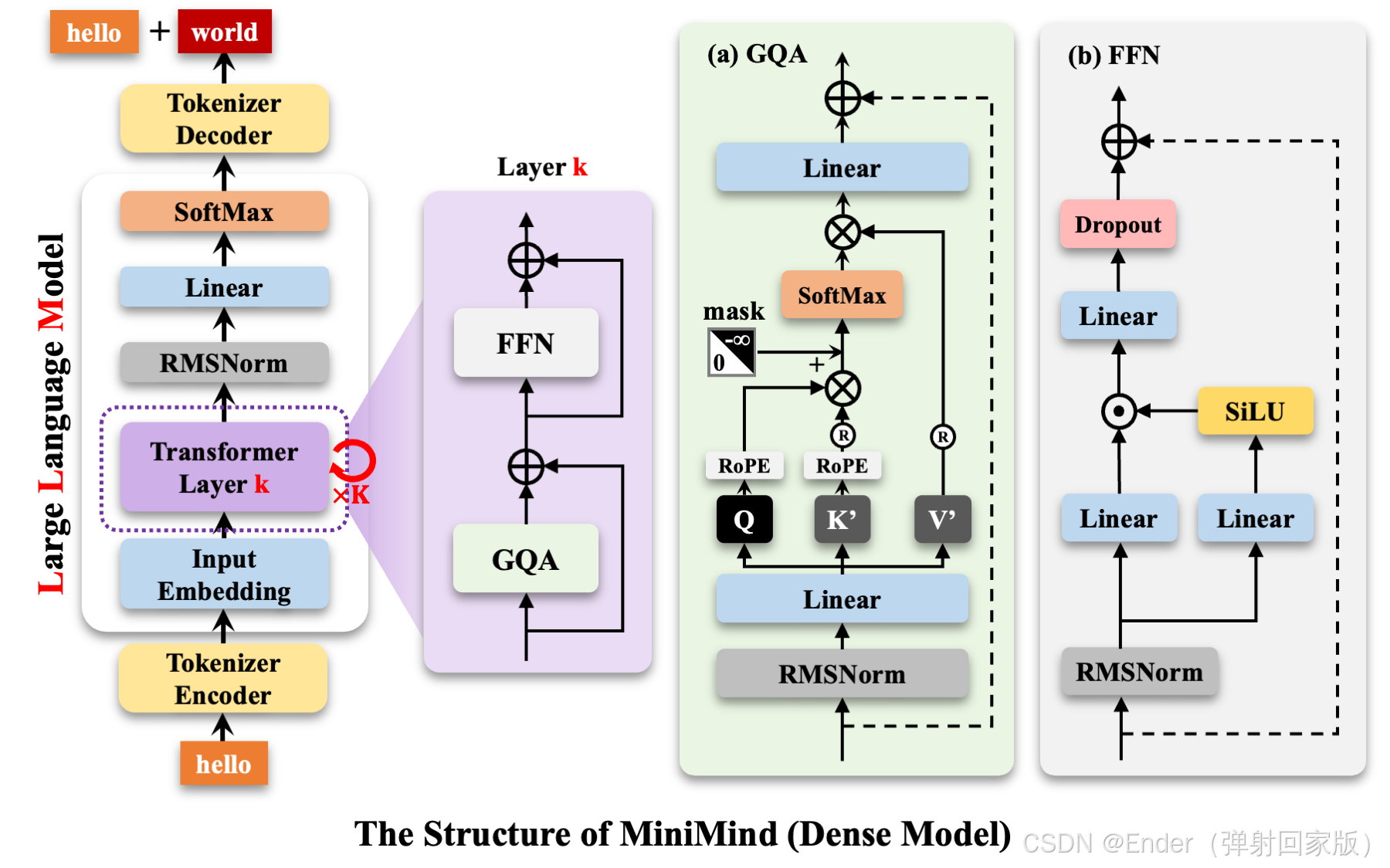
🎯 结语
通过 MiniMind,你可以 在个人 GPU 设备上从零训练 LLM,掌握完整的 预训练 + 微调 流程,甚至可以训练自己的专属大语言模型!
💬 你觉得 MiniMind 适合哪些场景?欢迎在评论区讨论!
📌 MiniMind GitHub 地址:https://github.com/jingyaogong/minimind

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)