大语言模型微调:从原理到实战,一张消费级显卡就够了
摘要:大语言模型微调技术门槛显著降低,LoRA和QLoRA方法让消费级显卡也能实现高效微调。LoRA通过训练小型适配矩阵(仅需0.1%参数量)达到全参数微调95%以上效果,QLoRA进一步引入4-bit量化使7B模型显存需求降至8GB。实践流程包括:1)数据准备(1万条高质量数据优于10万条低质数据);2)LoRA配置(推荐r=8-16);3)训练参数调优;4)两阶段微调策略提升专业领域效果。当前
大语言模型微调:从原理到实战,一张消费级显卡就够了
说起来,大模型微调这个话题最近热度越来越高。前两天在即刻上看到好几个技术博主在分享自己的微调实战经验,作为AI Native Coder,我其实一直挺关注这个方向的。
原因很简单。2025年之前,想玩大模型微调简直是土豪的专属游戏——动辄几张A100显卡,算力成本数万起步。但现在,随着LoRA、QLoRA这些技术成熟,情况完全变了。
今天想系统聊聊大语言模型微调这件事,从原理到实践,给想上手的同学一个完整的技术路线图。
微调是什么?和预训练什么关系?
先说个基本概念。大模型的成长其实分两个阶段:
预训练阶段:用海量文本(万亿级别token)让模型学习通用知识和语言能力。这就像让一个学生读完所有学科的教材,成为"博而不专"的通才。
微调阶段:用特定领域的专业数据让模型"专业化"。这就像让那个通才再深造医学或法律,成为某个领域的专家。
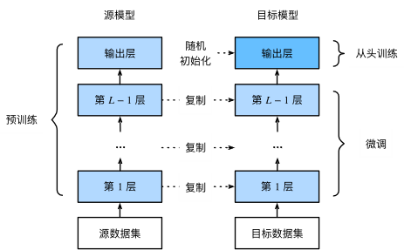
为什么需要微调?因为通用模型虽然博学,但在专业任务上往往不够"精准"。比如你让ChatGPT写Python代码它很在行,但让它分析医疗影像诊断报告,效果可能就不太理想了。
这时候微调的价值就体现出来了——通过少量专业数据的训练,让模型快速掌握某个领域的"行话"和思维方式。
三种主流微调方法:怎么选?
现在微调的方法有很多,但真正主流的其实就三种:全参数微调、LoRA、QLoRA。
全参数微调:土豪的专属
这个方法最直接——解冻模型的所有参数,全部重新训练。
听起来很完美对吧?但代价太大了。以7B参数模型为例,全参数微调至少需要4张A100显卡(40GB显存),单日训练成本超过5000元。如果要微调70B模型,成本直接飙升到数万元。
而且每次微调都会生成一个完整的新模型文件,想适配多个领域就得存多个版本,存储压力巨大。
适用场景:只有在大厂、科研机构或者对性能要求极致到不能容忍任何损失的时候,才会用这个方法。2025年,绝大多数从业者已经不再使用这个方法了。
LoRA:参数高效微调的代表作
LoRA(Low-Rank Adaptation)是微软在2021年提出的方法,核心思想非常巧妙——不直接修改模型参数,而是在关键层旁边加两个小的矩阵(A和B),只训练这两个矩阵。
举个例子,7B模型的权重矩阵大概是4096×4096的大小。如果用全参数微调,要训练1677万个参数;但用LoRA,只需要训练两个4096×8和8×4096的矩阵,一共65,536个参数。
参数量减少了250倍!
这个数字还挺猛的。我第一次看到这个数据时也愣了一下——这么少的参数,效果会不会很差?
事实证明不会。在GLUE基准测试上,LoRA仅用0.1%的参数,就能达到全参数微调95%~99%的性能。
更重要的是,LoRA训练后的"适配器"通常只有几十MB,而完整模型要十几GB。一套基础模型可以搭配多个LoRA适配器,就像给一套游戏装不同DLC一样,切换任务只要几秒钟。
适用场景:中小团队、个人开发者、需要快速迭代的业务。这是目前工业界最主流的方案。
QLoRA:极致显存压缩
QLoRA是LoRA的"省钱升级版"。它在LoRA基础上引入了4-bit量化技术——把模型权重从16位或32位压缩到4位。
效果有多夸张?在7B模型上,显存需求从24GB降到8GB左右。这意味着你甚至可以在单张RTX 3060上微调7B模型。
代价是什么呢?训练时间会增加20%~30%(因为每次计算前要反量化),性能会有轻微损失(约1%~3%)。
但这个性价比,对于算力有限的团队来说简直是福音。
适用场景:个人开发者、边缘设备部署、超大模型(70B+)微调。
硬件需求:你的显卡够用吗?
微调大模型最关键的是显存。简单总结一下:
|
模型规模 |
微调方法 |
最低显存 |
推荐显卡 |
|
7B |
QLoRA (4-bit) |
8GB |
RTX 3060 / RTX 4060 |
|
7B |
LoRA |
24GB |
RTX 3090 / RTX 4090 |
|
7B |
全参数 |
80GB |
A100 (80GB) |
|
13B |
QLoRA |
16GB |
RTX 3080 / RTX 4070 |
|
13B |
LoRA |
40GB |
A100 (40GB) |
|
70B |
QLoRA |
48GB |
2x RTX 4090 / A100 (80GB) |
这个表格可以作为一个快速参考。核心结论是:得益于QLoRA,现在一张24GB显存的RTX 4090已经能让你玩转绝大多数中等规模模型了。
完整微调流程:从数据到部署
现在说实战。我用Hugging Face的Transformers、PEFT、TRL库,以LoRA微调为例,走一遍完整流程。
第一步:环境准备
pip install transformers datasets peft trl bitsandbytes accelerate核心依赖就这几个。注意版本兼容性,特别是PyTorch和CUDA的版本匹配。
第二步:数据准备
数据的质量远比数量重要。很多人一开始就想着要准备几十万条数据,但实际上1万条高质量标注数据,往往比10万条"垃圾数据"效果好得多。

标准的数据格式是这样的:
[
{
"instruction": "用Python实现快速排序算法",
"input": "",
"output": "def quick_sort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr) // 2]\n left = [x for x in arr if x < pivot]\n middle = [x for x in arr if x == pivot]\n right = [x for x in arr if x > pivot]\n return quick_sort(left) + middle + quick_sort(right)"
}
]关键点:
• instruction要清晰明确,让模型知道要做什么
• output要是高质量的标准答案
• 如果有input(比如给一段文本让它总结),也要标注好
数据预处理也很重要。比如:
• 去除重复数据
• 过滤低质量样本(输出太短、格式混乱的)
• 数据增强(改写instruction、生成多样化output)
第三步:模型加载和LoRA配置
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
from trl import SFTTrainer, SFTConfig
# 1. 加载基础模型
model_name = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 2. 配置LoRA参数
peft_config = LoraConfig(
r=16, # 低秩矩阵的秩
lora_alpha=32, # 缩放因子,通常设为r的2倍
lora_dropout=0.05, # dropout率,防止过拟合
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # 目标模块
bias="none",
task_type="CAUSAL_LM",
)
# 3. 应用LoRA
model = get_peft_model(model, peft_config)
model.print_trainable_parameters() # 打印可训练参数比例这几个参数很重要,我逐个解释:
• r(rank):核心参数。太小(如2-4)可能欠拟合,太大(如64+)接近全参数微调。经验值是8-16,在大多数任务上能达到最佳平衡。
• lora_alpha:缩放因子,控制LoRA更新的强度。通常设为r的2倍。
• lora_dropout:防止过拟合,0.05是比较稳健的值。
• target_modules:选择要应用LoRA的层。通常选注意力层的qproj、vproj即可,kproj、oproj可以加上但不一定必要。
第四步:训练参数配置
training_args = SFTConfig(
output_dir="./qwen-lora-output", # 输出目录
num_train_epochs=3, # 训练轮数
per_device_train_batch_size=2, # 每个设备的batch size
gradient_accumulation_steps=4, # 梯度累积步数
learning_rate=2e-4, # 学习率
logging_steps=10, # 日志记录步数
max_seq_length=1024, # 最大序列长度
packing=True, # 启用打包以提高效率
)几个调优技巧:
• learning_rate:LoRA通常用2e-4到1e-4,比全参数微调高一些。可以从2e-4开始,观察loss曲线再调整。
• gradient_accumulation_steps:显存不够时,可以把batchsize设小,然后通过梯度累积模拟更大的batch。比如batchsize=2,gradientaccumulationsteps=4,等价于batch_size=8。
• max_seq_length:根据你的数据长度设置。太长浪费显存,太短会截断信息。
第五步:启动训练
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("json", data_files="your_data.json", split="train")
# 初始化Trainer
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=training_args,
)
# 开始训练
trainer.train()训练过程中,要关注loss曲线。
理想的loss曲线应该是:
• 初期快速下降
• 中期平稳收敛
• 后期趋于稳定,不要过度训练
如果loss震荡或发散,可能是:
• 学习率太高(降到原来的1/2或1/10)
• 数据质量差(检查数据)
• batch size太小(尝试梯度累积)
第六步:模型评估和保存
# 评估
metrics = trainer.evaluate()
print(f"Final eval loss: {metrics['eval_loss']}")
# 保存LoRA适配器
model.save_pretrained("./my-lora-adapter")LoRA的好处是只需要保存适配器(几十MB),不需要保存完整模型。
第七步:推理部署
from peft import PeftModel
# 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
# 加载LoRA适配器
model = PeftModel.from_pretrained(base_model, "./my-lora-adapter")
# 推理
inputs = tokenizer("用Python实现快速排序", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))如果想把LoRA合并到基础模型(这样就不需要动态加载适配器了):
merged_model = model.merge_and_unload()
merged_model.save_pretrained("./merged-model")进阶优化:怎么把效果榨干?
微调不是"跑通代码"就完了,还有很多细节可以优化。
数据增强
原始数据太少怎么办?可以用模型来增强:
1. 改写instruction:用GPT-4把instruction改写成不同的表达方式
2. 生成多样化output:同一个instruction生成多个版本的答案
3. 反向生成:从答案反推instruction
但要注意,增强数据的质量要严格控制,不能为了凑数量而降低质量。
两阶段微调
对于专业领域(医疗、法律、金融),推荐两阶段策略:
阶段一:持续预训练
• 用领域无标注文本(论文、报告、法规)
• 让模型先学习"行话"和知识体系
• 通常用LoRA就够了,rank可以设大一些(32-64)
阶段二:任务微调
• 用有标注的任务数据
• 让模型学会"怎么用知识"
• rank可以设小一些(8-16)
这样比直接微调效果好很多。
超参数搜索
关键超参数需要针对你的任务调优:
• r:从8开始,尝试8、16、32
• learning_rate:从2e-4开始,尝试2e-4、1e-4、5e-5
• num_train_epochs:不要过度训练,看validation loss
可以用验证集来网格搜索,但成本较高。更实用的方法是"基于经验的快速迭代"——先跑一个baseline,然后根据结果调整。
分布式训练
如果模型比较大(13B+),单卡可能跑不动。这时候可以用:
• FSDP:PyTorch的分布式训练框架,适合模型并行
• DeepSpeed ZeRO:微软的分布式优化器,显存优化效果很好
Hugging Face的Trainer对这两个都有支持,只需在TrainingArguments中配置即可。
常见问题:你可能遇到的坑
Q1:训练时显存溢出怎么办?
排查顺序:
1. 降低perdevicetrainbatchsize(比如从4降到2或1)
2. 减小maxseqlength(比如从2048降到1024)
3. 启用梯度检查点(gradient_checkpointing=True)
4. 如果是LoRA,考虑用QLoRA
Q2:模型效果不理想怎么办?
可能的原因:
1. 数据质量差 → 重新清洗数据,增加人工审核
2. 数据量不够 → 收集更多数据或做数据增强
3. 超参数不对 → 调整r、learning_rate、epochs
4. 基础模型不合适 → 换个更合适的模型(比如Qwen2.5可能比Llama 2在某些任务上更好)
Q3:模型"学偏了"怎么办?
这是典型的"灾难性遗忘"。解决方法:
1. 用LoRA而不是全参数微调(LoRA本身就能减少遗忘)
2. 在训练数据中混入一些原始预训练数据
3. 用正则化方法(如EWC)保护重要参数
Q4:多任务怎么处理?
两种方法:
1. 混合训练:把多个任务的数据混在一起训练,适合任务比较相似的场景
2. 多LoRA:每个任务训练一个LoRA适配器,推理时动态切换,适合任务差异大的场景
多LoRA的优势是存储效率高——一套基础模型+N个LoRA文件,比N个完整模型省太多了。
最后
微调本质上是在"教模型一种新的思维方式"。这个过程需要的不是算力,而是对数据的理解、对任务的把握、对细节的打磨。
2025年之前,大模型微调是大厂的专属游戏。但现在,随着LoRA、QLoRA这些技术的成熟,以及Hugging Face生态的完善,个人开发者和小团队也能玩得转了。
这是技术民主化的一个缩影。当门槛降低,创新就会爆发。
我见过很多有趣的微调案例:有人微调模型写小说,有人微调模型做心理咨询,有人微调模型分析股票研报。这些应用在两年前是不可能实现的,但现在,一张RTX 4090就能搞定。
这就是技术的魅力——它让普通人也能拥有创造工具的能力,而不是被动地使用工具。
如果你也想尝试,我建议从LoRA开始,找个小一点的模型(7B),准备几千条高质量数据,动手跑一遍。实践出真知,光看教程是学不会的。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)