【Ollama】大模型本地化部署
Ollama 适合个人开发者和中小型场景快速部署和本地推理大模型,但在精度、可微调能力和企业级支持方面仍有不足。
目录

一、租用服务器到服务器连接VScode全流程(可选)
AutoDL连接VSCode运行深度学习项目的全流程教程:
【云端深度学习训练与部署平台】AutoDL连接VSCode运行深度学习项目的全流程-CSDN博客
AutoDL官网地址:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
这里介绍了 AutoDL 平台的使用方法,从平台简介、服务器租用、VSCode远程连接,到高级GPU监控工具的安装,适合中文开发者快速上手深度学习任务。
▲如果说电脑硬件配置太低(如:显存低于24GB),请根据【AutoDL连接VSCode运行深度学习项目的全流程教程】,通过云服务器来进行部署运行;
▲如果说电脑硬件配置足够高(如:显存24GB及以上),或者说有自己的服务器,可以直接跳过这一步;
二、模型框架部署
2.1 Ollama本地化部署
2.1.1 进入官网
Ollama官网地址:Ollama
2.1.2 登录
2.1.3 下载模型
方法1:官网命令下载
1、选择Linux→复制下载命令
说明:通过这个命令安装可能
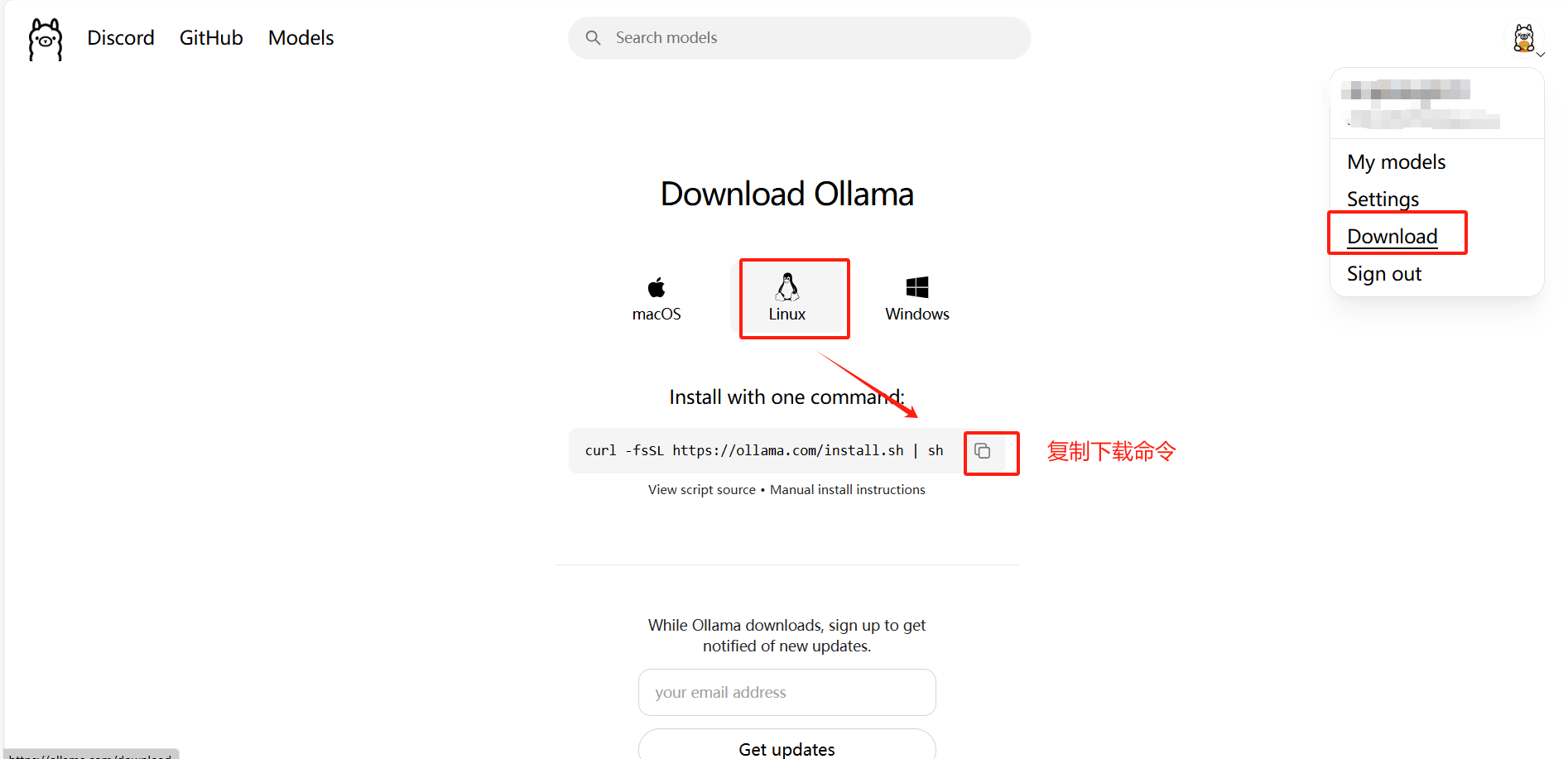 2、将命令粘贴到服务器终端
2、将命令粘贴到服务器终端
说明:官网下载速度时快时慢,不稳定
方法2:魔塔社区中下载
1、进入官网
2、搜索【Ollama】→选择【Ollama-Linux安装】
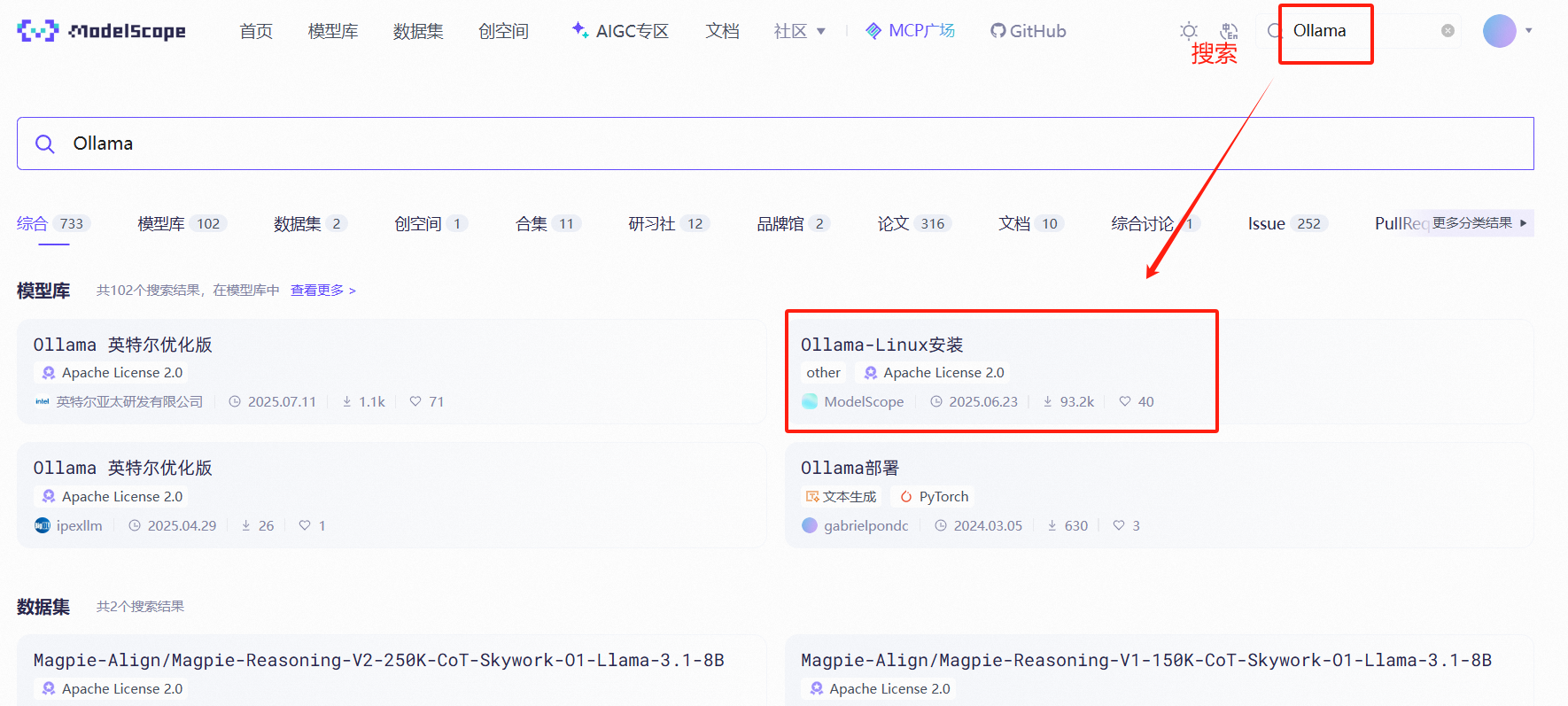
3、安装Ollama的Linux包
官网有提供安装命令说明
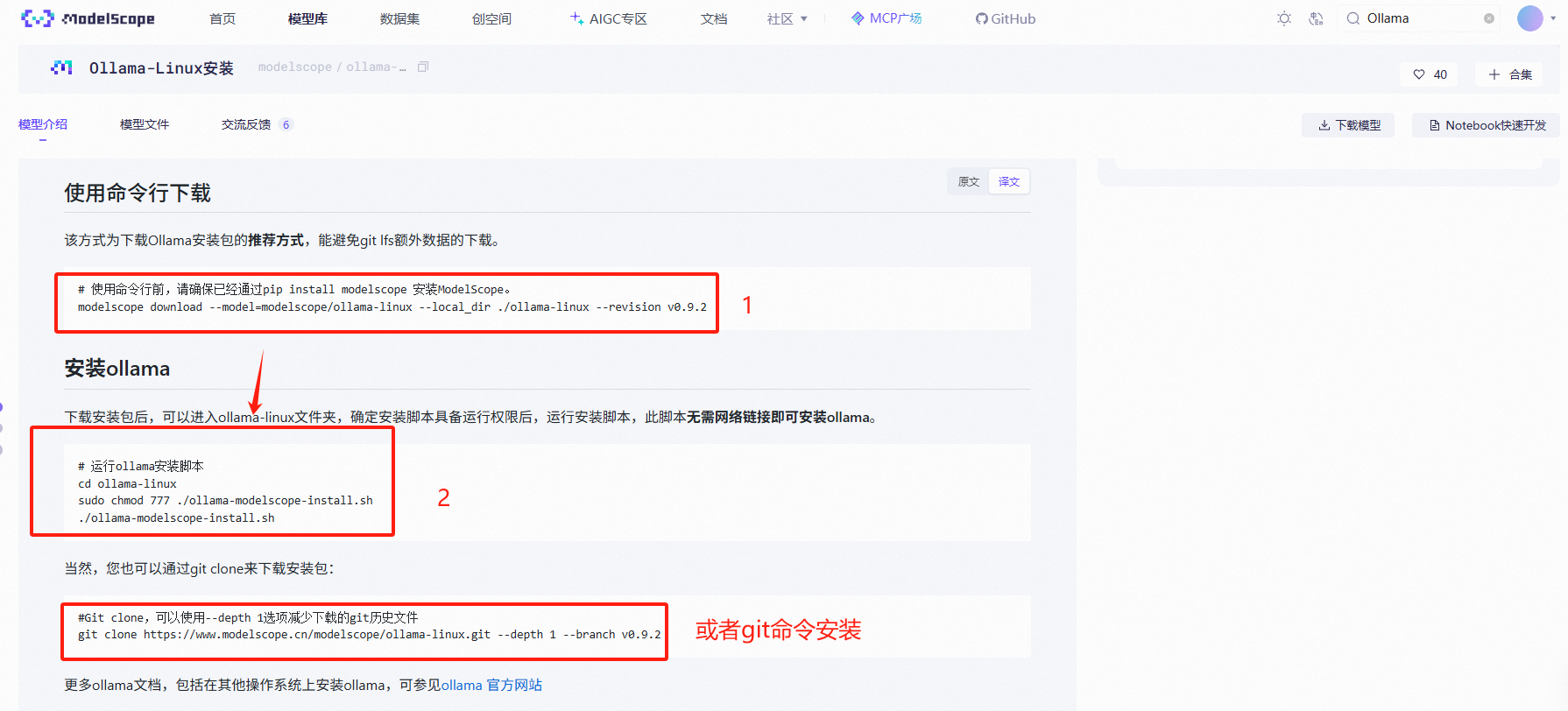
回到【服务器】执行命令,在数据盘中安装Linux包
#切换到数据盘路径下
ce root/autodl-tmp
#安装魔塔社区依赖
pip install modelscope
#查看当前所处目录(确保是/root)
pwd
#列出当前目录下的文件和文件夹
ls
#进入数据盘路径
cd autodl-temp/
#通过 modelscope 平台下载 Ollama 的 Linux 安装包(v0.9.2 版本),并保存在本地指定目录。
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux --revision v0.9.2
弹出以下信息表示安装成功
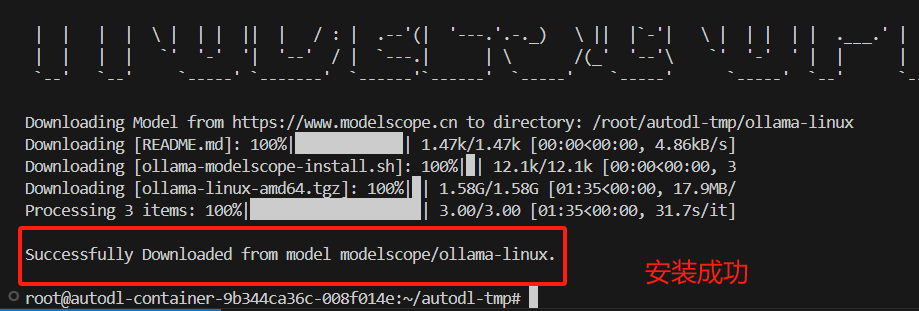
系统盘会多出一个【ollama-linux】文件

Ollama的Linux安装包命令详解
modelscope download \
--model=modelscope/ollama-linux \ # 1. 指定要下载的模型或工具名称(这里是 Ollama 的 Linux 安装包)
--local_dir ./ollama-linux \ # 2. 下载后保存的本地路径(当前目录下的 ollama-linux 文件夹)
--revision v0.9.2 # 3. 指定版本号(下载 Ollama 的 v0.9.2 版本)
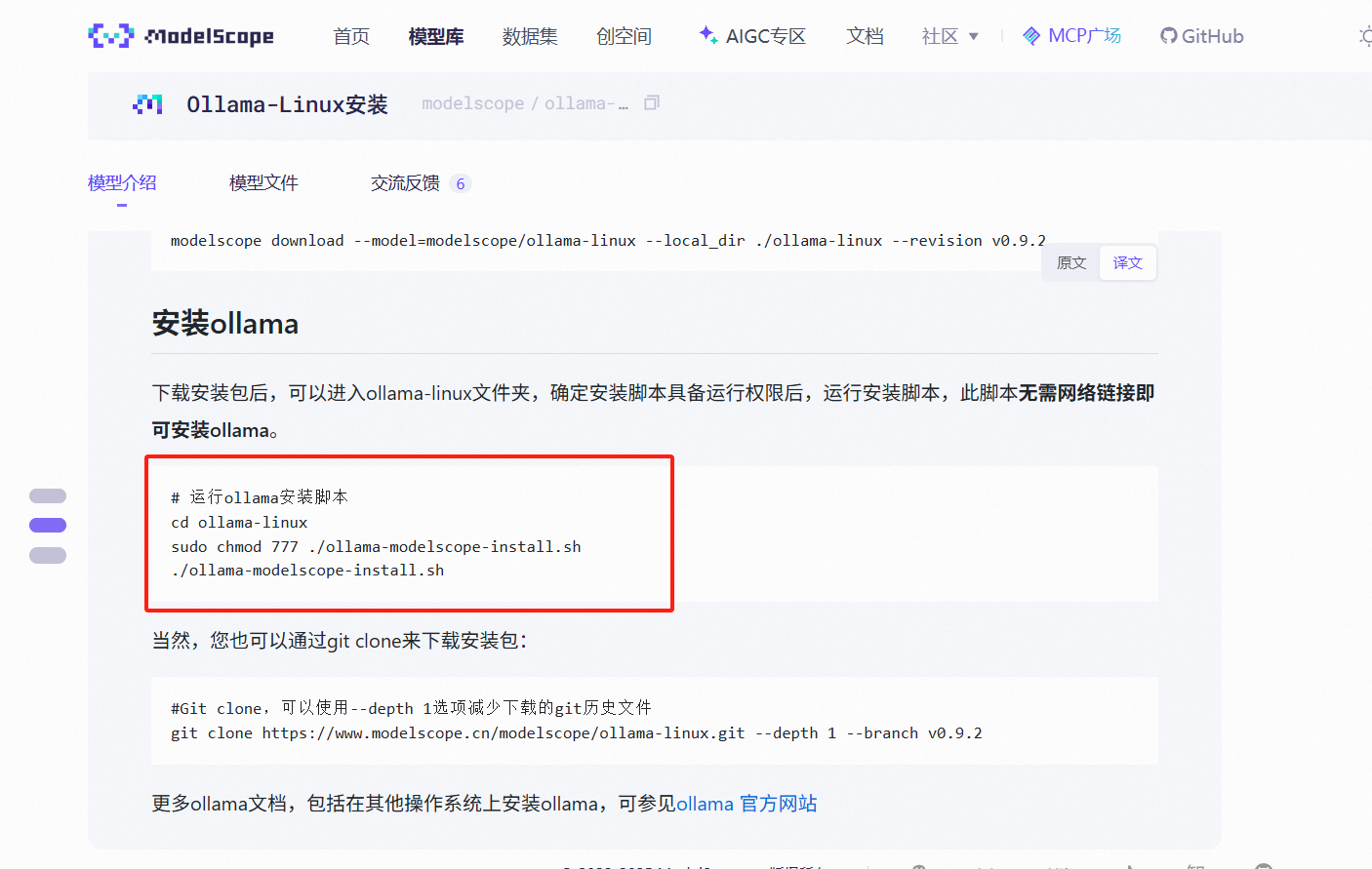
4、 安装Ollama
# 运行ollama安装脚本
cd ollama-linux
sudo chmod 777 ./ollama-modelscope-install.sh
./ollama-modelscope-install.sh这里可以直接参考官网命令
2.1.4 运行Ollama
#启动ollama服务
ollama serve#查看已有本地已有模型(可选)
ollama list拉取模型镜像并运行,这一步根据需求,去ollama官网选择一个模型,复制命令即可,如下:
这里以deepseek-r1为例
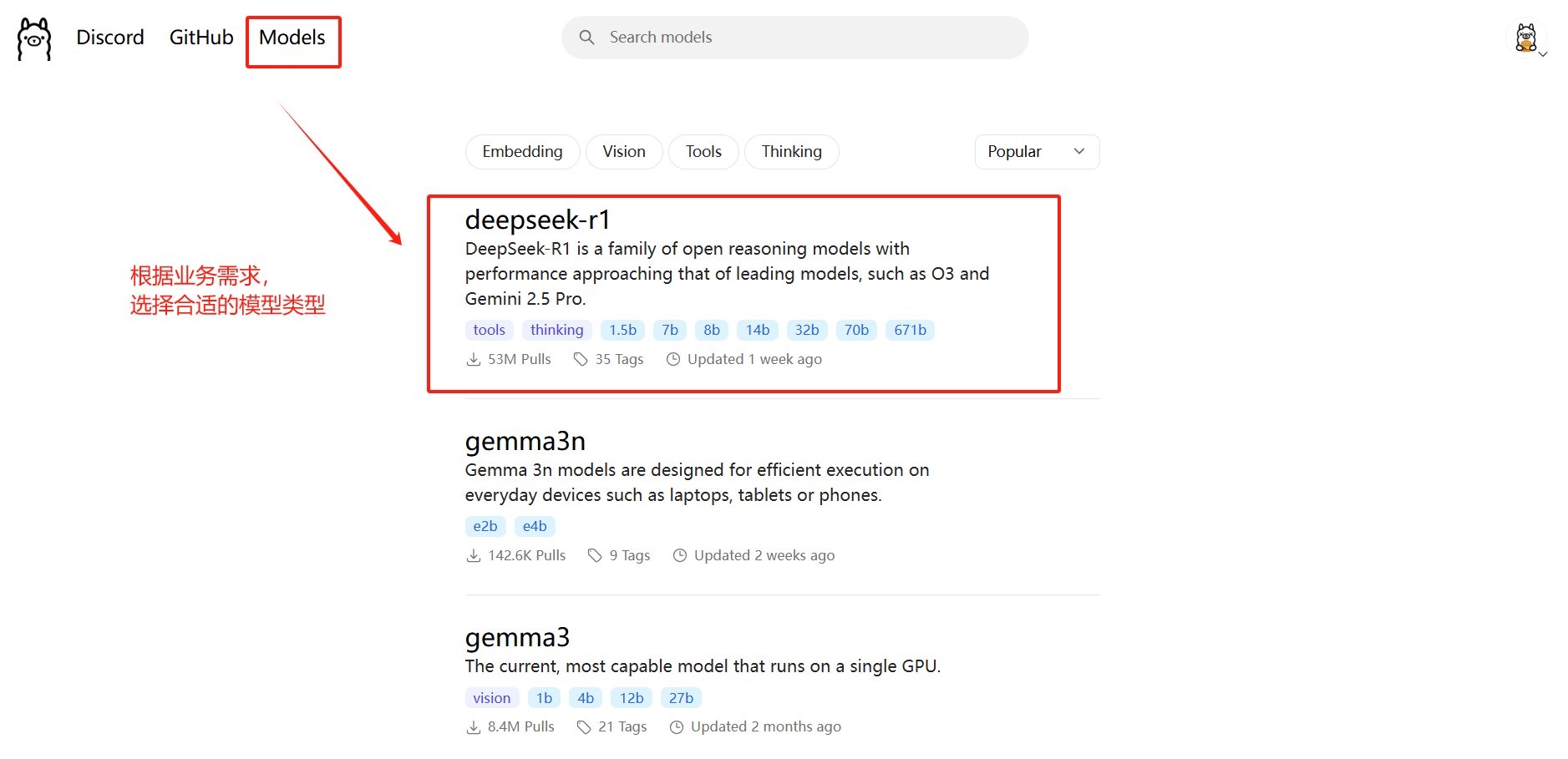
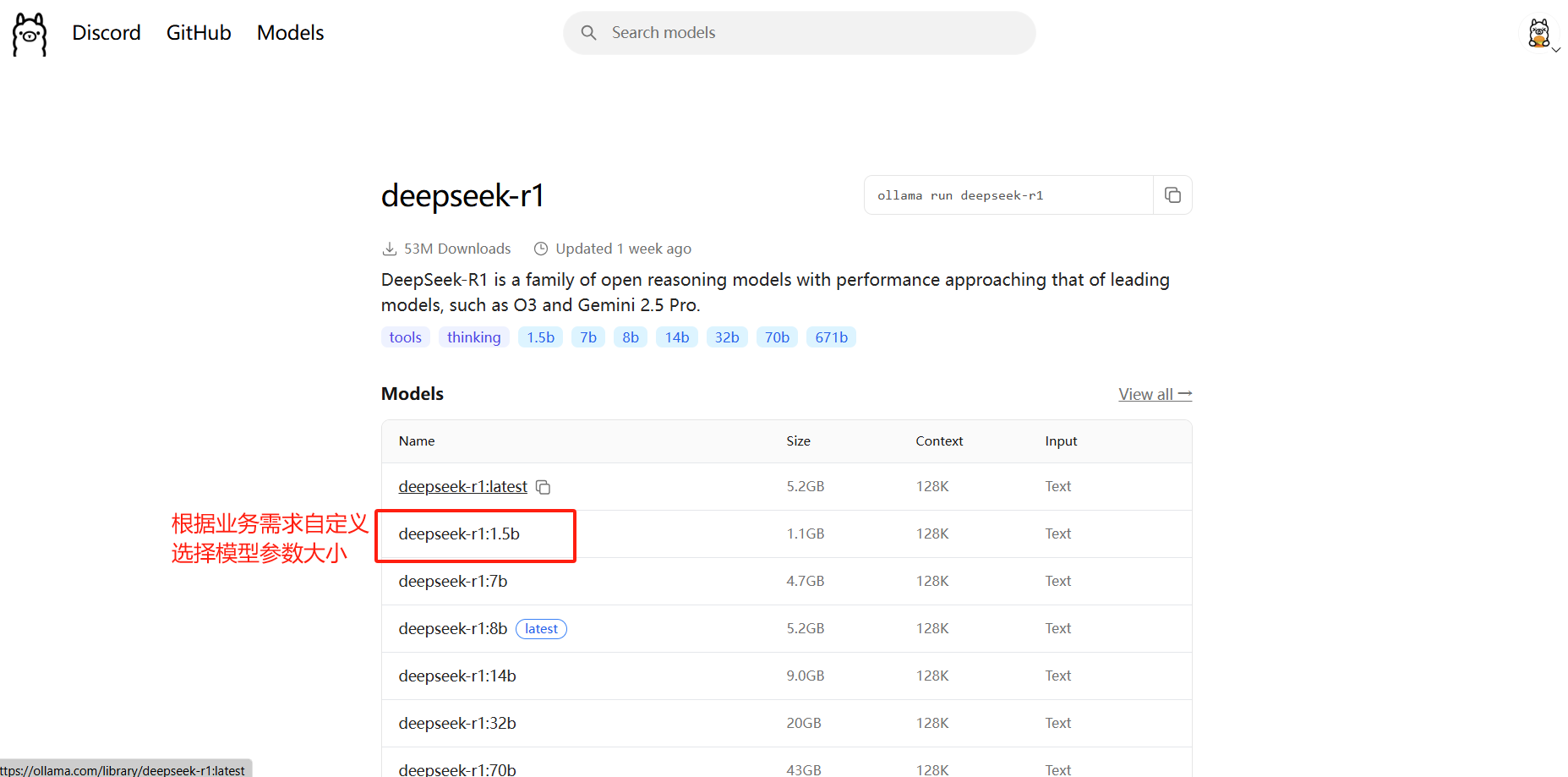
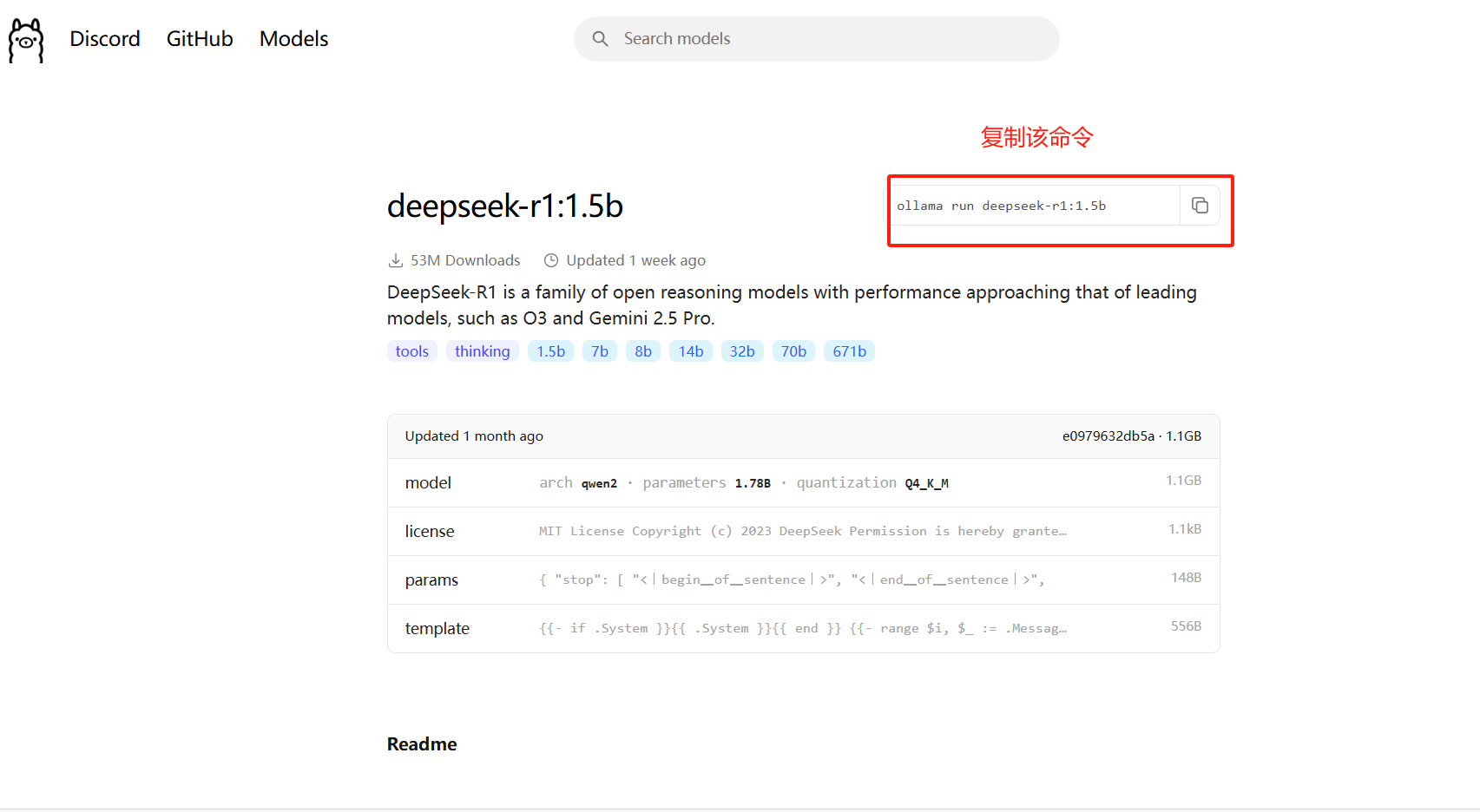
在服务器新开一个终端运行该命令
ollama run deepseek-r1:1.5b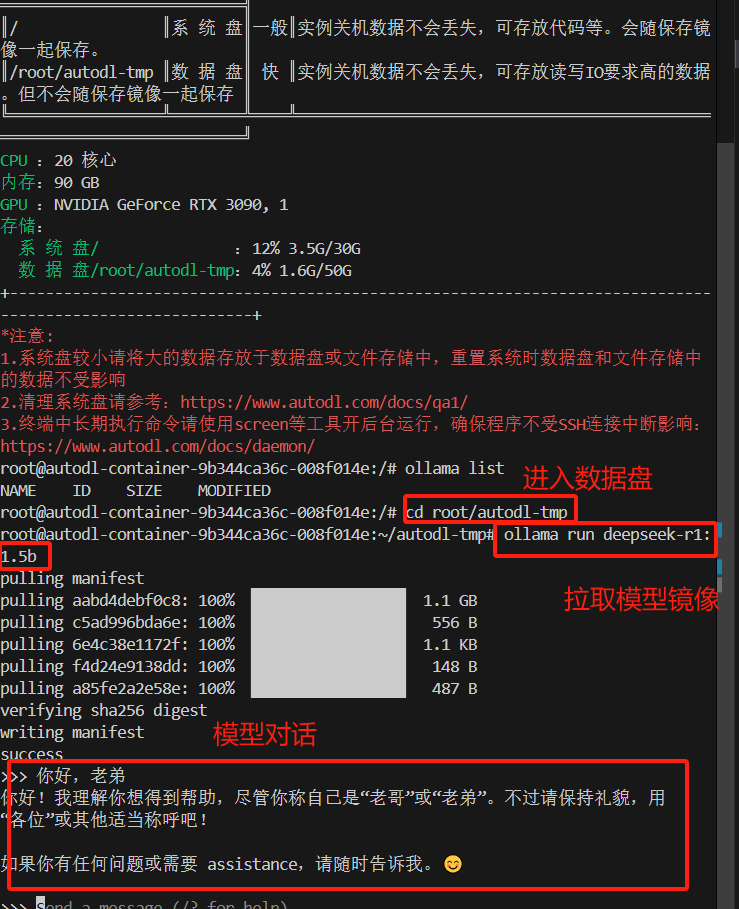
模型拉取成功后,即可进行对话,如果想要退出对话,可执行:
#退出对话
/exit三、适合部署人群
个人开发者
原因:Ollama上的模型大多都是经过量化压缩过的,也就是说在Ollama上下载的原参数大小的模型,下载到本地后的模型实际大小会小很多,所以在部署方面,对模型的配置要求会更低,运行起来也更快,部署方便快捷,并且能够在一卡的服务器上切换多个模型。但是带来问题就是,模型精度会下降,对于大多数企业场景来说,精度是非常重要的因素。
四、Ollama的优缺点
✅ 优点
| 优点 | 说明 |
|---|---|
| 🚀 轻量快速部署 | 一条命令即可运行本地大模型,无需复杂依赖配置 |
| 💾 模型量化压缩 | 多数模型为 4-bit/8-bit 量化,节省显存、下载快 |
| 💻 本地化支持好 | 支持 macOS(包括 M 系列)、Linux 和 Windows WSL |
| 🔄 多模型快速切换 | 可以在单张显卡上快速切换不同模型进行推理 |
| 🧩 支持多种热门模型 | 如 LLaMA、Qwen、Mistral、Gemma、Phi 等 |
| 📦 内置 API 接口 | 自带 REST API,可快速嵌入其他应用 |
| 🔐 数据更安全 | 本地运行,无需上传云端,适合隐私敏感场景 |
❌ 不足
| 不足 | 说明 |
|---|---|
| 🎯 模型精度下降 | 模型多为量化版本,推理速度快但精度较低 |
| 🧠 不支持训练/微调 | 目前仅支持推理,不适合定制任务 |
| 📚 模型/功能相对有限 | 模型版本和数量不如 HuggingFace 丰富;暂不支持复杂 RAG、多模态 |
| 🖥️ 资源依赖依旧存在 | 尽管优化了显存占用,但仍需要一张至少 6~8GB 显存的显卡才流畅运行大型模型 |
| 🧪 生态刚起步 | 插件系统、协同工具、可视化工具尚在发展中,企业级运维支持较弱 |
五、总结
Ollama 适合个人开发者和中小型场景快速部署和本地推理大模型,但在精度、可微调能力和企业级支持方面仍有不足。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)