大模型推理引擎/框架全解析,小白也能轻松上手的大模型部署指南
文章详细介绍了大模型推理引擎与框架的区别,并对比了10款主流工具,按用户类型分类。LMStudio适合零基础用户,llama.cpp和MLC-LLM适合个人开发者,vLLM、TensorRT-LLM等企业级框架提供高性能部署能力。各工具支持不同硬件和优化技术,用户可根据需求选择合适方案。大模型经过漫长的训练,最终需要推理评估,走向实际应用。就像人一样,经过多年的学习,最终需要通过面试,走向社会工作
文章详细介绍了大模型推理引擎与框架的区别,并对比了10款主流工具,按用户类型分类。LMStudio适合零基础用户,llama.cpp和MLC-LLM适合个人开发者,vLLM、TensorRT-LLM等企业级框架提供高性能部署能力。各工具支持不同硬件和优化技术,用户可根据需求选择合适方案。

大模型经过漫长的训练,最终需要推理评估,走向实际应用。就像人一样,经过多年的学习,最终需要通过面试,走向社会工作。
严格意义上,推理引擎和推理框架是不同的,推理引擎是实际执行大模型计算的代码库,提供了推理加速的功能,如PagedAttention、Continuous Batching等。推理框架集成了推理引擎,提供了更加完善的功能,背后实际提供计算的还是推理引擎。但目前业界似乎划分的没有那么明确。
大模型推理部署是大模型走向应用的关键一环,极致优化的推理框架能够缩短延迟、降低成本。
大模型推理技术发展的比较快,目前已有许多开源的大模型推理框架,很多大模型推理框架在2023年出现。
今天给大家介绍一些目前比较主流的大模型推理工具/引擎/框架。
LMStudio、llama.cpp、Ollama、vLLM、SGLang、LMDeploy、Hugging Face TGI、TensorRT-LLM、MLC-LLM、Xinference是比较有代表性的几个。
LM Studio、Ollama属于开箱即用的工具。
llama.cpp、vLLM、SGLang、LMDeploy、Hugging Face TGI、TensorRT-LLM、MLC-LLM、Xinference是推理引擎或者框架。
可以根据应用场景和使用难易程度简单的分为三类:
不会编程的普通用户:LM Studio、Ollama
个人开发者:llama.cpp、Ollama
企业用户:vLLM、SGLang、LMDeploy、TensorRT-LLM、MLC-LLM、Hugging Face TGI、Xinference。
其中使用起来最简单的是LMStudio,提供了图像化界面,即使不会编程也可以轻松使用。
Ollama使用也比较简单,对于普通用户提供了命令行,对于开发者,提供了API。
对于需要部署到生产环境中的企业用户,vLLM、SGLang、LMDeploy、TensorRT-LLM、MLC-LLM、Hugging Face TGI、Xinference这些框架提供了更灵活、可分布式部署的服务。
01 |
LM Studio

LM Studio是本地部署大模型的工具,提供了可视化的图形界面,适合没有编程经验的人使用,极大降低了大模型在本地部署的门槛,支持Windows、macOS、Linux系统。LM Studio是一个桌面应用程序,下载安装包安装后即可使用。
官方文档:
https://lmstudio.ai/docs/
02 |
llama.cpp

llama.cpp从其名字就能看出,它是一个使用C/C++进行开发的大模型推理引擎,最初是为了实现LLaMA系列模型的本地高效推理,现在也支持其他的大模型。针对CPU进行了优化,支持低性能硬件,如在笔记本电脑和手机上部署大模型。
核心特点:
- 通过 ARM NEON、Accelerate 和 Metal 框架进行了优化
- 支持x86架构AVX、AVX2、AVX512 和 AMX
- 支持1.5位、2 位、3 位、4 位、5 位、6 位和 8 位整数量化,以实现更快的推理和减少内存使用
- 支持英伟达、AMD、摩尔线程GPU
- 支持 Vulkan 和 SYCL 后端
- CPU 与 GPU 混合推理,以部分加速大于总显存容量的模型
开源时间:[2023.03]
最新版本:[b6838]
github star:[88.3k]
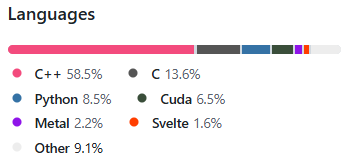
目前有1302位贡献者。

主要使用C/C++开发,所以推理速度很快。
github地址:
https://github.com/ggml-org/llama.cpp
03 |
Ollama

Ollama是构建在llama.cpp上的大模型本地部署工具。支持maxOS/Windows/Linux系统。它支持通过下载软件安装包,以可视化的方式安装,使用起来比较简单,可以把它看作一个软件,安装后通过命令行的方式使用。也支持Docker、python包的方式安装。
开源时间:[2023.06]
最新版本:[v0.12.6]
github star:[155k]
目前有538位贡献者。
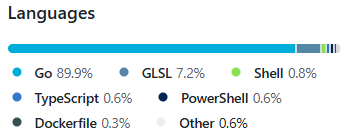
主要开发语言为Go。
github地址:
https://github.com/ollama/ollama
04 |
vLLM
vLLM 是一个开源的大模型推理引擎,快速且易于使用。vLLM起源于论文(《Efficient Memory Management for Large Language Model Serving with PagedAttention》),论文中提出了PagedAttention。vLLM 最初由加州大学伯克利分校的Sky Computing Lab开发,如今已发展为一个由开源社区驱动的项目,吸引了来自学术界和工业界的贡献。

核心特点:
- PagedAttention
- Continuous Batching
- 通过CUDA/HIP graph实现快速模型执行
- GPTQ, AWQ, AutoRound, INT4, INT8, and FP8量化
- 优化的 CUDA 内核,包括与 FlashAttention 和 FlashInfer 的集成
- Speculative decoding
- Chunked prefill
开源时间:[2023.06]
最新版本:[v0.11.0]
github star:[60.9k]
贡献者非常多,已经有1728位贡献者。
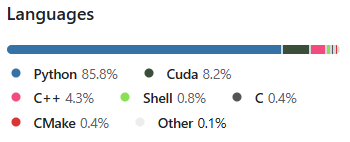
主要开发语言为python。
github地址:
https://github.com/vllm-project/vllm
05 |
SGLang

SGLang最初是由斯坦福大学和加州大学伯克利分校的团队开源的,是一个高性能的大语言模型和视觉语言模型推理引擎。它旨在在各种环境中提供低延迟和高吞吐量的推理,从单个 GPU 到大型分布式集群。SGLang起源于论文《SGLang: Efficient Execution of Structured Language Model Programs》),论文中提出了RadixAttention,带来了5倍推理速度提升。
SGLang提出的零开销CPU调度(zero-overhead CPU scheduler)降低了CPU的调度开销。

核心特点:
- RadixAttention
- zero-overhead CPU scheduler
- PD分离
- speculative decoding
- continuous batching
- paged attention
- tensor/pipeline/expert/data并行
- 结构化输出
- chunked prefill
- FP4/FP8/INT4/AWQ/GPTQ量化
- multi-LoRA batching
开源时间:[2024.01]
最新版本:[v0.5.3]
github star:[19.4k]
目前有797位贡献者。
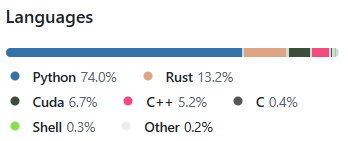
主要开发语言为python,还使用了13.2%的Rust。
github地址:
https://github.com/sgl-project/sglang
06 |
TensorRT-LLM
TensorRT LLM 是由英伟达开源的推理引擎,专门为英伟达GPU设计开发的,用于优化大语言模型(LLM)的推理。它提供了最先进的优化,包括自定义注意力内核、inflight batching、paged KV caching、量化(FP8、FP4、INT4 AWQ、INT8 SmoothQuant 等)、speculative decoding等功能,以高效地在 NVIDIA GPU 上执行推理。
核心特点:
- 自定义注意力内核(custom attention kernel)
- inflight batching
- paged KV caching
- 支持FP8,FP4,INT4 AWQ,INT8 SmoothQuant等量化
- speculative decoding
开源时间:[2023.09]
最新版本:[v1.0.0]
github star:[12k]
目前有349位贡献者。

主要开发语言为C++/python。
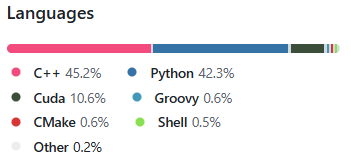
github地址:
https://github.com/NVIDIA/TensorRT-LLM
07 |
LMDeploy

LMDeploy由上海人工智能实验室开源的大模型推理引擎,支持国产芯片。LMDeploy 通过引入关键功能,如continuous batching、blocked KV cache, dynamic split&fuse、张量并行等技术,实现了高吞吐。
LMDeploy中开发了两个推理引擎:TurboMind和PyTorch。这两个推理引擎的侧重点不同,前者具有极致优化的推理性能,而后者使用Python开发,旨在降低开发者的使用门槛。
核心特点:
- continuous batching
- blocked KV cache
- dynamic split&fuse
- 张量并行
- 高性能的CUDA内核
- 支持AWQ/GPTQ、SmoothQuant、KV Cache INT4/INT8量化
开源时间:[2023.06]
最新版本:[v0.10.1]
github star:[7.2k]
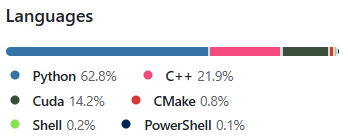
目前有136位贡献者。
主要开发语言为python,还使用了21.9%的C++和14.2%的Cuda。
github地址:
https://github.com/InternLM/lmdeploy
08 |
Hugging Face TGI
TGI(Text Generation Inference )是Hugging Face开源的大模型推理引擎。
核心特点:
- 支持生产环境(Open Telemetry, Prometheus metrics)
- 张量并行
- 使用SSE实现token流式传输
- Continuous batching
- FlashAttention
- PagedAttention
- bitsandbytes、GPTQ、EETQ、AWQ、Marlin、FP8
- Safetensors 权重加载
- 大模型水印
- speculative decoding
- 支持指定输出格式
- 支持英伟达GPU、AMD GPU、Intel GPU,还支持亚马逊AI芯片Inferentia、Intel AI芯片Gaudi、谷歌TPU
- 支持微调
开源时间:[2022.10]
最新版本:[v3.3.6]
github star:[10.6k]
目前有165位贡献者。
主要开发语言为python,还使用了16.2%的Rust。
github地址:
https://github.com/huggingface/text-generation-inference
09 |
MLC-LLM
开源时间:[2023.04]
最新版本:[v0.19.0]
github star:[21.5k]
MLC-LLM是AI大神陈天奇开源的,是一个面向大语言模型的机器学习编译器和高性能部署引擎。该项目的使命是使每个人都能在自己的平台上本地开发、优化和部署 AI 模型。
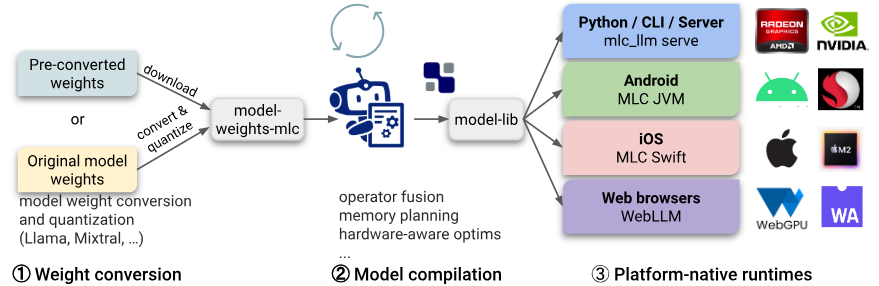
MLC-LLM工作流
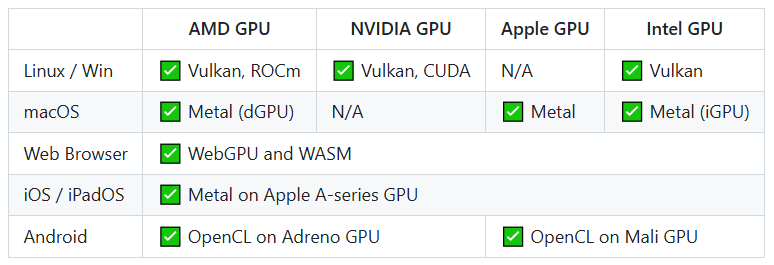
MLC-LLM支持多种GPU和操作系统:
目前有148位贡献者。
主要开发语言为python,还使用了25.5%的C++。
github地址:
https://github.com/mlc-ai/mlc-llm
10 |
Xinference

开源时间:[2023.07]
最新版本:[v1.11.0.post1]
github star:[8.7k]
Xorbits Inference(Xinference)是一个功能强大的分布式推理框架,支持语言、语音识别和多模态模型。
Xinference支持不同的推理引擎,用户选择模型后,Xinference 会自动选择合适的引擎。
可以通过多种方式使用Xinference:Web UI、命令行、python等。
核心特点:
- 多引擎架构设计,支持多种推理引擎,如vLLM、SGLang、llama.cpp等
- 推理时根据模型以及硬件资源自动选择最优的推理引擎
目前有148位贡献者。
主要开发语言为python,还使用了10.9%的JavaScript。

github地址:
https://github.com/xorbitsai/inference
总结
各个大模型推理框架也在不断的更新,一些新的推理技术会逐渐支持,只是开发的快慢而已,就看谁的开源生态更繁荣了。
目前很多大模型框架已支持PagedAttention、Continuous Batching、Speculative Decoding、Chunked Prefill等特性。
LM Sdudio不需要任何编程经验就可以使用,非常适合没有编程经验的人在本地快速部署大模型。
Ollama使用起来也非常简单,不懂编程也没关系,只需要了解命令行的使用就行,适合不会编程的人、个人开发者和研究者在本地部署大模型。
TensorRT-LLM适合在英伟达GPU上部署大模型的开发者和企业,本地部署和生产环境部署都可以。
LMDeploy适合需要在国产芯片部署大模型的开发者和企业,本地部署和生产环境部署都可以。
另外,vLLM和SGLang是目前使用较多的大模型推理框架,并且在github上有较多的开发者参与项目的更新,新特性支持更快。本地部署和生产环境部署都可以。
Xinference适合企业进行生产环境的分布式部署。
llama.cpp 针对 CPU 进行了深度优化,适合个人开发者在资源有限的设备(例如树莓派、笔记本电脑、手机等)上部署大模型。
MLC-LLM的适用场景与llama.cpp类似,也适合在各种设备上本地部署大模型。
AI时代,未来的就业机会在哪里?
答案就藏在大模型的浪潮里。从ChatGPT、DeepSeek等日常工具,到自然语言处理、计算机视觉、多模态等核心领域,技术普惠化、应用垂直化与生态开源化正催生Prompt工程师、自然语言处理、计算机视觉工程师、大模型算法工程师、AI应用产品经理等AI岗位。
掌握大模型技能,就是把握高薪未来。
那么,普通人如何抓住大模型风口?
AI技术的普及对个人能力提出了新的要求,在AI时代,持续学习和适应新技术变得尤为重要。无论是企业还是个人,都需要不断更新知识体系,提升与AI协作的能力,以适应不断变化的工作环境。
因此,这里给大家整理了一份《2025最新大模型全套学习资源》,包括2025最新大模型学习路线、大模型书籍、视频教程、项目实战、最新行业报告、面试题等,带你从零基础入门到精通,快速掌握大模型技术!
由于篇幅有限,有需要的小伙伴可以扫码获取!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。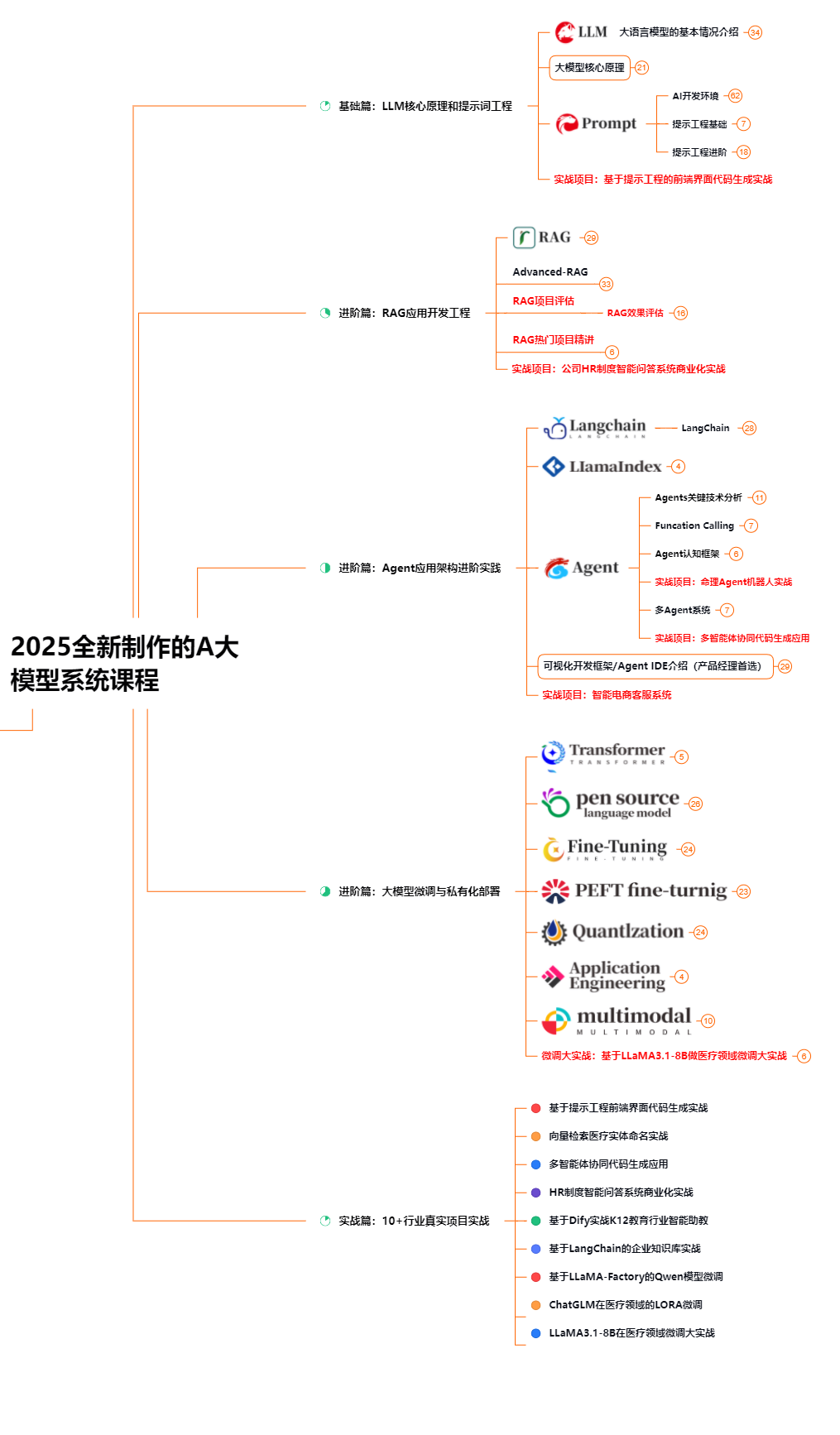
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
5. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

为什么大家都在学AI大模型?
随着AI技术的发展,企业对人才的需求从“单一技术”转向 “AI+行业”双背景。企业对人才的需求从“单一技术”转向 “AI+行业”双背景。金融+AI、制造+AI、医疗+AI等跨界岗位薪资涨幅达30%-50%。
同时很多人面临优化裁员,近期科技巨头英特尔裁员2万人,传统岗位不断缩减,因此转行AI势在必行!

这些资料有用吗?
这份资料由我们和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


大模型全套学习资料已整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 16
16 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)