克服AI幻觉:搭建分层验证框架,结合技术手段与逻辑方法论
本文提出了一套分层验证框架来应对AI幻觉问题,确保输出的科学性和严谨性。框架包含前置防御(可信数据源绑定、提示工程)、生成过程验证(多模型交叉检验、逻辑链拆解)、后置校正(置信度标注、科学方法论应用)三个层次,并推荐了RAG增强、Fact-Check API等系统化工具。文章强调领域特化、伦理界限和透明化设计,建议通过量化指标监控和对抗训练持续改进,最终实现从"黑箱生成"到&q
在应对AI幻觉并确保输出的科学性、严谨性时,可采用一种分层验证框架,结合技术手段与逻辑方法论。以下是系统性解决方案:
以下是文章内容的系统概括及核心思路的可视化: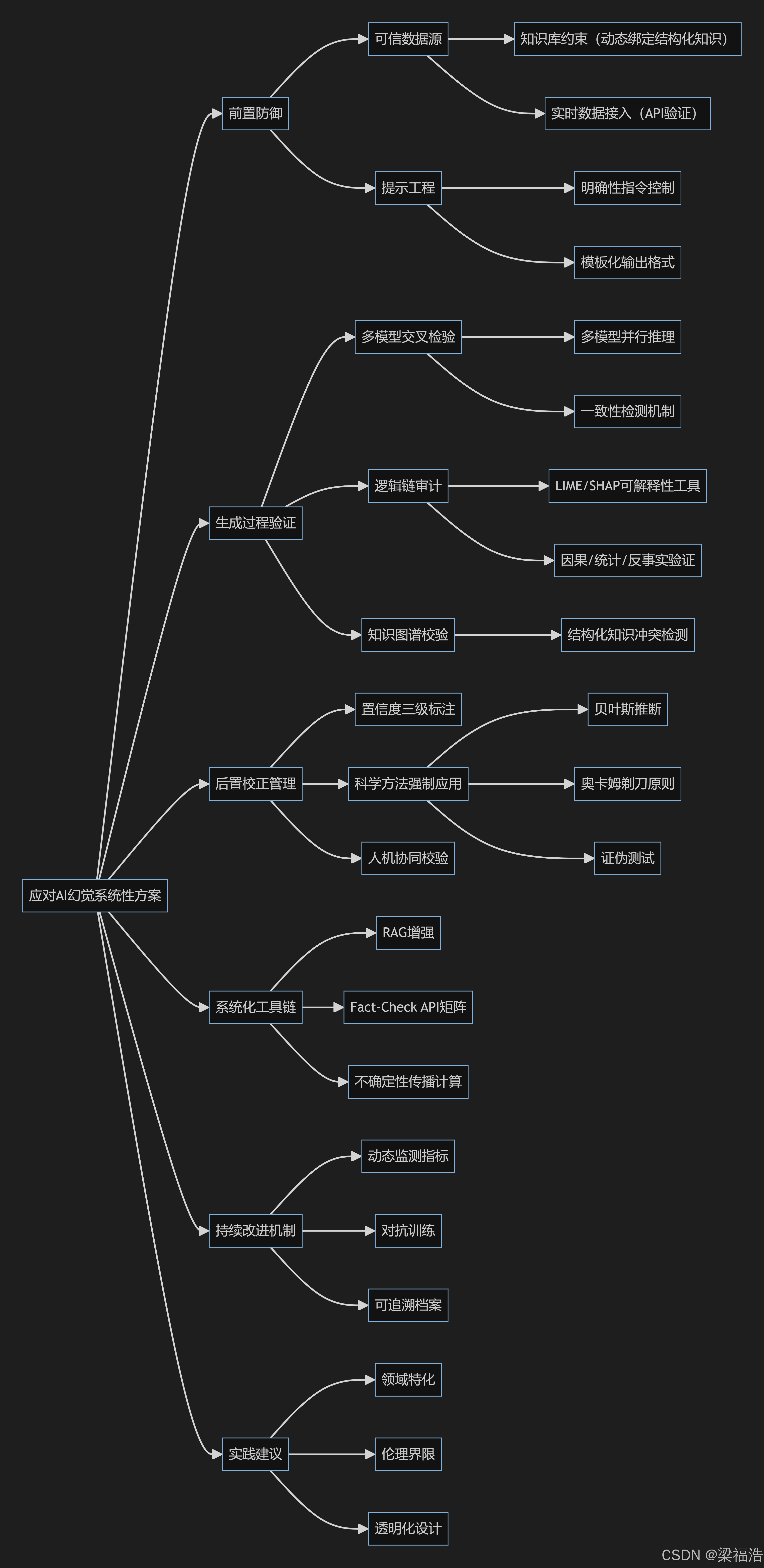
一、前置防御:输入与数据层面的控制
- 可信数据源的绑定
-
知识库约束(Knowledge Grounding):将AI的生成过程与结构化知识库(如行业报告、学术论文、权威数据库)动态绑定,优先从可靠来源抽取信息。
-
实时数据接入(Live Data Injection):接入API实时验证数据(如天气、金融数据),替换过时或推测性内容。
- 提示工程(Prompt Engineering)
- 通过明确性指令限定AI行为,例如:
"基于2023年《自然》期刊的实证研究,分步骤推导结论;若信息不足,明确标注不确定性"
- 模板化输出:强制生成内容包含数据来源、推理逻辑和假设说明。
二、生成过程中的验证机制
- 多模型交叉检验(Multi-Agent Verification)
- 部署多个独立模型(如GPT-4、Claude、专家系统)对同一问题进行并行推理,通过投票机制或一致性检测(Consensus Check)筛选可信结论。
- 逻辑链拆解(Chain-of-Thought Audit)
-
要求AI展示推理过程,使用可解释性工具(如LIME、SHAP)验证逻辑节点是否符合以下标准:
-
**因果性**:是否存在证据支撑的因果关系链; -
**统计显著性**:数据结论是否通过假设检验(如p<0.05); -
**反事实分析**:若替换关键变量,结论是否仍成立。
- 知识图谱嵌入(Knowledge Graph Embedding)
- 将输出内容映射到结构化知识图谱,检测是否存在与既有知识冲突的节点(如断言“太阳绕地球转”触发科学常识警报)。
三、后置校正与不确定性管理
- 置信度标注系统
-
AI需对每条断言标注置信度级别(如:
-
Level 1:直接引用权威数据
-
Level 2:基于统计模型的合理推断
-
Level 3:缺乏证据的假设性观点)
-
- 科学方法论强制应用
-
在信息不足时,强制启用以下方法:
-
**贝叶斯推断**:基于先验分布和似然函数计算后验概率; -
**奥卡姆剃刀原则**:优先选择假设最少的解释; -
**证伪测试**:列举可能推翻当前结论的条件。
- 人类专家协同校验
- 高风险领域(医疗、法律)设置人工审核节点,结合Hybrid Intelligence框架,将AI输出与专家知识库匹配,触发复核的阈值可通过异常检测算法动态调整。
四、系统化工具链示例
- RAG增强(Retrieval-Augmented Generation)
- 将生成式模型与检索系统结合,每个生成步骤前自动检索最新论文、专利库、行业白皮书作为事实基准。
- Fact-Check API矩阵
- 调用权威事实核查服务(如Google Fact Check Tools、Full Fact)接口,对人物、事件、数据类陈述进行即时验证。
- 不确定性传播计算器
- 对涉及数值推理的内容(如经济预测),实施误差传递计算,自动生成置信区间(如“GDP增速预计5.2%±0.8%,95% CI”)。
五、持续改进机制
- 动态评估指标
- 通过幻觉率(Hallucination Rate)、**事实一致性得分(Factual Consistency Score)**等量化指标监控系统表现。
- 对抗训练(Adversarial Training)
- 引入故意包含谬误的测试用例,训练模型识别矛盾陈述(如“水在150°C沸腾”触发压强条件核查)。
- 可追溯性档案
- 为每个结论构建可追溯证据链(Proof Chain),支持回溯到具体数据源、计算步骤和验证记录。
实践建议
-
领域特化:在专业领域(如医学)需定制知识约束规则,禁用通用语料库中的模糊类比;
-
伦理界限:对无法实证的问题(如哲学思辨)明确标注观点属性,避免伪装成事实;
-
透明化设计:向用户暴露置信度、数据来源及潜在利益冲突声明(如训练数据的时间范围限制)。
通过上述框架,可将AI输出从“黑箱生成”升级为“可验证的知识生产过程”,在技术创新与严谨性之间取得平衡。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)