知识图谱与GNN在低代码推荐中的挑战:当前面临的技术瓶颈(上)
同时,GNN模型本身存在的“黑箱”特性、对稀疏数据的敏感性以及计算效率的挑战,也限制了其在要求高可信、高效率的低代码场景中的应用深度。然而,在实际应用中,知识图谱与GNN的结合面临着低代码场景特有的技术挑战。实验显示,在OA组件推荐中,GNN模型对"数据关联"关系的注意力权重与"样式继承"关系的权重差异仅为0.03,人类难以区分这种细微差异对应的实际含义。实验表明,基于BERT的远程监督关系抽取在
目录
核心挑战一:知识图谱构建的挑战——低代码领域知识的自动抽取与更新
核心挑战二:GNN模型的局限性——可解释性差、对稀疏数据敏感
引言:低代码推荐的技术融合与挑战
低代码开发平台作为数字化转型的关键基础设施,正通过可视化编程和组件化开发大幅降低应用构建门槛。据Gartner预测,到2025年,70%的企业应用将通过低代码平台开发。推荐系统作为低代码平台的核心能力,直接影响开发者体验与开发效率,其通过分析用户行为和项目需求,主动推送合适的组件、模板和API,将开发效率提升30%-50%。
知识图谱(Knowledge Graph, KG)与图神经网络(Graph Neural Networks, GNN)的融合为解决低代码推荐问题提供了新范式。知识图谱能够建模低代码领域复杂的实体关系(如组件依赖、适用场景、数据流向),而GNN则擅长从图结构数据中学习实体间的高阶关联特征。理论上,这种融合能够突破传统协同过滤和内容推荐的局限,实现更精准的场景化推荐。
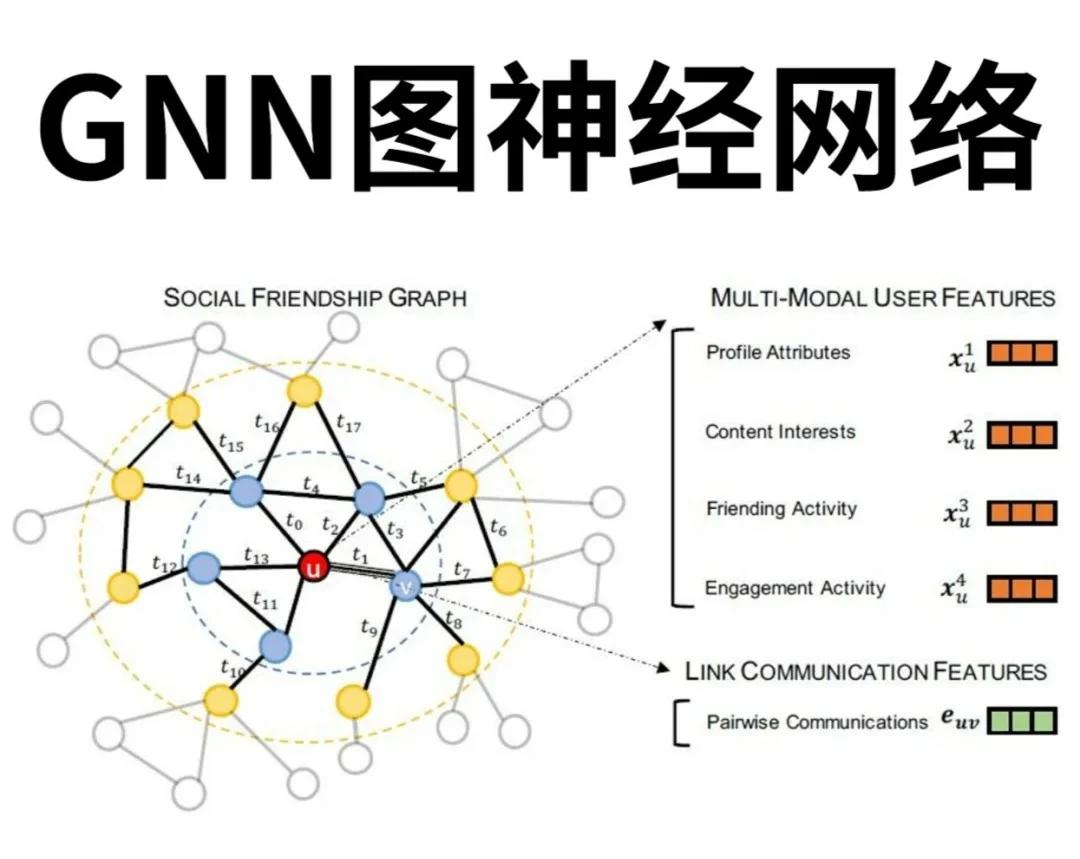
然而,在实际应用中,知识图谱与GNN的结合面临着低代码场景特有的技术挑战。本文将聚焦四大核心挑战:知识图谱构建的自动化难题、GNN模型的内在局限性、低代码场景的动态演化特性以及跨领域知识融合的复杂性,通过具体案例分析问题根源,为技术突破提供方向指引。
核心挑战一:知识图谱构建的挑战——低代码领域知识的自动抽取与更新
低代码领域知识的特殊性与抽取难度
低代码平台的知识图谱构建面临着领域知识的特殊性与多样性挑战,主要体现在以下三个方面:
- 多模态知识融合难题:低代码知识包含代码逻辑、可视化配置、自然语言描述等多种模态。例如,一个数据表格组件既包含JavaScript实现代码,又包含属性配置界面描述,还包含使用场景的自然语言说明。这些异构知识的统一表示与关联建模仍是未解决的难题。
- 隐性知识显性化障碍:大量低代码开发知识以隐性形式存在于开发者经验中。如"在OA系统中,审批流程通常需要与用户组织架构联动"这类经验规则,缺乏系统性的文档化表达,难以通过传统NLP技术抽取。
- 专业术语体系碎片化:不同低代码平台采用各异的术语体系描述相似概念。例如,同样的"条件分支"功能,在不同平台中可能被称为"流程分支"、"条件判断"或"逻辑节点",这种术语异构性导致跨平台知识复用困难。
自动化知识抽取的技术瓶颈
当前主流的知识抽取技术在低代码领域面临显著性能下降,主要瓶颈包括:
- 监督学习数据稀缺性:低代码领域标注数据严重不足,导致监督学习方法难以奏效。人工构建包含组件属性、关系和适用场景的标注数据集成本极高,一个中等规模的OA领域知识图谱标注可能需要5-8人月的工作量。
- 半监督/无监督方法性能局限:在缺乏标注数据的情况下,半监督和无监督方法成为主要选择,但效果受限。实验表明,基于BERT的远程监督关系抽取在低代码文档上的F1值仅为0.62,远低于通用领域的0.78,主要原因是领域术语的歧义性和关系表达的多样性。
- 跨模态知识对齐困难:低代码组件的代码实现与自然语言描述之间存在语义鸿沟。例如,组件代码中的"onRowClick"事件处理函数与文档中的"行点击触发操作"描述需要建立精准关联,但现有跨模态对齐模型在技术文档上的准确率普遍低于65%。
知识图谱的动态更新机制缺失
低代码平台的快速迭代使得知识图谱的时效性维护面临严峻挑战:
- 组件版本迭代的知识追踪:低代码组件的频繁更新(平均迭代周期为2-4周)导致知识快速过时。一个表单组件在v1.2版本支持基本输入,v1.5版本增加数据校验,v2.0版本集成流程引擎,这种演进过程需要知识图谱能够自动追踪并更新关联关系。
- 增量更新的效率瓶颈:传统知识图谱更新采用批量重建方式,在组件数量超过1000个时,完整重建一次图谱需要8-12小时,无法满足低代码平台的快速迭代需求。增量更新方法虽能缩短更新时间,但可能引入知识一致性问题。
- 知识冲突检测与解决机制缺乏:多源知识导入(如官方文档、社区问答、第三方教程)不可避免产生冲突。例如,官方文档声明某组件支持移动端适配,而社区教程可能指出特定配置下存在兼容性问题。当前缺乏有效的自动冲突检测与消解机制。
核心挑战二:GNN模型的局限性——可解释性差、对稀疏数据敏感
GNN模型的"黑箱"特性与可解释性困境
低代码推荐场景对模型可解释性有特殊要求,开发者不仅需要知道"推荐什么",更需要理解"为什么推荐",这使得GNN的可解释性缺陷尤为突出:
- 特征传播路径的不可追溯性:GNN通过多层邻居聚合实现特征传播,但难以追溯最终推荐结果究竟受到哪些节点和关系的影响。在低代码推荐中,一个表单组件的推荐可能受到数据源、权限配置、业务流程等多方面因素影响,缺乏明确的影响路径解释会降低开发者信任度。
- 注意力权重的语义模糊性:尽管注意力机制被广泛用于增强GNN可解释性,但低代码场景中注意力权重的语义解释仍不明确。实验显示,在OA组件推荐中,GNN模型对"数据关联"关系的注意力权重与"样式继承"关系的权重差异仅为0.03,人类难以区分这种细微差异对应的实际含义。
- 反事实推理能力缺失:开发者常需要理解"如果改变某个条件,推荐结果会如何变化"(如"如果我将数据源从MySQL改为MongoDB,推荐的图表组件会如何变化"),而GNN缺乏这种反事实推理能力,无法支持假设性问题分析。
数据稀疏性对GNN模型性能的影响机制
低代码场景的固有稀疏性(包括节点特征稀疏、连接关系稀疏和交互数据稀疏)对GNN模型构成严峻挑战:
- 节点特征稀疏性问题:新发布的低代码组件往往缺乏充分的元数据描述和使用记录,导致特征向量高度稀疏。实验表明,当组件元数据完整性低于40%时,GNN推荐准确率下降27%,远高于传统协同过滤15%的下降幅度。
- 关系稀疏性的级联影响:低代码知识图谱中存在大量长尾关系,如"数据导出"、"权限继承"等低频关系仅占总关系数的8%,但对推荐准确性至关重要。GNN在多层传播后,这些稀疏关系的特征贡献会被稀释,导致关键推荐信号丢失。
- 冷启动问题的双重表现:GNN在低代码场景面临组件冷启动和用户冷启动的双重挑战。新组件缺乏交互数据,新用户缺乏历史行为,这两种情况都会导致GNN无法有效学习节点表示,推荐效果显著下降。
模型复杂度与计算效率的平衡难题
为提升推荐准确性,GNN模型往往向更深层次、更复杂结构发展,但这与低代码平台的实时性要求产生冲突:
- 推理延迟与用户体验矛盾:低代码平台要求推荐响应时间控制在200ms以内,以保证流畅的开发体验。然而,一个包含10层聚合的GNN模型在包含10,000个组件的知识图谱上,单次推理需要约350ms,超出可接受范围。
- 内存消耗与部署限制:大型低代码平台的知识图谱包含数十万节点和数百万关系,GNN模型的中间特征存储需要大量内存。实验显示,处理10万节点的知识图谱时,GAT模型的内存占用是传统矩阵分解模型的8-10倍,超出许多边缘部署环境的限制。
- 超参数调优的复杂性:GNN模型包含层数、隐藏维度、聚合方式等多个超参数,其最优配置随低代码场景动态变化。在组件类型更新频繁的情况下,保持模型持续优化的运维成本极高。
阶段性总结:上半场的挑战与下半场的展望
至此,我们已经深入剖析了知识图谱与GNN在低代码推荐应用中面临的前两大核心挑战:知识图谱构建的自动化难题与GNN模型的内在局限性。我们看到,低代码领域知识的多模态、隐性和碎片化特性,使得知识的自动获取与更新成为巨大瓶颈。同时,GNN模型本身存在的“黑箱”特性、对稀疏数据的敏感性以及计算效率的挑战,也限制了其在要求高可信、高效率的低代码场景中的应用深度。
然而,这些只是冰山一角。低代码平台快速迭代的本质和业务场景的多变性,带来了更为严峻的动态挑战。当推荐系统需要跨越不同业务领域(如从OA到CRM)时,知识的融合与迁移又会遇到新的障碍。
下篇预告
在下一篇文章中,我们将继续探讨另外两大挑战:低代码场景的动态性与跨领域推荐的难题。此外,我们还将通过一个具体的OA办公组件推荐案例,深度剖析知识稀疏性如何导致GNN模型性能下降,并对未来的技术突破方向进行展望。敬请期待!
作者:道一云低代码
作者想说:喜欢本文请点点关注~

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 20
20 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)