YOLOv8实战(上) - 从零构建你的专属商品检测器
本文介绍了YOLOv8实战项目中异构数据集融合的关键技术。主要内容包括:1) 分析VOC与YOLO两种数据格式的核心差异,重点解析了VOC的XML标注结构和YOLO的归一化坐标特点;2) 提出多源数据集整合方案,通过自动化脚本解决类别ID映射冲突问题;3) 详细说明从VOC到YOLO格式的转换流程,包括坐标归一化处理和数据结构重组。该方案能有效提升模型在复杂场景下的泛化能力,为智能零售等实际应用提

前言
Hello,大家好,我是
GISer Liu😁,一名热爱AI技术的GIS开发者。本系列是作者参加DataWhale 2025年6月份Yolo原理组队学习的技术笔记文档,这里整理为博客,希望能帮助Yolo的开发者少走弯路!
🚀 欢迎来到YOLOv8实战系列!在目标检测项目中,我们常常面临数据集多样、格式不一的挑战。如何将来自不同源(如不同视角、不同标注格式)的数据高效地整合,并训练出一个能识别多种场景的强大模型?
本文是YOLOv8实战系列的上篇,旨在解决这个核心问题。我们将手把手带你:
- 玩转异构数据集:深入理解VOC与YOLO两种主流数据格式,并掌握将它们融合的实用技巧。
- 攻克ID映射难题:通过自动化脚本解决多数据集类别ID冲突的关键问题,为模型训练扫清障碍。
- 定制化模型训练:从环境搭建到参数配置,一步步完成YOLOv8自定义模型的训练,并学会解读训练结果。
无论你是刚接触YOLO,希望完整跑通一个项目的在校学生,还是希望提升数据集处理与模型训练能力的工程师,本文都将为你提供一份详尽的、可复现的操作指南。OK, 让我们开始构建自己的专属检测器吧!
一、 项目概述:从需求到准备
1. 课程引言
③ 项目背景:YOLO Master与智能零售结算系统的实际需求
本次实战源于DataWhale的YOLO Master项目,目标是模拟一个智能零售结算系统的核心功能。先说说我们的应用场景:

在无人零售柜,当顾客完成选购,系统需要通过摄像头快速、准确地识别所有商品并自动结算。
这就对我们的目标检测模型提出了很高的要求。
③ 学习目标:为何要合并数据集?——提升模型泛化能力的关键
在现实场景中,单一的数据集往往存在局限性。例如,我们拥有的数据集可能只包含从上往下(俯视)拍摄的商品图片,而实际应用中摄像头可能是平视的。为了让模型能够应对不同视角、光照和背景,一个至关重要的策略就是合并多个不同来源的数据集。
通过融合不同数据集的优势,我们可以极大地提升模型的泛化能力和鲁棒性,让它在真实、多变的场景中表现更佳。
③ 技术栈概览:YOLOv8、Ultralytics框架
为完成此任务,我们将采用当前业界领先的技术栈:

- 模型:YOLOv8,以其卓越的速度和精度平衡而闻名。
- 框架:Ultralytics,一个强大且用户友好的深度学习框架,它将YOLOv8的训练、验证和部署流程变得异常简单。
2. 任务准备
③ 数据集介绍:鱼眼镜头商品数据集 vs. 常规视角饮料数据集
本次实战我们将融合以下两个特点鲜明的数据集:
- 鱼眼镜头**_**智能销售数据集:

- 特点:由鱼眼摄像头在零售柜内部从上往下拍摄,图片具有广视角和独特的畸变效果。
- 视角:主要为商品顶部视角。
- 格式:经典的VOC格式。
- “B站同济子豪兄”开源的饮料数据集:

- 特点:一个开源的饮料检测数据集。
- 视角:主要为商品正面视角。
- 格式:YOLO格式。
通过合并这两个数据集,我们的模型将同时学习商品的顶部和正面特征,变得更加“智能”。
在开始之前,请确保读者对基本的Python编程和命令行操作有一定了解。我们将涉及环境配置、脚本编写和模型训练等多个环节。
二、 数据集探索:深入理解VOC与YOLO格式
在处理数据前,我们必须先了解它们的“语言”——数据格式。
1. VOC数据集深度解析

VOC (PASCAL Visual Object Classes) 是计算机视觉领域的经典数据集格式。我们的“鱼眼镜头_智能销售数据集”就采用此格式。一个标准的VOC数据集通常包含以下部分:
JPEGImages/:存放所有.jpg格式的原始图像文件。Annotations/:存放与每张图像对应的.xml格式的标注文件。ImageSets/:(可选)存放.txt文件来划分训练集、验证集和测试集。labels.txt/classes.txt:一个纯文本文件,每行包含一个类别名称。
③ 核心文件夹结构:Annotations与JPEGImages的作用
JPEGImages目录非常直观,就是所有图片的存储位置。Annotations目录是VOC格式的精髓所在,每个XML文件都详细描述了一张图片里的所有目标信息。
③ 标注文件详解:以XML为例,拆解<object>**, **<bndbox>等关键字段
我们以一个名为ori_000_XYGOC20200313162026456_1.xml的标注文件为例,看看里面究竟藏着什么秘密。

<filename>:对应的图片文件名,ori_000_XYGOC20200313162026456_1.jpg。<size>:图片的尺寸,宽960像素,高720像素。<object>:每个<object>标签代表图片中的一个物体。<name>:物体的类别名称,如hongshaoniurou(红烧牛肉面)。<bndbox>:物体的边界框(Bounding Box)。<xmin>,<ymin>: 边界框左上角的坐标。<xmax>,<ymax>: 边界框右下角的坐标。- 注意:这些坐标是绝对像素值。
③ 数据脉络:理解train.txt与labels.txt如何组织数据


labels.txt:定义了数据集中所有类别的名称,每一行是一个类别。模型训练时,会按照这个文件的顺序为类别分配索引(ID),例如第一行是ID 0,第二行是ID 1,以此类推。train_list.txt/val_list.txt:这些文件用于划分数据集。每一行通常包含一个图片路径和一个对应的标注文件路径,告诉模型哪些数据用于训练,哪些用于验证。
2. YOLO数据集格式简介
YOLO格式因其简洁高效而广受欢迎,我们的“饮料数据集”就采用此格式。
① YOLO格式的核心思想:归一化与<class_id> <x_center> <y_center> <width> <height>

与VOC不同,YOLO的标注信息直接存储在与图片同名的.txt文件中。例如,image001.jpg的标注信息就在image001.txt里。文件中的每一行代表一个物体,格式如下:
<class_id> <x_center> <y_center> <width> <height>
<class_id>:类别的索引ID,一个整数,对应类别文件中的行号(从0开始)。<x_center>,<y_center>:物体边界框中心的x, y坐标。<width>,<height>:物体边界框的宽度和高度。- 核心区别:这四个坐标值都是归一化的,即相对于图片总宽度和总高度的比例(值在0到1之间)。
② 与VOC格式的对比:直观理解两者差异
| 特性 | VOC 格式 | YOLO 格式 |
|---|---|---|
| 标注文件 | 每张图一个独立的 .xml 文件 |
每张图一个独立的 .txt 文件 |
| 坐标体系 | 绝对像素坐标 (xmin, ymin, xmax, ymax) |
归一化相对坐标 (x_center, y_center, width, height) |
| 类别表示 | 类别名称字符串 (<name>) |
类别索引ID (<class_id>) |
| 复杂度 | 结构化,信息丰富但较繁琐 | 简洁,更适合直接用于模型训练 |
3.将数据集从VOC格式转化为YOLO格式
在使用YoloV8训练VOC数据集时,需要将VOC格式的数据集转化为YOLO格式,因为YOLOv8默认使用YOLO格式的标注文件(.txt);
上聚集常用划分方法为:留出法、交叉验证法、自助法;例如使用7:2:1的比例,以兼顾训练稳定性和评估可靠性;
代码如下:
import os
import xml.etree.ElementTree as ET
import shutil
# 定义路径
voc_images_dir = "./dataset/VOC/JPEGImages" # 改为自己的VOC数据集图像文件所在路径
voc_annotations_dir = "./dataset/VOC/Annotations" # 改为自己的VOC数据集标签文件所在路径
yolo_labels_dir = "./dataset/YOLO/labels" # 改为自己的YOLO数据集标签文件所在路径
yolo_images_dir = "./dataset/YOLO/images" # 改为自己的YOLO数据集图像文件所在路径
labels_txt_path = "./dataset/VOC/labels.txt" # 改为自己的VOC数据集类别文件所在路径
# 数据集划分文件
train_txt_path = "./dataset/VOC/train_list.txt" # 改为自己的VOC数据集中训练集路径
val_txt_path = "./dataset/VOC/val_list.txt" # 改为自己的VOC数据集中验证集路径
test_txt_path = "./dataset/VOC/test_list.txt" # 改为自己的VOC数据集中测试集路径
# 创建目标目录
os.makedirs(os.path.join(yolo_images_dir, "train"), exist_ok=True)
os.makedirs(os.path.join(yolo_images_dir, "val"), exist_ok=True)
os.makedirs(os.path.join(yolo_labels_dir, "train"), exist_ok=True)
os.makedirs(os.path.join(yolo_labels_dir, "val"), exist_ok=True)
if os.path.exists(test_txt_path):
os.makedirs(os.path.join(yolo_images_dir, "test"), exist_ok=True)
os.makedirs(os.path.join(yolo_labels_dir, "test"), exist_ok=True)
# 记录成功和失败的文件数量
success_count = 0
error_count = 0
# 读取类别列表
with open(labels_txt_path, "r") as f:
classes = [line.strip() for line in f.readlines()]
# 处理文件并移动图片
def process_and_move_datasets_files(file_list, split_name):
global success_count, error_count
for file in file_list:
file = file.strip()
if not file:
continue
parts = file.split()
# 分离图片和XML路径,并取出文件名
img_path_part, xml_path_part = parts
img_file = os.path.basename(img_path_part)
xml_file = os.path.basename(xml_path_part)
# 构造XML文件完整路径
xml_path = os.path.join(voc_annotations_dir, xml_file)
# 解析XML文件
try:
tree = ET.parse(xml_path) # 解析XML文件
root = tree.getroot() # 获取根元素
except Exception as e:
print(f"处理XML文件 {xml_path} 失败: {str(e)}")
error_count += 1
break
# 获取图像尺寸
size = root.find("size")
width = int(size.find("width").text)
height = int(size.find("height").text)
# 生成对应的YOLO格式txt文件
txt_filename = os.path.splitext(img_file)[0] + ".txt"
txt_path = os.path.join(yolo_labels_dir, split_name, txt_filename)
with open(txt_path, "w") as f_txt:
for obj in root.findall("object"):
cls_name = obj.find("name").text
if cls_name not in classes:
continue # 如果类别不在 classes 中,则跳过
cls_id = classes.index(cls_name)
# 提取边界框坐标
bbox = obj.find("bndbox")
xmin = int(bbox.find("xmin").text)
ymin = int(bbox.find("ymin").text)
xmax = int(bbox.find("xmax").text)
ymax = int(bbox.find("ymax").text)
# 转换为YOLO格式,对坐标进行归一化
x_center = (xmin + xmax) / 2 / width
y_center = (ymin + ymax) / 2 / height
w = (xmax - xmin) / width
h = (ymax - ymin) / height
f_txt.write(f"{cls_id} {x_center:.6f} {y_center:.6f} {w:.6f} {h:.6f}\n")
# 移动图片文件
src_img_path = os.path.join(voc_images_dir, img_file)
dst_img_path = os.path.join(yolo_images_dir, split_name, img_file)
try:
if os.path.exists(src_img_path):
shutil.copy2(src_img_path, dst_img_path)
print(f"复制文件{src_img_path}成功")
success_count += 1
except Exception as e:
print(f"复制文件{src_img_path}错误|{str(e)}")
error_count += 1
# 处理训练集
with open(train_txt_path, "r") as f:
train_files = f.readlines()
process_and_move_datasets_files(train_files, "train")
# 处理验证集
with open(val_txt_path, "r") as f:
val_files = f.readlines()
process_and_move_datasets_files(val_files, "val")
# 处理测试集(选用)
if os.path.exists(test_txt_path):
with open(test_txt_path, "r") as f:
test_files = f.readlines()
process_and_move_datasets_files(test_files, "test")
print("所有文件处理完成")
print(f"成功处理文件: {success_count} 个")
print(f"失败处理文件: {error_count} 个")

经过处理的文件格式如下:

其中:
- images/train 和 labels/train :
- 存放用于训练模型的图片和标签文件。
- 例如,一张图片可能包含多个饮料瓶,标签文件会标注每个饮料瓶的类别和位置。
- images/val 和 labels/val :
- 存放用于验证模型性能的饮料瓶图片和标签文件。
- 例如,模型可以通过验证集检查是否能够正确识别饮料。
- images/test 和 labels/test (可选):
- 存放用于最终测试模型性能的饮料瓶图片和标签文件。
- 例如,测试集可以用来评估模型在真实场景中的表现
三、 数据集工程:融合与预处理的艺术
现在,我们正式开始动手处理数据,这是整个项目中承前启后的关键一步。
1. 核心挑战:为何必须统一类别ID?
③ 问题分析:同一物体在不同数据集中ID冲突的后果
想象一下:
- 在“鱼眼数据集”中,
baishikele(百事可乐)的类别ID可能是7。 - 在“饮料数据集”中,
pepsi(也是百事可乐)的类别ID可能是1。
如果我们不经处理直接合并,模型会认为这是两种完全不同的物体,因为它看到了两个不同的ID。这就完全违背了我们合并数据集以增强模型识别能力的初衷。因此,在合并前,必须创建一个统一的类别ID体系。
③ 解决方案:建立统一的“类别字典”进行映射
我们的策略是,以类别更丰富的“鱼眼数据集”的labels.txt为基准,将“饮料数据集”中的类别名称和ID全部映射到这个基准体系中。
2. 实战:Python脚本自动化融合异构数据集
我们将通过一系列Python脚本来自动化完成这个看似复杂的过程。
③ 步骤一:统一并生成最终的类别名称文件classes.txt
首先,我们需要手动将“饮料数据集”中的类别名称统一为“鱼眼数据集”中的对应名称。例如,将pepsi改为baishikele。
classes.txt原始内容 (左) vs. 更新后内容 (右)
| cola | kele |
|---|---|
| pepsi | baishikele |
| sprite | xuebi |
| fanta | fenda |
| spring | nongfushanquan |
| ice | binghongcha |
| scream | jianjiao |
| milk | wangzainiunai |
| red | hongniu |
| king | wanglaoji |
③ 步骤二:编写脚本,自动化读取旧ID并映射为新ID
下面的脚本会读取两个数据集的类别文件,为“饮料数据集”的旧ID创建一个到新ID的映射字典,然后遍历所有标签文件,将旧ID替换为新ID。
import os
import glob
def main():
drink_dataset_path = "./dataset/Drink_284_Detection" # 填写你的DRINK_284_DETECTION_LABELME目录的根路径
drink_classes_path = "./dataset/Drink_284_Detection/classes.txt" # 填写你的 DRINK_284_DETECTION_LABELME 的 classes.txt 路径
smart_goods_labels_path = "./dataset/YOLO/labels.txt" # 填写你的鱼眼镜头_智能销售数据集的 labels.txt 路径
# 读取drink_dataset的类别列表
with open(drink_classes_path, 'r', encoding='utf-8') as f:
drink_classes = [line.strip() for line in f.readlines() if line.strip()] # 读取饮料数据集的类别列表
# 读取鱼眼镜头_智能销售数据集的饮料数据集的类别列表
with open(smart_goods_labels_path, 'r', encoding='utf-8') as f:
smart_goods_classes = [line.strip() for line in f.readlines() if line.strip()]
# 创建手动映射字典,为没有直接匹配的类别指定映射关系
# 这里假设的映射关系需要根据实际情况调整
manual_mapping = {
"cola": "kele", # cola 映射到 kele
"pepsi": "baishikele", # pepsi 映射到 baishikele
"sprite": "xuebi", # sprite 映射到 xuebi
"fanta": "fenda", # fanta 映射到 fenda
"spring": "nongfushanquan", # spring 映射到 nongfushanquan
"ice": "binghongcha", # ice 映射到 binghongcha
"scream": "jianjiao", # scream 映射到 jianjiao
"milk": "wangzainiunai", # milk 映射到 wangzainiunai
"red": "hongniu", # red 映射到 hongniu
"king": "wanglaoji" # king 映射到 wanglaoji
}
# 创建索引映射字典
idx_map = {}
for old_idx, class_name in enumerate(drink_classes):
# 首先检查手动映射
if class_name in manual_mapping:
target_class = manual_mapping[class_name]
if target_class in smart_goods_classes:
new_idx = smart_goods_classes.index(target_class)
idx_map[old_idx] = new_idx
print(f"类别'{class_name}'通过手动映射到'{target_class}',源索引{old_idx}->现索引{new_idx}")
else:
print(f"手动映射的目标类别'{target_class}'在目标labels中未找到")
# 然后检查直接匹配
elif class_name in smart_goods_classes:
new_idx = smart_goods_classes.index(class_name)
idx_map[old_idx] = new_idx
print(f"类别'{class_name}'直接匹配,源索引{old_idx}->现索引{new_idx}")
else:
print(f"类别'{class_name}'在目标labels中未找到,也没有手动映射")
# 打印索引映射
print("\n索引开始更新")
for old_idx, new_idx in idx_map.items():
class_name = drink_classes[old_idx]
if class_name in manual_mapping:
target_class = manual_mapping[class_name]
print(f"类别'{class_name}'映射到'{target_class}',源索引{old_idx}->现索引{new_idx}")
else:
print(f"类别'{class_name}'由源索引{old_idx}->现索引{new_idx}")
# 获取train和val文件夹中的标签文件
train_labels_path = os.path.join(drink_dataset_path, "labels", "train") # 获取饮料数据集的训练标签文件路径
val_labels_path = os.path.join(drink_dataset_path, "labels", "val") # 获取饮料数据集的验证标签文件路径
train_label_files = glob.glob(os.path.join(train_labels_path, "*.txt")) # 获取训练标签文件列表
val_label_files = glob.glob(os.path.join(val_labels_path, "*.txt")) # 获取验证标签文件列表
label_files = train_label_files + val_label_files
# 处理每个标签文件
for label_file in label_files:
with open(label_file, 'r', encoding='utf-8') as f: # 读取标签文件
lines = f.readlines()
new_lines = []
for line in lines:
new_lines_parts = line.strip().split() # 把标签文件中的每一行拆分成一个列表
# 更新索引
old_idx = int(new_lines_parts[0])
if old_idx in idx_map:
new_idx = idx_map[old_idx]
new_line = " ".join([str(new_idx)] + new_lines_parts[1:]) + "\n" # 将更新后的索引和其余部分重新组合成新行
new_lines.append(new_line)
else:
print(f"文件{label_file}中的索引{old_idx}未在映射中找到")
# 将更新后的内容写回文件
with open(label_file, 'w', encoding='utf-8') as f:
f.writelines(new_lines)
print("所有ID已映射完成")
if __name__ == "__main__":
main()

运行此脚本后,“饮料数据集”的所有标签文件都将采用与“鱼眼数据集”一致的ID体系。
③ 步骤三:设计智能采样策略,平衡不同数据集的样本量
简单的将两个数据集合并可能导致样本不均衡。考虑到“鱼眼数据集”样本量远大于“饮料数据集”,我们采取一种智能采样策略:
- 使用全部的“饮料数据集”(正面视角)。
- 从“鱼眼数据集”(顶部视角)中,抽取约两倍于“饮料数据集”样本量的数据。
- 在抽取时,优先选择那些包含两个数据共通类别(如可乐、雪碧等)的图片。
这样做的好处是:既保证了“鱼眼数据集”的数据量优势,又让“饮料数据集”的正面视角特征得到充分学习,同时还控制了最终数据集的总体规模,降低了训练成本。
③ 步骤四:编写脚本,完成数据集的物理合并与划分
以下脚本将执行上述采样策略,并将来自两个数据集的图片和更新后的标签文件,复制到一个全新的、合并后的数据集目录中。
"""
数据集合并脚本
本脚本用于合并两个数据集(Drink_284_Detection_Labelme和YOLO_datasets)到一个新数据集,
处理类别映射和样本选择,优先考虑有重叠类别的样本。
主要功能:
- 合并数据集同时保持一致的类别索引
- 优先选择包含重叠类别的样本
- 在新数据集中保持原始目录结构
- 处理不同类别索引之间的标签文件转换
使用方法:
1. 设置输入数据集路径和输出目录路径
2. 运行脚本生成合并后的数据集
"""
import os
import shutil
import random
# 常量定义
RANDOM_SEED = 100 # 固定随机种子保证结果可复现
DRINK_DATASET_PATH = "./dataset/Drink_284_Detection" # 饮料数据集路径
SMART_GOODS_PATH = "./dataset/YOLO" # 智能商品数据集路径(YOLO格式)
NEW_DATASET_PATH = "./dataset/merged_dataset" # 合并后的新数据集路径
# 设置随机种子
random.seed(RANDOM_SEED)
# 读取饮料数据集的类别列表
with open(os.path.join(DRINK_DATASET_PATH, 'classes.txt'), 'r') as f:
drink_classes = [line.strip() for line in f if line.strip()]
# 读取智能商品数据集的类别列表
with open(os.path.join(SMART_GOODS_PATH, 'labels.txt'), 'r') as f:
smart_goods_classes = [line.strip() for line in f if line.strip()]
# 创建智能商品数据集的类别索引到类别名称的映射
smart_goods_index_to_class = {str(idx): cls for idx, cls in enumerate(smart_goods_classes)}
# 找出两个数据集的重叠类别
common_classes = set(drink_classes).intersection(set(smart_goods_classes))
print("两个数据集的重叠类别:", common_classes)
# 创建饮料数据集的类别索引到类别名称的映射
drink_index_to_class = {str(idx): cls for idx, cls in enumerate(drink_classes)}
# 合并并排序新数据集的所有类别
new_datasets_classes = sorted(set(drink_classes + smart_goods_classes))
print("新数据集的所有类别:", new_datasets_classes)
# 创建类别名称到新索引的映射
class_to_new_index = {cls: idx for idx, cls in enumerate(new_datasets_classes)}
# 创建饮料数据集索引到新索引的映射
drink_index_to_new_index = {str(idx): class_to_new_index[cls] for idx, cls in enumerate(drink_classes)}
# 创建智能商品数据集索引到新索引的映射
smart_goods_index_to_new_index = {str(idx): class_to_new_index[cls] for idx, cls in enumerate(smart_goods_classes)}
def contains_common_class(label_file, common_classes, index_to_class):
"""
检查标签文件是否包含重叠类别
参数:
label_file: 标签文件路径
common_classes: 重叠类别集合
index_to_class: 索引到类别名称的映射
返回:
bool: 如果包含重叠类别返回True,否则返回False
"""
if not os.path.exists(label_file):
return False
with open(label_file, 'r') as f:
lines = f.readlines()
for line in lines:
parts = line.strip().split()
if parts:
index = parts[0]
cls = index_to_class.get(index)
if cls in common_classes:
return True
return False
def extract_samples(smart_goods_subset, extract_count, common_classes, smart_goods_index_to_class):
"""
从智能商品数据集中抽取样本
参数:
smart_goods_subset: 子集名称(train/val)
extract_count: 需要抽取的样本数量
common_classes: 重叠类别集合
smart_goods_index_to_class: 索引到类别名称的映射
返回:
list: 抽取的样本文件名列表
"""
# 获取样本路径
images_path = os.path.join(SMART_GOODS_PATH, 'images', smart_goods_subset)
labels_path = os.path.join(SMART_GOODS_PATH, 'labels', smart_goods_subset)
images = os.listdir(images_path)
# 优先抽取包含重叠类别的图像
priority_images = []
other_images = []
for img in images:
label_file = os.path.join(labels_path, img.replace('.jpg', '.txt').replace('.png', '.txt'))
if contains_common_class(label_file, common_classes, smart_goods_index_to_class):
priority_images.append(img)
else:
other_images.append(img)
# 优先从包含重叠类别的图像中抽取
if len(priority_images) >= extract_count:
extracted = random.sample(priority_images, extract_count)
else:
extracted = priority_images
remaining_count = extract_count - len(priority_images)
if remaining_count > 0:
# 从其他图像中随机抽取剩余数量
extracted += random.sample(other_images, min(remaining_count, len(other_images)))
return extracted
def update_label_file(label_file, index_mapping):
"""
更新标签文件中的类别索引
参数:
label_file: 标签文件路径
index_mapping: 旧索引到新索引的映射
"""
with open(label_file, 'r') as f:
lines = f.readlines()
new_lines = []
for line in lines:
parts = line.strip().split()
if parts:
old_index = parts[0]
new_index = index_mapping.get(old_index, old_index) # 保持找不到的索引不变
parts[0] = str(new_index)
new_lines.append(' '.join(parts) + '\n')
with open(label_file, 'w') as f:
f.writelines(new_lines)
# 统计饮料数据集的训练集和验证集数量
drink_train_images = os.listdir(os.path.join(DRINK_DATASET_PATH, 'images', 'train'))
drink_val_images = os.listdir(os.path.join(DRINK_DATASET_PATH, 'images', 'val'))
drink_train_count = len(drink_train_images)
drink_val_count = len(drink_val_images)
print(f"饮料数据集 - 训练集数量: {drink_train_count}, 验证集数量: {drink_val_count}")
# 计算需要从智能商品数据集中抽取的样本数量(饮料数据集的2倍)
smart_goods_train_extract_count = 2 * drink_train_count
smart_goods_val_extract_count = 2 * drink_val_count
print(f"需要从智能商品数据集抽取 - 训练集: {smart_goods_train_extract_count}, 验证集: {smart_goods_val_extract_count}")
# 从智能商品数据集中抽取样本
smart_goods_train_extracted = extract_samples('train', smart_goods_train_extract_count, common_classes, smart_goods_index_to_class)
smart_goods_val_extracted = extract_samples('val', smart_goods_val_extract_count, common_classes, smart_goods_index_to_class)
print(f"实际抽取样本 - 训练集: {len(smart_goods_train_extracted)}, 验证集: {len(smart_goods_val_extracted)}")
# 创建新数据集的目录结构
for subset in ['train', 'val']:
for folder in ['images', 'labels']:
os.makedirs(os.path.join(NEW_DATASET_PATH, folder, subset), exist_ok=True)
def process_dataset(source_path, target_path, images_list, index_map, subset):
"""
处理数据集,复制图片和标签文件到新数据集并更新标签
参数:
source_path: 源数据集路径
target_path: 目标数据集路径
images_list: 图像文件名列表
index_map: 索引映射关系
subset: 子集名称(train/val)
"""
for img in images_list:
# 复制图像文件
source_img = os.path.join(source_path, 'images', subset, img)
target_img = os.path.join(target_path, 'images', subset, img)
shutil.copy(source_img, target_img)
# 处理对应的标签文件
base_name = os.path.splitext(img)[0]
source_label = os.path.join(source_path, 'labels', subset, f"{base_name}.txt")
target_label = os.path.join(target_path, 'labels', subset, f"{base_name}.txt")
if os.path.exists(source_label):
shutil.copy(source_label, target_label)
update_label_file(target_label, index_map)
# 处理饮料数据集
process_dataset(DRINK_DATASET_PATH, NEW_DATASET_PATH, drink_train_images,
drink_index_to_new_index, 'train')
process_dataset(DRINK_DATASET_PATH, NEW_DATASET_PATH, drink_val_images,
drink_index_to_new_index, 'val')
# 处理智能商品数据集
process_dataset(SMART_GOODS_PATH, NEW_DATASET_PATH, smart_goods_train_extracted,
smart_goods_index_to_new_index, 'train')
process_dataset(SMART_GOODS_PATH, NEW_DATASET_PATH, smart_goods_val_extracted,
smart_goods_index_to_new_index, 'val')
# 写入新数据集的类别文件
with open(os.path.join(NEW_DATASET_PATH, 'classes.txt'), 'w') as f:
for cls in new_datasets_classes:
f.write(cls + '\n')
print(f"新数据集已创建,路径: {NEW_DATASET_PATH}")
print(f"新数据集总类别数: {len(new_datasets_classes)}")


执行完毕后,我们就得到了一个全新的、融合了两种视角、采用统一ID体系的merged_dataset,万事俱备,只待训练!
四、 自定义模型训练:打造专属的YOLOv8检测器
现在,我们将使用刚刚精心准备好的merged_dataset来训练我们自己的YOLOv8模型。
1. 搭建高效的训练环境
① 基础环境:克隆Ultralytics仓库并安装核心依赖
# 1. 克隆官方仓库
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
pip install -r requirements.txt
# 2. pip直接安装
pip install ultralytics
作者直接采用方法2

② 硬件加速:确认CUDA环境与GPU驱动
为了高效训练,强烈建议使用NVIDIA GPU。请确保您已正确安装与PyTorch版本兼容的NVIDIA驱动、CUDA Toolkit和cuDNN。可以通过在终端输入nvidia-smi来检查GPU状态。

作者这里是4060Ti显卡,勉强够用😉
③ 下载好预训练模型
我们此次选择的是YOLOv8m.pt,YOLOv8m.pt 是 YOLOv8 中等规模(medium)的预训练权重。它已经在COCO数据集上进行了预训练。

2. 精通配置文件
YOLOv8的训练由两个核心.yaml文件控制。
① 模型架构配置 (yolov8.yaml):根据新数据集的类别总数,修改nc参数
这个文件定义了模型的网络结构。我们通常不需要修改结构本身,但必须更新一个关键参数:nc (number of classes)。
在ultralytics/cfg/models/v8/yolov8.yaml文件中,找到 nc 参数,将其值从默认的80(COCO数据集类别数)修改为我们新数据集的总类别数。根据之前的脚本输出,这个值是113。
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLOv8 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolov8
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 113 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 129 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPS
s: [0.33, 0.50, 1024] # YOLOv8s summary: 129 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPS
m: [0.67, 0.75, 768] # YOLOv8m summary: 169 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPS
l: [1.00, 1.00, 512] # YOLOv8l summary: 209 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPS
x: [1.00, 1.25, 512] # YOLOv8x summary: 209 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPS
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
nc:类别数量,默认值为80(对应 COCO 数据集)
scales:定义了不同模型规模的缩放因子,包括深度(depth)、宽度(width)和最大通道数(max_channels)。
backbone:定义了模型的主干网络
head:定义了模型的头部网络
nc: 80 # number of classes
更改为 nc: 113 # number of classes
② 数据集配置 (data.yaml):指定融合后数据集的路径与类别列表
我们需要创建一个新的data.yaml文件来告诉YOLOv8我们的数据集在哪里,以及它包含哪些类别。可以仿照ultralytics/cfg/datasets/coco128.yaml来创建。
新建dataset.yaml文件,内容如下:
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# COCO128 dataset https://www.kaggle.com/datasets/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/detect/coco/
# Example usage: yolo train data=coco128.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco128 ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ./dataset/merged_dataset #数据集根路径
train: images/train # 训练集图像相对路径
val: images/val # 验证集图像相对路径
# Classes
names:
0: 3+2-2
1: 3jia2
2: aerbeisi
3: anmuxi
4: aoliao
5: asamu
6: baicha
7: baishikele
8: baishikele-2
9: baokuangli
10: binghongcha
11: bingqilinniunai
12: bingtangxueli
13: buding
14: chacui
15: chapai
16: chapai2
17: damaicha
18: daofandian1
19: daofandian2
20: daofandian3
21: daofandian4
22: dongpeng
23: dongpeng-b
24: fenda
25: gudasao
26: guolicheng
27: guolicheng2
28: haitai
29: haochidian
30: haoliyou
31: heweidao
32: heweidao2
33: heweidao3
34: hongniu
35: hongniu2
36: hongshaoniurou
37: jianjiao
38: jianlibao
39: jindian
40: kafei
41: kaomo_gali
42: kaomo_jiaoyan
43: kaomo_shaokao
44: kaomo_xiangcon
45: kebike
46: kele
47: kele-b
48: kele-b-2
49: laotansuancai
50: liaomian
51: libaojian
52: lingdukele
53: lingdukele-b
54: liziyuan
55: lujiaoxiang
56: lujikafei
57: luxiangniurou
58: maidong
59: mangguoxiaolao
60: meiniye
61: mengniu
62: mengniuzaocan
63: moliqingcha
64: nfc
65: niudufen
66: niunai
67: nongfushanquan
68: qingdaowangzi-1
69: qingdaowangzi-2
70: qinningshui
71: quchenshixiangcao
72: rancha-1
73: rancha-2
74: rousongbing
75: rusuanjunqishui
76: suanlafen
77: suanlaniurou
78: taipingshuda
79: tangdaren
80: tangdaren2
81: tangdaren3
82: ufo
83: ufo2
84: wanglaoji
85: wanglaoji-c
86: wangzainiunai
87: weic
88: weitanai
89: weitanai2
90: weitanaiditang
91: weitaningmeng
92: weitaningmeng-bottle
93: weiweidounai
94: wuhounaicha
95: wulongcha
96: xianglaniurou
97: xianguolao
98: xianxiayuban
99: xuebi
100: xuebi-b
101: xuebi2
102: yezhi
103: yibao
104: yida
105: yingyangkuaixian
106: yitengyuan
107: youlemei
108: yousuanru
109: youyanggudong
110: yuanqishui
111: zaocanmofang
112: zihaiguo
重要提示:
data.yaml中的names列表必须与merged_dataset/classes.txt的内容和顺序完全一致!其中download字段是可选的,因为数据集已经准备好,且不需要提供下载链接,所以请务必从data.yaml文件中删除download字段
3. 开始训练!
① 编写并运行训练脚本train.py
在ultralytics目录下创建一个train.py文件。
from ultralytics import YOLO
def train_custom_model():
# 1. 加载一个预训练模型
# 我们选择中等规模的'yolov8m.pt'作为起点,它在速度和精度上是一个很好的平衡点
model = YOLO('./pre_model/yolov8m.pt')
# 2. 开始训练
results = model.train(
data='./dataset.yaml', # 指向你的数据集配置文件
epochs=100, # 训练轮次
imgsz=640, # 输入图片尺寸
batch=16, # 批处理大小,根据你的GPU显存调整
device='0', # 使用第一个GPU,如果是CPU则为 'cpu'
workers=8, # 数据加载线程数,根据你的CPU性能调整
project='./output/', # 训练结果保存的根目录
name='drink_model_v1' # 本次实验的名称
)
if __name__ == '__main__':
train_custom_model()
运行此脚本 python train.py,激动人心的训练过程就开始了!
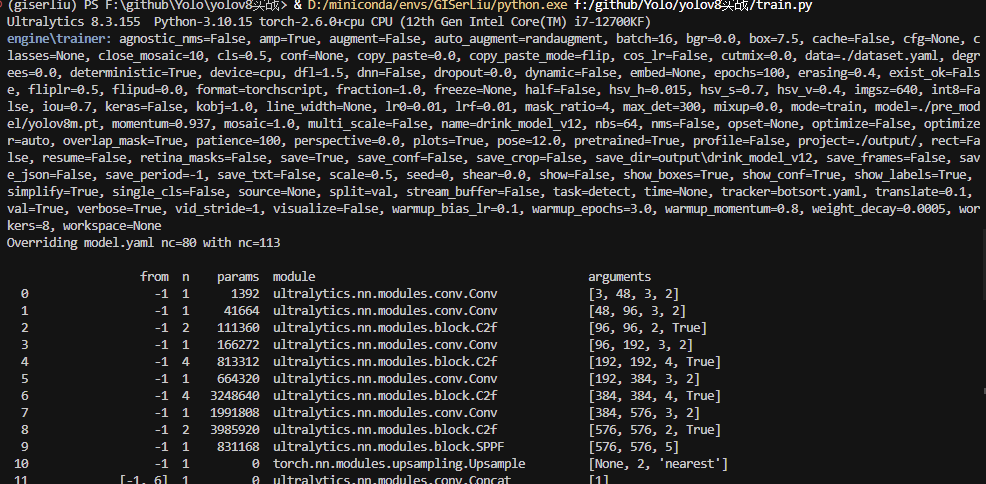
② 解读训练日志:实时监控box_loss , cls_loss与mAP50-95的变化

在训练过程中,终端会打印出丰富的日志信息。看懂它们是评估训练状态的关键。
- Epoch: 当前训练轮次/总轮次。
- GPU_mem: GPU显存占用情况。
- box_loss: 边界框回归损失,越低表示框的位置预测越准。
- cls_loss: 分类损失,越低表示物体类别预测越准。
- dfl_loss: 分布焦点损失,辅助边界框回归,同样是越低越好。
- mAP50: IoU阈值为0.5时的平均精度,是目标检测中一个核心的、直观的性能指标。
- mAP50-95: 在IoU阈值从0.5到0.95的区间内,平均计算的mAP。这个指标更严格,更能反映模型的综合定位能力。
理想的训练状态是:所有loss持续下降,而mAP50和mAP50-95稳步上升。
4. 分析训练成果
训练结束后,所有结果都保存在了output/drink_model_v1目录下。
① 训练产物:理解best.pt与last.pt的区别与用途
在weights/子目录中,你会找到两个重要的文件:
last.pt: 保存了最后一次训练epoch的模型权重。best.pt: 保存在所有验证轮次中,mAP50-95指标最高的模型权重。这通常是我们最终部署和使用的模型。
② 结果可视化:通过results.png和confusion_matrix.png评估模型性能
results.png:以图表形式展示了所有loss和mAP指标在整个训练过程中的变化曲线,可以直观地判断模型是否收敛。
confusion_matrix.png:混淆矩阵,展示了模型在各个类别上的分类情况,可以帮助我们发现哪些类别之间容易被混淆。
总结
本文我们从零开始,完整地走过了数据理解、数据融合、环境配置到模型训练的全流程。现在,让我们回顾一下核心成果:
✅ 掌握了数据集工程:学会了如何处理并融合来自不同源、采用不同标注格式的数据集,并解决了关键的类别ID映射问题。
✅ 具备了独立训练能力:根据自己的数据集,配置并成功训练一个专属的YOLOv8模型。
✅ 学会了评估模型性能:通过解读训练日志和结果图表,初步判断模型的训练效果。
我们已经成功打造出了一个强大的自定义模型(best.pt),这就像是铸成了一把锋利的宝剑。但这仅仅是第一步,如何用好这把剑,让它在实际工作中削铁如泥呢?
在下一篇文章中,作者将带你进入样本自动标注和迭代优化的实战环节:利用这个刚刚训练好的模型,结合X-AnyLabeling工具,实现AI辅助下的高效自动标注与模型的迭代优化!
文章参考
拓展阅读
- YOLO实践之数据集制作与整理@程宏 @刘伟鸿
- 作者的算法专栏 - CSDN 博客 (包含更多YOLO技术文章)
💖 感谢您的耐心阅读!
如果您觉得本文对您理解和实践YOLOv8有所帮助,请考虑点赞、收藏或分享给更多有需要的朋友。您的支持是我持续创作优质内容的动力!敬请期待下篇《YOLOv8实战(下) - AI辅助标注与模型迭代优化》,欢迎在评论区交流讨论,共同进步。


这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)