上下文工程完全指南:打造高确定性AI Agent的四大支柱(建议收藏)
文章探讨了上下文工程在构建可靠AI Agent中的关键作用,指出长上下文会导致"四宗罪"问题:中毒、干扰、混淆和冲突。提出四大支柱策略:写入(构建外部记忆)、选择(精准检索所需信息)、压缩(平衡保真度与成本)和隔离(划分认知边界)。开发者需从"提示工程师"转变为"上下文架构师",系统性地设计和管理AI的认知空间,将LLM的"概率性"优化为"确定性",打造更可靠、更落地的AI应用。
导读:
硅谷大神Andrej Karpathy,在今年6月一场主题为“Software in the Era of AI”的演讲中指出:与其构建很多自主Agent的炫目Demo,不如更多构建半自主产品。
是的,AI应用的最大价值之一,其实恰恰是“确定性”。
上下文工程(Context Engineering),其使命正是为了不断将LLM的“概率性”,最大程度优化为“确定性”。
说人话,就是让以AI Agent为代表的Apps,可落地,更靠谱。
从“简单提示”到“认知空间”
在构建可落地AI Agent的实践中,我们的视角必须超越单一的“提示工程”。
正如 Andrej Karpathy 所言,如果大型语言模型(LLM)是新时代的“操作系统”,如下图:
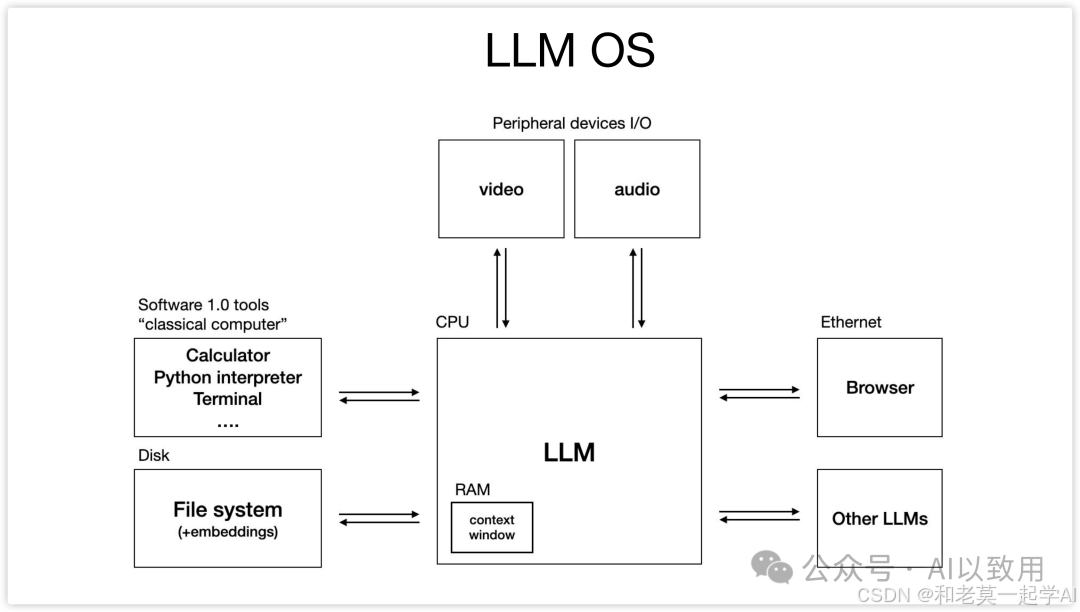
那么它的上下文窗口(Context Window)就是“内存(RAM)”,作为模型的工作记忆,上下文工程(Context Engineering)正是这样一门“精妙的艺术与科学,旨在为LLM的上下文窗口精确填充下一步所需的恰当信息”。
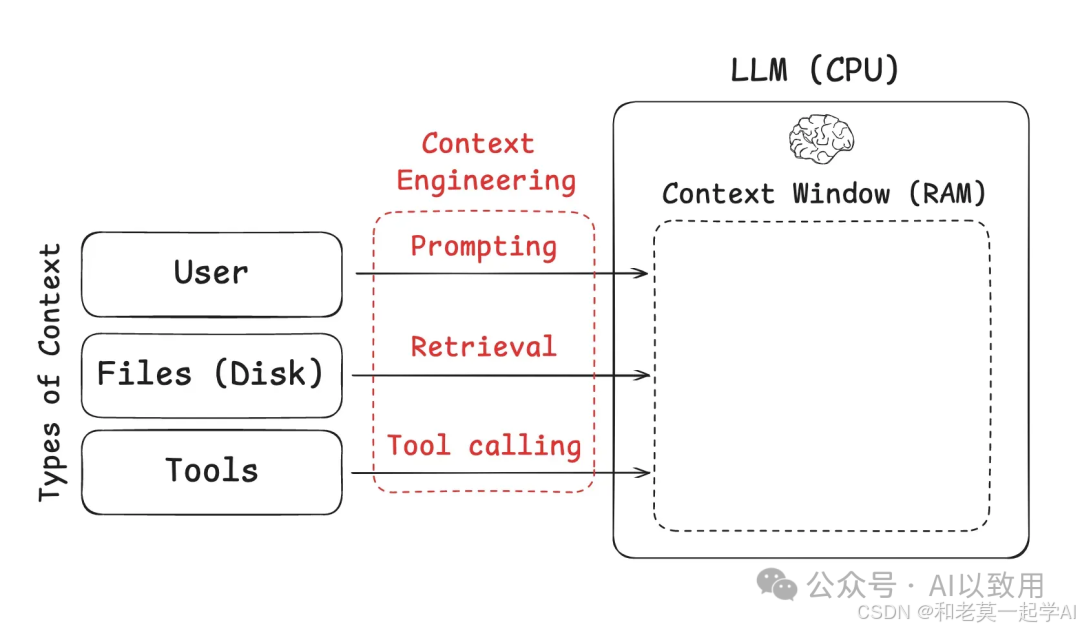
一个精心设计的上下文,可以显著提升Agent的任务解决能力、降低运营成本,并规避性能退化问题。你的AI有多强大,最终取决于你为它构建的上下文有多精良。
核心挑战:长上下文的“四宗罪”
通常,Agent会交替执行LLM 调用和工具调用,通常用于执行长时间运行的任务。Agent会交替执行LLM 调用和工具调用,并使用工具反馈来决定下一步操作。
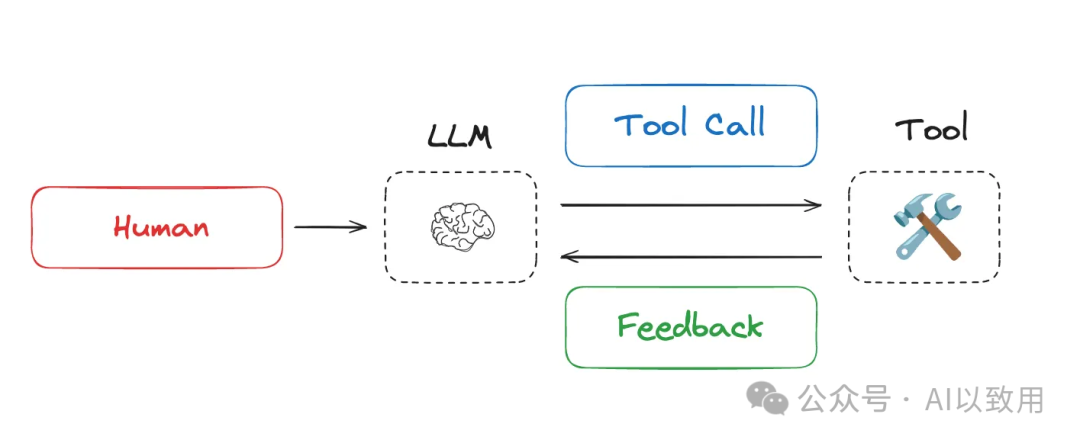
当Agent执行长耗时任务时,其上下文会不断累积,这不仅会超出窗口限制、增加成本与延迟,更会引发一系列性能衰退问题。
这些问题可以归结为长上下文的“四宗罪”:
-
• 上下文中毒 (Context Poisoning): 当一次错误的生成(幻觉)被写入上下文后,它会像毒药一样污染后续的每一步推理,导致Agent偏离正确的轨道,最终得出错误结论。
-
• 上下文干扰 (Context Distraction): 当上下文中充斥了大量信息时,即使这些信息都是正确的,也可能压倒(overwhelm)模型在预训练阶段学到的核心指令或能力,使其“分心”,忘记了最初的目标。。
-
• 上下文混淆 (Context Confusion): 当上下文中包含了与当前任务不相关,但形式上又可能产生关联的冗余信息时,模型会被这些“噪音”所迷惑,从而影响其决策的准确性。
研究发现,即使是像“猫一生中大部分时间都在睡觉”这样的简单短语,也会大大破坏先进的推理模型,使其错误率增加三倍。【参考论文:《Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models》(https://arxiv.org/pdf/2503.01781)】
-
• 上下文冲突 (Context Clash): 当上下文中的不同部分包含了相互矛盾或不一致的信息时,模型会陷入决策困境,不知道应该相信哪一部分,导致行为的不可预测性。
管理上下文,本质上就是管理AI的注意力与记忆力,是构建可靠Agent的基石。
四大支柱:上下文工程的实现策略
为应对上述挑战,业界已发展出四种核心的上下文工程策略,堪称四大支柱:写入(Write)、选择(Select)、压缩(Compress)和隔离(Isolate) 。
如下图所示,这些策略构成了上下文工程的通用类别:
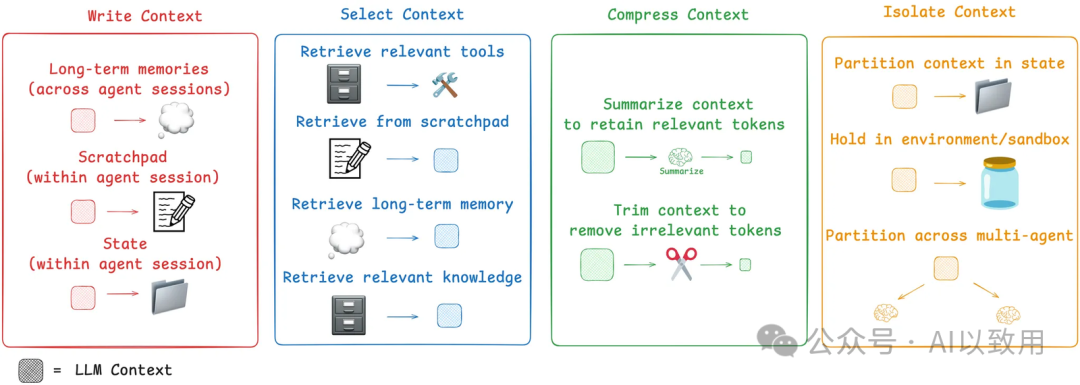
支柱一:写入 (Write) - 构建Agent的外部记忆
定义: 将信息从即时上下文窗口中移出,保存至外部存储,为Agent构建一个超越单次交互的持久化信息基础。
1.1 便笺
- • 目的: 在Agent的单个任务会话(Session)内持久化中间状态和思考过程。
- • 机制: Agent在执行任务时,将中间的思考、计划或关键发现写入临时存储(如文件或运行时状态对象)。这确保了Agent的“思考链”不会因为上下文长度限制而中断。便笺的实现方式多样,可以是一个简单地写入文件的工具调用,也可以是会话期间持续存在的运行时状态对象中的一个字段,该字段在会话期间持续存在。
- • 应用: Anthropic 的multi-agent研究表明,主Agent(LeadResearcher)会将任务规划写入“记忆”(即便笺),以防止上下文窗口超出200,000个token时被截断,从而保留重要的计划。LangGraph 的检查点(Checkpoint)机制也是这一理念的技术实现,允许将信息写入状态并在Agent轨迹的任何步骤中获取,从而方便了“便笺”的实现。
1.2 记忆
-
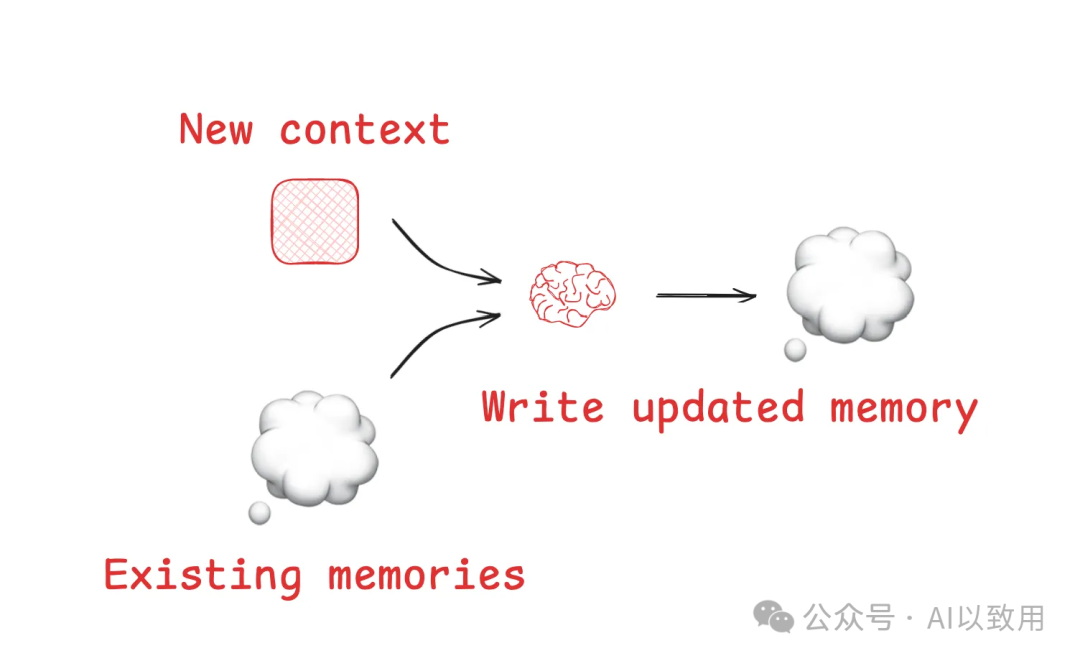
• 目的: 实现跨会话的信息持久化,使Agent能够从过去的交互中学习,从而在多个会话中受益。
-
• 机制: 通过“读取-更新-写入”循环,结合新旧信息,利用LLM自身能力生成更新后的记忆,并写回长期存储。
-
• 应用: Reflexion 框架引入了在每次Agent回合后进行反思并重用这些自生成记忆的理念。Generative Agents 则创建了定期从Agent过去反馈集合中合成的记忆。这些概念已融入流行的产品,如 ChatGPT 的自定义指令、Cursor 和 Windsurf 的规则文件,它们都具备基于用户与Agent交互自动生成并持久化长期记忆的机制。
支柱二:选择 (Select) - 给予Agent此刻最需的洞察
定义: 从外部存储中,智能地检索与当前任务最相关的信息,并将其动态载入LLM的上下文窗口。
2.1 从记忆/便笺中选择
-
• 机制: 选择便笺上下文的机制取决于其实现方式。如果它是一个工具,Agent可以通过调用工具来读取。如果它是Agent运行时状态的一部分,开发者可以选择在每个步骤中向LLM暴露状态的哪些部分。这提供了对LLM在后续回合中暴露便笺上下文的细粒度控制。对于大规模记忆,通常采用向量检索或知识图谱进行查询。

-
• 挑战: 选择的艺术在于“精准”而非“丰富”。错误的记忆选择会导致上下文污染。
*在AI Engineer World’s Fair 上,Simon Willison 分享了一个记忆选择出错的案例:ChatGPT 从记忆中获取了他的位置,并意外地将其注入到请求的图像中。这种意外或不希望的记忆检索可能会让一些用户感觉上下文窗口“*不再属于他们 ”!
2.2 从工具 (Tools) 中选择
- • 机制: Agent使用工具,但如果提供的工具过多,它们可能会不堪重负,通常是因为工具描述重叠,导致模型对使用哪个工具感到困惑。一种方法是对工具描述应用 RAG(检索增强生成)思想,仅为任务获取最相关的工具,并将其载入上下文。
- • 效果: 一些最新研究表明,此方法能将工具选择的准确率提升高达3倍。例如,LangGraph 的 Bigtool 库正是通过对工具描述进行语义搜索来实现工具选择,尤其适用于处理大量工具集的情况。
2.3 从知识 (Knowledge) 中选择
-
• 机制: 这是最经典的 RAG 场景,通过检索外部知识库为Agent提供事实依据。
-
• 挑战与实践: RAG 是一个丰富的话题,它可能是核心的上下文工程挑战。有关RAG的大量研究与实践表明,对于复杂知识的检索,需要多层次、多模态的混合策略。
支柱三:压缩 (Compress) - 在信息保真度与成本间取得平衡
定义: 在保留核心信息的前提下,对上下文进行精简,以减少token消耗、降低延迟。
3.1 上下文总结 (Context Summarization)
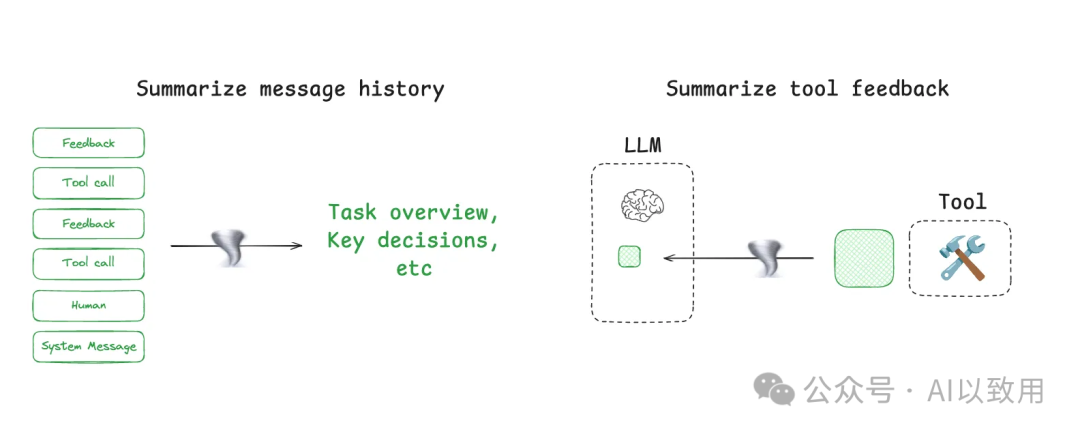
-
• 机制: 利用LLM自身能力,将冗长的信息(如对话历史、工具输出)提炼成摘要。
-
• 应用: 可用于对全局轨迹进行总结(如 Claude Code 的“自动压缩”功能,当上下文窗口使用超过95%时触发,它会总结用户与Agent交互的完整轨迹),也可用于对局部信息(如某个工具的输出)进行后处理。
-
• 挑战: 总结是有损压缩,关键细节可能在提炼中丢失。如果需要捕获特定事件或决策,总结可能是一个挑战。Cognition 公司甚至为此步骤专门微调模型,这凸显了其难度与重要性,表明“在信息保真度与压缩效率之间取得平衡,是上下文总结的艺术所在”。
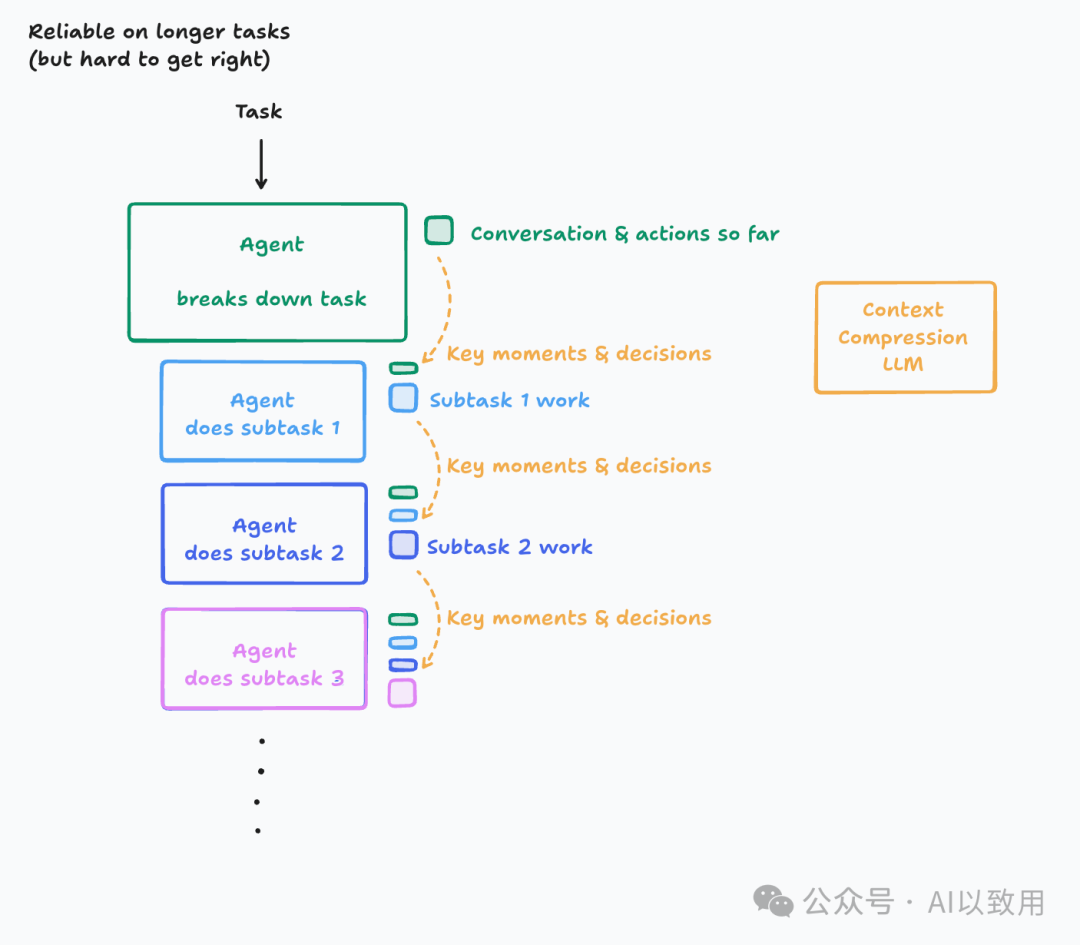
3.2 上下文裁剪 (Context Trimming)
- • 机制: 与总结通常使用LLM提炼最相关的上下文片段不同,裁剪通常采用更直接的、基于启发式规则的过滤方法,如移除最旧的消息,或使用一个训练好的模型来“修剪”无关信息(如 Drew Breunig 提到的 Provence,一个用于问答的训练有素的上下文修剪器)。
支柱四:隔离 (Isolate) - 为专注与安全划分认知边界
定义: 通过逻辑或物理方式划分上下文,帮助Agent更专注地处理子任务,或在安全环境中执行操作。
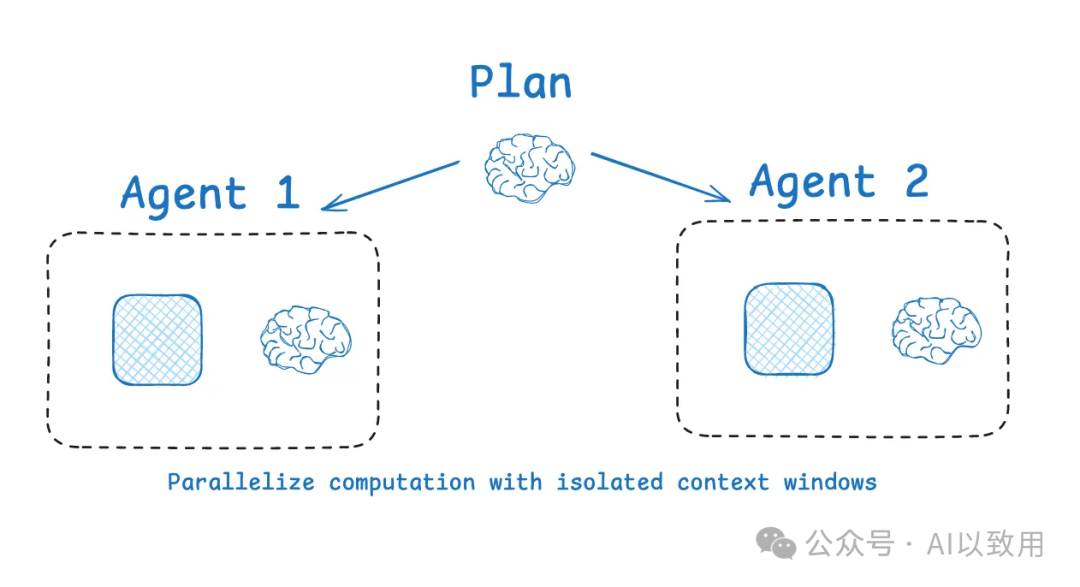
4.1 Multi-Agent架构
-
• 机制: 将复杂任务分解,分配给拥有独立上下文的多个子Agent并行或串行工作。这是用“分而治之”的思想来管理上下文的复杂度。OpenAI Swarm 库的动机之一就是关注点分离,即一个Agent团队可以处理特定的子任务,每个Agent拥有自己特定的工具集、指令和上下文窗口。
-
• 优势: Anthropic 的multi-agent研究表明,具有隔离上下文的多个Agent在性能上往往优于一个处理庞大上下文的单一Agent,因为每个子Agent的上下文窗口可以分配给更聚焦的子任务。
-
• 挑战: Multi-Agent架构的挑战包括token使用量(Anthropic 报告称可能比聊天多达15倍! ),需要精心设计的提示工程来规划子Agent的工作,以及子Agent之间的协调机制。例如,LangGraph 提供了对构建多Agent架构的强大支持,例如通过 supervisor 和 swarm 库,使得这种复杂的上下文管理模式得以实现。
4.2 通过环境进行隔离
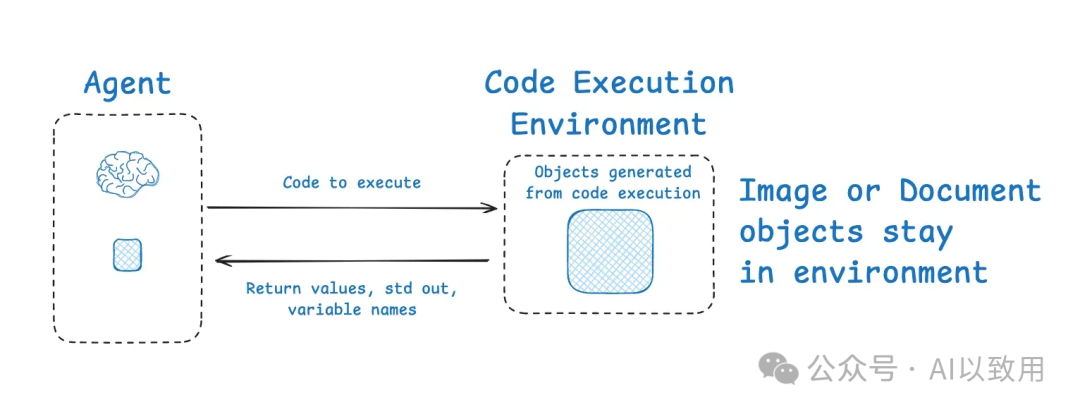
-
• 机制: 让Agent(特别是代码Agent)在一个沙箱(Sandbox)环境中执行代码,仅将摘要式结果传回给LLM。HuggingFace 的 Deep Researcher 展示了通过 CodeAgent 和沙箱隔离上下文的例子。CodeAgent 输出包含所需工具调用的代码,这些代码随后在沙箱中运行,然后将选定的上下文(例如返回值)从工具调用中传回LLM。
-
• 优势: 这允许上下文在环境中与LLM隔离。HuggingFace 指出,这是隔离token密集型对象的绝佳方式:“ [代码Agent允许]更好地处理状态……需要存储此图像/音频/其他以供以后使用?没问题,只需将其作为变量分配到您的状态中,您就可以[稍后使用它]。 ”这极大地节约了上下文空间。
4.3 通过状态对象进行隔离
- • 机制: 在Agent的运行时状态(State)中定义结构化模式,仅将部分字段暴露给LLM,从而在架构层面实现轻量级的上下文隔离。
- • 优势: 状态对象可以设计为具有特定模式的字段,其中上下文可以写入,只有部分字段(例如消息)在Agent的每个回合中暴露给LLM,从而实现更具选择性的使用。这与沙箱的目的相同,但提供了一种更轻量级的、架构层面的上下文隔离方式。
结语:请成为「上下文架构师」
上下文工程正在成为构建高阶AI Agent的核心技艺。它要求我们从一个单纯的“提问者”或“提示工程师”,转变为一个深思熟虑的 “上下文架构师”。
系统性地运用写入、选择、压缩、隔离这四大策略,去主动设计和管理AI的认知空间。这不仅是技术的挑战,更是思维模式的转变。
未来,最强大的AI Agent,必定与最优秀的上下文架构师密不可分。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 35
35 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)