工具系列:PyCaret 介绍_聚类算法案例
PyCaret 是一个开源的、低代码的 Python 机器学习库,可以自动化机器学习工作流程。它是一个端到端的机器学习和模型管理工具,可以大幅加快实验周期并提高工作效率。与其他开源机器学习库相比,PyCaret 是一个替代低代码库,可以用几行代码代替数百行代码。这使得实验速度指数级增长,效率更高。PyCaret 本质上是围绕几个机器学习库和框架(如scikit-learn、XGBoost、Ligh
👋 工具系列:PyCaret 介绍_聚类算法案例
PyCaret教程已经系统的将官网文档翻译成中文,您可以去http://www.aidoczh.com/docs/pycaret/ 查看文档,该网站www.aidoczh.com主要是将AI工具官方文档翻译成中文,还有其他工具文档可以看。
本案例代码下载
https://download.csdn.net/download/wjjc1017/88642616
工具介绍
PyCaret 是一个开源的、低代码的 Python 机器学习库,可以自动化机器学习工作流程。它是一个端到端的机器学习和模型管理工具,可以大幅加快实验周期并提高工作效率。
与其他开源机器学习库相比,PyCaret 是一个替代低代码库,可以用几行代码代替数百行代码。这使得实验速度指数级增长,效率更高。PyCaret 本质上是围绕几个机器学习库和框架(如scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray等)的 Python 封装。
PyCaret 的设计和简洁性受到了 Gartner 首次使用的公民数据科学家这一新兴角色的启发。公民数据科学家是能够执行简单和中等复杂的分析任务的高级用户,而以前这些任务需要更多的技术专长。
💻 安装
PyCaret在以下64位系统上进行了测试和支持:
- Python 3.7 - 3.10
- 仅适用于Ubuntu的Python 3.9
- Ubuntu 16.04或更高版本
- Windows 7或更高版本
您可以使用Python的pip软件包管理器安装PyCaret:
pip install pycaret
PyCaret的默认安装不会自动安装所有额外的依赖项。为此,您需要安装完整版本:
pip install pycaret[full]
或者根据您的用例,您可以安装以下其中之一的变体:
pip install pycaret[analysis]pip install pycaret[models]pip install pycaret[tuner]pip install pycaret[mlops]pip install pycaret[parallel]pip install pycaret[test]
# 导入pycaret库
import pycaret
# 打印pycaret库的版本号
pycaret.__version__
'3.0.0'
🚀 快速开始
PyCaret的聚类模块是一个无监督机器学习模块,它执行将一组对象分组的任务,使得同一组中的对象(也称为簇)彼此之间比与其他组中的对象更相似。
它提供了几个预处理功能,通过设置函数为建模准备数据。它有超过10个可用的算法和几个绘图来分析训练模型的性能。
在PyCaret的无监督模块中,典型的工作流程按照以下6个步骤进行:
设置 ➡️ 创建模型 ➡️ 分配标签 ➡️ 分析模型 ➡️ 预测 ➡️ 保存模型
# 从pycaret数据集模块加载示例数据集
from pycaret.datasets import get_data
data = get_data('jewellery')
| Age | Income | SpendingScore | Savings | |
|---|---|---|---|---|
| 0 | 58 | 77769 | 0.791329 | 6559.829923 |
| 1 | 59 | 81799 | 0.791082 | 5417.661426 |
| 2 | 62 | 74751 | 0.702657 | 9258.992965 |
| 3 | 59 | 74373 | 0.765680 | 7346.334504 |
| 4 | 87 | 17760 | 0.348778 | 16869.507130 |
设置
此函数初始化训练环境并创建转换流水线。在执行PyCaret中的任何其他函数之前,必须先调用设置函数。它只有一个必需的参数,即data。所有其他参数都是可选的。
# 导入 pycaret clustering 库并初始化设置
from pycaret.clustering import *
# 使用指定的 session_id 对数据进行设置
s = setup(data, session_id = 123)
| Description | Value | |
|---|---|---|
| 0 | Session id | 123 |
| 1 | Original data shape | (505, 4) |
| 2 | Transformed data shape | (505, 4) |
| 3 | Numeric features | 4 |
| 4 | Preprocess | True |
| 5 | Imputation type | simple |
| 6 | Numeric imputation | mean |
| 7 | Categorical imputation | mode |
| 8 | CPU Jobs | -1 |
| 9 | Use GPU | False |
| 10 | Log Experiment | False |
| 11 | Experiment Name | cluster-default-name |
| 12 | USI | 3c6c |
一旦设置成功执行,它将显示包含实验级别信息的信息网格。
- 会话ID: 伪随机数,在所有函数中分布为种子,以便以后能够重现。如果未传递
session_id,则会自动生成一个随机数,并分发给所有函数。 - 原始数据形状: 在进行任何转换之前的原始数据形状。
- 转换后数据形状: 经过转换后的数据形状。
- 数值特征: 被视为数值的特征数量。
- 分类特征: 被视为分类的特征数量。
PyCaret的API
PyCaret有两套可以使用的API。 (1) 函数式API(如上所示)和 (2) 面向对象的API。
使用面向对象的API时,您将导入一个类并执行该类的方法,而不是直接执行函数。
# 导入ClusteringExperiment类并初始化该类
from pycaret.clustering import ClusteringExperiment
exp = ClusteringExperiment()
# 检查exp的类型
type(exp)
pycaret.clustering.oop.ClusteringExperiment
# 初始化实验设置
exp.setup(data, session_id=123) # 设置实验的数据和会话ID为123
| Description | Value | |
|---|---|---|
| 0 | Session id | 123 |
| 1 | Original data shape | (505, 4) |
| 2 | Transformed data shape | (505, 4) |
| 3 | Numeric features | 4 |
| 4 | Preprocess | True |
| 5 | Imputation type | simple |
| 6 | Numeric imputation | mean |
| 7 | Categorical imputation | mode |
| 8 | CPU Jobs | -1 |
| 9 | Use GPU | False |
| 10 | Log Experiment | False |
| 11 | Experiment Name | cluster-default-name |
| 12 | USI | 6c6d |
<pycaret.clustering.oop.ClusteringExperiment at 0x16a6fe44e50>
你可以使用任何两种方法,即函数式或面向对象编程,并且可以在两组API之间来回切换。选择的方法不会影响结果,并且已经进行了一致性测试。
创建模型
该函数训练并评估给定模型的性能。可以使用get_metrics函数访问评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。可以使用models函数访问所有可用的模型。
# 导入所需的库
from pycaret.clustering import create_model
# 创建一个kmeans模型
kmeans = create_model('kmeans')
| Silhouette | Calinski-Harabasz | Davies-Bouldin | Homogeneity | Rand Index | Completeness | |
|---|---|---|---|---|---|---|
| 0 | 0.7207 | 5011.8115 | 0.4114 | 0 | 0 | 0 |
Processing: 0%| | 0/3 [00:00<?, ?it/s]
# 查看所有可用的模型
models()
| Name | Reference | |
|---|---|---|
| ID | ||
| kmeans | K-Means Clustering | sklearn.cluster._kmeans.KMeans |
| ap | Affinity Propagation | sklearn.cluster._affinity_propagation.Affinity... |
| meanshift | Mean Shift Clustering | sklearn.cluster._mean_shift.MeanShift |
| sc | Spectral Clustering | sklearn.cluster._spectral.SpectralClustering |
| hclust | Agglomerative Clustering | sklearn.cluster._agglomerative.AgglomerativeCl... |
| dbscan | Density-Based Spatial Clustering | sklearn.cluster._dbscan.DBSCAN |
| optics | OPTICS Clustering | sklearn.cluster._optics.OPTICS |
| birch | Birch Clustering | sklearn.cluster._birch.Birch |
| kmodes | K-Modes Clustering | kmodes.kmodes.KModes |
# 创建一个MeanShift模型
meanshift = MeanShift()
| Silhouette | Calinski-Harabasz | Davies-Bouldin | Homogeneity | Rand Index | Completeness | |
|---|---|---|---|---|---|---|
| 0 | 0.7393 | 3567.5370 | 0.3435 | 0 | 0 | 0 |
Processing: 0%| | 0/3 [00:00<?, ?it/s]
分配模型
该函数将训练数据分配给已训练的模型,并给出聚类标签。
# 对kmeans模型进行聚类分配
kmeans_cluster = assign_model(kmeans)
kmeans_cluster
| Age | Income | SpendingScore | Savings | Cluster | |
|---|---|---|---|---|---|
| 0 | 58 | 77769 | 0.791329 | 6559.830078 | Cluster 2 |
| 1 | 59 | 81799 | 0.791082 | 5417.661621 | Cluster 2 |
| 2 | 62 | 74751 | 0.702657 | 9258.993164 | Cluster 2 |
| 3 | 59 | 74373 | 0.765680 | 7346.334473 | Cluster 2 |
| 4 | 87 | 17760 | 0.348778 | 16869.507812 | Cluster 0 |
| ... | ... | ... | ... | ... | ... |
| 500 | 28 | 101206 | 0.387441 | 14936.775391 | Cluster 1 |
| 501 | 93 | 19934 | 0.203140 | 17969.693359 | Cluster 0 |
| 502 | 90 | 35297 | 0.355149 | 16091.402344 | Cluster 0 |
| 503 | 91 | 20681 | 0.354679 | 18401.087891 | Cluster 0 |
| 504 | 89 | 30267 | 0.289310 | 14386.351562 | Cluster 0 |
505 rows × 5 columns
分析模型
您可以使用plot_model函数来分析已训练模型在测试集上的性能。在某些情况下,可能需要重新训练模型。
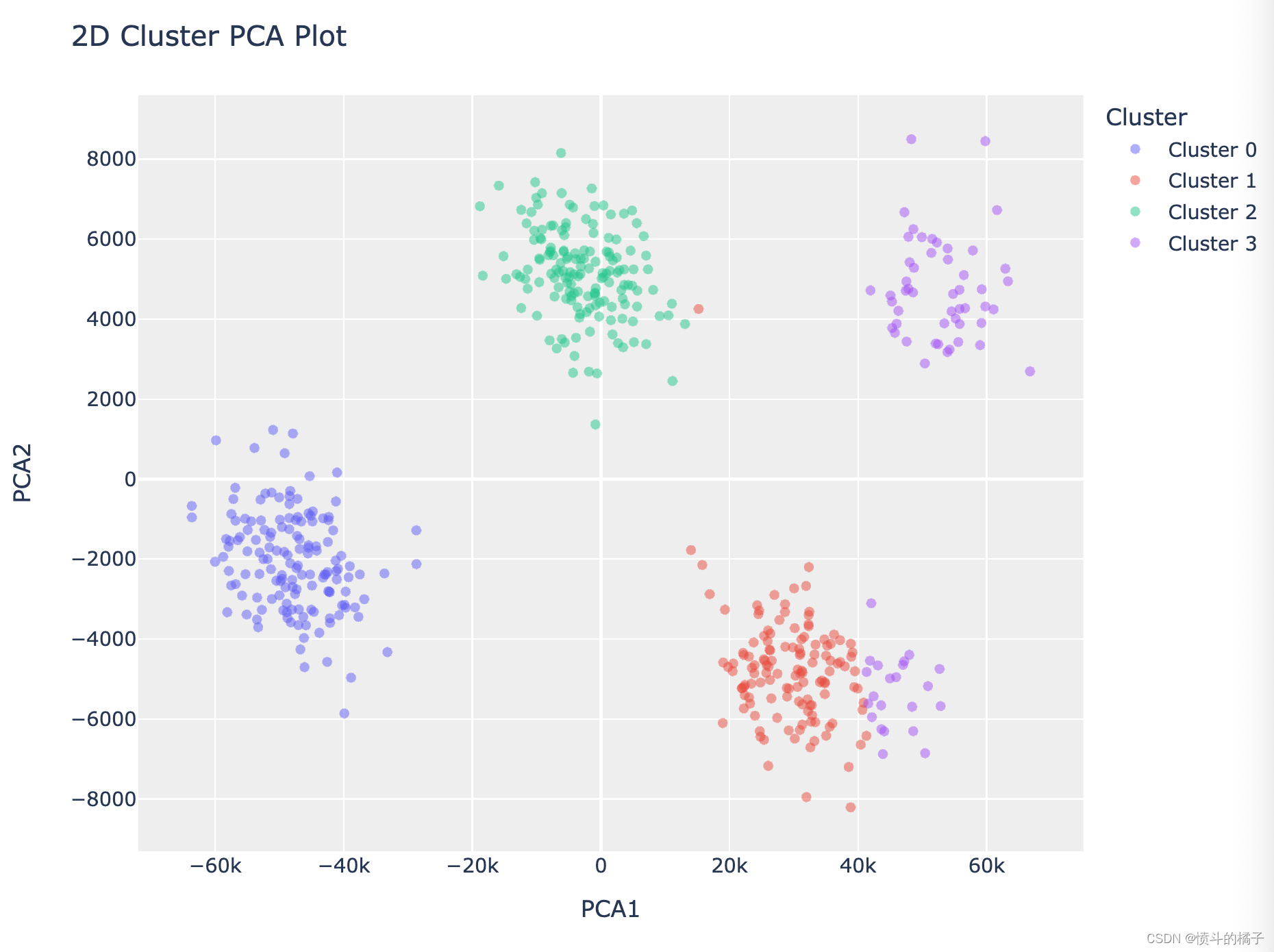
# 绘制PCA聚类图
plot_model(kmeans, plot='cluster')
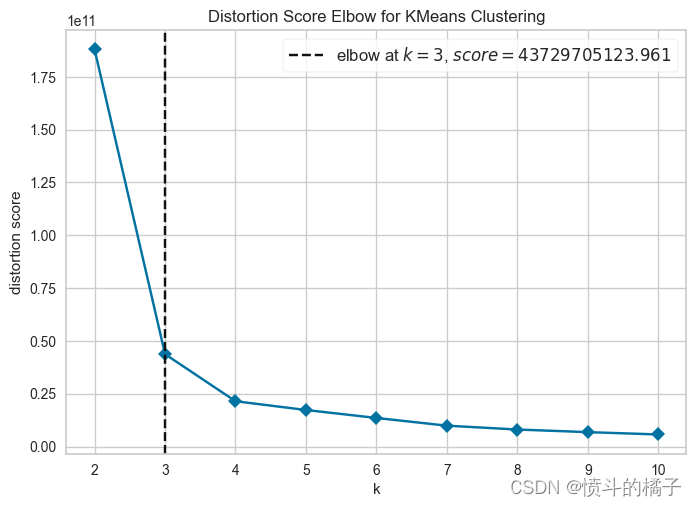
# plot elbow
plot_model(kmeans, plot = 'elbow')
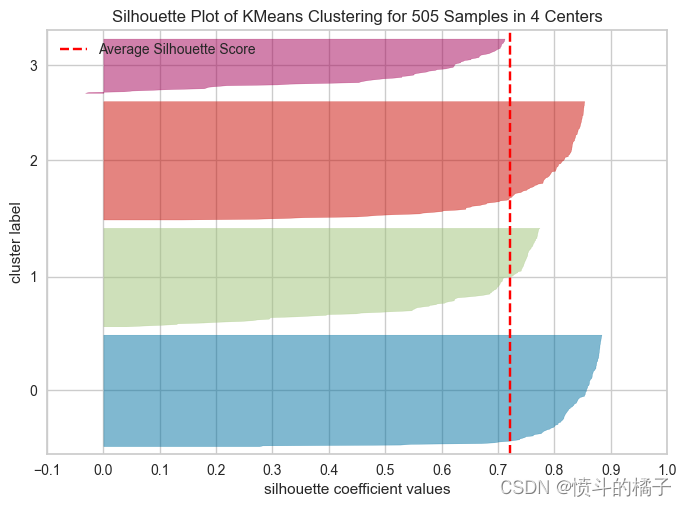
# 创建SilhouetteVisualizer对象,用于绘制轮廓图
plot_model(kmeans, plot = 'silhouette')
# check docstring to see available plots
# help(plot_model)
一种替代plot_model函数的方法是evaluate_model。它只能在Notebook中使用,因为它使用了ipywidget。
# 调用evaluate_model函数,传入kmeans模型进行评估
evaluate_model(kmeans)
interactive(children=(ToggleButtons(description='Plot Type:', icons=('',), options=(('Pipeline Plot', 'pipelin…
预测
predict_model 函数将 Cluster 标签作为输入数据框的新列返回。根据使用情况,可能需要或不需要此步骤。有时聚类模型仅用于分析目的,用户只对训练数据集上的分配标签感兴趣,可以使用 assign_model 函数完成。只有在您想要在未见过的数据上获取聚类标签时(即在训练模型期间未使用的数据),predict_model 才有用。
# 使用K-means模型对测试集进行预测
kmeans_pred = predict_model(kmeans, data=data)
kmeans_pred
| Age | Income | SpendingScore | Savings | Cluster | |
|---|---|---|---|---|---|
| 0 | 58.0 | 77769.0 | 0.791329 | 6559.829923 | Cluster 2 |
| 1 | 59.0 | 81799.0 | 0.791082 | 5417.661426 | Cluster 2 |
| 2 | 62.0 | 74751.0 | 0.702657 | 9258.992965 | Cluster 2 |
| 3 | 59.0 | 74373.0 | 0.765680 | 7346.334504 | Cluster 2 |
| 4 | 87.0 | 17760.0 | 0.348778 | 16869.507130 | Cluster 0 |
| ... | ... | ... | ... | ... | ... |
| 500 | 28.0 | 101206.0 | 0.387441 | 14936.775389 | Cluster 1 |
| 501 | 93.0 | 19934.0 | 0.203140 | 17969.693769 | Cluster 0 |
| 502 | 90.0 | 35297.0 | 0.355149 | 16091.401954 | Cluster 0 |
| 503 | 91.0 | 20681.0 | 0.354679 | 18401.088445 | Cluster 0 |
| 504 | 89.0 | 30267.0 | 0.289310 | 14386.351880 | Cluster 0 |
505 rows × 5 columns
保存模型
最后,您可以使用pycaret的save_model函数将整个流水线保存到磁盘上以供以后使用。
# 调用save_model函数保存模型
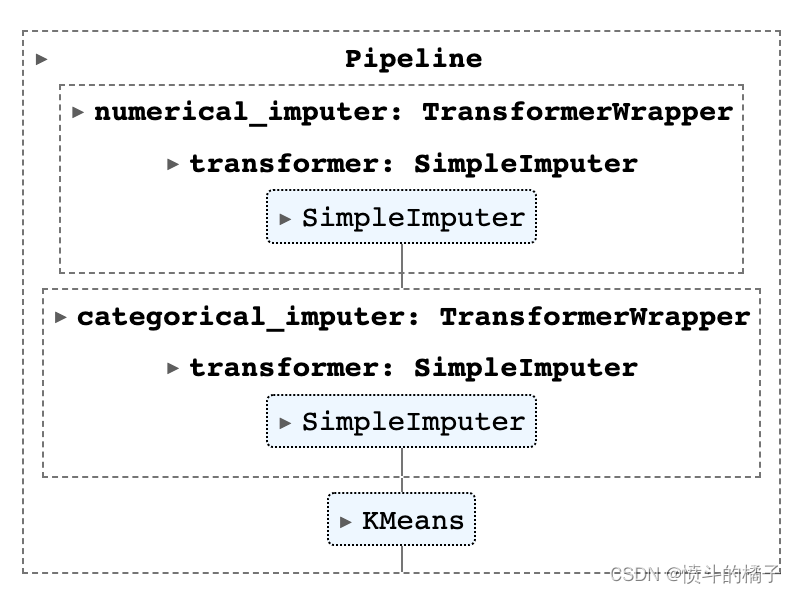
save_model(kmeans, 'kmeans_pipeline')
Transformation Pipeline and Model Successfully Saved
(Pipeline(memory=FastMemory(location=C:\Users\owner\AppData\Local\Temp\joblib),
steps=[('numerical_imputer',
TransformerWrapper(include=['Age', 'Income', 'SpendingScore',
'Savings'],
transformer=SimpleImputer())),
('categorical_imputer',
TransformerWrapper(include=[],
transformer=SimpleImputer(strategy='most_frequent'))),
('trained_model', KMeans(n_clusters=4, random_state=123))]),
'kmeans_pipeline.pkl')
# 加载模型
kmeans_pipeline = load_model('kmeans_pipeline')
kmeans_pipeline
Transformation Pipeline and Model Successfully Loaded
👇 详细的逐个函数概述
✅ 设置
此函数初始化训练环境并创建转换流水线。在执行PyCaret中的任何其他函数之前,必须调用设置函数。它只有一个必需的参数,即data。所有其他参数都是可选的。
# 初始化设置
s = setup(data, session_id=123)
| Description | Value | |
|---|---|---|
| 0 | Session id | 123 |
| 1 | Original data shape | (505, 4) |
| 2 | Transformed data shape | (505, 4) |
| 3 | Numeric features | 4 |
| 4 | Preprocess | True |
| 5 | Imputation type | simple |
| 6 | Numeric imputation | mean |
| 7 | Categorical imputation | mode |
| 8 | CPU Jobs | -1 |
| 9 | Use GPU | False |
| 10 | Log Experiment | False |
| 11 | Experiment Name | cluster-default-name |
| 12 | USI | 89ea |
为了访问由设置函数创建的所有变量,例如转换后的数据集、随机状态等,您可以使用get_config方法。
# 获取所有可用的配置信息
get_config()
{'USI',
'X',
'X_train',
'X_train_transformed',
'X_transformed',
'_available_plots',
'_ml_usecase',
'data',
'dataset',
'dataset_transformed',
'exp_id',
'exp_name_log',
'gpu_n_jobs_param',
'gpu_param',
'html_param',
'idx',
'is_multiclass',
'log_plots_param',
'logging_param',
'memory',
'n_jobs_param',
'pipeline',
'seed',
'train',
'train_transformed',
'variable_and_property_keys',
'variables'}
# 获取配置中的 'X_train_transformed' 数据
get_config('X_train_transformed')
| Age | Income | SpendingScore | Savings | |
|---|---|---|---|---|
| 0 | 58.0 | 77769.0 | 0.791329 | 6559.830078 |
| 1 | 59.0 | 81799.0 | 0.791082 | 5417.661621 |
| 2 | 62.0 | 74751.0 | 0.702657 | 9258.993164 |
| 3 | 59.0 | 74373.0 | 0.765680 | 7346.334473 |
| 4 | 87.0 | 17760.0 | 0.348778 | 16869.507812 |
| ... | ... | ... | ... | ... |
| 500 | 28.0 | 101206.0 | 0.387441 | 14936.775391 |
| 501 | 93.0 | 19934.0 | 0.203140 | 17969.693359 |
| 502 | 90.0 | 35297.0 | 0.355149 | 16091.402344 |
| 503 | 91.0 | 20681.0 | 0.354679 | 18401.087891 |
| 504 | 89.0 | 30267.0 | 0.289310 | 14386.351562 |
505 rows × 4 columns
# 打印当前的种子值
print("当前的种子值为: {}".format(get_config('seed')))
# 使用set_config函数来改变种子值
set_config('seed', 786)
# 打印新的种子值
print("新的种子值为: {}".format(get_config('seed')))
The current seed is: 123
The new seed is: 786
所有的预处理配置和实验设置/参数都传递给setup函数。要查看所有可用的参数,请检查docstring:
# help(setup)
# 初始化设置,使用normalize = True
# 参数data是要进行处理的数据
# 参数session_id是设置的会话ID,用于跟踪和识别不同的会话
# 参数normalize设置为True,表示对数据进行归一化处理
# 参数normalize_method设置为'minmax',表示使用最小-最大归一化方法进行归一化处理
# 返回值s是初始化设置后的结果,可以用于后续的操作
s = setup(data, session_id = 123,
normalize = True, normalize_method = 'minmax')
| Description | Value | |
|---|---|---|
| 0 | Session id | 123 |
| 1 | Original data shape | (505, 4) |
| 2 | Transformed data shape | (505, 4) |
| 3 | Numeric features | 4 |
| 4 | Preprocess | True |
| 5 | Imputation type | simple |
| 6 | Numeric imputation | mean |
| 7 | Categorical imputation | mode |
| 8 | Normalize | True |
| 9 | Normalize method | minmax |
| 10 | CPU Jobs | -1 |
| 11 | Use GPU | False |
| 12 | Log Experiment | False |
| 13 | Experiment Name | cluster-default-name |
| 14 | USI | cded |
# 获取X_train_transformed的配置信息,并查看参数的效果
config = get_config('X_train_transformed')
# 绘制'Age'列的直方图
config['Age'].hist()
<AxesSubplot:>
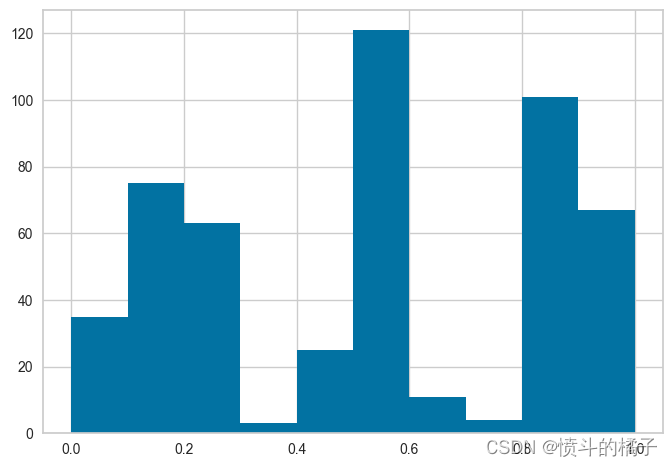
请注意,所有的值都在0和1之间 - 这是因为我们在setup函数中传递了normalize=True。如果你不记得它与实际数据的比较方式,没问题 - 我们也可以使用get_config来访问非转换的值,然后进行比较。请参见下面的内容,并注意x轴上的值范围,并将其与上面的直方图进行比较。
# 获取配置文件中的训练数据集X_train的年龄直方图
get_config('X_train')['Age'].hist()
<AxesSubplot:>
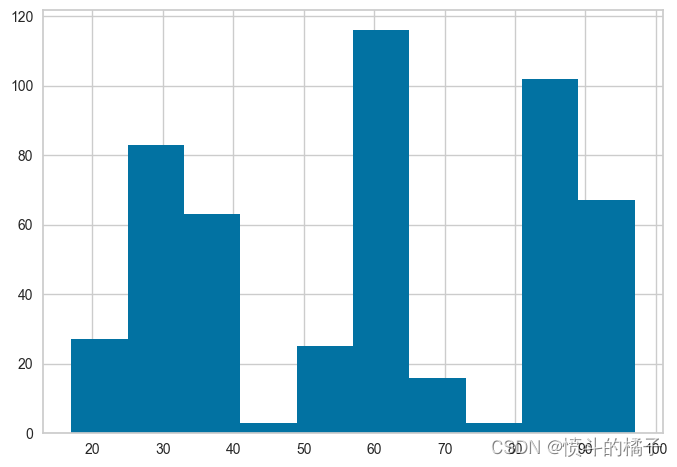
✅ 实验日志记录
PyCaret与许多不同类型的实验记录器集成(默认为’mlflow’)。要在PyCaret中启用实验跟踪,您可以设置log_experiment和experiment_name参数。它将根据定义的记录器自动跟踪所有指标、超参数和工件。
# 导入所需的库
from pycaret.clustering import *
# 设置实验
# data: 数据集
# log_experiment: 是否记录实验日志到mlflow
# experiment_name: 实验名称
# s = setup(data, log_experiment='mlflow', experiment_name='jewellery_project')
# train kmeans
# kmeans = create_model('kmeans')
# 启动mlflow的用户界面
!mlflow ui
默认情况下,PyCaret使用MLFlow日志记录器,可以使用log_experiment参数进行更改。以下日志记录器可用:
- mlflow
- wandb
- comet_ml
- dagshub
您可能会发现有用的其他日志记录相关参数有:
- experiment_custom_tags
- log_plots
- log_data
- log_profile
有关更多信息,请查看setup函数的文档字符串。
# help(setup)
✅ 创建模型
该函数使用交叉验证训练和评估给定估计器的性能。该函数的输出是一个包含每个折叠的CV分数的评分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。可以使用models函数访问所有可用的模型。
# 检查所有可用的模型
models()
| Name | Reference | |
|---|---|---|
| ID | ||
| kmeans | K-Means Clustering | sklearn.cluster._kmeans.KMeans |
| ap | Affinity Propagation | sklearn.cluster._affinity_propagation.Affinity... |
| meanshift | Mean Shift Clustering | sklearn.cluster._mean_shift.MeanShift |
| sc | Spectral Clustering | sklearn.cluster._spectral.SpectralClustering |
| hclust | Agglomerative Clustering | sklearn.cluster._agglomerative.AgglomerativeCl... |
| dbscan | Density-Based Spatial Clustering | sklearn.cluster._dbscan.DBSCAN |
| optics | OPTICS Clustering | sklearn.cluster._optics.OPTICS |
| birch | Birch Clustering | sklearn.cluster._birch.Birch |
| kmodes | K-Modes Clustering | kmodes.kmodes.KModes |
# 创建一个kmeans模型
kmeans = create_model('kmeans')
| Silhouette | Calinski-Harabasz | Davies-Bouldin | Homogeneity | Rand Index | Completeness | |
|---|---|---|---|---|---|---|
| 0 | 0.7569 | 1449.9983 | 0.3958 | 0 | 0 | 0 |
Processing: 0%| | 0/3 [00:00<?, ?it/s]
功能以上返回训练好的模型对象作为输出。评分表格仅显示而不返回。如果您需要访问评分表格,可以使用pull函数访问数据框。
# 调用pull函数获取kmeans_results
kmeans_results = pull()
# 打印kmeans_results的数据类型
print(type(kmeans_results))
# 输出kmeans_results的值
kmeans_results
<class 'pandas.core.frame.DataFrame'>
| Silhouette | Calinski-Harabasz | Davies-Bouldin | Homogeneity | Rand Index | Completeness | |
|---|---|---|---|---|---|---|
| 0 | 0.7569 | 1449.9983 | 0.3958 | 0 | 0 | 0 |
# 使用create_model函数创建一个包含10个聚类的kmeans模型
create_model('kmeans', num_clusters=10)
| Silhouette | Calinski-Harabasz | Davies-Bouldin | Homogeneity | Rand Index | Completeness | |
|---|---|---|---|---|---|---|
| 0 | 0.2828 | 2304.6187 | 1.3370 | 0 | 0 | 0 |
Processing: 0%| | 0/3 [00:00<?, ?it/s]

一些在create_model中可能非常有用的其他参数有:
- num_clusters
- ground_truth
- fit_kwargs
- experiment_custom_tags
- engine
您可以查看函数的文档字符串以获取更多信息。
create_model('kmeans', num_clusters = 10)
✅ 分配模型
该函数将训练数据分配给已训练的模型,并为其分配聚类标签。
# 调用assign_model函数,并将KMeans模型作为参数传入
assign_model(KMeans)
| Age | Income | SpendingScore | Savings | Cluster | |
|---|---|---|---|---|---|
| 0 | 58 | 77769 | 0.791329 | 6559.830078 | Cluster 1 |
| 1 | 59 | 81799 | 0.791082 | 5417.661621 | Cluster 1 |
| 2 | 62 | 74751 | 0.702657 | 9258.993164 | Cluster 1 |
| 3 | 59 | 74373 | 0.765680 | 7346.334473 | Cluster 1 |
| 4 | 87 | 17760 | 0.348778 | 16869.507812 | Cluster 0 |
| ... | ... | ... | ... | ... | ... |
| 500 | 28 | 101206 | 0.387441 | 14936.775391 | Cluster 2 |
| 501 | 93 | 19934 | 0.203140 | 17969.693359 | Cluster 0 |
| 502 | 90 | 35297 | 0.355149 | 16091.402344 | Cluster 0 |
| 503 | 91 | 20681 | 0.354679 | 18401.087891 | Cluster 0 |
| 504 | 89 | 30267 | 0.289310 | 14386.351562 | Cluster 0 |
505 rows × 5 columns
✅ 绘制模型
该函数分析训练模型的性能。
# 使用 KElbowVisualizer 可视化模型的拐点图
# 通过设置 plot 参数为 'elbow',可以绘制拐点图
# 通过设置 scale 参数为 2,可以控制图形的缩放比例
plot_model(kmeans, plot='elbow', scale=2)
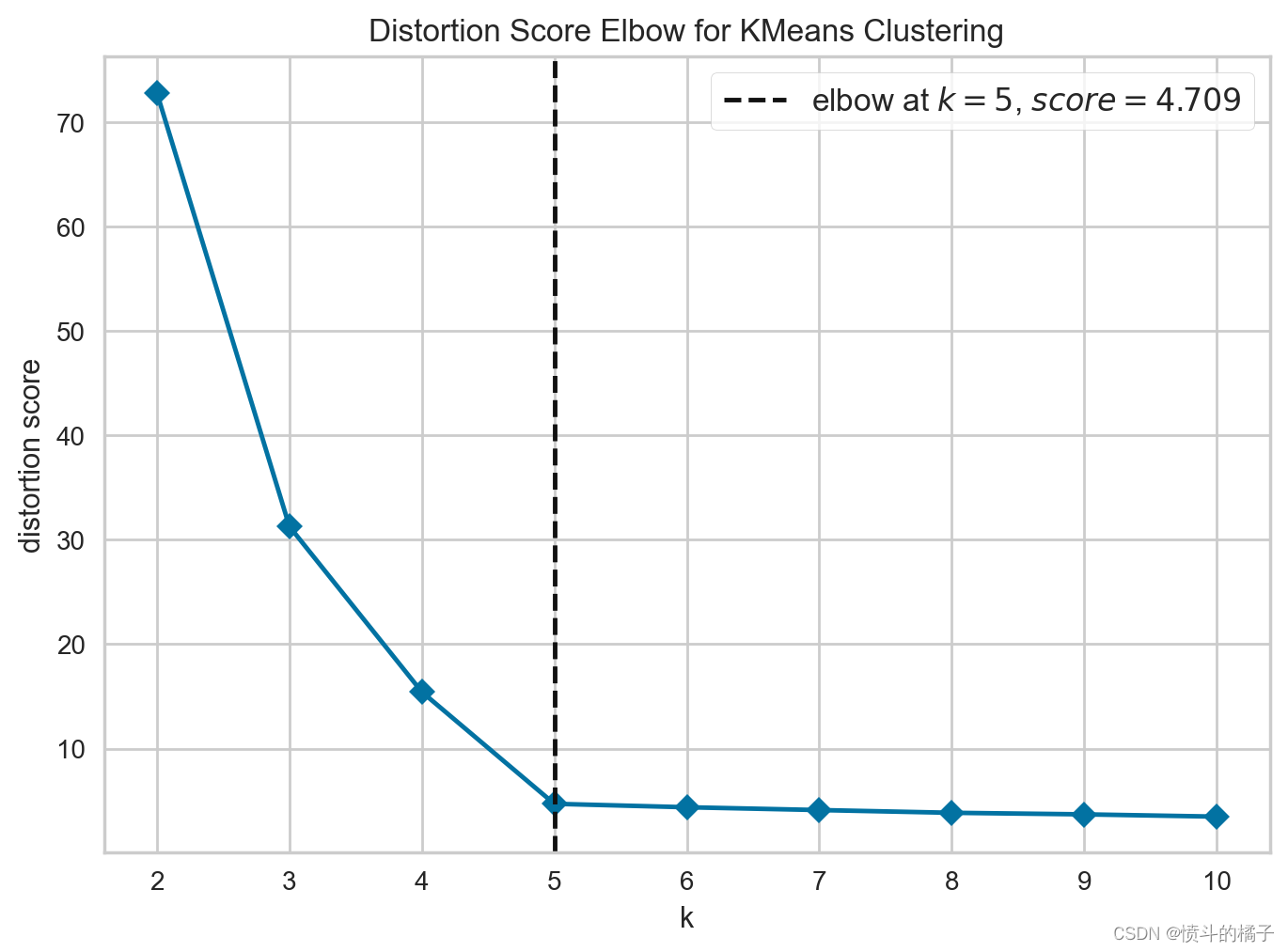
# 使用elbow方法绘制聚类模型的图形
# 参数plot='elbow'表示绘制elbow图
# 参数save=True表示保存图形
plot_model(kmeans, plot='elbow', save=True)
'Elbow Plot.png'
一些在plot_model中可能非常有用的其他参数包括:
- 特征
- 标签
- 显示格式
您可以查看函数的文档字符串以获取更多信息。
# help(plot_model)
✅ 部署模型
此函数将整个机器学习流程部署到云端。
AWS: 在AWS S3上部署模型时,必须使用命令行界面配置环境变量。要配置AWS环境变量,请在终端中输入aws configure命令。以下信息是必需的,可以使用您的Amazon控制台帐户的身份和访问管理(IAM)门户生成:
- AWS访问密钥ID
- AWS秘密密钥访问
- 默认区域名称(可以在AWS控制台的全局设置下看到)
- 默认输出格式(必须留空)
GCP: 要在Google Cloud Platform(‘gcp’)上部署模型,必须使用命令行或GCP控制台创建项目。创建项目后,您必须创建一个服务帐号,并将服务帐号密钥下载为JSON文件,以在本地环境中设置环境变量。了解更多信息:https://cloud.google.com/docs/authentication/production
Azure: 要在Microsoft Azure(‘azure’)上部署模型,必须在本地环境中设置用于连接字符串的环境变量。转到Azure门户上的存储帐户设置以访问所需的连接字符串。
AZURE_STORAGE_CONNECTION_STRING(作为环境变量必需)
了解更多信息:https://docs.microsoft.com/en-us/azure/storage/blobs/storage-quickstart-blobs-python?toc=%2Fpython%2Fazure%2FTOC.json
# 部署模型到AWS S3
deploy_model(kmeans, model_name='my_first_platform_on_aws', platform='aws', authentication={'bucket': 'pycaret-test'})
# 从AWS S3加载模型
# 从AWS S3加载模型,模型名称为'my_first_platform_on_aws',平台为'aws'
# 需要进行身份验证,验证方式为使用存储桶(bucket)的身份验证
# 加载完成后,将结果保存在loaded_from_aws变量中
# load model from aws s3
loaded_from_aws = load_model(model_name = 'my_first_platform_on_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
loaded_from_aws
✅ 保存/加载模型
这个函数将转换流水线和训练好的模型对象保存为pickle文件,以便以后使用,保存在当前工作目录中。
# 调用保存模型的函数,将kmeans模型保存为'my_first_model'文件
save_model(kmeans, 'my_first_model')
Transformation Pipeline and Model Successfully Saved
(Pipeline(memory=FastMemory(location=C:\Users\owner\AppData\Local\Temp\joblib),
steps=[('numerical_imputer',
TransformerWrapper(include=['Age', 'Income', 'SpendingScore',
'Savings'],
transformer=SimpleImputer())),
('categorical_imputer',
TransformerWrapper(include=[],
transformer=SimpleImputer(strategy='most_frequent'))),
('normalize', TransformerWrapper(transformer=MinMaxScaler())),
('trained_model', KMeans(n_clusters=4, random_state=123))]),
'my_first_model.pkl')
# 加载模型
loaded_from_disk = load_model('my_first_model')
loaded_from_disk
# 从磁盘中加载模型文件 'my_first_model',并将其赋值给变量 loaded_from_disk
Transformation Pipeline and Model Successfully Loaded

✅ 保存/加载实验
该函数将实验中的所有变量保存到磁盘上,以便以后恢复而无需重新运行设置函数。
# 保存实验
save_experiment('my_experiment')
# 从磁盘加载实验
exp_from_disk = load_experiment('my_experiment', data=data)
| Description | Value | |
|---|---|---|
| 0 | Session id | 123 |
| 1 | Original data shape | (505, 4) |
| 2 | Transformed data shape | (505, 4) |
| 3 | Numeric features | 4 |
| 4 | Preprocess | True |
| 5 | Imputation type | simple |
| 6 | Numeric imputation | mean |
| 7 | Categorical imputation | mode |
| 8 | Normalize | True |
| 9 | Normalize method | minmax |
| 10 | CPU Jobs | -1 |
| 11 | Use GPU | False |
| 12 | Log Experiment | False |
| 13 | Experiment Name | cluster-default-name |
| 14 | USI | 79ce |

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)