InnoDB 独立表空间(ibd 文件)迁移实战指南
本文深入解析InnoDB独立表空间(ibd文件)迁移技术,涵盖表空间架构、迁移原理、实战案例及自动化工具建设。重点包括:1)InnoDB表空间类型对比与核心优势分析;2)ibd文件结构详解及SDI信息提取方法;3)标准迁移流程与跨服务器优化方案;4)企业级场景如大表迁移、数据恢复实施指南;5)常见问题排查与性能优化技巧;6)自动化脚本与监控工具设计方案。通过系统化的理论讲解和实战演示,帮助读者掌握
一、InnoDB 表空间架构深度解析
1. InnoDB 存储引擎架构概述
InnoDB 作为 MySQL 的默认存储引擎,其表空间架构是数据存储和管理的核心。理解表空间架构是掌握 ibd 文件迁移技术的基础。
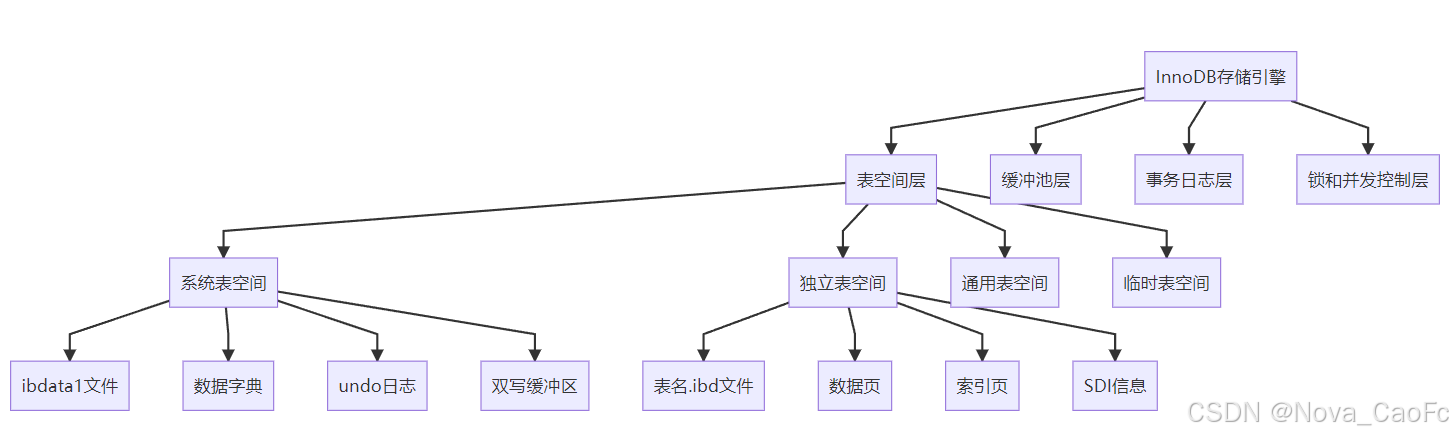
1.1 表空间类型对比分析
|
表空间类型 |
存储方式 |
优点 |
缺点 |
适用场景 |
|
系统表空间 |
所有表共享一个或多个文件 |
管理简单,适合小数据量 |
单文件过大,性能瓶颈,难以维护 |
MySQL 早期版本,小数据库 |
|
独立表空间 |
每个表一个 ibd 文件 |
管理灵活,性能优异,便于迁移 |
文件数量多,需要更多文件描述符 |
生产环境,大表管理 |
|
通用表空间 |
多个表共享一个文件 |
平衡了两种方式的优缺点 |
管理复杂度增加 |
特定场景的表组管理 |
|
临时表空间 |
存储临时表数据 |
自动管理,不影响业务数据 |
会话结束自动清理 |
临时数据处理 |
2. 独立表空间核心优势
2.1 性能优势分析
I/O 性能优化:
- 每个表有独立的 I/O 路径,减少竞争
- 可以将热点表放在高性能存储设备上
- 表删除时可以立即释放磁盘空间
维护操作隔离:
- 单个表的 OPTIMIZE TABLE 操作不影响其他表
- 表空间可以独立进行备份和恢复
- 便于实现数据的冷热分离存储
2.2 管理灵活性
精细的存储管理:
-- 查看表空间使用情况
-- 查看表空间使用情况
SELECT
TABLE_SCHEMA,
TABLE_NAME,
ROUND(DATA_LENGTH/1024/1024, 2) AS DATA_SIZE_MB,
ROUND(INDEX_LENGTH/1024/1024, 2) AS INDEX_SIZE_MB,
ROUND((DATA_LENGTH + INDEX_LENGTH)/1024/1024, 2) AS TOTAL_SIZE_MB
FROM
information_schema.TABLES
WHERE
ENGINE = 'InnoDB'
AND TABLE_SCHEMA NOT IN ('mysql', 'information_schema', 'performance_schema', 'sys')
ORDER BY
TOTAL_SIZE_MB DESC;3.1 ibd 文件组成结构
InnoDB 的 .ibd 文件是独立表空间的核心存储文件,包含了表的所有数据、索引及元信息,其内部结构复杂且高度结构化。每个 ibd 文件由以下关键部分组成,各部分协同工作以保证数据的存储、索引和一致性:
| 组成部分 | 位置范围 | 核心作用 | 关键信息点 |
|---|---|---|---|
| 文件头(File Header) | 文件起始位置(前 38 字节) | 标识文件属性,确保文件合法性和兼容性 | 包含「魔术数字」(验证文件格式)、表空间版本号、页大小(如 16KB)、表空间 ID(唯一标识)等。 |
| 数据页(Data Pages) | 文件头之后的主要区域 | 存储表的实际数据记录(行数据) | 每个数据页大小固定(由 innodb_page_size 定义,默认 16KB),包含页头(Page Header)、用户记录、页目录(快速定位记录)、页尾校验(Checksum)。 |
| 索引页(Index Pages) | 与数据页混合存储 | 存储 B + 树索引结构,包括主键索引和二级索引 | 主键索引页直接关联数据页(聚簇索引特性),二级索引页存储索引键和主键值,通过主键关联数据。 |
| SDI 数据(Serialized Data Dictionary Information) | 分散在特定页中(如页类型为 SDI 的页) | 存储表结构元数据(MySQL 5.7+) | 包含表名、字段定义、数据类型、索引信息、字符集等,替代了旧版本的 .frm 文件功能。 |
| undo 日志段(Undo Log Segments) | 表空间预留区域 | 存储事务回滚所需的旧版本数据(仅当表使用独立 undo 日志时) | 支持事务的原子性和隔离性,默认情况下 undo 日志可能存储在系统表空间(ibdata1)中。 |
| 空闲空间(Free Space) | 文件中未使用的区域 | 预留空间用于新数据插入或现有数据更新,减少文件频繁扩展的性能开销 | 当空闲空间不足时,ibd 文件会自动扩展(受 innodb_autoextend_increment 控制)。 |
| 文件尾(File Trailer) | 文件末尾(最后 8 字节) | 存储文件校验信息,确保文件完整性 | 包含页校验和(Checksum)和日志序列号(LSN),用于检测文件损坏或不一致。 |
各部分关键细节说明:
-
文件头(File Header)是 ibd 文件的「身份证」,数据库启动时会首先校验文件头的魔术数字(如
0x4942444E,即 "IBDN"),确认文件为有效的 InnoDB 表空间文件。表空间 ID 需与数据库数据字典中的记录匹配,否则会导致「表空间标识符不匹配」错误。 -
数据页与索引页两者均采用固定大小的页结构(默认 16KB),通过页头的「页类型」字段区分(如数据页类型为
FIL_PAGE_DATA,索引页类型为FIL_PAGE_INDEX)。页尾的校验和用于检测页损坏,确保数据在写入和读取过程中未被篡改。 -
SDI 数据MySQL 5.7 及以上版本将表结构信息以 JSON 格式嵌入 ibd 文件,可通过
ibd2sdi工具提取。这一设计使得即使丢失.frm文件,也能从 ibd 文件中恢复表结构,是独立表空间迁移的关键依赖。 -
空闲空间管理InnoDB 会主动管理空闲空间,避免频繁的文件系统操作。例如,删除数据后,空间不会立即释放给操作系统,而是标记为「可重用」,供后续插入使用(需执行
OPTIMIZE TABLE才能真正释放磁盘空间)。
3.2 SDI 信息详解
SDI(Serialized Data Dictionary Information) 是 MySQL 5.7 及以上版本引入的重要特性,它将表结构信息直接存储在 ibd 文件中:
{
"dd_version": 80023,
"sdid": 1,
"dd_object_type": "Table",
"dd_object": {
"name": "user",
"schema_id": 1,
"mysql_version_id": 80023,
"created": "2025-10-22 10:00:00",
"last_altered": "2025-10-22 10:00:00",
"hidden": 0,
"avg_row_length": 0,
"auto_increment": 1,
"charset_id": 45,
"collation_id": 45,
"comment": "",
"compression": "",
"create_options": "",
"data_length": 0,
"data_free": 0,
"engine": "InnoDB",
"flags": 0,
"force_primary_key": 0,
"id": 101,
"index_length": 0,
"initial_auto_increment": 1,
"insert_id": 0,
"max_rows": 0,
"min_rows": 0,
"row_format": "Dynamic",
"schema_ref": "test",
"se_private_data": "ibd_file_name=user.ibd;ibd_file_size=114688;table_id=101",
"secondary_engine": "",
"secondary_engine_attribute": "",
"table_type": "BASE TABLE",
"tablespace_id": 2,
"version": 0,
"view_definition": "",
"view_definition_utf8": "",
"view_check_option": "NONE",
"view_algorithm": "UNDEFINED",
"view_security": "DEFINER",
"create_statement": "CREATE TABLE `user` (\n `id` int NOT NULL AUTO_INCREMENT,\n `name` varchar(50) NOT NULL,\n `email` varchar(100) DEFAULT NULL,\n PRIMARY KEY (`id`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci"
}
}二、独立表空间迁移基础理论
1. 迁移原理深度剖析
1.1 核心原理
ibd 文件迁移的本质是将表的数据文件从一个数据库实例复制到另一个实例,并让目标实例能够正确识别和使用这些数据。这个过程涉及到以下关键技术点:
表空间标识验证:
每个 ibd 文件都有唯一的表空间 ID,目标实例需要验证这个 ID 与数据字典中的信息是否匹配。
数据一致性保证:
迁移过程中必须确保 ibd 文件处于一致性状态,避免数据损坏。
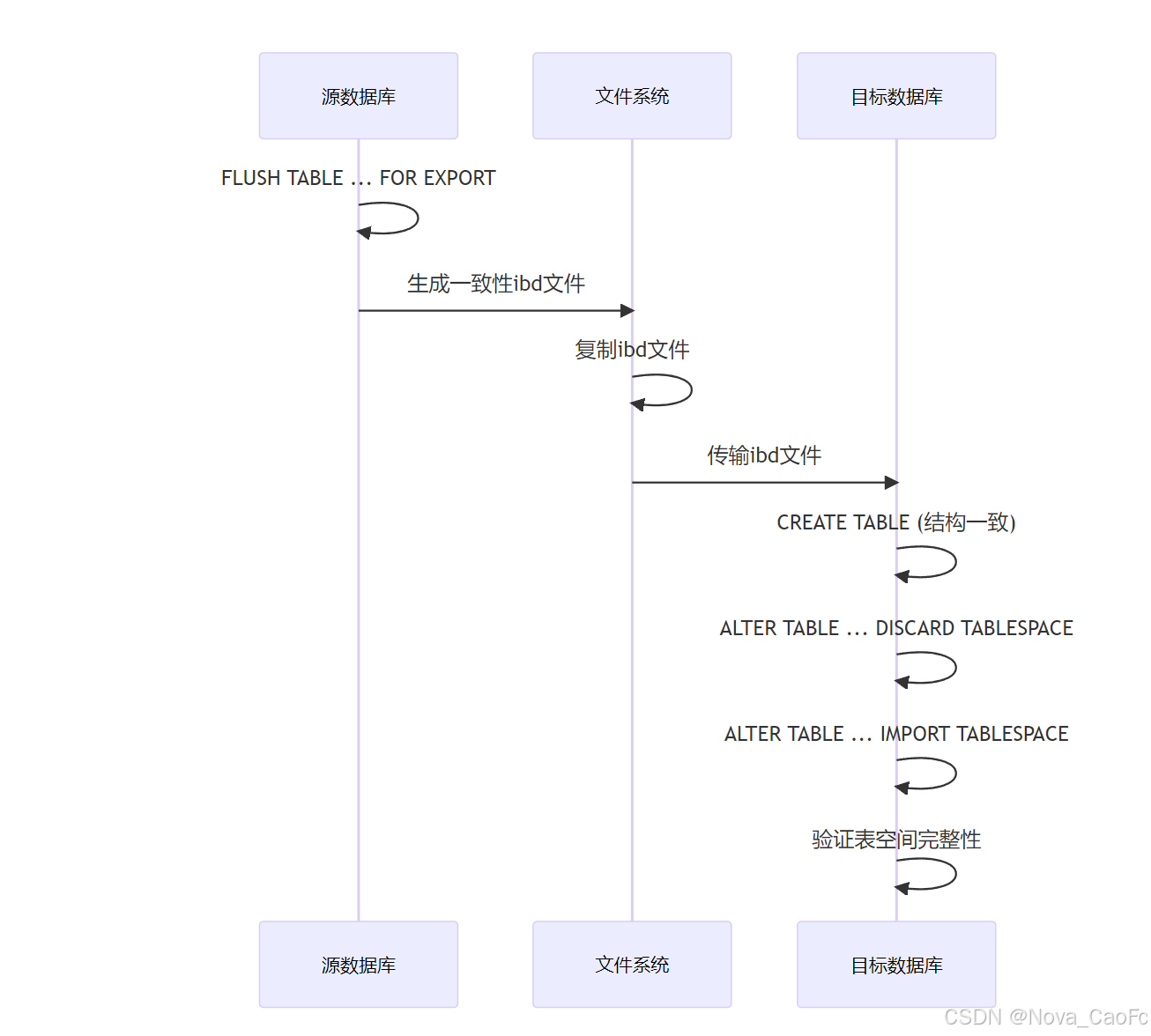
1.2 迁移过程数据流
2. 迁移前提条件验证
2.1 环境检查清单
1. 独立表空间配置验证:
-- 检查独立表空间是否开启
SHOW VARIABLES LIKE 'innodb_file_per_table';
-- 期望结果:innodb_file_per_table | ON2. MySQL 版本兼容性检查:
-- 查看MySQL版本
SELECT VERSION();
-- 检查innodb版本
SHOW VARIABLES LIKE 'innodb_version';版本兼容性矩阵:
|
源版本 |
目标版本 |
兼容性 |
备注 |
|
5.6.x |
5.6.x |
✅ |
完全兼容 |
|
5.6.x |
5.7.x |
⚠️ |
部分兼容,建议升级后迁移 |
|
5.7.x |
5.7.x |
✅ |
完全兼容 |
|
5.7.x |
8.0.x |
⚠️ |
需要特殊处理,建议使用逻辑备份 |
|
8.0.x |
8.0.x |
✅ |
完全兼容 |
2.2 表结构一致性检查
1. 表结构完整性验证:
-- 源库导出表结构
SHOW CREATE TABLE database_name.table_name;
-- 目标库创建表结构后验证
SHOW CREATE TABLE database_name.table_name;2. 表结构对比脚本:
#!/bin/bash
# 表结构对比脚本
SOURCE_HOST="source-db"
TARGET_HOST="target-db"
DB_NAME="your_database"
TABLE_NAME="your_table"
# 获取源库表结构
SOURCE_STRUCTURE=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "SHOW CREATE TABLE $DB_NAME.$TABLE_NAME;" | awk 'NR==2{print $0}')
# 获取目标库表结构
TARGET_STRUCTURE=$(mysql -h $TARGET_HOST -u root -p -N -B -e "SHOW CREATE TABLE $DB_NAME.$TABLE_NAME;" | awk 'NR==2{print $0}')
# 对比结构
if [ "$SOURCE_STRUCTURE" = "$TARGET_STRUCTURE" ]; then
echo "✅ 表结构一致"
else
echo "❌ 表结构不一致"
echo "源库结构: $SOURCE_STRUCTURE"
echo "目标库结构: $TARGET_STRUCTURE"
fi3. 性能影响评估
3.1 迁移过程性能开销
CPU 和 I/O 影响测试:
#!/bin/bash
# 迁移性能影响测试脚本
# 监控CPU使用率
echo "开始监控CPU使用率..."
top -bn1 | grep "Cpu(s)"
# 监控I/O性能
echo "开始测试磁盘I/O性能..."
dd if=/dev/zero of=/tmp/testfile bs=1M count=100 oflag=direct 2>&1 | grep copied
# 监控内存使用
echo "内存使用情况..."
free -h
# 监控网络带宽(如果跨服务器迁移)
echo "网络带宽测试..."
iperf3 -c target-server -t 10性能影响评估表:
|
迁移阶段 |
CPU 使用率 |
I/O 使用率 |
内存使用 |
网络带宽 |
业务影响 |
|
文件准备 |
低 (5-10%) |
中 (20-30%) |
低 |
无 |
无 |
|
文件复制 |
低 (5-15%) |
高 (60-80%) |
中 |
高 |
轻微 |
|
导入表空间 |
中 (20-40%) |
高 (50-70%) |
中 |
无 |
中等 |
|
验证阶段 |
中 (15-30%) |
中 (20-40%) |
低 |
无 |
轻微 |
三、完整迁移实战指南
1. 迁移前准备工作
1.1 环境准备清单
1. 目标环境配置:
# 1. 创建数据目录
mkdir -p /data/mysql/{data,log,tmp}
chown -R mysql:mysql /data/mysql/
# 2. 配置my.cnf
cat > /etc/my.cnf << EOF
[mysqld]
basedir=/usr/local/mysql
datadir=/data/mysql/data
socket=/tmp/mysql.sock
port=3306
user=mysql
# InnoDB配置
innodb_file_per_table=1
innodb_flush_log_at_trx_commit=1
sync_binlog=1
innodb_buffer_pool_size=2G
# 日志配置
log_error=/data/mysql/log/mysql-error.log
slow_query_log=1
slow_query_log_file=/data/mysql/log/mysql-slow.log
long_query_time=2
[mysql]
socket=/tmp/mysql.sock
EOF
# 3. 初始化数据库
mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/mysql/data
# 4. 启动MySQL服务
systemctl start mysqld
systemctl enable mysqld1.2 安全检查
1. 文件权限检查:
# 检查数据目录权限
ls -la /data/mysql/data/
# 检查ibd文件权限
ls -la /data/mysql/data/*/*.ibd
# 确保权限为mysql:mysql
chown -R mysql:mysql /data/mysql/
chmod 755 /data/mysql/
chmod 640 /data/mysql/data/*/*.ibd2. 网络连通性测试:
# 测试MySQL端口连通性
telnet target-host 3306
# 测试文件传输速度
scp test_file user@target-host:/tmp/2. 表结构获取与验证
2.1 从正常运行的数据库获取
1. 直接导出表结构:
-- 导出单个表结构
SHOW CREATE TABLE database_name.table_name;
-- 导出整个数据库表结构
mysqldump -u root -p --no-data database_name > schema.sql
-- 导出特定表的结构
mysqldump -u root -p --no-data database_name table_name > table_schema.sql2. 批量导出表结构:
#!/bin/bash
# 批量导出表结构脚本
DB_NAME="your_database"
OUTPUT_DIR="schema_backup"
mkdir -p $OUTPUT_DIR
# 获取所有表名
TABLES=$(mysql -u root -p -N -B -e "USE $DB_NAME; SHOW TABLES;")
for TABLE in $TABLES; do
echo "导出表结构: $TABLE"
mysqldump -u root -p --no-data $DB_NAME $TABLE > $OUTPUT_DIR/${TABLE}_schema.sql
done2.2 从 ibd 文件提取 SDI 信息
1. 使用 ibd2sdi 工具(MySQL 8.0+):
# 基础用法
ibd2sdi /data/mysql/data/database_name/table_name.ibd
# 格式化输出
ibd2sdi /data/mysql/data/database_name/table_name.ibd | jq '.'
# 提取CREATE TABLE语句
ibd2sdi /data/mysql/data/database_name/table_name.ibd | \
jq -r '.[] | select(.dd_object_type == "Table") | .dd_object.create_statement'2. MySQL 5.7 版本处理:
# MySQL 5.7需要手动编译或下载ibd2sdi工具
# 或者使用第三方工具
wget https://github.com/Percona-Lab/innodb_ruby/releases/download/0.9.10/innodb_ruby-0.9.10.gem
gem install innodb_ruby-0.9.10.gem
# 使用innodb_ruby提取表结构
innodb_space -f /data/mysql/data/database_name/table_name.ibd sdi2.3 从 frm 文件提取(MySQL 5.6 及以下)
1. 使用 mysqlfrm 工具:
# 安装percona-toolkit
yum install percona-toolkit -y
# 解析frm文件
mysqlfrm --diagnostic /data/mysql/data/database_name/table_name.frm
# 输出CREATE TABLE语句
mysqlfrm --diagnostic /data/mysql/data/database_name/table_name.frm | grep -A 100 "CREATE TABLE"2. 手动解析 frm 文件:
# 查看frm文件头部信息
hexdump -C /data/mysql/data/database_name/table_name.frm | head -20
# 使用strings命令查找表名和字段名
strings /data/mysql/data/database_name/table_name.frm | grep -E "(CREATE TABLE|COLUMN_NAME)"3. 标准迁移流程
3.1 源库操作步骤
Step 1: 锁定表并刷新数据:
-- 锁定表,防止数据变更
LOCK TABLES database_name.table_name READ;
-- 刷新表数据到磁盘
FLUSH TABLE database_name.table_name FOR EXPORT;
-- 查看表状态
SHOW TABLE STATUS LIKE 'table_name';Step 2: 复制 ibd 文件:
# 复制ibd文件到临时目录
cp /data/mysql/data/database_name/table_name.ibd /backup/
# 复制cfg文件(如果存在)
cp /data/mysql/data/database_name/table_name.cfg /backup/
# 解锁表
mysql -u root -p -e "UNLOCK TABLES;"3.2 目标库操作步骤
Step 1: 创建表结构:
-- 在目标库创建相同的表结构
CREATE TABLE `table_name` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`email` varchar(100) DEFAULT NULL,
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;Step 2: 丢弃表空间:
-- 丢弃目标库的空表空间
ALTER TABLE database_name.table_name DISCARD TABLESPACE;
-- 验证ibd文件是否被删除
SHOW WARNINGS;Step 3: 传输并导入 ibd 文件:
# 传输ibd文件到目标服务器
scp /backup/table_name.ibd user@target-host:/data/mysql/data/database_name/
# 设置正确的权限
ssh user@target-host "chown mysql:mysql /data/mysql/data/database_name/table_name.ibd"
# 导入表空间
mysql -u root -p -e "ALTER TABLE database_name.table_name IMPORT TABLESPACE;"3.3 迁移后验证
1. 数据完整性验证:
-- 检查记录数
SELECT COUNT(*) FROM database_name.table_name;
-- 检查前几行数据
SELECT * FROM database_name.table_name LIMIT 10;
-- 检查后几行数据
SELECT * FROM database_name.table_name ORDER BY id DESC LIMIT 10;
-- 检查索引
SHOW INDEX FROM database_name.table_name;
-- 检查表状态
SHOW TABLE STATUS LIKE 'table_name';2. 性能验证:
-- 检查查询性能
EXPLAIN SELECT * FROM database_name.table_name WHERE id = 1;
-- 检查索引使用情况
EXPLAIN SELECT * FROM database_name.table_name WHERE name = 'test';
-- 检查表空间大小
SELECT
TABLE_NAME,
ROUND(DATA_LENGTH/1024/1024, 2) AS DATA_SIZE_MB,
ROUND(INDEX_LENGTH/1024/1024, 2) AS INDEX_SIZE_MB
FROM
information_schema.TABLES
WHERE
TABLE_SCHEMA = 'database_name'
AND TABLE_NAME = 'table_name';4. 跨服务器迁移实战
4.1 使用 scp 传输
1. 单表迁移脚本:
#!/bin/bash
# 跨服务器ibd文件迁移脚本
SOURCE_HOST="source-db"
TARGET_HOST="target-db"
DB_NAME="your_database"
TABLE_NAME="your_table"
SOURCE_DATA_DIR="/data/mysql/data"
TARGET_DATA_DIR="/data/mysql/data"
echo "开始迁移表: $DB_NAME.$TABLE_NAME"
# 源库锁定表并刷新
echo "源库锁定表..."
mysql -h $SOURCE_HOST -u root -p -e "
USE $DB_NAME;
LOCK TABLES $TABLE_NAME READ;
FLUSH TABLE $TABLE_NAME FOR EXPORT;
"
# 复制ibd文件
echo "复制ibd文件..."
scp $SOURCE_HOST:$SOURCE_DATA_DIR/$DB_NAME/$TABLE_NAME.ibd $TARGET_HOST:$TARGET_DATA_DIR/$DB_NAME/
# 源库解锁表
echo "源库解锁表..."
mysql -h $SOURCE_HOST -u root -p -e "UNLOCK TABLES;"
# 目标库设置权限并导入
echo "目标库设置权限..."
ssh $TARGET_HOST "chown mysql:mysql $TARGET_DATA_DIR/$DB_NAME/$TABLE_NAME.ibd"
echo "导入表空间..."
mysql -h $TARGET_HOST -u root -p -e "
USE $DB_NAME;
ALTER TABLE $TABLE_NAME IMPORT TABLESPACE;
"
echo "迁移完成,开始验证..."
# 验证数据
SOURCE_COUNT=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE_NAME;")
TARGET_COUNT=$(mysql -h $TARGET_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE_NAME;")
if [ "$SOURCE_COUNT" -eq "$TARGET_COUNT" ]; then
echo "✅ 数据验证成功,记录数一致: $SOURCE_COUNT"
else
echo "❌ 数据验证失败,源库: $SOURCE_COUNT, 目标库: $TARGET_COUNT"
fi4.2 使用 rsync 传输(大文件优化)
1. rsync 优化传输:
#!/bin/bash
# 使用rsync进行大文件迁移
SOURCE_HOST="source-db"
TARGET_HOST="target-db"
DB_NAME="your_database"
TABLE_NAME="your_table"
SOURCE_PATH="/data/mysql/data/$DB_NAME/$TABLE_NAME.ibd"
TARGET_PATH="/data/mysql/data/$DB_NAME/"
# 源库准备
mysql -h $SOURCE_HOST -u root -p -e "
USE $DB_NAME;
LOCK TABLES $TABLE_NAME READ;
FLUSH TABLE $TABLE_NAME FOR EXPORT;
"
# 使用rsync传输(支持断点续传)
rsync -avz --progress $SOURCE_HOST:$SOURCE_PATH $TARGET_HOST:$TARGET_PATH
# 后续步骤同上...四、企业级迁移场景实战
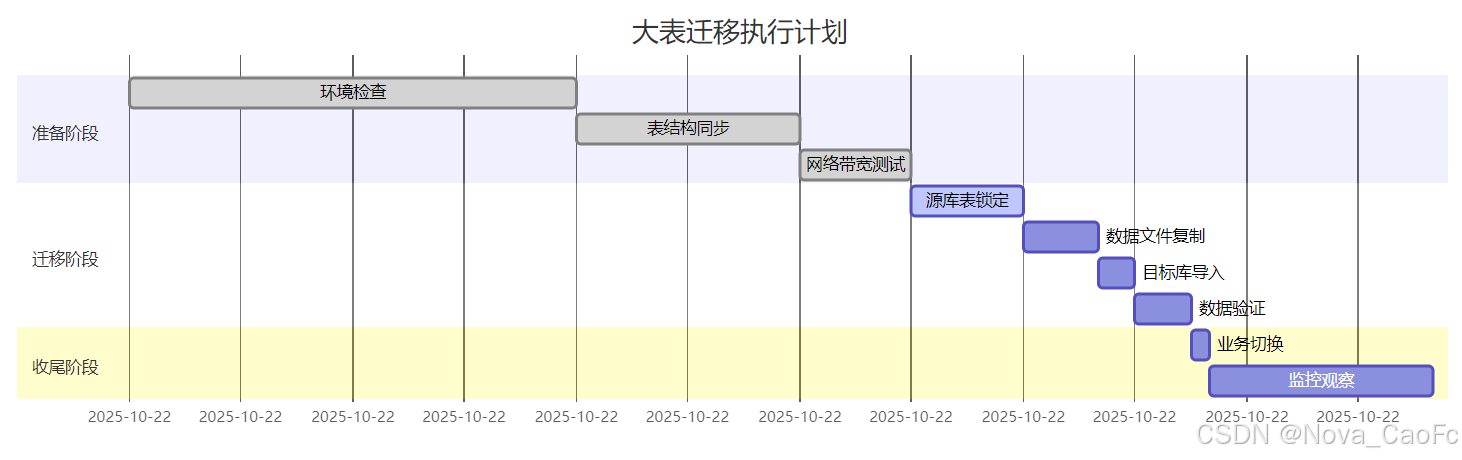
1. 大表跨实例迁移案例
1.1 电商订单表迁移(500GB)
场景背景:
- 表名:order_info
- 数据量:500GB
- 记录数:2 亿条
- 索引:主键索引、用户 ID 索引、订单时间索引
- 迁移要求:停机时间 < 30 分钟
1. 迁移前评估:
-- 评估表大小和结构
SELECT
TABLE_NAME,
ROUND(DATA_LENGTH/1024/1024/1024, 2) AS DATA_SIZE_GB,
ROUND(INDEX_LENGTH/1024/1024/1024, 2) AS INDEX_SIZE_GB,
ROUND((DATA_LENGTH + INDEX_LENGTH)/1024/1024/1024, 2) AS TOTAL_SIZE_GB,
TABLE_ROWS
FROM
information_schema.TABLES
WHERE
TABLE_SCHEMA = 'ecommerce'
AND TABLE_NAME = 'order_info';
-- 检查碎片情况
SHOW TABLE STATUS LIKE 'order_info';
-- 分析索引使用情况
SELECT
TABLE_NAME,
INDEX_NAME,
CARDINALITY,
SUB_PART,
PACKED,
INDEX_TYPE
FROM
information_schema.STATISTICS
WHERE
TABLE_SCHEMA = 'ecommerce'
AND TABLE_NAME = 'order_info';2. 迁移执行计划:
3. 迁移执行脚本:
#!/bin/bash
# 大表迁移专用脚本
set -e
# 配置参数
SOURCE_HOST="192.168.1.100"
TARGET_HOST="192.168.1.200"
DB_NAME="ecommerce"
TABLE_NAME="order_info"
BACKUP_DIR="/backup/mysql"
LOG_FILE="/var/log/mysql_migration.log"
# 日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" | tee -a $LOG_FILE
}
log "开始执行大表迁移: $DB_NAME.$TABLE_NAME"
# 1. 环境检查
log "执行环境检查..."
if ! mysql -h $SOURCE_HOST -u root -p -e "SELECT 1" > /dev/null 2>&1; then
log "❌ 源库连接失败"
exit 1
fi
if ! mysql -h $TARGET_HOST -u root -p -e "SELECT 1" > /dev/null 2>&1; then
log "❌ 目标库连接失败"
exit 1
fi
# 2. 表结构验证
log "验证表结构..."
SOURCE_STRUCT=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "SHOW CREATE TABLE $DB_NAME.$TABLE_NAME;" | awk 'NR==2{print $0}')
TARGET_STRUCT=$(mysql -h $TARGET_HOST -u root -p -N -B -e "SHOW CREATE TABLE $DB_NAME.$TABLE_NAME;" | awk 'NR==2{print $0}')
if [ "$SOURCE_STRUCT" != "$TARGET_STRUCT" ]; then
log "❌ 表结构不一致,迁移中止"
exit 1
fi
# 3. 源库准备
log "源库锁定表并刷新数据..."
mysql -h $SOURCE_HOST -u root -p -e "
USE $DB_NAME;
LOCK TABLES $TABLE_NAME READ;
FLUSH TABLE $TABLE_NAME FOR EXPORT;
"
# 4. 文件传输
log "开始传输ibd文件..."
START_TIME=$(date +%s)
# 使用多线程传输(使用pigz压缩)
ssh $SOURCE_HOST "
cd /data/mysql/data/$DB_NAME &&
pigz -c $TABLE_NAME.ibd
" | ssh $TARGET_HOST "
cd /data/mysql/data/$DB_NAME &&
pigz -d > $TABLE_NAME.ibd.tmp &&
mv $TABLE_NAME.ibd.tmp $TABLE_NAME.ibd &&
chown mysql:mysql $TABLE_NAME.ibd
"
END_TIME=$(date +%s)
DURATION=$((END_TIME - START_TIME))
log "文件传输完成,耗时: ${DURATION}秒"
# 5. 解锁源库
log "源库解锁表..."
mysql -h $SOURCE_HOST -u root -p -e "UNLOCK TABLES;"
# 6. 目标库导入
log "目标库导入表空间..."
mysql -h $TARGET_HOST -u root -p -e "
USE $DB_NAME;
ALTER TABLE $TABLE_NAME IMPORT TABLESPACE;
"
# 7. 数据验证
log "执行数据验证..."
SOURCE_COUNT=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE_NAME;")
TARGET_COUNT=$(mysql -h $TARGET_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE_NAME;")
if [ "$SOURCE_COUNT" -eq "$TARGET_COUNT" ]; then
log "✅ 数据验证成功,记录数: $SOURCE_COUNT"
else
log "❌ 数据验证失败,源库: $SOURCE_COUNT, 目标库: $TARGET_COUNT"
exit 1
fi
# 8. 性能验证
log "执行性能验证..."
mysql -h $TARGET_HOST -u root -p -e "
USE $DB_NAME;
EXPLAIN SELECT * FROM $TABLE_NAME WHERE order_id = 12345;
EXPLAIN SELECT * FROM $TABLE_NAME WHERE user_id = 6789 AND order_time > '2025-10-01';
"
log "🎉 大表迁移完成,总耗时: $(( (date +%s) - $(date -d "$START_TIME" +%s) ))秒"2. 压缩传输优化:
# 使用split分割大文件并行传输
ssh $SOURCE_HOST "
cd /data/mysql/data/$DB_NAME &&
split -b 10G $TABLE_NAME.ibd $TABLE_NAME.ibd.part.
"
# 并行传输
for part in $(ssh $SOURCE_HOST "ls -1 $TABLE_NAME.ibd.part.*"); do
scp $SOURCE_HOST:$part $TARGET_HOST:/data/mysql/data/$DB_NAME/ &
done
# 合并文件
ssh $TARGET_HOST "
cd /data/mysql/data/$DB_NAME &&
cat $TABLE_NAME.ibd.part.* > $TABLE_NAME.ibd &&
rm -f $TABLE_NAME.ibd.part.*
"2. 单表数据恢复案例
2.1 误删除表数据恢复
场景背景:
- 故障时间:2025-10-22 14:30
- 故障操作:DELETE FROM order_info WHERE order_date < '2025-01-01';
- 影响范围:误删了 2025 年之前的所有订单数据(约 500 万条)
- 恢复目标:恢复误删的数据
1. 故障应急处理:
-- 立即停止应用写入
FLUSH TABLES WITH READ LOCK;
-- 检查数据损失情况
SELECT COUNT(*) FROM order_info;
SELECT MIN(order_date), MAX(order_date) FROM order_info;
-- 备份当前数据
mysqldump -u root -p ecommerce order_info > order_info_after_delete.sql2. 从备份恢复数据:
#!/bin/bash
# 单表数据恢复脚本
BACKUP_DIR="/backup/mysql"
DB_NAME="ecommerce"
TABLE_NAME="order_info"
RECOVERY_DATE="2025-01-01"
log "开始单表数据恢复: $DB_NAME.$TABLE_NAME"
# 1. 从全量备份中提取需要恢复的数据
log "从全量备份提取数据..."
gunzip -c $BACKUP_DIR/full_backup_20251021.sql.gz | \
mysql -u root -p -D $DB_NAME -e "
CREATE TABLE IF NOT EXISTS ${TABLE_NAME}_recovery LIKE $TABLE_NAME;
"
# 使用sed过滤INSERT语句
gunzip -c $BACKUP_DIR/full_backup_20251021.sql.gz | \
sed -n '/INSERT INTO `'$TABLE_NAME'` VALUES/,/;/p' | \
mysql -u root -p $DB_NAME
# 2. 从ibd备份文件恢复(如果有)
if [ -f "$BACKUP_DIR/${TABLE_NAME}.ibd" ]; then
log "使用ibd文件恢复..."
# 创建临时表
mysql -u root -p -e "
USE $DB_NAME;
CREATE TABLE IF NOT EXISTS ${TABLE_NAME}_temp LIKE $TABLE_NAME;
ALTER TABLE ${TABLE_NAME}_temp DISCARD TABLESPACE;
"
# 复制ibd文件
cp $BACKUP_DIR/${TABLE_NAME}.ibd /data/mysql/data/$DB_NAME/${TABLE_NAME}_temp.ibd
chown mysql:mysql /data/mysql/data/$DB_NAME/${TABLE_NAME}_temp.ibd
# 导入表空间
mysql -u root -p -e "
USE $DB_NAME;
ALTER TABLE ${TABLE_NAME}_temp IMPORT TABLESPACE;
"
# 提取需要恢复的数据
mysql -u root -p -e "
USE $DB_NAME;
INSERT INTO ${TABLE_NAME}_recovery
SELECT * FROM ${TABLE_NAME}_temp WHERE order_date < '$RECOVERY_DATE';
DROP TABLE ${TABLE_NAME}_temp;
"
fi
# 3. 合并恢复数据到主表
log "合并恢复数据..."
mysql -u root -p -e "
USE $DB_NAME;
-- 检查重复数据
SELECT COUNT(*) FROM ${TABLE_NAME}_recovery
WHERE order_id IN (SELECT order_id FROM $TABLE_NAME);
-- 插入恢复数据(忽略重复)
INSERT IGNORE INTO $TABLE_NAME
SELECT * FROM ${TABLE_NAME}_recovery;
-- 验证恢复结果
SELECT COUNT(*) FROM $TABLE_NAME WHERE order_date < '$RECOVERY_DATE';
"
# 4. 清理临时表
mysql -u root -p -e "DROP TABLE IF EXISTS ${TABLE_NAME}_recovery;"
log "✅ 单表数据恢复完成"2.2 表结构损坏恢复
1. 从 ibd 文件恢复表结构:
#!/bin/bash
# 从ibd文件恢复表结构脚本
IBD_FILE="/data/mysql/data/ecommerce/order_info.ibd"
DB_NAME="ecommerce"
TABLE_NAME="order_info"
log "从ibd文件恢复表结构: $IBD_FILE"
# 提取SDI信息
SDI_DATA=$(ibd2sdi $IBD_FILE)
# 解析CREATE TABLE语句
CREATE_STATEMENT=$(echo $SDI_DATA | \
jq -r '.[] | select(.dd_object_type == "Table") | .dd_object.create_statement')
if [ -z "$CREATE_STATEMENT" ]; then
log "❌ 无法提取CREATE TABLE语句"
exit 1
fi
log "提取到表结构:"
echo "$CREATE_STATEMENT"
# 在数据库中创建表
mysql -u root -p -e "
USE $DB_NAME;
$CREATE_STATEMENT;
"
# 导入表空间
mysql -u root -p -e "
USE $DB_NAME;
ALTER TABLE $TABLE_NAME DISCARD TABLESPACE;
"
# 复制ibd文件
cp $IBD_FILE /data/mysql/data/$DB_NAME/$TABLE_NAME.ibd
chown mysql:mysql /data/mysql/data/$DB_NAME/$TABLE_NAME.ibd
# 导入表空间
mysql -u root -p -e "
USE $DB_NAME;
ALTER TABLE $TABLE_NAME IMPORT TABLESPACE;
"
log "✅ 从ibd文件恢复表结构和数据完成"3. 测试环境数据复用案例
3.1 生产数据脱敏迁移
1. 数据脱敏迁移脚本:
#!/bin/bash
# 生产数据脱敏迁移脚本
PROD_HOST="prod-db"
TEST_HOST="test-db"
DB_NAME="ecommerce"
TABLE_NAME="user_info"
log "开始生产数据脱敏迁移"
# 1. 源库准备数据
mysql -h $PROD_HOST -u root -p -e "
USE $DB_NAME;
-- 创建临时表
CREATE TABLE IF NOT EXISTS ${TABLE_NAME}_anonymized LIKE $TABLE_NAME;
-- 插入脱敏数据
INSERT INTO ${TABLE_NAME}_anonymized
SELECT
user_id,
CONCAT('user_', user_id), -- 用户名脱敏
CONCAT('user_', user_id, '@test.com'), -- 邮箱脱敏
CONCAT('138****', RIGHT(phone, 4)), -- 手机号脱敏
created_at
FROM $TABLE_NAME
WHERE created_at > '2025-01-01'; -- 只迁移最近的数据
-- 锁定表并刷新
LOCK TABLES ${TABLE_NAME}_anonymized READ;
FLUSH TABLE ${TABLE_NAME}_anonymized FOR EXPORT;
"
# 2. 传输数据文件
scp $PROD_HOST:/data/mysql/data/$DB_NAME/${TABLE_NAME}_anonymized.ibd \
$TEST_HOST:/data/mysql/data/$DB_NAME/${TABLE_NAME}.ibd
# 3. 源库清理
mysql -h $PROD_HOST -u root -p -e "
UNLOCK TABLES;
DROP TABLE ${TABLE_NAME}_anonymized;
"
# 4. 目标库导入
ssh $TEST_HOST "chown mysql:mysql /data/mysql/data/$DB_NAME/${TABLE_NAME}.ibd"
mysql -h $TEST_HOST -u root -p -e "
USE $DB_NAME;
ALTER TABLE $TABLE_NAME IMPORT TABLESPACE;
"
# 5. 验证脱敏结果
log "验证脱敏结果:"
mysql -h $TEST_HOST -u root -p -e "
USE $DB_NAME;
SELECT * FROM $TABLE_NAME LIMIT 10;
"
log "✅ 生产数据脱敏迁移完成"3.2 数据子集迁移
1. 按条件筛选迁移:
-- 迁移最近3个月的订单数据
CREATE TABLE temp_order_info LIKE order_info;
INSERT INTO temp_order_info
SELECT * FROM order_info
WHERE order_date >= DATE_SUB(NOW(), INTERVAL 3 MONTH);
-- 然后按照标准迁移流程处理temp_order_info表2. 随机抽样迁移:
-- 随机抽取10%的数据用于测试
CREATE TABLE temp_order_info LIKE order_info;
INSERT INTO temp_order_info
SELECT * FROM order_info
ORDER BY RAND()
LIMIT (SELECT FLOOR(0.1 * COUNT(*)) FROM order_info);五、故障排查与性能优化
1. 常见迁移错误及解决方案
1.1 表空间导入失败
错误 1: Tablespace identifier does not match
ERROR 1808 (HY000): Schema mismatch (tablespace identifier does not match)
解决方案:
-- 检查表空间ID
SELECT
TABLE_SCHEMA,
TABLE_NAME,
TABLESPACE_NAME,
TABLESPACE_ID
FROM
information_schema.INNODB_SYS_TABLES
WHERE
NAME LIKE 'database_name/table_name';
-- 重新创建表结构
DROP TABLE database_name.table_name;
CREATE TABLE database_name.table_name (...); -- 使用正确的表结构
-- 重新导入表空间
ALTER TABLE database_name.table_name DISCARD TABLESPACE;
-- 重新复制ibd文件
ALTER TABLE database_name.table_name IMPORT TABLESPACE;错误 2: Unsupported file format
ERROR 1812 (HY000): Tablespace is missing for table 'database_name.table_name'
解决方案:
# 检查文件格式版本
ibd2sdi /path/to/table.ibd | grep dd_version
# 检查MySQL版本兼容性
mysql -V
# 如果版本不兼容,考虑使用逻辑备份
mysqldump -u root -p database_name table_name > backup.sql
mysql -u root -p database_name < backup.sql1.2 数据一致性问题
错误:迁移后数据不一致
-- 检查数据一致性
SELECT COUNT(*) FROM source_db.table_name;
SELECT COUNT(*) FROM target_db.table_name;
-- 检查特定记录
SELECT * FROM source_db.table_name WHERE id = 12345;
SELECT * FROM target_db.table_name WHERE id = 12345;
-- 检查索引
SHOW INDEX FROM source_db.table_name;
SHOW INDEX FROM target_db.table_name;解决方案:
#!/bin/bash
# 数据一致性检查脚本
SOURCE_HOST="source-db"
TARGET_HOST="target-db"
DB_NAME="your_database"
TABLE_NAME="your_table"
# 检查记录数
SOURCE_COUNT=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE_NAME;")
TARGET_COUNT=$(mysql -h $TARGET_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE_NAME;")
if [ "$SOURCE_COUNT" -ne "$TARGET_COUNT" ]; then
echo "❌ 记录数不一致: 源库 $SOURCE_COUNT, 目标库 $TARGET_COUNT"
# 检查缺失的ID
mysql -h $SOURCE_HOST -u root -p -e "
SELECT id FROM $DB_NAME.$TABLE_NAME
WHERE id NOT IN (SELECT id FROM $DB_NAME.$TABLE_NAME@$TARGET_HOST)
LIMIT 10;
"
fi
# 检查表结构
SOURCE_STRUCT=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "SHOW CREATE TABLE $DB_NAME.$TABLE_NAME;" | awk 'NR==2{print $0}')
TARGET_STRUCT=$(mysql -h $TARGET_HOST -u root -p -N -B -e "SHOW CREATE TABLE $DB_NAME.$TABLE_NAME;" | awk 'NR==2{print $0}')
if [ "$SOURCE_STRUCT" != "$TARGET_STRUCT" ]; then
echo "❌ 表结构不一致"
echo "源库: $SOURCE_STRUCT"
echo "目标库: $TARGET_STRUCT"
fi1.3 性能问题
问题:迁移过程缓慢
# 检查系统资源使用情况
top
iostat -x 1
vmstat 1
# 检查MySQL进程状态
mysql -u root -p -e "SHOW PROCESSLIST;"
mysql -u root -p -e "SHOW ENGINE INNODB STATUS;"
# 检查磁盘I/O性能
dd if=/dev/zero of=/tmp/testfile bs=1M count=100 oflag=direct
dd if=/tmp/testfile of=/dev/null bs=1M count=100 iflag=direct优化方案:
# 1. 使用更快的压缩算法
ssh source-host "lz4 -9 /data/mysql/data/db/table.ibd -" | \
ssh target-host "lz4 -d > /data/mysql/data/db/table.ibd"
# 2. 并行传输
for i in {1..4}; do
ssh source-host "
dd if=/data/mysql/data/db/table.ibd bs=1G skip=$((i-1)) count=1 2>/dev/null
" | ssh target-host "
dd of=/data/mysql/data/db/table.ibd bs=1G seek=$((i-1)) 2>/dev/null
" &
done
wait
# 3. 使用专用网络
# 配置10Gbps网络或使用RDMA六、自动化工具链建设
1. 迁移自动化脚本
1.1 批量迁移脚本
1. 多表批量迁移:
#!/bin/bash
# 多表批量迁移脚本
set -e
# 配置参数
SOURCE_HOST="source-db"
TARGET_HOST="target-db"
DB_NAME="your_database"
TABLE_LIST=("table1" "table2" "table3") # 要迁移的表列表
BACKUP_DIR="/backup/mysql"
LOG_FILE="/var/log/mysql_batch_migration.log"
# 日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" | tee -a $LOG_FILE
}
# 验证函数
validate_migration() {
local TABLE=$1
local SOURCE_COUNT=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE;")
local TARGET_COUNT=$(mysql -h $TARGET_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE;")
if [ "$SOURCE_COUNT" -eq "$TARGET_COUNT" ]; then
log "✅ 表 $TABLE 验证成功,记录数: $SOURCE_COUNT"
return 0
else
log "❌ 表 $TABLE 验证失败,源库: $SOURCE_COUNT, 目标库: $TARGET_COUNT"
return 1
fi
}
# 单个表迁移函数
migrate_table() {
local TABLE=$1
log "开始迁移表: $TABLE"
# 1. 源库准备
mysql -h $SOURCE_HOST -u root -p -e "
USE $DB_NAME;
LOCK TABLES $TABLE READ;
FLUSH TABLE $TABLE FOR EXPORT;
"
# 2. 传输文件
scp $SOURCE_HOST:/data/mysql/data/$DB_NAME/$TABLE.ibd \
$TARGET_HOST:/data/mysql/data/$DB_NAME/
# 3. 源库解锁
mysql -h $SOURCE_HOST -u root -p -e "UNLOCK TABLES;"
# 4. 目标库处理
ssh $TARGET_HOST "chown mysql:mysql /data/mysql/data/$DB_NAME/$TABLE.ibd"
mysql -h $TARGET_HOST -u root -p -e "
USE $DB_NAME;
ALTER TABLE $TABLE IMPORT TABLESPACE;
"
# 5. 验证
validate_migration $TABLE
}
# 主执行流程
log "开始批量迁移,共 ${#TABLE_LIST[@]} 个表"
# 创建结果目录
mkdir -p $BACKUP_DIR/{success,failed}
# 并行迁移(最多4个表同时进行)
MAX_PARALLEL=4
current_parallel=0
for TABLE in "${TABLE_LIST[@]}"; do
if [ $current_parallel -ge $MAX_PARALLEL ]; then
wait # 等待当前批次完成
current_parallel=0
fi
(
if migrate_table $TABLE; then
echo $TABLE >> $BACKUP_DIR/success/$(date +%Y%m%d).txt
else
echo $TABLE >> $BACKUP_DIR/failed/$(date +%Y%m%d).txt
fi
) &
current_parallel=$((current_parallel + 1))
done
wait # 等待所有迁移完成
# 生成报告
SUCCESS_COUNT=$(wc -l < $BACKUP_DIR/success/$(date +%Y%m%d).txt 2>/dev/null || echo 0)
FAILED_COUNT=$(wc -l < $BACKUP_DIR/failed/$(date +%Y%m%d).txt 2>/dev/null || echo 0)
log "🎉 批量迁移完成"
log "成功: $SUCCESS_COUNT 个表"
log "失败: $FAILED_COUNT 个表"
if [ $FAILED_COUNT -gt 0 ]; then
log "❌ 迁移失败的表: $(cat $BACKUP_DIR/failed/$(date +%Y%m%d).txt)"
exit 1
fi1.2 增量迁移脚本
1. 基于时间戳的增量迁移:
#!/bin/bash
# 增量迁移脚本
SOURCE_HOST="source-db"
TARGET_HOST="target-db"
DB_NAME="your_database"
TABLE_NAME="your_table"
LAST_MIGRATION_FILE="/var/log/last_migration_timestamp"
# 获取上次迁移时间戳
if [ -f $LAST_MIGRATION_FILE ]; then
LAST_TIMESTAMP=$(cat $LAST_MIGRATION_FILE)
else
LAST_TIMESTAMP="1970-01-01 00:00:00"
fi
CURRENT_TIMESTAMP=$(date '+%Y-%m-%d %H:%M:%S')
log "开始增量迁移: $TABLE_NAME (从 $LAST_TIMESTAMP 到 $CURRENT_TIMESTAMP)"
# 1. 源库创建临时表
mysql -h $SOURCE_HOST -u root -p -e "
USE $DB_NAME;
CREATE TABLE IF NOT EXISTS ${TABLE_NAME}_incremental LIKE $TABLE_NAME;
-- 插入增量数据
INSERT INTO ${TABLE_NAME}_incremental
SELECT * FROM $TABLE_NAME
WHERE update_time > '$LAST_TIMESTAMP';
LOCK TABLES ${TABLE_NAME}_incremental READ;
FLUSH TABLE ${TABLE_NAME}_incremental FOR EXPORT;
"
# 2. 传输文件
scp $SOURCE_HOST:/data/mysql/data/$DB_NAME/${TABLE_NAME}_incremental.ibd \
$TARGET_HOST:/data/mysql/data/$DB_NAME/${TABLE_NAME}_incremental.ibd
# 3. 源库清理
mysql -h $SOURCE_HOST -u root -p -e "
UNLOCK TABLES;
DROP TABLE ${TABLE_NAME}_incremental;
"
# 4. 目标库导入
ssh $TARGET_HOST "chown mysql:mysql /data/mysql/data/$DB_NAME/${TABLE_NAME}_incremental.ibd"
mysql -h $TARGET_HOST -u root -p -e "
USE $DB_NAME;
CREATE TABLE IF NOT EXISTS ${TABLE_NAME}_incremental LIKE $TABLE_NAME;
ALTER TABLE ${TABLE_NAME}_incremental DISCARD TABLESPACE;
ALTER TABLE ${TABLE_NAME}_incremental IMPORT TABLESPACE;
-- 合并到主表
INSERT IGNORE INTO $TABLE_NAME
SELECT * FROM ${TABLE_NAME}_incremental;
DROP TABLE ${TABLE_NAME}_incremental;
"
# 5. 更新时间戳
echo "$CURRENT_TIMESTAMP" > $LAST_MIGRATION_FILE
log "✅ 增量迁移完成"2. 监控自动化工具
2.1 数据一致性检查工具
1. 表级一致性检查:
#!/bin/bash
# 数据一致性检查工具
SOURCE_HOST="source-db"
TARGET_HOST="target-db"
DB_NAME="your_database"
RESULT_FILE="/var/log/data_consistency_check.log"
log "开始数据一致性检查"
# 获取所有表列表
TABLES=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "
SELECT TABLE_NAME
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = '$DB_NAME'
AND TABLE_TYPE = 'BASE TABLE'
AND ENGINE = 'InnoDB';
")
for TABLE in $TABLES; do
log "检查表: $TABLE"
# 检查记录数
SOURCE_COUNT=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE;")
TARGET_COUNT=$(mysql -h $TARGET_HOST -u root -p -N -B -e "SELECT COUNT(*) FROM $DB_NAME.$TABLE;")
if [ "$SOURCE_COUNT" -ne "$TARGET_COUNT" ]; then
log "❌ 记录数不一致: $TABLE (源库: $SOURCE_COUNT, 目标库: $TARGET_COUNT)"
echo "$TABLE,count_mismatch,$SOURCE_COUNT,$TARGET_COUNT" >> $RESULT_FILE
continue
fi
# 检查表大小
SOURCE_SIZE=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "
SELECT ROUND((DATA_LENGTH + INDEX_LENGTH)/1024/1024, 2)
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = '$DB_NAME' AND TABLE_NAME = '$TABLE';
")
TARGET_SIZE=$(mysql -h $TARGET_HOST -u root -p -N -B -e "
SELECT ROUND((DATA_LENGTH + INDEX_LENGTH)/1024/1024, 2)
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = '$DB_NAME' AND TABLE_NAME = '$TABLE';
")
# 允许1%的误差
DIFF_PERCENT=$(echo "scale=4; ($SOURCE_SIZE - $TARGET_SIZE)/$SOURCE_SIZE * 100" | bc | awk '{print ($1 < 0) ? -$1 : $1}')
if (( $(echo "$DIFF_PERCENT > 1" | bc -l) )); then
log "⚠️ 表大小差异较大: $TABLE (源库: ${SOURCE_SIZE}MB, 目标库: ${TARGET_SIZE}MB, 差异: ${DIFF_PERCENT}%)"
echo "$TABLE,size_mismatch,$SOURCE_SIZE,$TARGET_SIZE" >> $RESULT_FILE
else
log "✅ 表 $TABLE 一致性检查通过"
fi
done
log "数据一致性检查完成"
# 生成报告
FAILED_TABLES=$(wc -l < $RESULT_FILE 2>/dev/null || echo 0)
if [ $FAILED_TABLES -gt 0 ]; then
log "❌ 发现 $FAILED_TABLES 个表存在一致性问题"
exit 1
else
log "✅ 所有表一致性检查通过"
fi2.2 自动修复工具
1. 表结构自动同步:
#!/bin/bash
# 表结构自动同步工具
SOURCE_HOST="source-db"
TARGET_HOST="target-db"
DB_NAME="your_database"
log "开始表结构同步检查"
# 获取所有表列表
TABLES=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "
SELECT TABLE_NAME
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = '$DB_NAME'
AND TABLE_TYPE = 'BASE TABLE';
")
for TABLE in $TABLES; do
log "检查表结构: $TABLE"
# 获取源库表结构
SOURCE_STRUCT=$(mysql -h $SOURCE_HOST -u root -p -N -B -e "SHOW CREATE TABLE $DB_NAME.$TABLE;" | awk 'NR==2{print $0}')
# 获取目标库表结构
TARGET_STRUCT=$(mysql -h $TARGET_HOST -u root -p -N -B -e "SHOW CREATE TABLE $DB_NAME.$TABLE;" 2>/dev/null | awk 'NR==2{print $0}')
if [ "$SOURCE_STRUCT" != "$TARGET_STRUCT" ]; then
log "⚠️ 表结构不一致,开始同步: $TABLE"
# 备份目标库表数据
mysqldump -h $TARGET_HOST -u root -p $DB_NAME $TABLE > /backup/${TABLE}_backup_$(date +%Y%m%d_%H%M%S).sql
# 删除目标库表
mysql -h $TARGET_HOST -u root -p -e "DROP TABLE IF EXISTS $DB_NAME.$TABLE;"
# 重新创建表结构
mysql -h $TARGET_HOST -u root -p -e "USE $DB_NAME; $SOURCE_STRUCT;"
log "✅ 表结构同步完成: $TABLE"
else
log "✅ 表结构一致: $TABLE"
fi
done3. 学习路径与资源推荐
5.1 官方文档
1. MySQL 官方文档:
2. Percona 文档:
5.2 开源工具
1. 迁移工具:
2. 监控工具:
5.3 社区资源
1. 技术社区:
2. 技术会议:
- MySQL Connect
- Percona Live
- FOSDEM MySQL DevRoom
总结
InnoDB 独立表空间(ibd 文件)迁移技术是 MySQL 数据库运维中的重要技能,它为企业提供了高效、灵活的数据迁移解决方案。通过本文的深入讲解,我们从理论基础到实战案例,全面覆盖了 ibd 文件迁移的各个方面:
核心要点回顾
- 技术原理:理解 InnoDB 表空间架构和 ibd 文件结构是成功迁移的基础
- 迁移流程:标准化的迁移流程包括准备、传输、导入、验证四个关键阶段
- 实战场景:大表迁移、分库分表、数据恢复、测试环境复用等企业级应用
- 故障排查:掌握常见问题的诊断和解决方法
- 自动化建设:通过脚本和工具链提升迁移效率和可靠性
最佳实践建议
- 环境准备:充分的前期准备是迁移成功的关键
- 数据验证:严格的验证机制确保数据一致性
- 性能优化:合理的硬件和配置优化提升迁移效率
- 安全考虑:数据安全和访问控制不可忽视
- 自动化:建设完善的自动化工具链降低人为错误
未来展望
随着云原生技术的发展和 AI 技术的应用,MySQL 迁移技术将朝着更加自动化、智能化的方向发展。容器化部署、智能故障检测、自动性能优化等技术将为数据库运维带来新的机遇和挑战。
掌握 InnoDB 独立表空间迁移技术,不仅能够解决当前的数据库运维难题,更为未来的技术发展奠定了坚实的基础。希望本文能够帮助读者深入理解这一重要技术,并在实际工作中发挥重要作用。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 38
38 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)