【医学影像 AI】Affective-ROPTester: LLMs的能力和偏差分析在预测 ROP 病变中的应用
本研究构建了首个中文ROP风险预测数据集CROP(993条早产儿入院记录),提出Affective-ROPTester评估框架,探究LLMs在ROP预测中的能力与偏差。研究发现:1)LLMs仅依赖内在知识预测效果有限,引入外部知识可显著提升性能;2)模型存在高估中高风险的固有偏差;3)积极情感框架能有效缓解预测偏差。该研究为医疗AI的风险预测提供了新基准,揭示了情感提示工程在提升诊断可靠性中的重要
【医学影像 AI】Affective-ROPTester: LLMs的能力和偏差分析在预测 ROP 病变中的应用
0. 论文简介
0.1 基本信息
2025 年 深圳 张国明 等在 arxiv 发布论文 “Affective-ROPTester: LLMs的能力和偏差分析在预测 ROP 病变中的应用(Affective-ROPTester: Capability and Bias Analysis of LLMs in Predicting Retinopathy of Prematurity)”。
本研究构建了含 993 条中文早产儿入院记录(低、中、高风险各 331 条)的 CROP 基准数据集,提出整合 Instruction、CoT、ICL 三种提示策略及情感框架的 Affective-ROPTester 评估框架,探究大型语言模型(LLMs)预测早产儿视网膜病变(ROP)风险的能力与偏差,发现 LLMs 仅依赖内在知识预测效果有限,引入外部知识可显著提升性能,且存在高估中高风险的偏差,积极情感框架能缓解该偏差。
论文下载: arxiv
引用格式: Zhao S, Zhang Y L, Xiao L W, et al. Affective-ROPTester: Capability and Bias Analysis of LLMs in Predicting Retinopathy of Prematurity[EB/OL]. 2025. https://arxiv.org/pdf/2507.05816
0.2 论文速览
研究的问题
- 问题 1:LLMs 仅依赖内在知识能否有效预测 ROP 风险?
- 问题 2:LLMs 在 ROP 风险预测中是否存在固有偏差?
- 问题 3:提示中的情感框架如何影响 LLMs 的预测结果与偏差?
主要的贡献
- 构建 CROP 基准数据集
为填补文本型 ROP 风险预测数据集空白,研究收集 3922 条原始早产儿病历,筛选并平衡后形成993 条有效记录。 - 提出 Affective-ROPTester 评估框架
框架通过三种提示策略与情感嵌入,全面评估 LLMs 的 ROP 风险预测能力。
核心结论:
- LLMs 需依赖外部知识(如 CoT 的风险因素、ICL 的演示样本)才能有效预测 ROP 风险,仅靠内在知识性能有限;
- LLMs 存在 “高估 ROP 风险” 的固有偏差,可通过引入外部知识与积极情感框架缓解;
- CROP 数据集与 Affective-ROPTester 框架为 LLMs 的 ROP 预测研究提供了首个中文基准。
关键问题 1:该研究构建的 CROP 数据集有何创新性与价值?
CROP 数据集的创新性与价值主要体现在三点:
- 填补数据缺口:是目前首份仅基于中文入院文本记录的 ROP 风险预测数据集,此前研究多依赖病历 + 影像,缺乏纯文本基准,解决了 LLMs 在文本型 ROP 预测中 “无数据可用” 的问题;
- 样本平衡与标注严谨:共 993 条记录,低 / 中 / 高风险各 331 条,避免样本偏倚;标注基于最终临床诊断,将 “无 ROP”“轻度 ROP(2 型)”“重度 ROP(1 型 / 侵袭性 / 4-5 期)” 分别对应低 / 中 / 高风险,确保标签准确性;
- 临床实用性:仅包含早产儿入院时的文本信息(如胎龄、出生体重、氧疗情况),无需影像数据,适配临床中 “早期快速风险筛查” 的需求,且通过伦理审批(深圳眼科医院 NO. 2022KYPJ064),具备临床转化潜力。
关键问题 2:LLMs 在 ROP 风险预测中存在何种固有偏差?该偏差可通过哪些方式有效缓解?
- 固有偏差类型:高估风险偏差
LLMs 倾向于将低风险早产儿误判为中 / 高风险,具体表现为:- Qwen-2.5 在 Instruction 策略下,低风险样本正确预测率仅 5.36%,92.59% 的高风险样本预测正确;
- GPT-4o 偏差更严重,低风险样本正确预测率 0%,97.22% 误判为高风险,中等风险样本 92.79% 误判为高风险;
- 偏差原因:模型对医疗风险的 “过度严谨”,为避免漏诊 ROP 导致的失明,优先高估风险,符合 “医疗保守性” 倾向,但会增加不必要的临床检查负担。
- 有效缓解方式
- 引入外部知识:通过 CoT 策略提供 ROP 风险因素推理(如胎龄 < 28 周为高风险、1000-1500g 为中风险),或 ICL 策略提供相似病例演示,可显著降低偏差;例如 Qwen-2.5 在 CoT 策略下,低风险正确预测率从 5.36% 提升至 59.82%,高风险误判率从 24.11% 降至 3.57%;
- 嵌入积极情感框架:相比消极(“早产儿易患 ROP”)或中性框架,积极框架(“多数早产儿可避免 ROP”)可引导模型客观评估,如 Qwen-2.5 在积极框架下,低风险样本被误判为高风险的概率从 76.79%(消极框架)降至 21.43%。
0.3 摘要
尽管大型语言模型(LLMs)在多个领域取得了显著进展,但其预测早产儿视网膜病变(ROP)风险的能力仍未得到充分探索。
为填补这一空白,本研究构建了一个全新的中文基准数据集 CROP,该数据集包含 993 条早产儿入院记录,并标注了低、中、高三种风险等级。
为系统考察 LLMs 在 ROP 风险分层中的预测能力与情感偏差,研究提出了自动化评估框架 Affective-ROPTester,该框架整合了三种提示策略:基于指令(Instruction-based)、思维链(Chain-of-Thought, CoT)和上下文学习(In-Context Learning, ICL)。其中,指令策略用于评估 LLMs 的内在知识及相关偏差,而思维链与上下文学习策略则借助外部医学知识提升预测准确性。关键在于,研究在提示层面融入情感元素,以探究不同情感框架对模型 ROP 预测能力及偏差模式的影响。
基于 CROP 数据集的实证研究得出三项主要结论:
第一,LLMs 仅依赖内在知识进行 ROP 风险预测时效果有限,但在加入结构化外部输入后,预测性能显著提升;
第二,模型输出中存在明显的情感偏差,表现为持续倾向于高估中高风险病例;
第三,与消极情感框架相比,积极情感框架有助于缓解模型输出中的预测偏差。
这些发现凸显了情感敏感型提示工程在提升诊断可靠性中的关键作用,同时强调了 Affective-ROPTester 作为评估与缓解临床语言建模系统情感偏差的框架所具有的实用价值。本研究旨在深入探索 LLMs 用于 ROP 预测的能力,为医疗健康领域的发展做出贡献。
1. 引言
近年来,在强大计算资源的支持下,大型语言模型(LLMs)[1]、[2] 展现出了令人瞩目的能力。其广泛的适用性不仅改变了文本摘要 [3]、数学推理等传统自然语言处理(NLP)任务,还在教育 [4]-[6]、金融 [7]、医疗健康 [8]-[10] 等领域实现了当前最优(state-of-the-art)的性能。以 LLMs 为核心、依托患者病历的智能医疗系统,旨在预测患者最可能罹患的疾病,并协助医生做出精准的临床决策。尽管已有多项研究证实 LLMs 在推动智能医疗发展方面的潜在优势 [11]、[12],但关于其预测早产儿视网膜病变(ROP)[13] 风险的研究仍处于探索阶段。
早产儿视网膜病变(ROP)是一种发生于早产儿和低出生体重儿的视网膜血管疾病,其发病机制尚未完全明确 [14]、[15]。传统上,ROP 的诊断高度依赖病历资料和影像学检查 [16]。尽管临床实践已能够诊断早产儿视网膜病变,但对高危患儿进行早期风险预测是实现有效干预的关键,这仍是该领域面临的一大挑战 [17]。研究表明,ROP 的已知风险因素包括出生体重、胎龄、多胎妊娠、分娩方式、氧疗时长、氧浓度等 [15]。鉴于 LLMs 具备强大的推理能力和丰富的医学知识储备,本文尝试仅利用病历资料,借助 LLMs 实现 ROP 风险预测。由此,引出三个核心问题:(1)LLMs 在 ROP 风险预测中的效果如何?(2)LLMs 在 ROP 风险预测中是否存在固有偏差?(3)提示语中嵌入的情感元素对 LLMs 的预测结果及偏差会产生多大程度的影响?
以往研究主要聚焦于基于病历和影像学检查的 ROP 诊断,导致目前缺乏仅利用病历资料进行 ROP 风险预测的基准数据集。为应对这些挑战,本文构建了一个名为 CROP 的中文 ROP 风险预测数据集,该数据集仅包含早产儿的初始入院记录。数据集共收录 993 条可用的早产儿入院记录,将其均匀划分为低风险、中风险和高风险三个类别。本研究的初衷是借助 LLMs,仅通过早产儿的入院记录实现 ROP 风险预测。
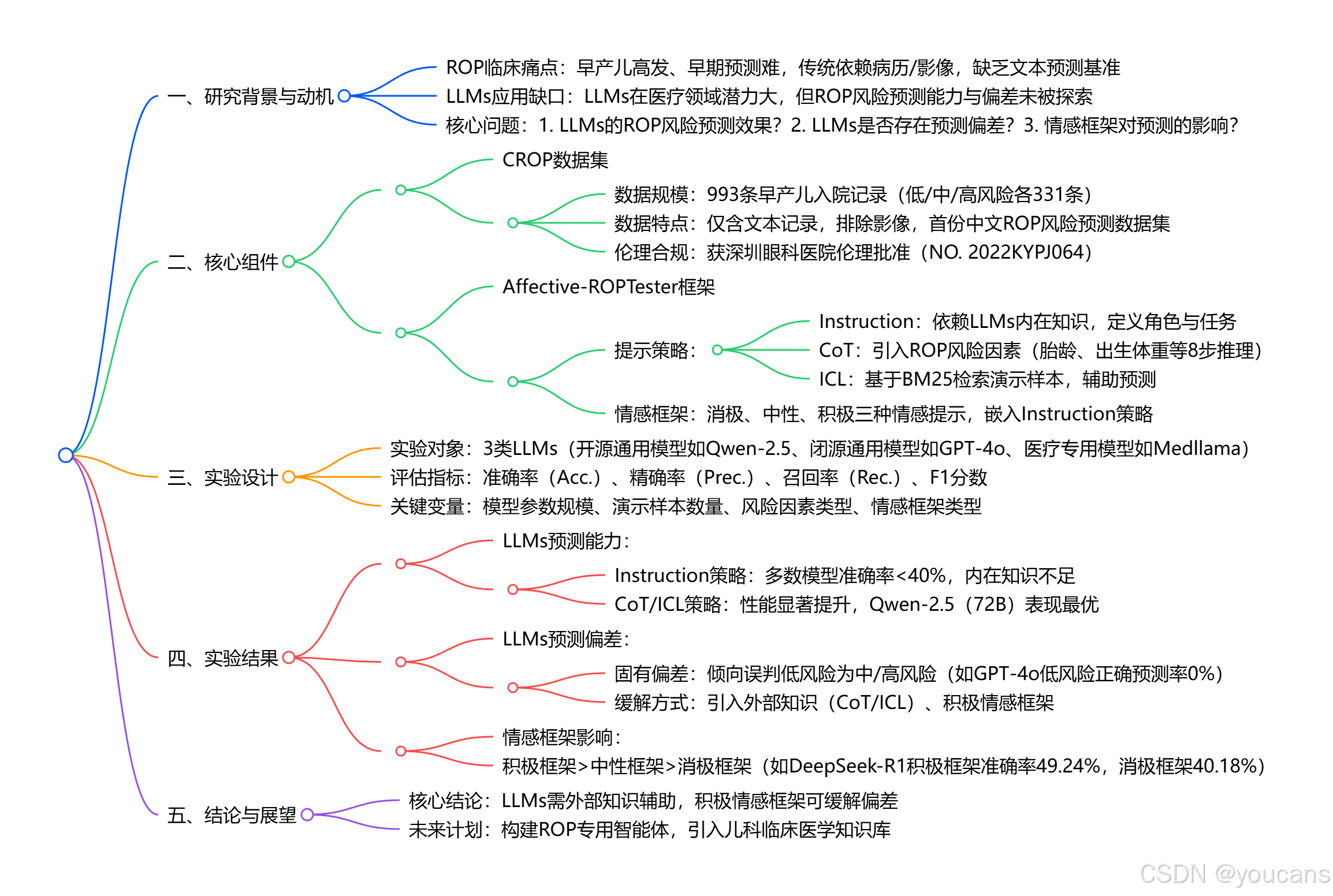
为验证 LLMs 在 ROP 风险预测中的能力及潜在偏差,本文提出了 Affective-ROPTester 评估框架,该框架包含指令型(Instruction)、思维链(Chain-of-Thought, CoT)和上下文学习(In-Context Learning, ICL)三种策略,如图 1 所示。其中,指令策略用于验证仅依赖 LLMs 的内在知识能否有效预测 ROP 风险,并探究模型是否存在偏差;对于思维链和上下文学习策略,研究引入已知风险因素和演示样例作为外部知识,进一步验证 LLMs 在 ROP 风险预测中的性能。关键在于,研究在提示语层面融入情感元素,以探究不同情感框架对 LLMs 的 ROP 预测能力及潜在偏差的影响。
研究通过全面实验评估了多种当前主流 LLMs 在 ROP 风险预测中的效果。实验结果表明,仅依赖模型的内在知识无法有效预测 ROP 风险,且 Qwen-2.5、GPT-4o 等 LLMs 存在显著偏差;此外,积极情感框架有助于提高预测准确性并缓解偏差;最终,外部知识的引入有效提升了 ROP 风险预测的准确率,例如 Qwen-2.5 模型在思维链策略下的准确率达到 61.33%。
本文的主要贡献总结如下:
- 为填补 LLMs 与 ROP 风险预测之间的数据集空白,构建了一个全新的 ROP 风险预测基准数据集。据作者所知,这是首个仅利用早产儿入院记录实现 ROP 风险预测的中文数据集。
- 提出了包含指令型、思维链和上下文学习三种策略的 Affective-ROPTester 框架。值得注意的是,指令策略中整合了不同情感框架,以考察情感线索的影响。这些策略全面验证了 LLMs 在仅依赖内在知识和引入外部知识两种场景下的 ROP 风险预测能力,可为 ROP 风险预测研究提供基准参考;同时也为研究人员设计细粒度情感提示语提供指导,以充分释放 LLMs 的潜力,让更多医生从 Affective-ROPTester 框架中受益。
- 证实了 LLMs 在 ROP 风险预测中存在潜在偏差,实验发现模型倾向于将病例预测为中高风险。此外,引入外部知识可缓解这种偏差,在提示语中融入积极情感元素也能起到类似作用。
- 除为未来基于 LLM 的医疗风险预测研究提供基准外,Affective-ROPTester 框架还为构建细粒度、情感感知的提示语提供了可操作的指导,有助于充分发挥 LLMs 的能力,推动临床医生更广泛地采用这些具备可解释性和情感平衡性的决策支持工具。
2. 相关工作
2.1 眼科领域中的大型语言模型(LLMs)
随着大型语言模型(LLMs)的发展 [18]、[19],其在医疗领域的应用日益广泛 [20]-[22],在眼科领域尤为突出。Postaci 等人 [13] 评估了 LLMs 生成早产儿视网膜病变(ROP)相关科普材料的能力,评估维度包括可读性、准确性和完整性;Holmes 等人 [23] 则对 LLMs 在儿童眼科诊疗咨询中的表现进行了评估,证实 LLMs 具备辅助眼科诊断的潜力。Engin 等人 [24] 提出将 LLMs 作为虚拟咨询顾问的设想,并测试了其在 ROP 咨询场景中的有效性;Ermiş等人 [25] 研究了 LLMs 对 ROP 相关常见问题的应答能力,采用可读性、适宜性等指标进行评估。
此外,Shi 等人 [26] 开发了一套交互式系统,利用 LLMs 实现眼底荧光血管造影报告生成与视觉问答功能;Tan 等人 [27] 通过微调 LLMs,评估了基于 LLM 的聊天机器人对眼科相关患者咨询的应答准确性。为提升眼科相关问题应答的准确性,Nguyen 等人 [28] 采用检索增强生成算法对模型性能进行了优化 [28]。
2.2 早产儿视网膜病变(ROP)的诊断与预测
传统 ROP 研究主要聚焦于结合病历资料与影像学检查,诊断早产儿是否存在视网膜病变 [29]。例如,Kumar 等人 [30] 提出一种深度卷积神经网络,用于早产儿视网膜病变的自动检测;Sankari 等人 [31] 开发了一种混合深度学习网络,用于 ROP 检测,且该网络展现出良好的准确性;Redd 等人 [32] 基于深度学习模型,通过眼底检查评估早产儿视网膜病变的严重程度。
与疾病诊断不同,ROP 风险预测的难度更大。Wu 等人 [17] 设计了 OC-Net 和 SE-Net 模型,以视网膜图像为输入实现 ROP 风险预测。与上述研究不同,本文重点关注 LLMs 的 ROP 风险预测能力及模型内部潜在偏差,且仅以早产儿的初始入院记录作为模型输入。
2.3 情感偏差
情感偏差在大型语言模型(LLMs)中普遍存在,越来越多的研究表明,不同模型的情感偏差程度与表现形式存在差异 [33]、[34]。Lin 等人 [35] 探究了语音情感识别模型中的性别偏差,发现女性说话人的情感识别性能通常略优于男性,且传统自监督学习方法存在显著的性别偏差;Kadan 等人 [36] 研究了语言模型中的潜在情感偏差,发现这类模型常将特定情感与性别、种族或宗教错误关联。
为缓解模型对情感类别的偏差,Kang 等人 [37] 提出一种主动学习方法,通过有效引导人工标注构建偏差更小、质量更高的多标签情感语料库;Mao 等人 [38] 针对基于提示的情感分类与情感识别任务,对预训练语言模型展开系统性实证研究,发现预训练语言模型存在多种偏差,例如与标签类别数量相关的偏差。本文则探究了利用情感提示能否提升模型的 ROP 风险预测能力,并缓解潜在偏差。
3. 预备知识
3.1 任务定义
本研究将早产儿视网膜病变(ROP)风险预测任务定义为三分类问题,风险类别分为低风险、中风险和高风险。尽管 ROP 的发病机制尚未完全明确,但已知早产儿的 ROP 风险因素包括出生体重、胎龄、多胎妊娠、分娩方式、氧疗时长、氧浓度、红细胞输注,以及妊娠期高血压、妊娠期糖尿病等母体相关情况 [15]。因此,本任务的研究目的在于验证大型语言模型(LLMs)是否仅能通过入院记录,实现对早产儿 ROP 风险的预测;同时,本研究还旨在探究现有 LLMs 中可能影响其 ROP 风险预测性能的潜在偏差。
具体而言,对于给定的电子入院记录 x 和潜在风险类别集合 y,ROP 风险预测任务借助 LLMs(记为M)的推理能力,从潜在风险集合中输出最可能的病变等级作为预测结果。由此,预测标签 y p r e y_{pre} ypre 需满足最大似然条件,公式如下: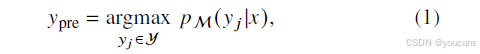
其中, y j y_j yj 代表输入 x 对应的真实标签,Y 为风险类别集合,包含低风险、中风险、高风险三类。
3.2 数据集构建
与以往包含病历资料和影像学检查的数据集不同,本研究引入CROP 数据集—— 这是一个专门用于基于文本的 ROP 风险预测研究的中文基准数据集。具体而言,研究收集了确诊为 “无 ROP”“轻度 ROP” 和 “重度 ROP” 的早产儿病历资料:其中,轻度 ROP 对应 2 型 ROP,重度 ROP 则涵盖 1 型 ROP、侵袭性 ROP 及 4 期、5 期 ROP [17]、[39]。在所有病历资料中,研究专门提取入院记录用于 ROP 风险预测任务;同时,根据最终诊断结果,将提取的入院记录标注为低风险、中风险或高风险。
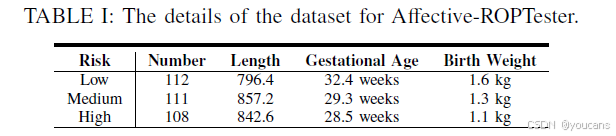
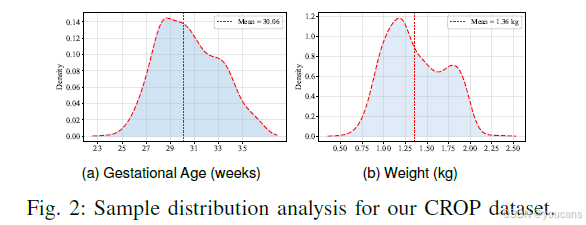
为构建 ROP 预测数据集,研究最初收集了 3922 条原始病历记录,但其中高风险样本仅 331 条。因此,为保证样本平衡,最终确定的 CROP 基准数据集包含 993 条早产儿入院记录,低风险、中风险、高风险三类样本各 331 条。尽管本研究的核心目的是验证 LLMs 自身的 ROP 风险预测能力,但为进行对比,研究也对 LLMs 进行了微调。基于此,CROP 数据集中的测试集仅包含 331 条记录,详细信息如表 1 所示。
本研究已获得深圳眼科医院伦理委员会批准(批准号:2022KYPJ064),且研究过程严格遵循《赫尔辛基宣言》原则。所有数据均由广东省妇幼保健院提供。
表 1:Affective-ROPTester 所用数据集详细信息
4. 用于 ROP 风险预测的 Affective-ROPTester 框架
如图 1 所示,本研究借助 Affective-ROPTester 框架实现早产儿视网膜病变(ROP)风险预测,该框架包含三种验证策略:指令型(Instruction)、思维链(Chain-of-Thought, CoT)和上下文学习(In-Context Learning, ICL)。其中,指令型策略进一步验证了不同情感框架对 ROP 风险预测的影响。这三种策略的核心设计思路是:依托指令型策略或外部知识,验证大型语言模型(LLMs)的 ROP 风险预测能力。
4.1 基于指令型策略的 ROP 风险预测
本研究首先提出用于 ROP 风险预测的指令型策略。该策略旨在挖掘 LLMs 的基础能力,通过启发式方法探究其内在知识能否实现 ROP 风险预测,同时验证 LLMs 在 ROP 风险预测中是否存在偏差。具体而言,指令型策略包含两个核心组件:(1)定义 LLMs 的角色与任务;(2)划定标签空间以约束模型生成内容。
相关指令如策略 1(Scheme 1)所示。

策略 1(Scheme 1)
(1)你是一名早产儿眼科专家,请判断下述早产儿是否可能发生早产儿视网膜病变(ROP)。
(2)风险等级分为低风险、中风险、高风险三类。严禁提供任何额外描述,仅需输出 “低风险”“中风险” 或 “高风险” 中的任意一类作为结果。
因此,LLMs 的输入可表示为以下形式:
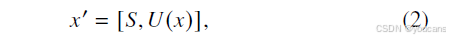
其中,S 代表预定义的系统指令,U(x) 代表含提示语的输入,提示语内容为 “请将该早产儿的视网膜病变风险等级划分为:”。将
x′ 代入公式(1),即可输出 LLMs 预测的 ROP 风险标签。
指令型策略仅依托 LLMs 的基础知识,用于验证其是否具备 ROP 风险预测能力;同时,该策略也为系统分析 LLMs 在 ROP 风险预测中的固有偏差提供了支持。
4.2 不同情感框架的设计
为了评估不同情感框架对LLMs预测ROP能力的影响,以及情感提示中嵌入的情感线索是否可能引入额外的偏差,我们在提示层面设计了三种类型的情感元素,基于指导方案。这些情感元素包括负面情感提示、中性情感提示和积极情感提示。具体来说,我们在不同的框架中嵌入了不同的情感特征。例如,在积极情感提示中,使用指令“你是一名对治疗结果充满信心的儿科眼科医生,相信大多数病例可以成功避免视网膜病变。”来引导LLMs避免过于悲观的预测。
因此,LLMs 的输入可表示为如下形式(含情感提示语):
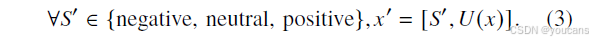
不同的情感框架能够从多维度探索提示层面的情感元素如何影响LLMs预测ROP风险的能力,从而促进对LLMs能力的更深入理解。
4.3 基于思维链(CoT)策略的 ROP 风险预测
此外,本研究提出用于 ROP 风险预测的思维链(CoT)策略。该策略在指令型策略的基础上,增加了 ROP 风险预测的推理过程。
尽管 ROP 的发病机制尚未明确,但已有研究证实其发病与多个关键因素相关,包括早产和低出生体重等 [15]、[40]。因此,本研究通过预定义思维链流程,使模型的推理逻辑与已知风险因素对齐,从而提升 LLMs 的预测能力并缓解偏差。
具体而言,该思维链流程包含 8 个关键步骤,如策略 2(Scheme 2)所示。其中,胎龄和出生体重作为已明确的 ROP 主要风险因素,是构建思维链的核心基础;同时,氧疗时长、氧浓度等其他风险因素也被纳入流程并加以考量。
本研究提出的思维链策略整合了所有已知风险因素,作为 LLMs 的诊断依据。因此,含思维链的 LLMs 输入可描述为:
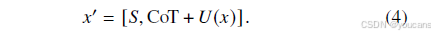
基于思维链策略的 LLMs 具有两大优势:(1)构成思维链的已知风险因素可为 LLMs 提供外部知识,助力其更精准地预测患者的 ROP 风险概率;(2)明确的外部知识有助于缓解 LLMs 潜在的预测偏差。

策略 2(Scheme 2)
- 步骤 1:明确基础数据与风险因素
收集早产儿的出生体重、胎龄、多胎妊娠情况、分娩方式、氧疗时长、氧浓度、红细胞输注情况,以及母体妊娠期高血压、妊娠期糖尿病等母体相关情况。 - 步骤 2:分析胎龄与出生体重的影响
- 胎龄<28 周:高风险,若出生体重<1000 克,风险更高;
- 胎龄 28-32 周:中风险,对应出生体重通常为 1000-1500 克;
- 胎龄 32-34 周:低风险,对应出生体重通常>1500 克。
- 步骤 3:考量多胎妊娠的额外影响
多胎妊娠可能增加视网膜病变风险(尤其双胞胎),需在每位早产儿的风险评估中纳入该因素。 - 步骤 4:评估氧暴露的影响
高氧环境(尤其是用于治疗早产儿呼吸窘迫的高氧疗法)会显著增加视网膜病变风险。 - 步骤 5:分析妊娠并发症的影响
母体妊娠期存在高血压、糖尿病、子痫前期等并发症时,会增加早产儿视网膜病变风险。 - 步骤 6:考量生长因子的作用
血管内皮生长因子(VEGF)、胰岛素样生长因子 - 1(IGF-1)等生长因子水平过低与视网膜病变发病密切相关,需在评估中纳入该因素。 - 步骤 7:整合所有因素进行综合风险评估
- 高风险:胎龄<28 周或出生体重<1000 克,且合并高氧暴露、多胎妊娠或妊娠并发症等额外因素;
- 中风险:胎龄 28-32 周、出生体重 1000-1500 克,且可能合并上述某一项风险因素;
- 低风险:胎龄>32 周、出生体重>1500 克,且无其他显著风险因素。
- 步骤 8:基于综合因素制定风险分类结论
结合所有相关因素,预测每位早产儿的视网膜病变风险等级。
4.4 基于上下文学习(ICL)策略的 ROP 风险预测
最后,本研究在指令型策略基础上,提出用于 ROP 风险预测的上下文学习(ICL)策略。该策略以 LLMs 为核心驱动,依托演示样本完成预测任务,且通过为 ROP 风险预测任务定制特定角色提示语启动流程。在本研究的 ICL 策略中,LLMs 被设定为 “眼科专家” 角色;同时,研究提供演示样本作为外部知识,以增强 “眼科专家” 角色的专业判断能力。
具体而言,检索模块首先从 CROP 数据集的训练集中,检索与当前输入样本最相关的案例,将其作为 LLMs 模块的演示样本。研究采用 BM25 算法 [41] 构建检索模块,该算法可有效评估不同样本间的相关性,相关计算逻辑如下:
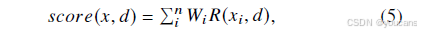
其中, x i x_i xi 代表样本 x 中的词汇,d 代表目标样本, W i W_i Wi 代表词汇权重, R ( x i , d ) R(x_i ,d) R(xi,d) 代表词汇与目标样本的相关性得分。
保留相关性最高的前 k 个样本作为演示样本,随后将这些演示样本及其真实标签按顺序输入 LLMs 模块,最后输入待查询样本以完成 ROP 风险预测。
因此,ICL 策略的最终输入可表述为:
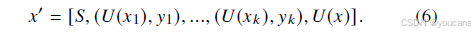
ICL 策略的优势源于演示样本提供的隐性诊断依据:扮演 “眼科专家” 角色的 LLMs 可从历史样本中提取经验,在优化预测准确性的同时,避免模型偏差带来的影响。
5. 实验
5.1 实验细节
5.1.1 大型语言模型(LLMs)
为验证 LLMs 在早产儿视网膜病变(ROP)风险预测中的能力与偏差,本研究对多类 LLMs 进行了评估,包括开源通用模型、闭源通用模型及专用医疗语言模型。其中:
开源通用模型:采用 GLM-4(9B)[42]、Gemma-2(27B)[43]、Yi(34B)[44]、DeepSeek(V2-16B、R1-distill-llama-70B)[2]、Mixtral-8×7B [45]、LLaMA-3.3(70B)[46]、LLaMA-4 [1]、Qwen-3(235B)[47] 及 Qwen-2.5(0.5B 至 72B)[48];
闭源通用模型:采用 GPT-3.5 [49]、GPT-4 [50]、GPT-4o [51]、o3-mini、o4-mini、Doubao-pro [52]、ERNIE-3.5 [53]、Baichuan-4 [54] 及 Claude-3.5 [55];
专用医疗模型:采用 Medllama(7B)、HuatuoGPT-o1(7B)[56]、Doctorai(8B)¹、Openbiollm(70B)[57]。
(注:¹https://ollama.com/)
5.1.2 实验设置
依据第 3 章(预备知识)的设计,本研究基于 CROP 数据集验证 LLMs 的 ROP 风险预测能力,该数据集包含低、中、高三类风险标签,样本分布分析如图 2 所示。为保证模型输出的一致性,将温度系数(temperature)与核采样(nucleus sampling)参数分别设为 0 和 1.0,模型最大输入长度设为 10K。此外,在上下文学习(ICL)策略中,演示样本数量设为 5,并开展了相关消融实验。
在 ROP 风险预测模型性能评估方面,采用的指标包括准确率(Acc.)、精确率(Prec.)、召回率(Rec.)及 F1 分数。指标缩写说明:GA&W 代表胎龄与出生体重(gestational age and birth weight),MP 代表多胎妊娠(multiple pregnancies),OE 代表氧暴露(oxygen exposure),PC 代表妊娠并发症(pregnancy complications)。实验硬件采用配备 48GB 显存的 NVIDIA A6000 显卡。
5.2 LLMs 的 ROP 风险预测能力
5.2.1 指令型策略(Instruction Scheme)的性能
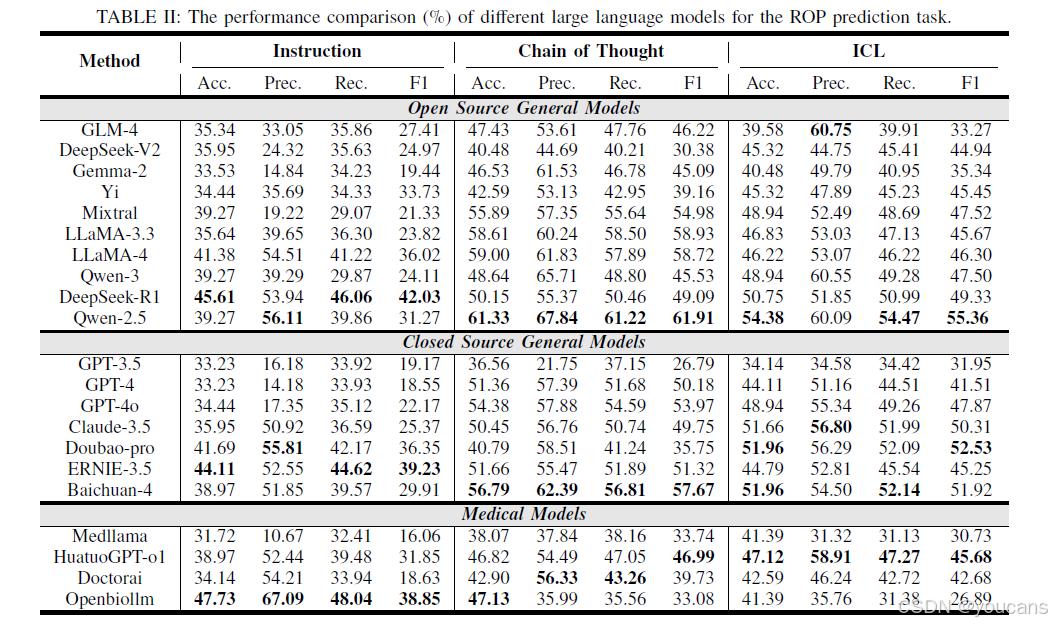
首先,本研究验证仅采用指令型策略时,LLMs 能否实现 ROP 风险预测。如表 2 所示,实验结果表明,多数 LLMs 的 ROP 风险预测效果不佳,准确率较低。例如,LLaMA-3.3 模型的准确率仅为 35.64%,这说明仅依赖 LLMs 的内在知识无法有效实现 ROP 风险预测,也难以提供可靠的诊断辅助。此外,随着模型参数规模的增大,开源通用模型中的 DeepSeek-R1 模型表现最优;且相较于 LLaMA-3.3 模型,蒸馏版 DeepSeek-R1 模型的准确率显著提升了 9.97%。
5.2.2 思维链(CoT)策略的性能
本研究验证了 CoT 策略在 LLMs 上的表现。结果显示,引入 CoT 策略后,与指令型策略相比,LLMs 的预测准确率显著提升。例如,LLaMA-3.3 模型的准确率平均提升了 25.21%。同时,在开源模型与闭源模型中,Qwen-2.5 与 Baichuan-4 模型分别表现最优。上述结果表明,CoT 策略有助于提升模型的预测性能,且能使模型的推理逻辑与 ROP 已知风险因素更好地对齐。
5.2.3 上下文学习(ICL)策略的性能
在 ICL 策略下,LLMs 的 ROP 风险预测准确率同样高于指令型策略。例如,Claude-3.5 模型的性能平均提升了 15.48%。然而,尽管 ICL 策略能提升模型性能,其效果仍不及 CoT 策略 —— 以 Qwen-2.5 模型为例,其在 ICL 策略下的性能较 CoT 策略平均下降了 7%。原因在于,与由已知风险因素构成的 CoT 策略相比,由演示样本构成的 ICL 策略对模型的推理能力及对 ROP 疾病的内在理解提出了更高要求。
5.2.4 不同来源模型的性能对比
从另一角度出发,本研究评估了不同来源模型的表现:在指令型策略中,专用医疗模型 Openbiollm 的表现最优,ROP 风险预测准确率达 47.73%,这表明经更多专业医疗样本微调的模型能具备更精准的 ROP 诊断能力(相较于 LLaMA-3.3 模型,准确率提升了 12.09%);而在 CoT 与 ICL 策略中,开源模型 Qwen-2.5 的表现优于其他 LLMs,其潜在原因可能是 Qwen-2.5 在中文任务上的性能始终优于其他模型,这与 Qwen-2.5 相关研究中的描述一致 [48]。
尽管 CoT 与 ICL 策略有助于提升模型的 ROP 风险预测准确率,但表现最优的 Qwen-2.5 模型准确率也仅为 61.33%,尚未达到理想水平。因此,通过 Affective-ROPTester 框架三类策略的验证,针对 “LLMs 的 ROP 风险预测效果如何” 这一问题,本研究得出结论:当前 LLMs 的 ROP 风险预测能力仍有待提升。
5.3 LLMs 在 ROP 风险预测中的偏差
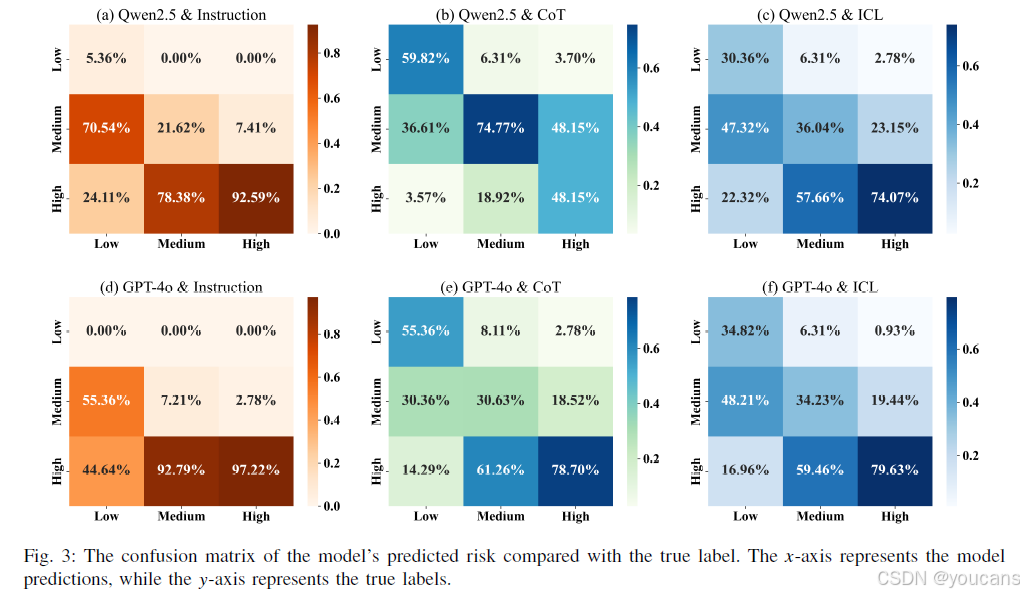
为验证 LLMs 在 ROP 风险预测中是否存在固有偏差,本研究分析了 Qwen-2.5 与 GPT-4o 模型风险输出结果的混淆矩阵(如图 3 所示)。具体而言,在指令型策略(第一列)中,模型明显倾向于输出高风险或中风险结果。例如,Qwen-2.5 模型对低风险样本的预测准确率仅为 5.36%,而对高风险样本的预测准确率达 92.59%;对于中风险样本,该模型也倾向于将其预测为高风险,且未出现任何低风险预测结果。
与 Qwen-2.5 模型相比,GPT-4o 模型的高风险预测倾向更为显著。例如,对于低风险样本,其正确预测率为 0%,而高风险预测占比达 44.64%,显著高于 Qwen-2.5 模型的 24.11%;在中风险样本中,GPT-4o 模型将其误判为高风险的比例高达 92.79%。上述分析表明,未引入外部知识的 LLMs(原生 LLMs)倾向于将 ROP 风险预测为中风险或高风险,这回答了 “LLMs 在 ROP 风险预测中是否存在偏差” 的问题,证实了 LLMs 存在此类预测偏差。此外,GPT-4o 模型的偏差较 Qwen-2.5 更为明显,这也是其性能稳定性不及 Qwen-2.5 的原因。
此外,在 CoT 与 ICL 策略下,模型的偏差得到显著缓解:低风险样本的预测准确率大幅提升,高风险预测占比下降。例如,在 CoT 策略下,Qwen-2.5 模型对低风险样本的低风险预测率达 59.82%,高风险预测占比降至 3.57%。这一结果间接印证了仅依赖模型内在知识进行 ROP 风险预测存在偏差。
最后,本研究通过案例分析展示了 GPT-4o 模型的诊断过程(如图 5 所示):一名胎龄近 29 周、出生体重 1.13 千克的早产儿,根据已知风险因素应归为中风险;但 GPT-4o 模型将胎龄<30 周、体重<1.5 千克的婴儿均误判为高风险,存在明显误差。由此可见,模型偏差的成因可能是其评估标准过于严格,导致倾向于输出高风险预测。

5.4 不同情感框架下的 ROP 风险预测
5.4.1 不同情感框架的性能对比
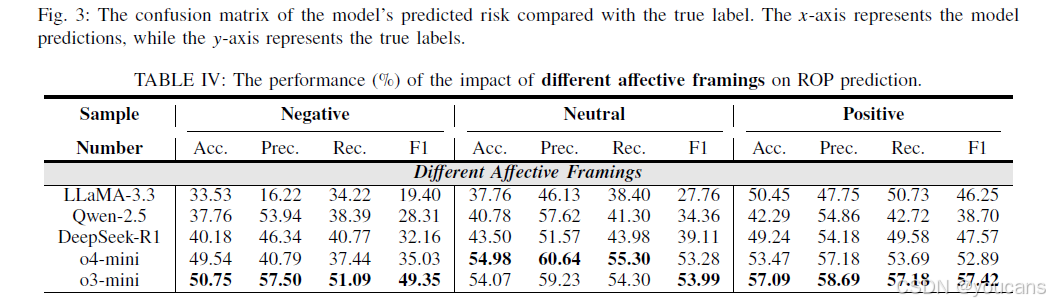
如表 4 所示,不同情感框架对 LLMs 的 ROP 风险预测能力存在显著影响。研究发现,与中性和积极情感框架相比,消极情感框架对预测准确率存在显著不利影响。例如,在 DeepSeek-R1 模型中,消极情感框架下的准确率为 40.18%,中性情感框架下提升至 43.50%(提升 3.32%),而积极情感框架下进一步提升至 49.24%(较消极框架提升 9.06%)。这一规律在其他模型中同样存在。因此,本研究得出结论:与消极情感框架相比,中性或积极情感框架有助于提升 ROP 风险预测的准确率,这回答了 “提示语中的情感元素对 LLMs 预测结果及偏差的影响程度” 这一问题。
5.4.2 不同情感框架对偏差的影响
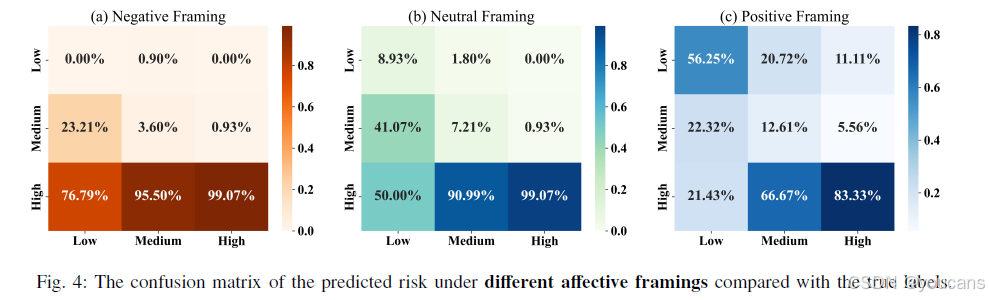
在 5.3 节中,本研究观察到 LLMs 倾向于将 ROP 风险预测为中风险或高风险,这可能源于模型对早产儿病情的 “过度悲观假设”。一个可行的解决方案是引入情感提示语以缓解偏差。如图 4 所示,研究呈现了不同情感框架下模型的风险预测倾向:在消极与中性情感框架下,模型仍倾向于预测中风险或高风险,这与 5.3 节的观察结果一致;相反,引入不同情感框架后,这种偏差得到显著缓解。例如,对于低风险样本,在消极情感框架下模型预测为高风险的概率为 76.79%,中性框架下降至 50%,而积极情感框架下仅为 21.43%。这表明在 ROP 风险预测场景中,嵌入积极情感框架的提示语有助于降低 LLMs 的预测偏差。
5.5 Affective-ROPTester 的消融实验
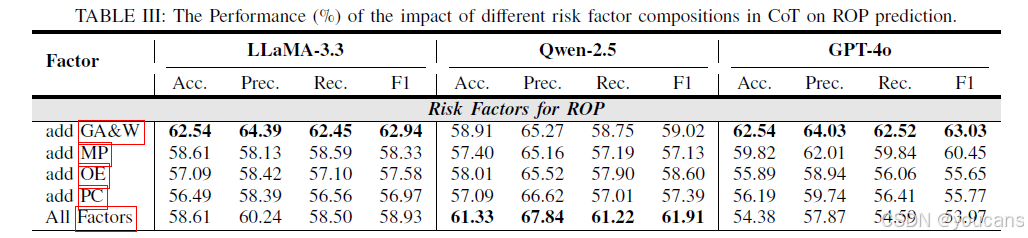
5.5.1 ROP 的不同风险因素
为分析 CoT 策略中已知风险因素对 ROP 预测的影响,本研究开展了消融实验。由表 3 可知,当 CoT 策略仅纳入胎龄与出生体重时,LLaMA-3.3 与 GPT-4o 模型的 ROP 风险预测效果最优。例如,GPT-4o 模型在该设置下的平均指标达 63.03%,高于纳入其他风险因素的结果。这一现象的原因在于,与其他风险因素相比,胎龄与出生体重具有明确的数值基础,能更有效地辅助模型进行预测。
5.5.2 ROP 风险预测的演示样本数量
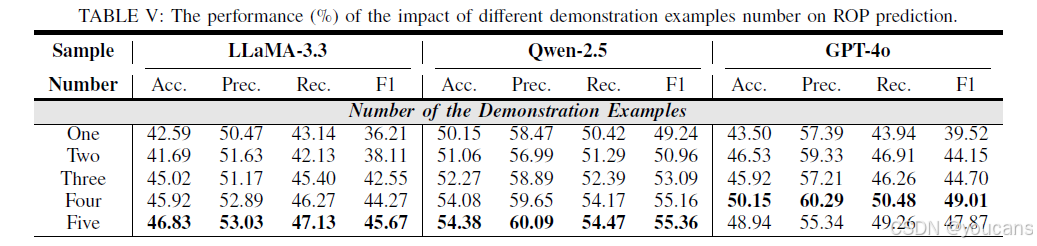
本研究分析了 ICL 策略中演示样本数量对模型性能的影响,结果如表 5 所示。随着演示样本数量的增加,LLMs 的 ROP 风险预测准确率逐渐提升。例如,LLaMA-3.3 模型的平均指标从初始的 43.1% 提升至 48.16%,这表明演示样本能辅助模型提升预测效果。此外,在 GPT-4o 模型中,当演示样本数量为 4 时,模型性能达到最优,这说明过多的演示样本也可能影响预测准确率。
5.5.3 模型推理与微调的影响
表 8 展示了具备推理能力的模型是否能优化 ROP 诊断性能。首先,研究发现,与 DeepSeek-R1 推理模型相比,o3-mini 模型的性能显著提升,准确率增加了 6.64%;此外,与非推理模型 GPT-4o 相比,推理模型的准确率提升了 2.41%,这表明推理能力有助于提升模型的 ROP 预测性能。然而,推理模型的性能仍不及 Qwen-2.5 模型。最后,本研究通过图 5 展示了 ROP 预测过程的案例分析:不难发现,模型将胎龄>28 周的早产儿归为高风险,这与已知风险因素不符,再次证明模型的 ROP 预测能力仍存在不足。此外,研究采用 LoRA 技术 [58] 对 Qwen2.5:7B 模型进行微调,结果显示其预测准确率仅为 44.11%。
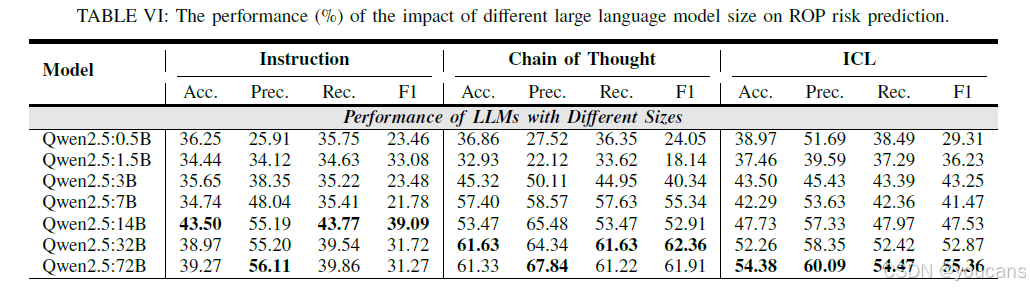
5.5.4 不同参数规模的 LLMs
为进一步验证不同参数规模 LLMs 的 ROP 风险预测能力,本研究采用参数规模从 0.5B 到 72B 的 Qwen-2.5 系列模型开展实验。由表 6 可知,在指令型策略中,模型的 ROP 风险预测准确率与参数规模无正相关关系,这是因为仅依赖模型内在知识无法准确诊断 ROP 风险;在 CoT 与 ICL 策略中,外部知识的引入显著提升了 ROP 风险预测准确率,且随着模型参数规模的增大,其推理能力相应增强,进而使 ROP 风险预测准确率逐步提升。
5.5.5 不同网络结构的模型性能
通过对比不同网络结构模型的性能,本研究发现,密集结构(dense structure)模型的表现优于混合专家(MoE)模型。如表 9 所示,Qwen2.5:7B 模型(密集结构)的预测准确率比 Mixtral 模型(MoE 结构)高 1.51%。此外,研究还探索了 CoT 与 ICL 策略结合场景下的模型 ROP 风险预测性能,实验结果显示该组合未带来性能提升 —— 相反,Qwen2.5:72B 模型的准确率下降了 4.84%。
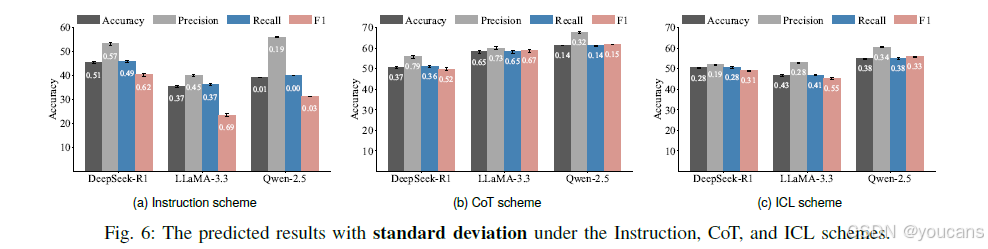
5.5.6 含标准差的实验结果
此外,本研究还呈现了 DeepSeek-R1、LLaMA-3.3 与 Qwen-2.5 模型在各策略下的含标准差预测结果(如图 6 所示)。结果显示,所有指标的标准差大多小于 0.5。例如,在 ICL 策略设置下,DeepSeek-R1 模型的标准差为 0.28,这表明本研究的实验结果具有良好的稳定性。
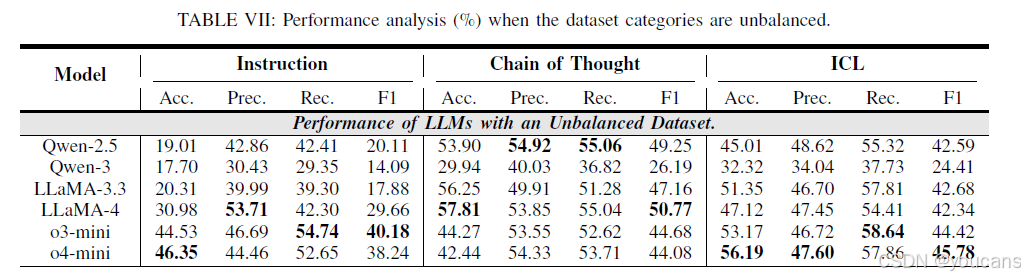
5.5.7 非平衡数据集的实验结果
为进一步验证模型 ROP 预测偏差等研究结论的可靠性,本研究采用未考虑样本类别平衡的全部样本(共 3922 条)开展实验。该非平衡数据集包含 2813 条低风险样本、848 条中风险样本与 331 条高风险样本,实验结果如表 7 所示。研究发现,与表 2 中的平衡数据集结果相比,模型的预测准确率更低。例如,Qwen-2.5 模型在指令型策略下的准确率仅为 19.01%,原因在于模型本身存在将 ROP 风险高估为中风险或高风险的偏差,而非平衡数据集中低风险样本占比更高,导致错误预测比例上升。上述结果进一步验证了 “模型在 ROP 预测中存在偏差” 这一研究结论。
5.5.8 疾病预测与疾病诊断的区别
在传统智能医疗领域,LLMs 可基于病历与影像学检查诊断患者是否患病,用于评估患者当前健康状况。例如,在 ROP 领域,LLMs 可诊断早产儿是否已出现视网膜病变 [31]。然而,本研究与传统 ROP 诊断不同:研究聚焦于仅通过入院记录预测早产儿的 ROP 风险,旨在在 ROP 发病机制尚不明确的前提下,提前预测早产儿的 ROP 风险,以实现早期发现与干预。
5.5.9 LLMs 的 ROP 相关知识储备
表 10 展示了 GPT-4 模型对 ROP 知识的介绍。可见,该模型具备 ROP 相关的关键知识,例如将体重与胎龄作为 ROP 风险预测的依据。尽管模型掌握 ROP 相关知识,但实验结果表明其 ROP 预测能力仍不足且存在显著偏差,这凸显了进一步探索 ROP 预测算法的重要性。
(注:原文中提及的表 2 至表 10、图 5 至图 6,均为实验数据与结果的结构化呈现,表格内容包含不同模型在各策略 / 情感框架 / 参数规模下的准确率、精确率、召回率及 F1 分数,图 5 为 GPT-4o 模型基于指令型策略的 ROP 风险预测案例推理过程,图 6 为三种策略下模型预测结果的标准差对比图)

6. 参考文献
[1] G. Zhang
版权说明:
本文由 youcans@xidian 对论文 “Affective-ROPTester: LLMs的能力和偏差分析在预测 ROP 病变中的应用”(Affective-ROPTester: Capability and Bias Analysis of LLMs in Predicting Retinopathy of Prematurity) 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
引用格式: Zhao S, Zhang Y L, Xiao L W, et al. Affective-ROPTester: Capability and Bias Analysis of LLMs in Predicting Retinopathy of Prematurity[EB/OL]. 2025. https://arxiv.org/pdf/2507.05816
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】Affective-ROPTester: LLMs的能力和偏差分析在预测 ROP 病变中的应用
(https://youcans.blog.csdn.net/article/details/153726758)
Crated:2025-10

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 35
35 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)