[ 钓鱼实战系列-基础篇-4 ] 一篇文章教会你用红队思维收集目标邮箱信息-2(附邮箱收集自动化脚本)
[ 钓鱼实战系列-基础篇-4 ] 一篇文章教会你用红队思维收集目标邮箱信息-2(附邮箱收集自动化脚本)网络钓鱼不仅是一种网络攻击技术同时也是一项最常见的社会工程技术,更是红队选手和网络犯罪分子的惯用伎俩。本文我们探讨收集目标邮箱自动化脚本。
🍬 博主介绍
👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~
✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】
🎉点赞➕评论➕收藏 == 养成习惯(一键三连)😋
🎉欢迎关注💗一起学习👍一起讨论⭐️一起进步📝文末有彩蛋
🙏作者水平有限,欢迎各位大佬指点,相互学习进步!
网络钓鱼不仅是一种网络攻击技术同时也是一项最常见的社会工程技术,更是红队选手和网络犯罪分子的惯用伎俩。
本文我们探讨收集目标邮箱自动化脚本。
文章目录
1.4.4 邮件爬取
1.4.4.1 基于搜索引擎的邮箱爬取
1.收集来源
利用搜索引擎搜索指定页面中存在的邮箱。
2.脚本内容
#! /usr/bin/env python
# _*_ coding:utf-8 _*_
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import sys
def bing_search(site, pages):
Subdomain = []
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip,deflate',
'Referer': "http://cn.bing.com/search?q=email+site%3abaidu.com&qs=n&sp=-1&pq=emailsite%3abaidu.com&first=2&FORM=PERE1",
'Cookie': "加入自己的cookie值"
}
for i in range(1,int(pages)+1):
url = "https://cn.bing.com/search?q=site%3a"+site+"&go=Search&qs=ds&first="+ str((int(i)-1)*10) +"&FORM=PERE"
conn = requests.session()
conn.get('http://cn.bing.com', headers=headers)
html = conn.get(url, stream=True, headers=headers, timeout=8)
soup = BeautifulSoup(html.content, 'html.parser')
# print(soup)
job_bt = soup.findAll('h2') # 寻找h2标签
# print(job_bt)
for i in job_bt:
# print(i)
link = i.a.get('href') if i.a else None
# print(link)
if link:
domain = str(urlparse(link).scheme + "://" + urlparse(link).netloc)
# print(domain)
if domain in Subdomain: # 去重
pass
else:
Subdomain.append(domain)
print(domain)
if __name__ == '__main__':
# site=baidu.com
if len(sys.argv) == 3:
site = sys.argv[1]
page = sys.argv[2]
else:
print ("usage: %s baidu.com 10" % sys.argv[0])
sys.exit(-1)
Subdomain = bing_search(site, page)
3.脚本内容解析
这个脚本是一个使用Python编写的脚本,用于通过Bing搜索引擎搜索特定网站的子域名。
可以自己进行优化,可以加入多线程来加速搜索过程,并且可以结合了Bing和Baidu及其他的搜索引擎进行搜索。
以下是对代码的详细解释:
1.导入模块
requests: 用于发送HTTP请求。
BeautifulSoup: 用于解析HTML内容。
urlparse: 用于解析URL。
sys: 用于处理命令行参数。
2.定义函数 banner(),打印一个指纹信息。
site: 要搜索的站点(例如 baidu.com)。
pages: 要搜索的页数。
3.定义函数 usage(),打印使用帮助信息。
Subdomain: 用于存储找到的子域名。
headers: HTTP请求头,模拟浏览器行为。
4.逻辑
循环遍历每一页,构建搜索URL并发送请求。
使用BeautifulSoup解析返回的HTML内容。
查找所有<h2>标签,提取其中的链接。
解析链接,获取域名,并检查是否已经存在于Subdomain列表中,避免重复。
如果域名不存在于列表中,则将其添加到列表并打印出来。
5.主程序部分
检查命令行参数是否正确。如果不正确,打印用法信息并退出。
调用bing_search函数,传入用户输入的站点和页数。
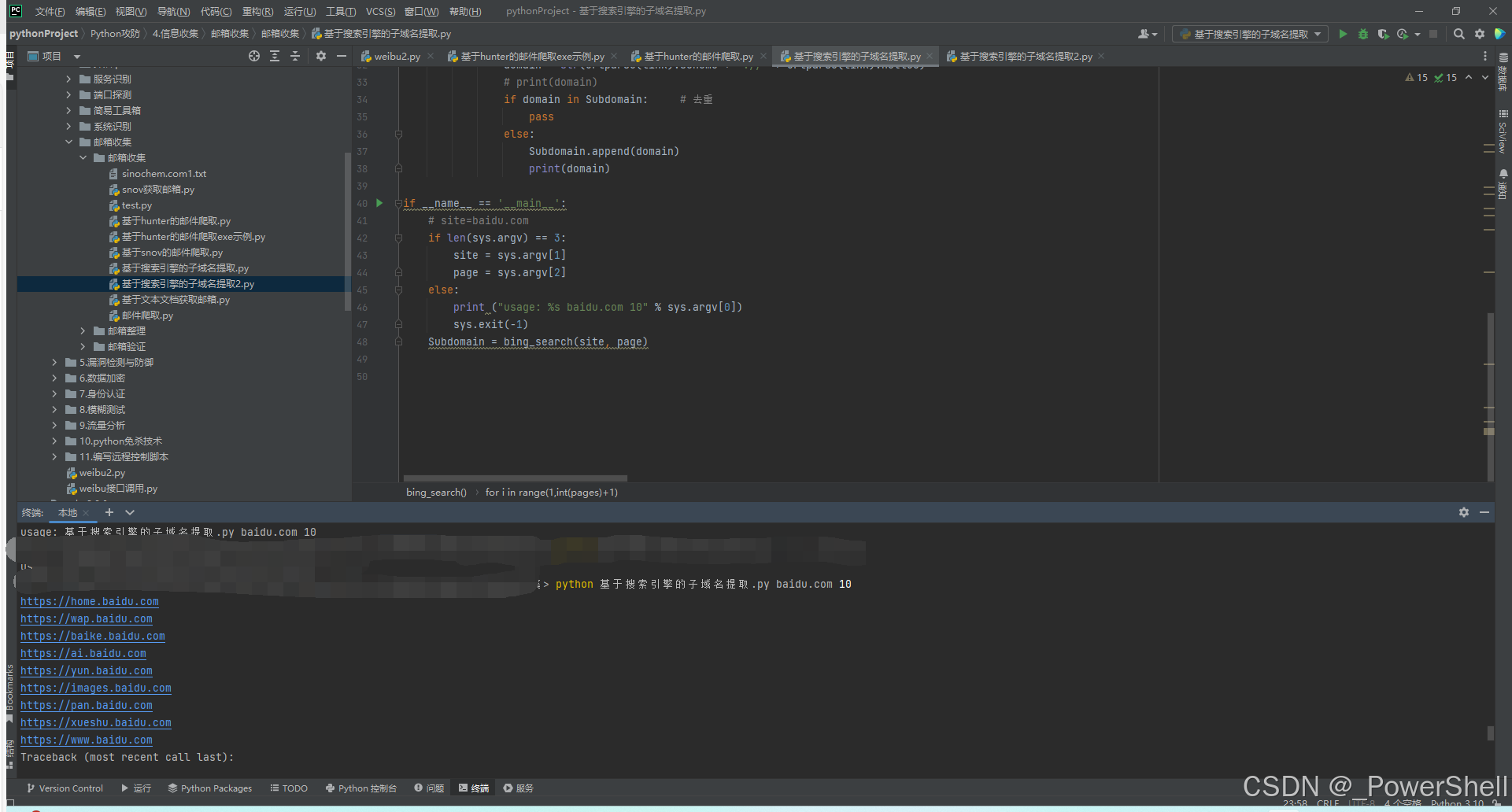
4.脚本使用介绍
注意事项:
需要在上述脚本中加入自己搜索引擎的cookie
参数说明:
python 基于搜索引擎的子域名提取.py 目标站点 页数
使用示例:
python 基于搜索引擎的子域名提取.py baidu.com 10
1.4.4.2 基于hunter的邮箱爬取
1.收集来源
Hunter还是非常不错的,Hunter 可让你在几秒钟内找到专业的电子邮件地址,并与重要的人联系。
我们可以通过使用 Hunter 去收集一个网站的电子邮件信息,可以使用插件更便捷的搜索。或者直接访问 Hunter 的官方网址,在搜索栏中搜索。也可以点击查看来源,查看到邮箱地址的来源。来源地址就可以成为 Email 信息收集的一个方向,从这一个点出发,扩散到一个面,进行渗透测试。
https://hunter.io/
2.脚本内容
import requests
from bs4 import BeautifulSoup
import json
import argparse
def find_emails(domain, num_emails):
api_key = "填入自己的api_key"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0'}
url = f"https://api.hunter.io/v2/domain-search?domain={domain}&api_key={api_key}"
try:
response = requests.get(url, headers=headers)
data = response.json()
emails = [result['value'] for result in data['data']['emails'][:num_emails]]
return emails
except Exception as e:
print(f"获取邮箱时发生错误: {e}")
return []
def save_to_file(emails, file_path):
try:
with open(file_path, 'a') as f:
for email in emails:
f.write(email + '\n')
except Exception as e:
print(f"保存到文件时发生错误: {e}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="获取指定域名的邮箱")
parser.add_argument('-t', '--target', help='目标域名', required=True)
parser.add_argument('-c', '--num_emails', type=int, help='获取多少个邮箱', default=10)
parser.add_argument('-f', '--save_to_file', action='store_true', help='保存到文件')
parser.add_argument('-o', '--output_file', help='指定文件路径', default='emails.txt')
args = parser.parse_args()
domain = args.target
num_emails = args.num_emails
save_to_file_flag = args.save_to_file
output_file = args.output_file
try:
emails = find_emails(domain, num_emails)
if save_to_file_flag:
save_to_file(emails, output_file)
else:
for email in emails:
print(email)
except Exception as e:
print(f"程序运行过程中发生错误: {e}")
3.脚本内容解析
这个Python脚本的主要功能是从Hunter.io API获取指定域名的邮箱地址,并将这些邮箱地址保存到文件中或打印到控制台。
以下是对脚本的详细解释:
1.导入模块
requests: 用于发送HTTP请求。
BeautifulSoup: 用于解析HTML内容(虽然在这个脚本中没有实际使用)。
json: 用于处理JSON数据。
argparse: 用于解析命令行参数。
2.函数定义
find_emails(domain, num_emails),这个函数从Hunter.io API获取指定域名的邮箱地址。
save_to_file(emails, file_path),这个函数将邮箱地址保存到指定的文件路径。
3.变量
api_key: 需要替换成你自己的Hunter.io API密钥。
headers: 设置请求头,模拟浏览器行为。
url: 构建API请求URL。
response: 发送GET请求并获取响应。
data: 将响应转换为JSON格式。
emails: 提取前num_emails个邮箱地址。
file_path: 文件路径。
4.逻辑
解析命令行参数:用户通过命令行输入目标域名、邮箱数量、是否保存到文件以及输出文件路径。
获取邮箱地址:调用find_emails函数,通过Hunter.io API获取指定数量的邮箱地址。
保存或打印结果:根据用户选择,将邮箱地址保存到文件或打印到控制台。
5.主程序部分
使用argparse解析命令行参数。
-t或–target: 目标域名(必需)。
-c或–num_emails: 获取的邮箱数量(默认为10)。
-f或–save_to_file: 是否保存到文件(布尔值)。
-o或–output_file: 输出文件路径(默认为emails.txt)。
根据解析的参数调用find_emails函数获取邮箱地址。
根据save_to_file_flag决定是保存到文件还是打印到控制台。
如果发生异常,打印错误信息。
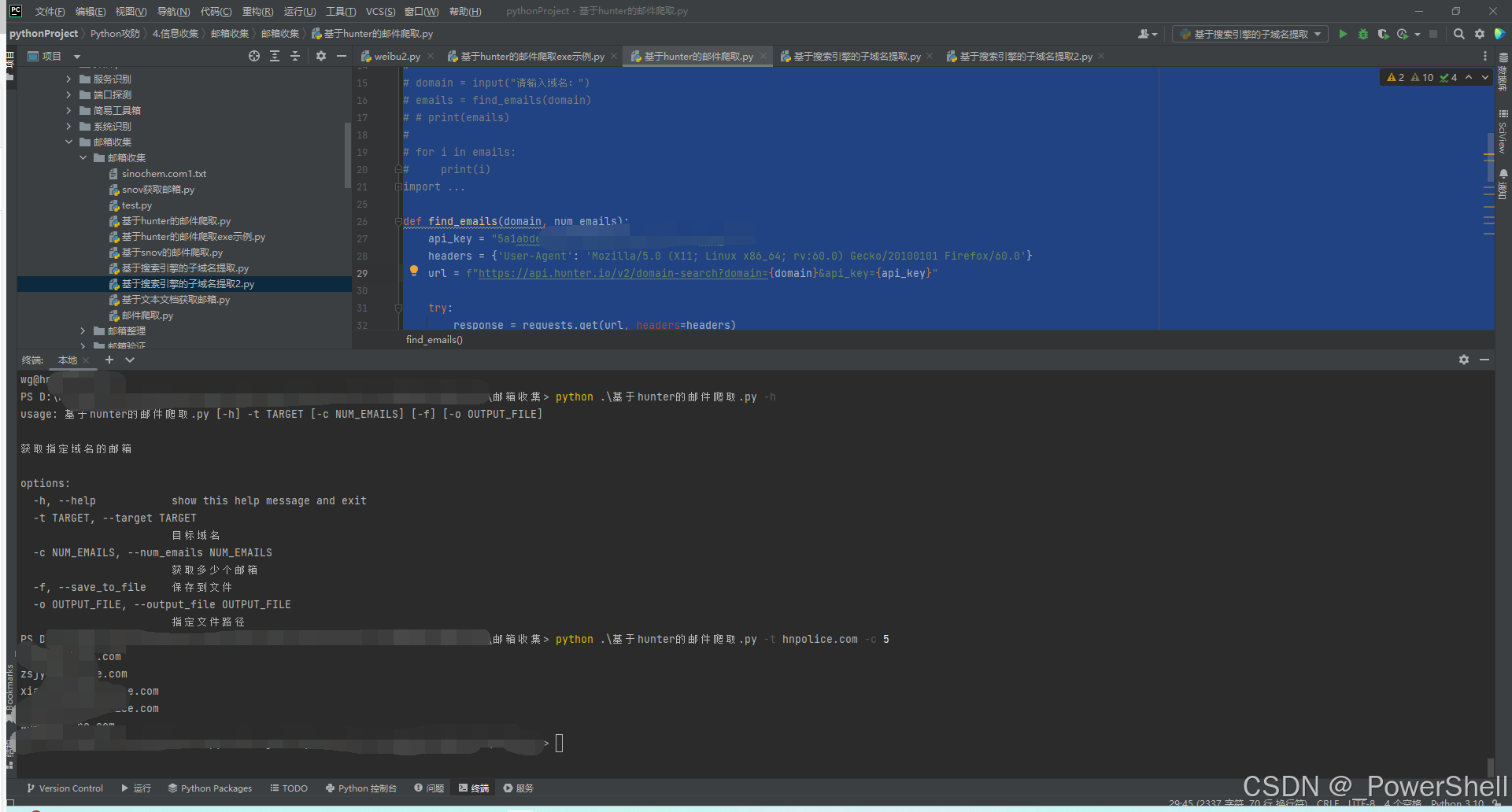
4.脚本使用介绍
注意事项:
使用时需要在上述脚本中填入自己 hunter.io 的api_key
使用参数:
-h, --help show this help message and exit
-t TARGET, --target TARGET
目标域名
-c NUM_EMAILS, --num_emails NUM_EMAILS
获取多少个邮箱
-f, --save_to_file 保存到文件
-o OUTPUT_FILE, --output_file OUTPUT_FILE
指定保存的文件路径
使用示例:
python .\基于hunter的邮件爬取.py -h
python .\基于hunter的邮件爬取.py -t xxx.com -c 5
python .\基于hunter的邮件爬取.py -t xxx.com -c 5 -f -o output.txt
1.4.4.3 基于snov的邮箱爬取
1.收集来源
snov可收集大量邮箱信息,极少数有有员工的姓名、职位、性别、联系电话。
注册需要企业邮箱,大部分十分钟邮箱目前已被列进黑名单,可用谷歌账号登录,查询企业邮箱信息,一个账号50次查询机会,有几个可用十分钟邮箱一直注册查询。
参考介绍:https://cn-sec.com/archives/396926.html
https://snov.io/
2.脚本内容
import json, requests
import argparse
def get_access_token():
params = {
'grant_type': 'client_credentials',
'client_id': '',
'client_secret': ''
}
try:
res = requests.post('https://api.snov.io/v1/oauth/access_token', data=params)
resText = res.text.encode('ascii', 'ignore')
return json.loads(resText)['access_token']
except Exception as e:
print("获取访问令牌时发生错误:", e)
return None
def get_domain_search(domain):
token = get_access_token()
if token is None:
return None
params = {
'access_token': token,
'domain': domain,
'type': 'all',
'limit': 20,
'lastId': 0
}
try:
res = requests.get('https://api.snov.io/v2/domain-emails-with-info', params=params)
return json.loads(res.text)
except Exception as e:
print("获取域名搜索结果时发生错误:", e)
return None
def save_to_file(data, file_path):
if data is None:
return
with open(file_path, 'a') as f:
for i in data['emails']:
f.write(i['email'] + '\n')
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='获取指定域名的电子邮件地址')
parser.add_argument('-t', '--target', help='输入目标域名', required=True)
parser.add_argument('-f', '--file', help='保存到文件', action='store_true')
parser.add_argument('-o', '--output', help='指定文件路径', default='output.txt')
args = parser.parse_args()
a = get_domain_search(args.target)
if a is not None:
print(a['lastId'])
for i in a['emails']:
print(i['email'])
if args.file:
save_to_file(a, args.output)
else:
print("无法获取域名搜索结果")
3.脚本内容解析
这个脚本是一个用于获取指定域名的电子邮件地址的工具。它通过调用第三方API(snov.io)来获取数据,并将结果保存到文件中。
以下是对脚本的详细解释:
1.导入模块
json: 用于处理JSON格式的数据。
requests: 用于发送HTTP请求。
argparse: 用于解析命令行参数。
2.函数定义
get_access_token(),这个函数用于获取令牌进行身份认证 。
get_domain_search(domain),获取域名搜索结果函数。
save_to_file(data, file_path),文件保存函数。
3.变量
params: 包含获取访问令牌所需的参数,包括授权类型、客户端ID和客户端密钥。
requests.post: 向API发送POST请求以获取访问令牌。
json.loads: 将响应文本转换为JSON对象并提取访问令牌。
get_access_token: 获取访问令牌。
params: 包含查询参数,包括访问令牌、目标域名、查询类型、限制数量和最后一条记录的ID。
requests.get: 向API发送GET请求以获取域名的电子邮件地址。
json.loads: 将响应文本转换为JSON对象并返回。
data: 包含要保存的电子邮件地址的数据。
file_path: 保存文件的路径。
argparse.ArgumentParser: 创建命令行参数解析器。
parser.add_argument: 定义命令行参数,包括目标域名、是否保存到文件以及输出文件路径。
args = parser.parse_args(): 解析命令行参数。
get_domain_search(args.target): 获取指定域名的电子邮件地址。
4.逻辑
解析命令行参数:用户通过命令行输入目标域名、是否保存到文件以及输出文件路径。
获取邮箱地址:调用 get_domain_search 函数,通过 snov API 获取指定数量的邮箱地址。
保存或打印结果:根据用户选择,将邮箱地址保存到文件或打印到控制台。
5.主程序部分
使用argparse解析命令行参数。
-t或–target: 目标域名(必需)。
-c或–num_emails: 获取的邮箱数量(默认为10)。
-f或–save_to_file: 是否保存到文件(布尔值)。
-o或–output_file: 输出文件路径(默认为emails.txt)。
根据解析的参数调用find_emails函数获取邮箱地址。
根据save_to_file_flag决定是保存到文件还是打印到控制台。
如果发生异常,打印错误信息。
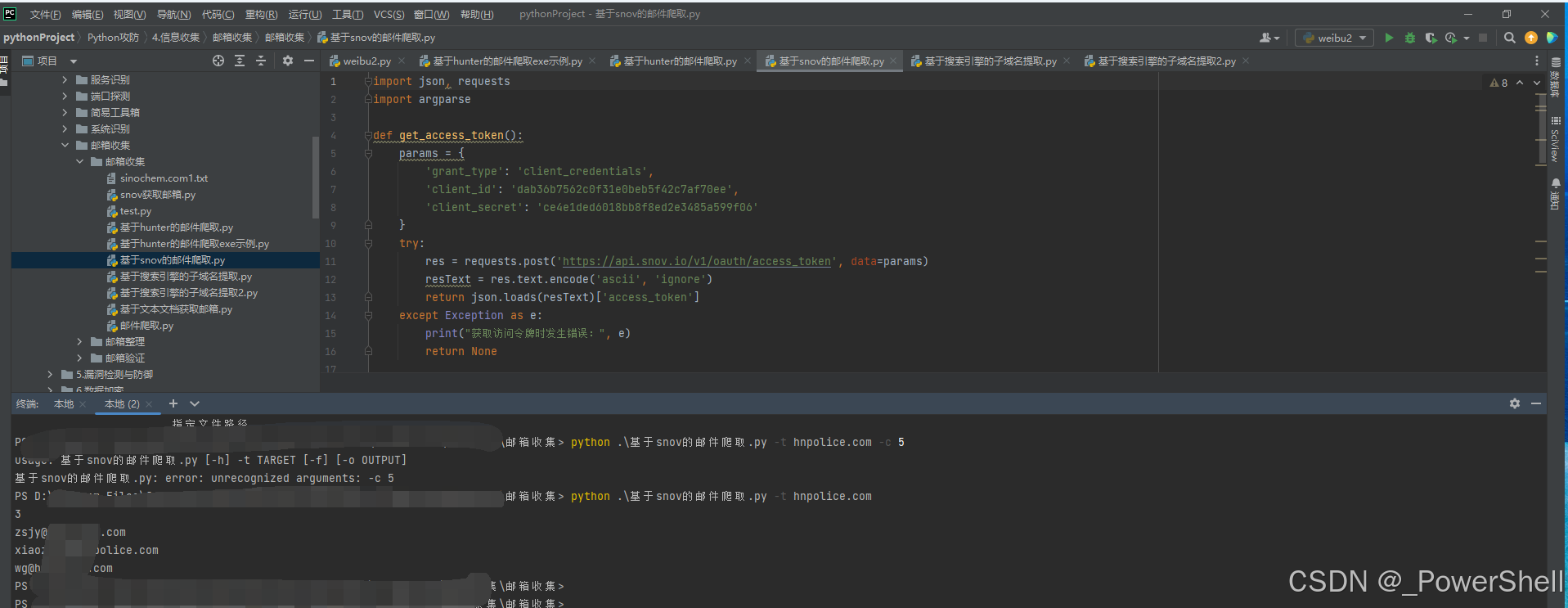
4.脚本使用介绍
注意事项:
需要加入自己 snov 的 client_id 和 client_secret 值
参数介绍:
usage: 基于snov的邮件爬取.py [-h] -t TARGET [-f] [-o OUTPUT]
-h, --help show this help message and exit
-t TARGET, --target TARGET
输入目标域名
-f, --file 保存到文件
-o OUTPUT, --output OUTPUT
指定文件路径
使用示例:
python .\基于snov的邮件爬取.py -h
python .\基于snov的邮件爬取.py -t xxx.com
python .\基于snov的邮件爬取.py -t xxx -f -o output.txt
1.4.4.4 基于mailverifier验证邮箱有效性
1.验证来源
mail-verifier 邮箱侦探
https://www.mail-verifier.com/
2.脚本内容
import requests
from bs4 import BeautifulSoup
import json
import argparse
def verifier_emails(email):
api_key = "80D59C7BB08596B61407F03660C10A4F"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0'}
url = f"https://api.mail-verifier.xyz/?cmd=verify&key={api_key}&email={email}"
response = requests.get(url, headers=headers)
data = response.json()
return data['code'] == 1
def read_emails_from_txt(file_path):
with open(file_path, 'r') as file:
emails = [line.strip() for line in file.readlines()]
return emails
def main():
parser = argparse.ArgumentParser(description="验证邮箱地址")
parser.add_argument("-t", "--target", help="单个邮箱目标")
parser.add_argument("-c", "--input_file", help="输入txt文件")
parser.add_argument("-f", "--save_to_file", action="store_true", help="保存到文件")
parser.add_argument("-o", "--output_file", help="指定文件路径")
args = parser.parse_args()
if args.target:
email = args.target
if verifier_emails(email):
print(f"有效的邮箱地址:{email}")
if args.save_to_file:
with open(args.output_file, "a") as file:
file.write(f"{email}\n")
elif args.input_file:
emails = read_emails_from_txt(args.input_file)
valid_emails = []
for email in emails:
if verifier_emails(email):
valid_emails.append(email)
print("有效的邮箱地址:")
for email in valid_emails:
print(email)
if args.save_to_file:
with open(args.output_file, "a") as file:
file.write(f"{email}\n")
if __name__ == "__main__":
main()
3.脚本内容解析
这个脚本是一个用于获取指定域名的电子邮件地址的工具。它通过调用第三方API(snov.io)来获取数据,并将结果保存到文件中。
以下是对脚本的详细解释:
1.导入模块
json: 用于处理JSON格式的数据。
requests: 用于发送HTTP请求。
argparse: 用于解析命令行参数。
2.函数定义
get_access_token(),这个函数用于获取令牌进行身份认证 。
get_domain_search(domain),获取域名搜索结果函数。
save_to_file(data, file_path),文件保存函数。
3.变量
params: 包含获取访问令牌所需的参数,包括授权类型、客户端ID和客户端密钥。
requests.post: 向API发送POST请求以获取访问令牌。
json.loads: 将响应文本转换为JSON对象并提取访问令牌。
get_access_token: 获取访问令牌。
params: 包含查询参数,包括访问令牌、目标域名、查询类型、限制数量和最后一条记录的ID。
requests.get: 向API发送GET请求以获取域名的电子邮件地址。
json.loads: 将响应文本转换为JSON对象并返回。
data: 包含要保存的电子邮件地址的数据。
file_path: 保存文件的路径。
argparse.ArgumentParser: 创建命令行参数解析器。
parser.add_argument: 定义命令行参数,包括目标域名、是否保存到文件以及输出文件路径。
args = parser.parse_args(): 解析命令行参数。
get_domain_search(args.target): 获取指定域名的电子邮件地址。
4.逻辑
解析命令行参数:用户通过命令行输入目标域名、是否保存到文件以及输出文件路径。
获取邮箱地址:调用 get_domain_search 函数,通过 snov API 获取指定数量的邮箱地址。
保存或打印结果:根据用户选择,将邮箱地址保存到文件或打印到控制台。
5.主程序部分
使用argparse解析命令行参数。
-t或–target: 目标域名(必需)。
-c或–num_emails: 获取的邮箱数量(默认为10)。
-f或–save_to_file: 是否保存到文件(布尔值)。
-o或–output_file: 输出文件路径(默认为emails.txt)。
根据解析的参数调用find_emails函数获取邮箱地址。
根据save_to_file_flag决定是保存到文件还是打印到控制台。
如果发生异常,打印错误信息。
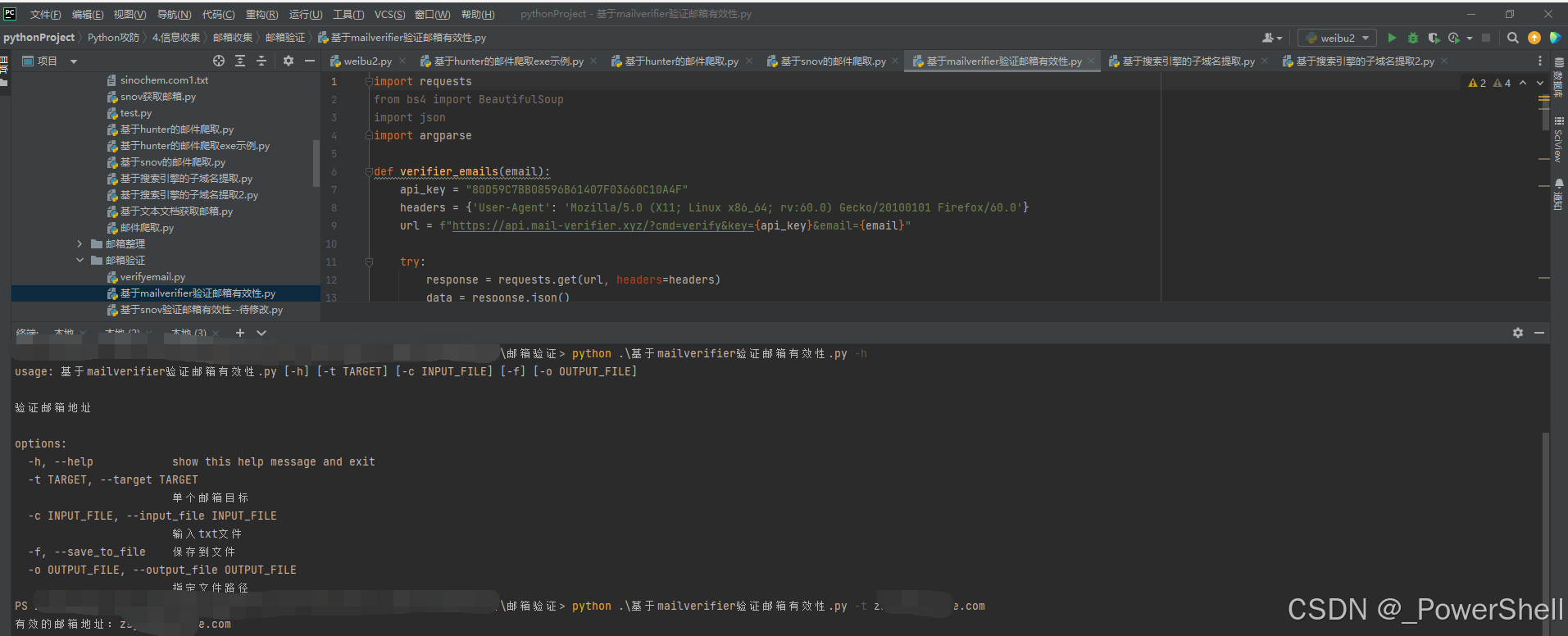
4.脚本使用介绍
注意事项:
需要加入自己 snov 的 client_id 和 client_secret 值
参数介绍:
usage: 基于mailverifier验证邮箱有效性.py [-h] [-t TARGET] [-c INPUT_FILE] [-f] [-o OUTPUT_FILE]
-h, --help show this help message and exit
-t TARGET, --target TARGET
单个邮箱目标
-c INPUT_FILE, --input_file INPUT_FILE
输入txt文件
-f, --save_to_file 保存到文件
-o OUTPUT_FILE, --output_file OUTPUT_FILE
指定文件路径
使用示例:
python .\基于mailverifier验证邮箱有效性.py -h
python .\基于mailverifier验证邮箱有效性.py -t xxx@xxx.com
python .\基于mailverifier验证邮箱有效性.py -t xxx@xxx.com -f -o output.txt
python .\基于mailverifier验证邮箱有效性.py -t xxx@xxx.com -c input.txt -f -o output.txt
相关资源
[ 提升篇 ] 钓鱼实战系列
[ 钓鱼实战系列-基础篇-4 ] 一篇文章教会你用红队思维收集目标邮箱信息-1(附邮箱收集自动化脚本)

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 91
91 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)