本地基于GGUF部署的DeepSeek实现轻量级调优之一:提示工程(Prompt Engineering)(完整详细教程)
前文,我们在本地windows电脑基于GGUF文件,部署了DeepSeek-1.5B模型,如果想自行对模型进行训练,离线模式下加载本地的DeepSeek模型进行训练时,是不能直接使用GGUF文件进行训练。(1)推理优化:GGUF(GPT-Generated Unified Format)是专为高效推理设计的二进制格式,常用于llama.cpp等工具在CPU/GPU上运行量化模型。(2)量化支持:支
前文,我们在本地windows电脑基于GGUF文件,部署了DeepSeek-1.5B模型,如果想自行对模型进行训练,离线模式下加载本地的DeepSeek模型进行训练时,是不能直接使用GGUF文件进行训练。
请参照我的文章在本地部署好模型之后再继续往下看:个人windows电脑上安装DeepSeek大模型(完整详细可用教程)-CSDN博客
一、GGUF文件的定位与限制
1.GGUF的作用:
(1)推理优化:GGUF(GPT-Generated Unified Format)是专为高效推理设计的二进制格式,常用于llama.cpp等工具在CPU/GPU上运行量化模型。
(2)量化支持:支持多种量化方法(如Q4_K_M、Q5_K_S),显著减少显存占用,但会损失部分精度。
2.训练限制:
(1)缺乏训练所需信息:GGUF文件仅包含推理所需的权重和架构简略信息,缺少训练必需的反向传播梯度计算图、优化器状态等。
(2)框架不兼容:主流训练框架(如PyTorch、TensorFlow)无法直接加载GGUF文件进行训练。
二、正确训练本地模型的步骤
1. 使用原始PyTorch模型文件(仅说明一下)
(1)模型文件要求:
config.json:模型架构配置文件。
pytorch_model.bin 或 model.safetensors:模型权重文件。
其他依赖文件(如tokenizer.json、special_tokens_map.json)。
(2)加载与训练python示例:
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
# 从本地目录加载模型和分词器
model_path = "./local/deepseek-model"
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 配置训练参数
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
learning_rate=2e-5,
fp16=True
)
# 使用Trainer进行训练(需准备数据集)
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator
)
trainer.train()后续我会写专门的文章来说明如何在本地部署并进行训练。
2. 将GGUF文件转换为PyTorch格式(如必须使用GGUF)
使用llama.cpp或社区工具将GGUF文件转换回PyTorch格式(需确保原始模型支持此操作):
# 示例命令(依赖llama.cpp的convert脚本)
./llama.cpp/convert-gguf-to-pth input.gguf output.pth注意:此操作可能需要模型架构的元信息,部分情况下不可行。
这个我也会在之后写文章单独说明如何实现。
三、基于GGUF的轻量级调优之提示工程(Prompt Engineering)
若必须使用GGUF文件,可通过以下方法间接调整模型行为(非传统训练):
1.构建模板
用llama.cpp加载了GGUF模型之后,通过设计输入文本的结构和内容,引导模型生成更符合预期的输出,无需修改模型权重。以下提供三种提示工程模板:
(1)基础问答优化
目标:提升回答的准确性和详细度。
输入模板:
[INST] <<SYS>>
你是一个专业知识丰富的助手,请以清晰、分点的方式回答问题。
<</SYS>>
问题:量子计算的基本原理是什么? [/INST]输出效果:模型会生成分点解释,而非零散的句子。
(2)角色扮演
目标:让模型模拟特定角色(如教师、医生)。
输入模板:
[INST] <<SYS>>
你是一名资深小学科学教师,请用适合10岁学生理解的语言解释:为什么天空是蓝色的?
<</SYS>>
[/INST]输出效果:回答会使用简单词汇和比喻,适合儿童理解。
(3)分步骤引导
目标:拆解复杂任务为步骤化输出。
输入模板:
[INST] <<SYS>>
请按以下步骤操作:
1. 列出所需材料;
2. 详细说明每一步;
3. 提示注意事项。
<</SYS>>
任务:如何更换自行车轮胎? [/INST]输出效果:模型生成结构化的步骤说明。
2.训练准备
基于以上提示工程模板,用llama.cpp运行GGUF模型,再使用LangChain构建提示模板与多步推理链,最后使用Guidance通过模板强制控制输出格式。
|
工具 |
用途 |
示例代码 |
|
llama.cpp |
本地运行GGUF模型 |
Llama(model_path="model.gguf") |
|
LangChain |
构建提示模板与多步推理链 |
PromptTemplate + LLMChain |
|
Guidance |
通过模板强制控制输出格式 |
约束JSON/列表生成 |
要在Windows系统上对DeepSeek大模型实现微调,先要做以下准备工作,而且先后顺序最好不要错:
(1)安装 Visual Studio Build Tools,勾选 C++桌面开发工具。
(2)安装 Git for Windows,勾选 Add Git to the system PATH,确保命令行可访问 git。
(3)安装 CMake 并确保其路径加入系统环境变量。
(4)安装 Python 3.x 并勾选 Add Python to PATH。
以下是详细步骤:
(1)安装 Visual Studio Build Tools
安装 Visual Studio Build Tools,官网下载地址:https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/。如下图,直接点击下载即可。下载的文件名称为:vs_BuildTools.exe。没有安装C++桌面开发工具可能导致python的依赖项llama-cpp-python安装不成功。
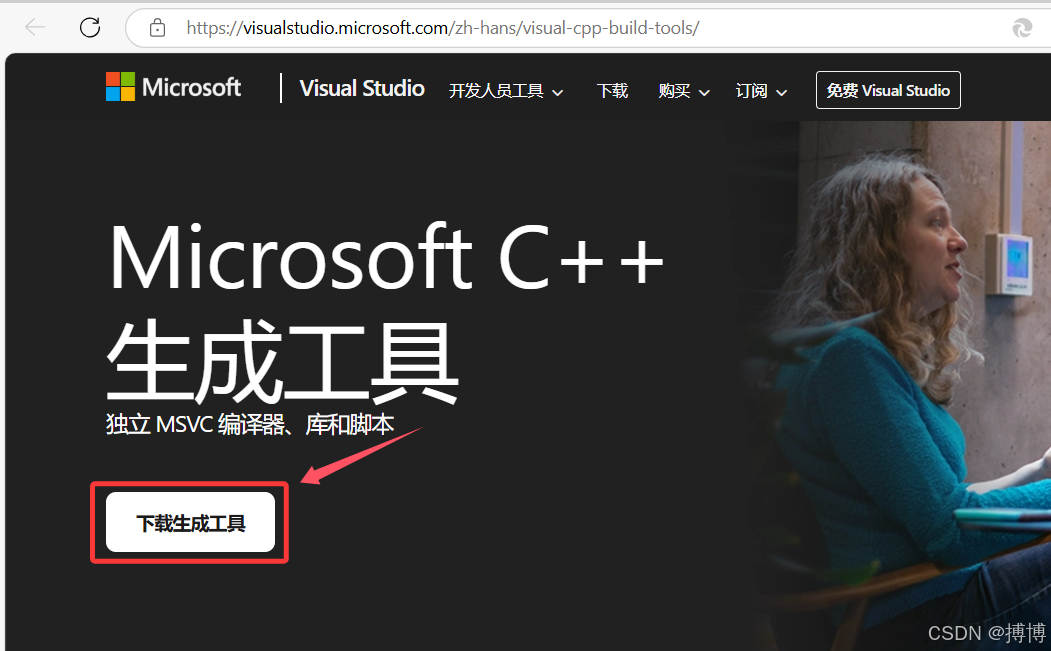
如果无法下载,可以在我的CSDN上下载:https://download.csdn.net/download/lzm12278828/90360334。
安装时,勾选“使用C++的桌面开发”工具。
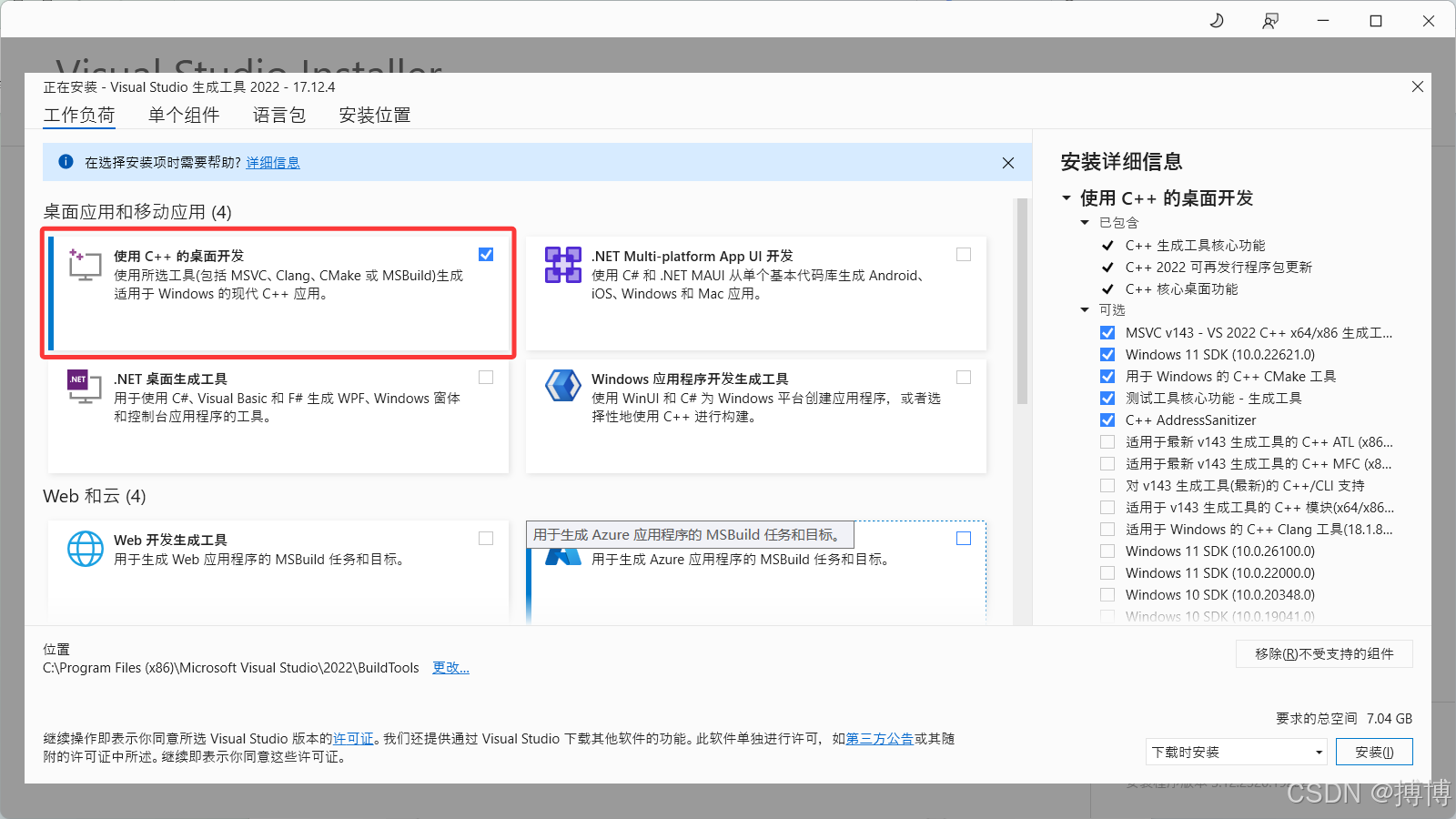
(2)安装Git for Windows
安装Git for Windows,官网下载地址:https://git-scm.com/downloads/win。当前下载的版本是:Git-2.47.1.2-64-bit.exe。
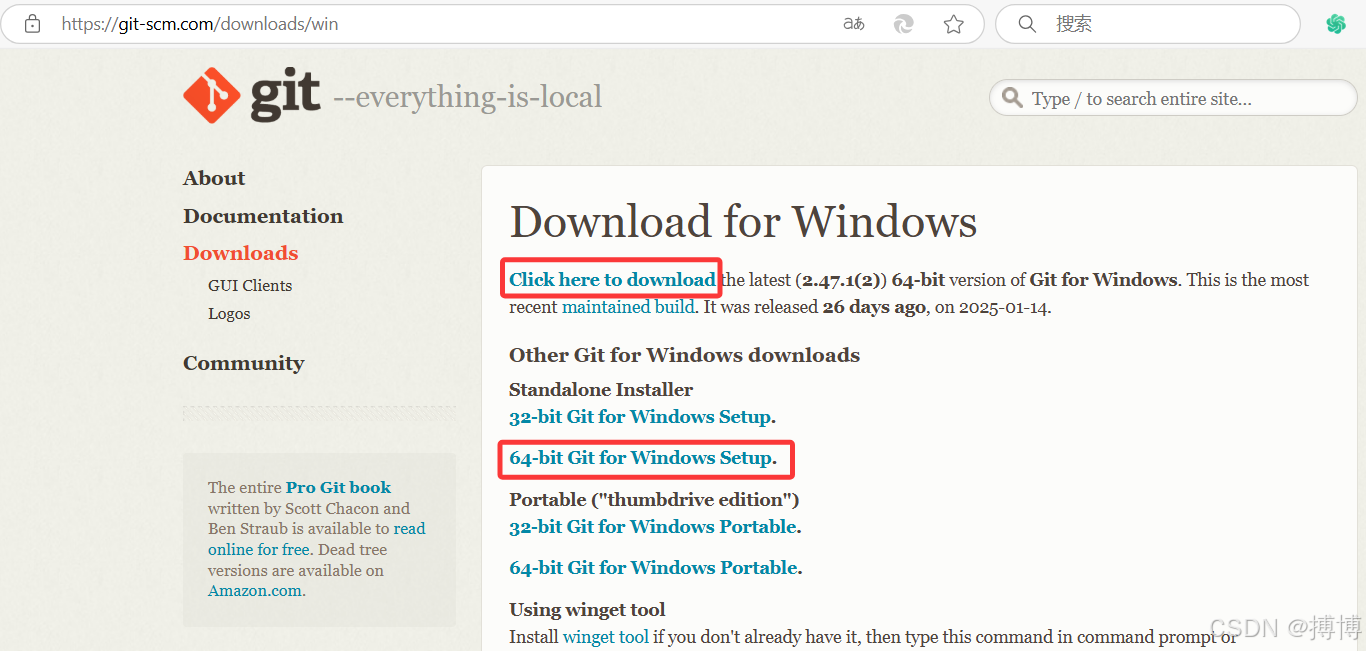
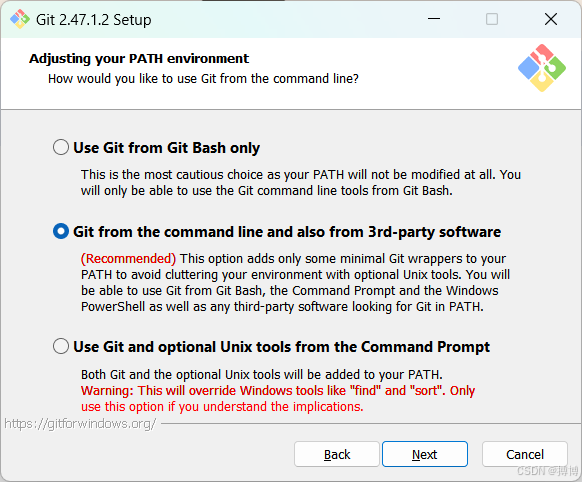
如果无法下载,可以在我的CSDN上下载:https://download.csdn.net/download/lzm12278828/90360343。
要确保Git其路径加入系统环境变量。没有安装Git可能导致python的依赖项llama-cpp-python安装不成功。
(3)安装CMake
安装CMake,官网下载地址:Download CMake。当前下载的版本是:cmake-3.31.5-windows-x86_64.msi。没有安装CMake可能导致python的依赖项llama-cpp-python安装不成功。
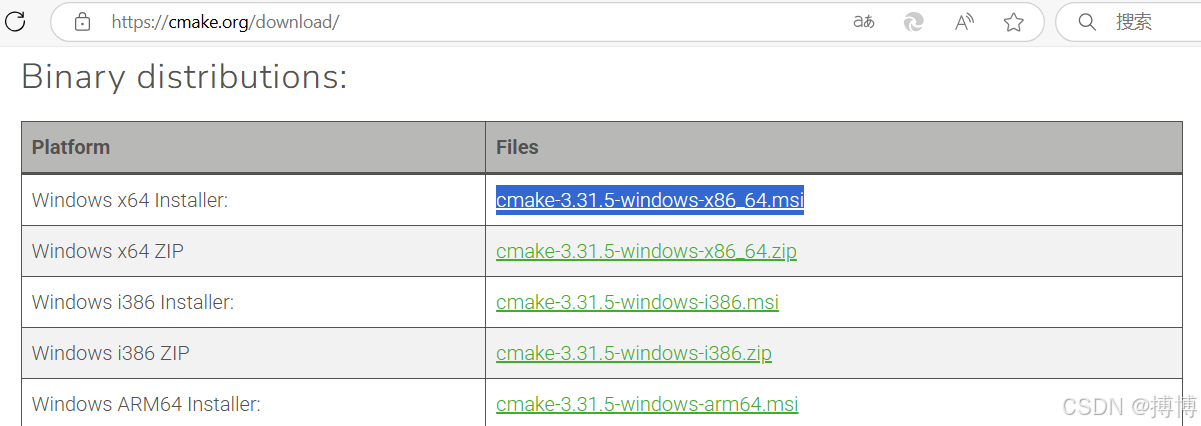
如果无法下载,可以在我的CSDN上下载:https://download.csdn.net/download/lzm12278828/90360341。
安装的过程中,一定要注意,要确保CMake其路径加入系统环境变量。
(4)安装python依赖项
在确保本机上已经安装python的情况下,顺序安装python依赖项:langchain、langchain_community和llama-cpp-python。如果使用清华镜像安装的命令为:pip install --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple llama-cpp-python。确保要全部安装成功。
3.基于LangChain的提示工程训练
接下来就可以基于LangChain的提示工程,可以创建一个python文件,将以下python示例代码全部放进去之后运行:
from langchain.llms import LlamaCpp
from langchain.prompts import PromptTemplate
# 加载GGUF模型
llm = LlamaCpp(
model_path="D:/DeepSeek-R1-Distill-Qwen-1.5B-Q8_0.gguf",
temperature=0.7,
max_tokens=200
)
# 定义提示模板
template = """
[INST] <<SYS>>
你是一个经验丰富的厨师,请用不超过3个步骤回答。
<</SYS>>
问题:如何制作{dish}? [/INST]
"""
prompt = PromptTemplate.from_template(template)
# 运行提示链
chain = prompt | llm
response = chain.invoke({"dish": "提拉米苏"})
print(response)CMD中执行python文件,直接直接写上py,之后可将文件拖进去,回车就可以执行了。
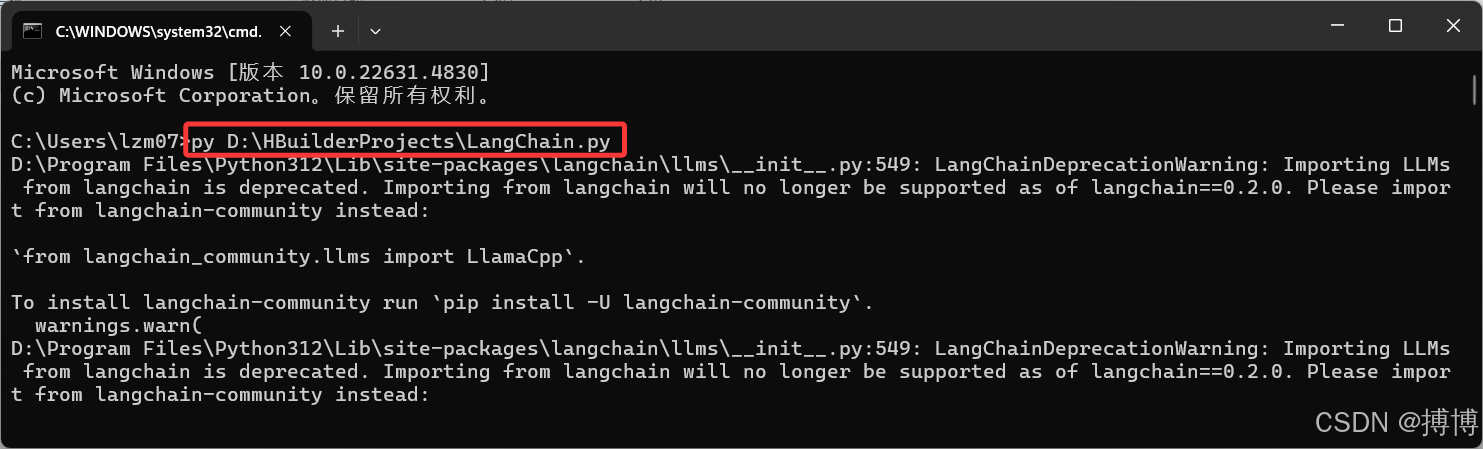
训练结果如下:
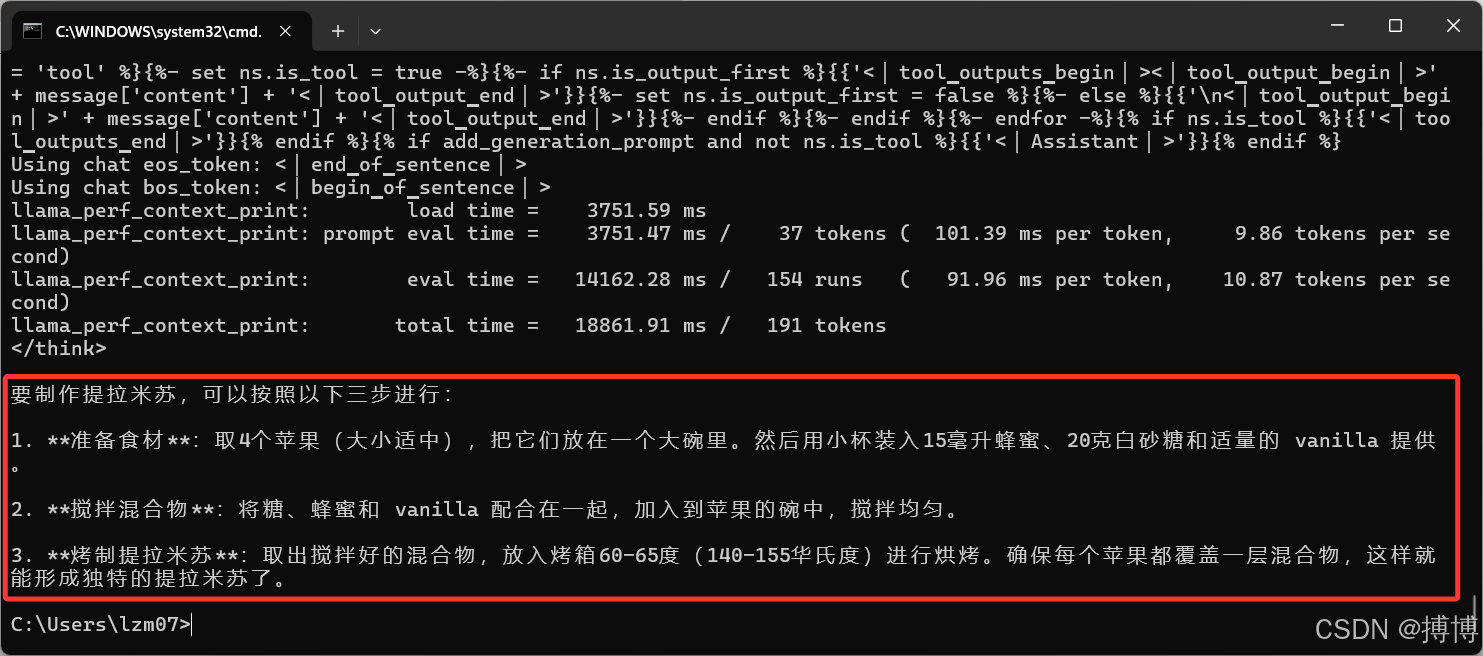
4.测试训练结果
接下来试一下已经训练的模型,先启动自己安装好的模型,进入命令提示符CMD。启动模型:ollama run my_model_name。之后就可以提问了。

之后会显示模型思考过程,再罗列制作步骤。模型回答问题会有条例很多。
5.说明
(1)模型知识截止:GGUF模型的知识无法更新,提示工程仅能优化其已知信息的表达方式。
(2)性能平衡:复杂提示可能增加推理时间,需权衡效果与速度。
(3)伦理风险:避免设计诱导生成有害内容的提示。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)