AI Agent架构优缺点浅析和选型
1. 为什么「架构」比「模型」更重要
2024 年前后,行业焦点是「哪个 LLM 更强」。到 2025–2026 年,共识已经转移:生产级 Agent 的瓶颈,80% 在架构与工程,20% 在模型能力。
一个典型的 Agent 系统至少包含:
| 组件 | 职责 |
|---|---|
|
推理循环 |
决定何时思考、何时行动、何时停止 |
|
工具层 |
API、数据库、代码沙箱、浏览器等外部能力 |
|
记忆层 |
会话上下文、用户偏好、组织知识 |
|
编排层 |
多步流程、分支、重试、人机协同 |
|
治理层 |
权限隔离、审计、护栏、可观测性 |
同一模型,用 ReAct 单循环 vs. Plan-and-Execute vs. 层级多 Agent,在成本、可靠性、可调试性上可能相差一个数量级。因此,先选对架构,再选框架和模型,是当前工程实践的基本顺序。
2. 主流AI Agent架构分类体系
业界已收敛出一套「四象限 + 八模式」分类(参考 Digital Applied 2026 Taxonomy 等综述):
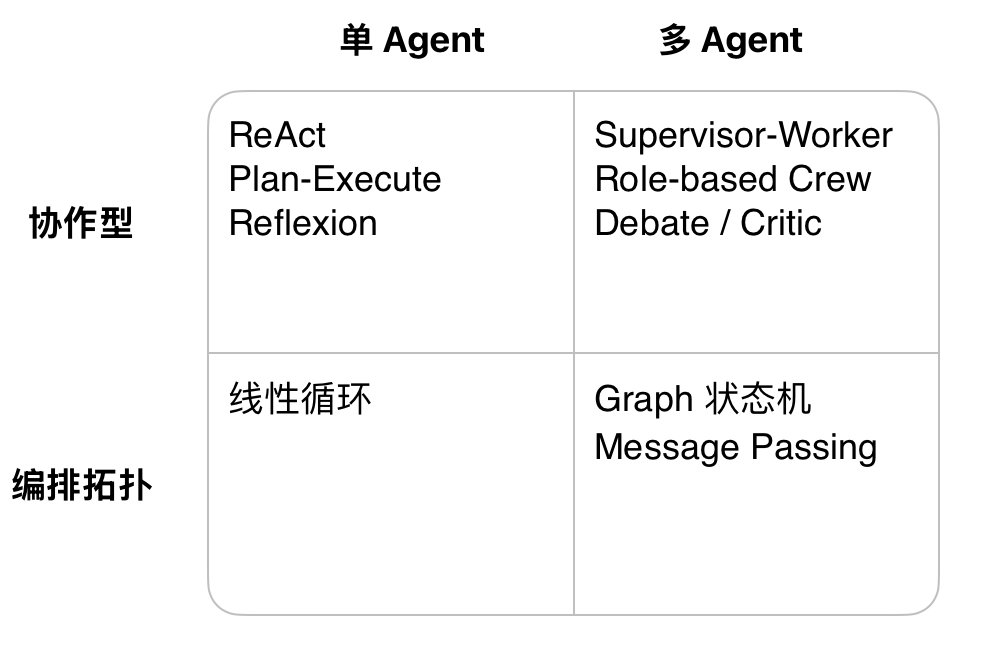
大多数生产系统并非单一模式,而是 2–3 种模式的组合。例如:ReAct + Reflexion + Human-in-the-Loop,或 Supervisor-Worker + Verifier-Critic + Graph 编排。
3. 单 Agent 架构模式(由简到繁)
3.1 ReAct(Reason + Act)—— 默认基线
原理:在 Thought → Action → Observation 的 tight loop 中交替推理与工具调用,根据每步观察动态调整策略。
优点:
- 实现简单,几乎所有框架都内置支持
- 适合开放式、探索型任务(研究、排障、信息搜集)
- 对中途变化的环境适应性强
- Token 开销相对可控(无全局规划阶段)
缺点:
- 存在「局部最优陷阱」:每步决策只看当前状态,难以保证全局最优
- 长链路任务容易「推理漂移」(reasoning drift)
- 复杂依赖关系(并行步骤、条件分支)难以自然表达
- 工具输出过大时迅速耗尽上下文窗口
适用场景:客服问答、代码助手、轻量 research agent、MVP 验证。
不适用:强顺序依赖的多步工作流、需审计的合规流程、步骤数 >15 的复杂任务。
3.2 Plan-and-Execute(规划-执行分离)
原理:Planner 先生成完整多步计划(可为线性列表或 DAG),Executor 逐步执行;Planner 可在执行失败时 replan。
优点:
- 全局视角,减少逐步决策的短视性
- Planner 可用强模型,Executor 可用便宜模型 → 成本优化
- 计划可审计、可人工预审(Human-in-the-Loop 友好)
- DAG 形式支持并行执行独立子任务(2025 年 AAAI 论文 Beyond ReAct 在此方向有 SOTA 结果)
缺点:
- 计划生成后环境变化时,replan 成本高
- 两阶段分离增加延迟(首 token 时间更长)
- 计划质量成为单点瓶颈;计划错误会被放大
- 对需要大量探索的任务不如 ReAct 灵活
适用场景:ETL 流水线、报告生成、多 API 编排、企业审批流、ToolQA 类复杂工具链任务。
变体:
- RP-ReAct(2025 论文):Reasoner-Planner Agent 负责战略级子步骤规划与结果分析,Proxy-Execution Agent 用 ReAct 执行具体工具调用,并采用外部存储管理大工具输出——专为企业私有化部署设计。
3.3 Reflexion(反思/自修正)
原理:Agent 完成任务后,Critic(可以是同一模型或独立模型)评估输出,生成反思文本写入记忆,下次运行时参考历史反思改进。
优点:
- 对重复性失败模式效果显著(如格式错误、遗漏步骤)
- 可与 ReAct 叠加,改动小、收益高
- LangChain 2026 调研显示 32% 从业者将输出质量列为部署首要障碍,Reflexion 直接针对此痛点
缺点:
- 增加 1–2 轮 LLM 调用,延迟和成本上升
- 反思质量依赖 Critic 能力;可能「越反思越偏」
- 需要持久化反思存储
适用场景:代码生成、结构化输出、质量敏感但可接受多轮迭代的任务。
3.4 Tree of Thoughts / Graph Search(搜索型推理)
原理:在决策点展开多条推理路径(树或图),用启发式或 LLM 评分选择最优路径。
优点:
- 理论上可突破单路径 ReAct 的局部最优
- 适合有明确评估标准的任务(数学、逻辑谜题)
缺点:
- 计算开销极大(分支数 × 深度 × LLM 调用)
- 生产环境极少全量部署;多用于研究或高价值单次决策
- 可观测性和调试复杂
适用场景:研究原型、高 stakes 单次决策(如医疗辅助诊断候选方案生成)。
3.5 Agentic RAG(Agent 控制检索)
这是 2025–2026 年知识增强 Agent 的主流方向,与传统固定 RAG 管道有本质区别:
| 模式 | 检索时机 | 灵活性 |
|---|---|---|
|
Naive RAG |
固定:先检索再生成 |
低 |
|
Corrective RAG (CRAG) |
按置信度分级处理 |
中 |
|
Self-RAG |
模型自决是否检索 |
中高 |
|
Agentic RAG |
Agent 决定何时、如何、检索几次 |
高 |
Agentic RAG 子模式:
- RAG as Tool:检索器作为一个 tool,Agent 按需调用
- Multi-step RAG:多轮检索-推理-再检索
- Tool RAG:当工具数 >50 时,先语义检索相关工具子集再注入 context(解决 tool selection 退化问题)
- Graph RAG:结合知识图谱做多跳推理
优点:动态适应查询复杂度,支持多源知识融合。
缺点:链路更长,幻觉与错误检索的复合风险更高,需要 CRAG/Self-RAG 等纠错机制。
4. 多 Agent 架构模式
4.1 Supervisor-Worker(监督者-工作者)
原理:Supervisor Agent 负责任务分解、路由、质量门控、结果合成;Worker Agent 专注领域执行,通常工具集隔离。
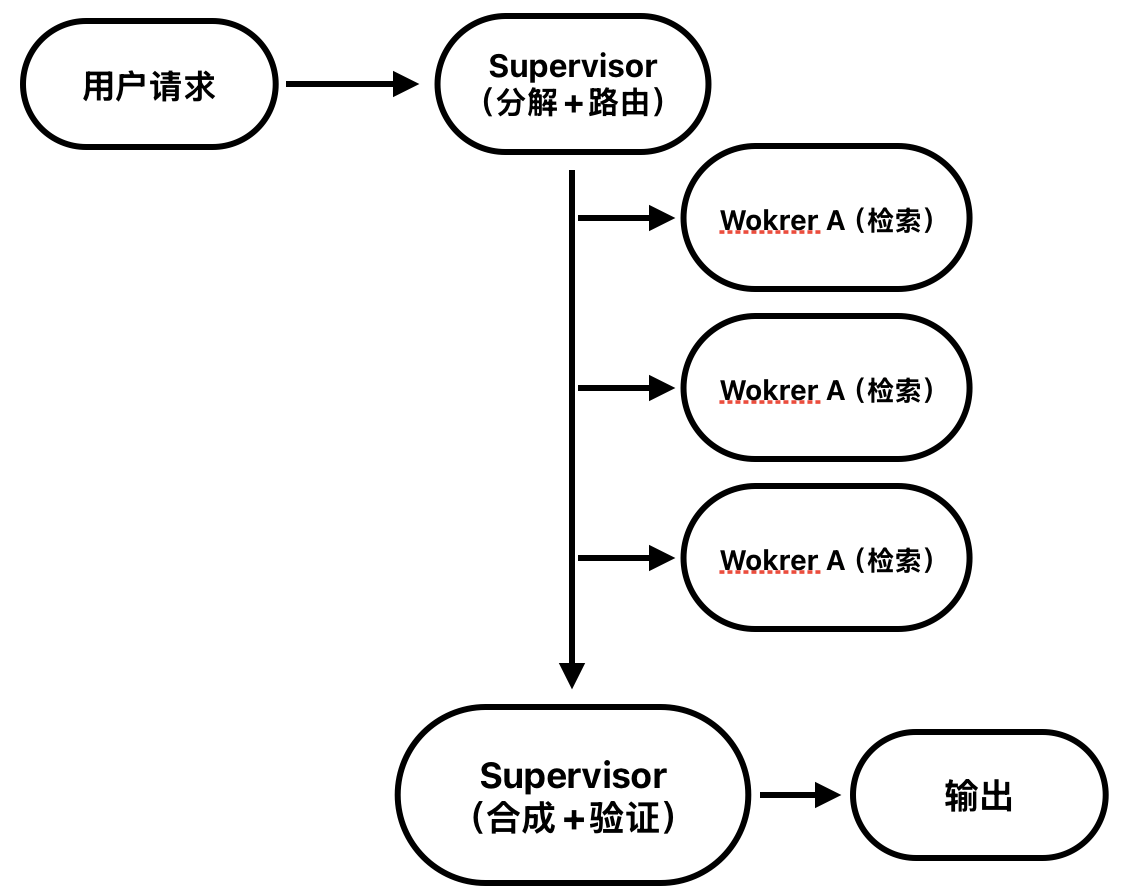
优点:
- 职责清晰,可测试、可审计
- 支持并行 scatter-gather
- 工具权限可按角色隔离(Governed Autonomy 架构核心)
- 符合企业「审批链」心智模型
缺点:
- Supervisor 是单点瓶颈与单点故障
- 协调开销(Agent 间 context 传递)显著
- 需要设计清晰的 Agent 间契约(输入/输出 schema)
- 调试需还原跨 Agent 因果链
适用场景:贷款审批、合规审查、复杂代码生成(architect + coder + reviewer)、Databricks Agent Bricks / Google ADK 等企业方案。
规模建议:Worker 数量控制在 3–7 个;超过 7 个考虑嵌套层级 Supervisor。
4.2 Role-based Crew(角色协作,CrewAI 范式)
原理:定义 Agent 角色(goal、backstory、tools),通过 Task 链或 Flow 事件驱动协作;Agent 不直接互发消息,而是传递 Task 输出。
优点:
- 心智模型直观(「组建一个团队」)
- 快速原型,CrewAI 内置 100+ 工具
- Pydantic 结构化输出验证
- Flows 提供事件驱动控制,弥补纯 Crew 的线性局限
缺点:
- 无原生持久化/checkpoint——步骤 7/10 失败需从头开始
- 长时运行工作流运维成本高
- 可观测性弱于 LangGraph + LangSmith
- 已从 LangChain 解耦,生态独立
适用场景:内容营销流水线、市场调研、快速 PoC、角色分工明确的短流程。
4.3 Debate / Critic-Verifier(辩论与验证)
原理:多个 Agent 对同一问题提出方案并互相 critique,或由独立 Verifier 打分/拒绝。
优点:
- 高 stakes 场景下显著降低幻觉和逻辑错误
- 输出可解释性更强
缺点:
- Token 成本成倍增长
- 可能陷入「无效辩论循环」
- 需要终止条件设计
适用场景:法律合同审查、医疗 second opinion、安全关键代码 review。
4.4 Message Passing / Group Chat(AutoGen 范式)
原理:每个 Agent 是独立 Actor,通过异步消息协调;GroupChat 选择下一发言者。
优点:
- 组合性极强,可动态增减 Agent
- 适合对话式协作、研究实验
- AutoGen v0.4 基于 Actor 模型,支持 .NET + Python(AG2 社区 fork)
缺点:
- 无 Agent 拥有全局视图,调试 = 读消息日志
- AutoGen 官方已进入 maintenance mode,Microsoft 推荐迁移至 Microsoft Agent Framework (MAF)
- 持久化、HITL、fault recovery 需自建
适用场景:学术研究、对话式 brainstorming;新生产项目优先考虑 MAF 或 LangGraph。
5. 编排拓扑:三种底层协调范式
这是选框架时最应关注的维度——不是「哪个框架 star 多」,而是「你的失败模式能否被该拓扑调试」。
| 维度 | Graph(LangGraph) | Crew(CrewAI) | Message(AutoGen/MAF) |
|---|---|---|---|
|
状态模型 |
Typed StateGraph + reducer |
Pydantic BaseModel + Flow |
Actor 私有状态 + 消息 |
|
持久化 |
Postgres/SQLite checkpoint |
无自动 resume |
手动 save/load |
|
Fault Recovery |
从 checkpoint 自动恢复 |
从头重跑 |
需自建 |
|
HITL |
|
基础支持 |
UserProxy / MAF approval gates |
|
Time Travel |
支持 replay 任意 checkpoint |
不支持 |
不支持 |
|
调试方式 |
看状态图 + trace |
看 process events |
读消息日志 |
|
学习曲线 |
中高 |
低 |
中 |
LangGraph 已成为长时运行、需审计、需 HITL 的生产首选(Klarna、Uber、Replit 等案例)。其本质是 有向图状态机:Node = 计算单元,Edge = 条件路由,Checkpoint = 持久化快照。
Microsoft Agent Framework 是 2025–2026 年 Azure 生态的统一答案,合并 AutoGen Actor 原语 + Semantic Kernel 的企业治理能力,适合 .NET/Python 混合栈。
OpenAI Agents SDK(Swarm 的生产继任者)强调 handoffs(Agent 间委托)、guardrails、tracing 作为一等概念,与 OpenAI 模型和 Built-in Tools(web search、file search、computer use)深度集成。
6. 横切能力层
6.1 MCP(Model Context Protocol)
Anthropic 开源、现已成为工具与数据接入的事实标准。Host 应用通过 MCP Client 连接 MCP Server,Server 暴露 Tools、Resources、Prompts 三类原语。
2026-07-28 RC 版重大变化:
- 无状态核心:移除 session handshake,每请求自描述
- Tasks 扩展:长时任务通过 task handle 异步驱动
- MCP Apps:UI 组件与 Agent 交互
架构意义:Agent 框架(LangGraph / OpenAI SDK / CrewAI)负责「怎么编排」,MCP 负责「怎么连外部世界」。二者互补,不应混为一谈。
6.2 记忆分层
| 类型 | 内容 | 典型实现 |
|---|---|---|
|
Working Memory |
当前会话 in-context |
Context window |
|
Episodic Memory |
历史交互记录 |
Vector DB / Mem0 |
|
Semantic Memory |
事实与知识 |
RAG / Knowledge Graph |
|
Procedural Memory |
工具使用启发式 |
System prompt / LoRA |
Mem0 适合个性化;Letta(原 MemGPT) 适合自编辑记忆块;Zep/Graphiti 适合时序推理;LangMem 适合 LangGraph 生态。
关键原则:Memory ≠ RAG。Memory 是「这个用户/session 发生了什么」,RAG 是「组织知道什么」。
6.3 Human-in-the-Loop(HITL)
生产 Agent 几乎都需要 HITL,但实现深度差异巨大:
- LangGraph
interrupt():执行暂停 → checkpoint → 人工输入 → 精确恢复 - CrewAI:基础支持,无原生 resume
- OpenAI Agents SDK:guardrails 可触发人工审核
合规、金融、医疗场景,HITL 不是可选项。
6.4 可观测性
2026 年 OpenTelemetry 成为 Agent trace 的默认格式。必备能力:
- 每次 LLM 调用、tool call、retrieval 的可追溯 span
- 成本归因(按 Agent / 按用户 / 按任务)
- 评估闭环(LangSmith、Braintrust、Future AGI 等)
没有 observability 的 Agent,等于「黑盒自动化」——无法上线。
7. 框架选型对比
| 框架 | 架构范式 | 最佳场景 | 主要风险 |
|---|---|---|---|
|
LangGraph |
Graph 状态机 |
长时工作流、HITL、生产 SLA |
学习曲线陡 |
|
CrewAI |
Role + Flow |
快速原型、角色分工短流程 |
无 checkpoint,长流程脆弱 |
|
OpenAI Agents SDK |
Handoff 委托 |
OpenAI 栈、Built-in Tools |
厂商绑定 |
|
Microsoft Agent Framework |
Actor + Workflow |
Azure/.NET 企业栈 |
生态较新 |
|
AutoGen / AG2 |
Group Chat |
研究、遗留项目 |
官方 maintenance |
|
Google ADK |
层级 Agent |
GCP 生态 |
相对封闭 |
|
Dify / Coze 等低代码 |
可视化编排 |
非工程团队、简单 Bot |
复杂逻辑受限 |
8. 选型决策
三条铁律(2026 行业共识):
-
默认单 Agent:多 Agent 的协调 tax 常被低估。LangChain 2026 报告与多篇生产复盘均指出,多数「多 Agent 系统」用单 Agent + 更好 prompt/tool 即可达到同等效果。
-
先测量失败模式,再选架构:是 planning 瓶颈?→ Plan-and-Execute。是重复性错误?→ Reflexion。是输出质量?→ Verifier。是 context 溢出?→ 外部记忆 + Tool output 压缩。
-
可观测性先于复杂度:每增加一个 Agent 或一层编排,debug 难度指数上升。没有 trace 的多 Agent = 技术债。
9. 按场景的具体推荐
9.1 企业内部知识助手
- 架构:ReAct + RAG as Tool + CRAG 纠错
- 框架:LangGraph(如需 HITL 审批)或 Dify(快速上线)
- 工具接入:MCP Server 连接内部 Wiki/Confluence/数据库
- 记忆:Mem0 或 LangMem 做用户级个性化
9.2 复杂 API 编排(如「查库存 → 算运费 → 下单 → 发通知」)
- 架构:Plan-and-Execute(DAG 计划)+ 结构化 tool schema
- 框架:LangGraph(checkpoint 必须)
- 模型策略:Planner 用强推理模型,Executor 用便宜模型
9.3 代码生成 Agent
- 架构:ReAct + Reflexion + Sandbox 执行
- 框架:LangGraph 或 Cursor Agent 类自建循环
- 关键:代码执行沙箱(E2B、Modal、Daytona)+ 测试工具作为 verifier
9.4 金融/合规审查
- 架构:Supervisor-Worker + Critic-Verifier + HITL interrupt
- 框架:LangGraph(原生 interrupt + audit trail)
- 治理:Role-based tool isolation,Worker 不可越权调用
9.5 快速 MVP / Demo
- 架构:ReAct 单 Agent 或 CrewAI 3 角色 Crew
- 框架:CrewAI 或 OpenAI Agents SDK
- 注意:PoC 架构 ≠ 生产架构,提前规划迁移路径
9.6 研究型 / 探索型 Agent
- 架构:ReAct + Agentic RAG + 多源 Tool
- 框架:LangGraph(灵活分支)或 OpenAI Agents SDK(Built-in web search)
- 可选:ToT 用于高价值决策点
10. 2026 趋势与反模式
趋势
- Planning 与 Execution 解耦成为复杂任务主流(RP-ReAct、Planner-centric DAG)
- MCP 成为工具层标准,框架层竞争加剧
- OpenTelemetry trace 成为 Agent 可观测性基线
- Memory 产品化(Mem0、Letta、Zep 独立成层)
- Computer Use Agent(浏览器/桌面自动化)与 MCP 工具链融合
- Eval-driven development:先定义 eval set,再迭代架构
反模式(务必避免)
- ❌ 一上来就 Multi-Agent Swarm:通信开销和 debug 噩梦
- ❌ 把 RAG 当 Memory 混用:导致 context 污染和检索噪声
- ❌ 工具列表无限膨胀:>30 工具应引入 Tool RAG
- ❌ 无 checkpoint 的长工作流:一次失败全部重来
- ❌ 无 eval 的架构迭代:无法判断是模型问题还是架构问题
- ❌ 忽略 context 经济学:大 tool output 不压缩,再强的模型也会退化
11. 总结
2026 年的 AI Agent 架构已从「实验玩具」进入「工程学科」阶段。核心结论:
| 层次 | 推荐默认 | 升级路径 |
|---|---|---|
|
推理循环 |
ReAct |
→ Plan-and-Execute → DAG Planner |
|
质量保障 |
结构化输出 schema |
→ Reflexion → Critic-Verifier |
|
知识 |
RAG as Tool |
→ Agentic RAG + CRAG |
|
多 Agent |
先不要 |
→ Supervisor-Worker → 嵌套层级 |
|
编排 |
简单循环 |
→ LangGraph 状态机 |
|
工具接入 |
直接 API |
→ MCP Server |
|
治理 |
Prompt 约束 |
→ HITL + OTel + Eval |
没有「最好」的架构,只有「最匹配你失败模式」的架构。 从 ReAct 单 Agent 基线出发,用 eval 和 trace 定位瓶颈,按需叠加 Reflexion、Plan-and-Execute、Supervisor-Worker。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)