跟踪资金流向:使用 ES|QL 和跨集群搜索追踪洗钱网络
作者:来自 Elastic Jon Williams
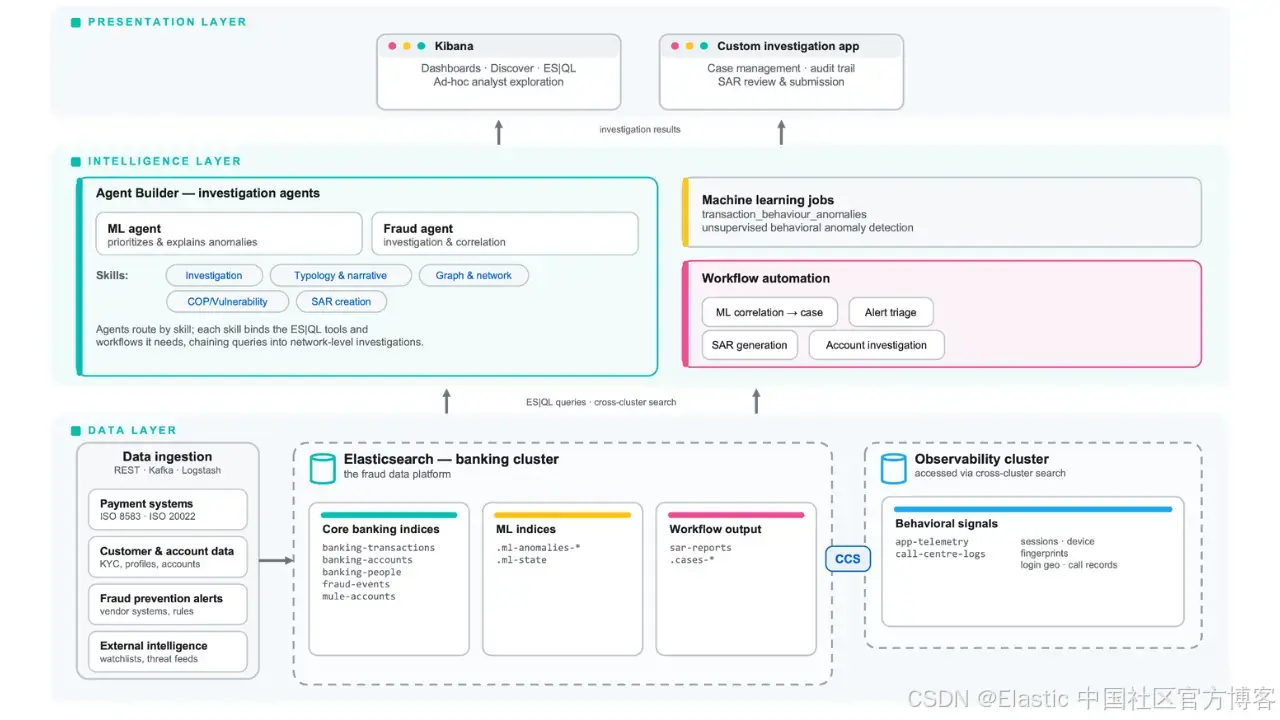
支持 Mule 检测和洗钱网络追踪的数据模型、跨集群架构以及五个 ES|QL 查询,这些都构建在大多数金融机构已经部署的基础设施之上。
亲自动手体验 Elasticsearch:深入了解我们在 Elasticsearch Labs 仓库中的示例 Notebooks,开始免费的云试用,或者立即在你的本地机器上试用 Elastic。
五个 ES|QL 查询可以在整个账户组合中标记 money mule(资金中转账户),从单个已报告案例向下游追踪洗钱网络,并在无需移动任何数据的情况下,将可疑支付与位于独立集群中的行为信号进行关联分析。本文介绍了我们基于 Elasticsearch 构建的欺诈调查平台背后的架构、数据模型以及 ES|QL 查询。同时还介绍了分层存储和 logsdb 索引模式如何将满足七年监管留存要求的存储成本最高降低 65%。这是三篇系列文章中的第二篇;第一篇介绍了金融服务行业在金融犯罪调查中的调查缺口,第三篇将介绍构建在该平台之上的 AI agents。
欺诈调查平台是如何构建的
我们在最近一次英国客户技术交流会上展示了这个平台。值得强调的一点是:Elasticsearch、Agent Builder、ES|QL 和 Kibana 都是许多金融机构已经在运行的组件,因此这里描述的调查能力可以基于现有基础设施进行组装,而不是作为一套独立的新技术栈来采购。
基于 Elasticsearch 的欺诈调查平台架构
该平台采用分层架构,在数据层、智能层和展示层之间实现清晰分离。
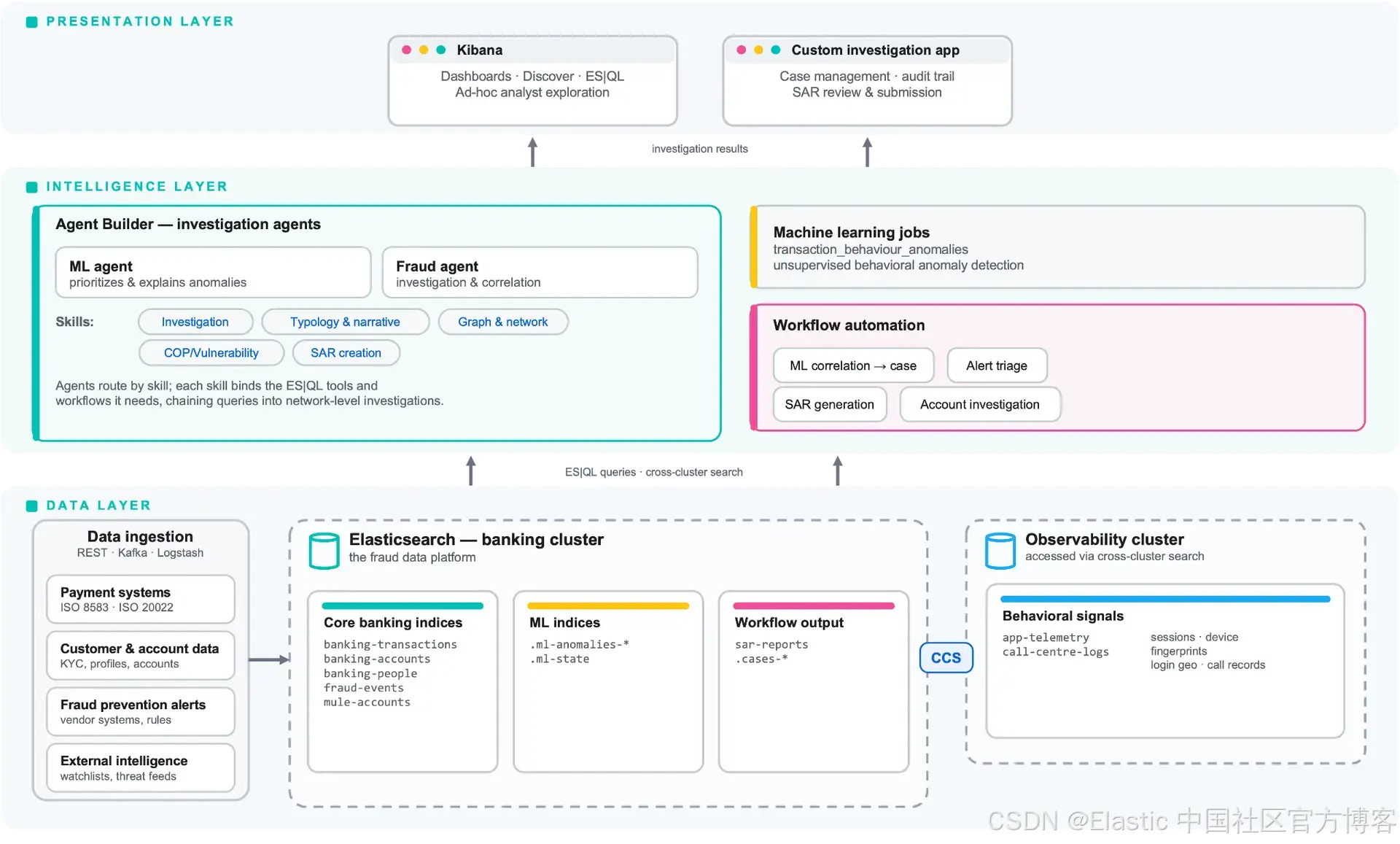
数据层:两个集群,一次搜索
欺诈调查数据很少只存在于一个地方。交易记录、客户资料以及账户元数据通常位于由支付或核心银行团队管理的银行数据集群中。与此同时,应用遥测数据(移动应用会话日志、网上银行事件、设备指纹以及呼叫中心交互记录)往往位于由工程或运维团队管理的可观测性集群中。
跨集群搜索(Cross-cluster search, CCS) 允许每个团队继续拥有并管理自己的数据。同时,调查人员可以在一次请求中跨两个集群进行查询,无需迁移到单一集群,也不需要单独的聚合层。银行集群保存交易数据;可观测性集群保存行为信号。调查人员看到的是统一的结果集,而两个团队都无需放弃对数据的控制权。
跨集群搜索 不仅仅是一个技术上的便利。它解决了我们在第一部分中描述的组织内部障碍——不同团队拥有不同数据、对查询影响生产系统的担忧,以及基于角色的访问控制(这些控制本身是有充分理由的)。CCS 在尊重这些限制的同时,仍然允许跨域调查。
智能层:Agent Builder、skills 和 workflows
智能层是 AI agents、ES|QL 查询、机器学习任务以及工作流自动化汇聚的地方。在 Elastic Agent Builder 中,agents 会将请求路由到合适的 skill,而每个 skill 会绑定其所需的 ES|QL 工具和 workflows;例如 Investigation、Typology & Narrative、Graph & Network、COP/Vulnerability 以及 SAR Creation。第三部分将详细介绍 agent 和 skill 的架构。在本文中,我们聚焦它们所依赖的数据与查询基础。
展示层:Kibana 与自定义应用
该平台包含一个自定义调查界面,用于与 agent 服务和 Elasticsearch API 通信。但同一份数据也可以在 Kibana 中用于临时的、分析师驱动的探索。这种双界面设计是有意为之:结构化调查流程用于提升速度,而 Kibana 用于回答工作流未设计覆盖的问题。
Kibana 仪表板提供运营视图(告警队列、案件数量趋势以及 mule 账户热力图),而 Discover 和 Kibana 控制台中的 ES|QL 则让分析师能够自由运行探索性查询,而无需等待他人构建新的仪表板。
关于可用性说明:本文中的数据模型和 ES|QL 查询可在任何 Elasticsearch 部署上运行,但该架构中的两个能力有特定要求:
-
带 ES|QL 的跨集群搜索 在 Elasticsearch 8.19 和 9.1 中通常可用;需要两个集群都具备兼容订阅(见 跨集群搜索 和 订阅)。
-
Elastic Agent Builder 在 Elastic Cloud Serverless 上以及云托管和自管理部署的 Enterprise 等级中可用(见 Agent Builder 正式发布)。
用于资金中转账户(money mule)检测的数据模型:交易、账户与行为信号
数据模型是一切的基础。欺诈调查是一个跨领域问题,这意味着数据模型必须能够容纳不同的文档(document)类型,同时仍然支持快速、灵活的查询。
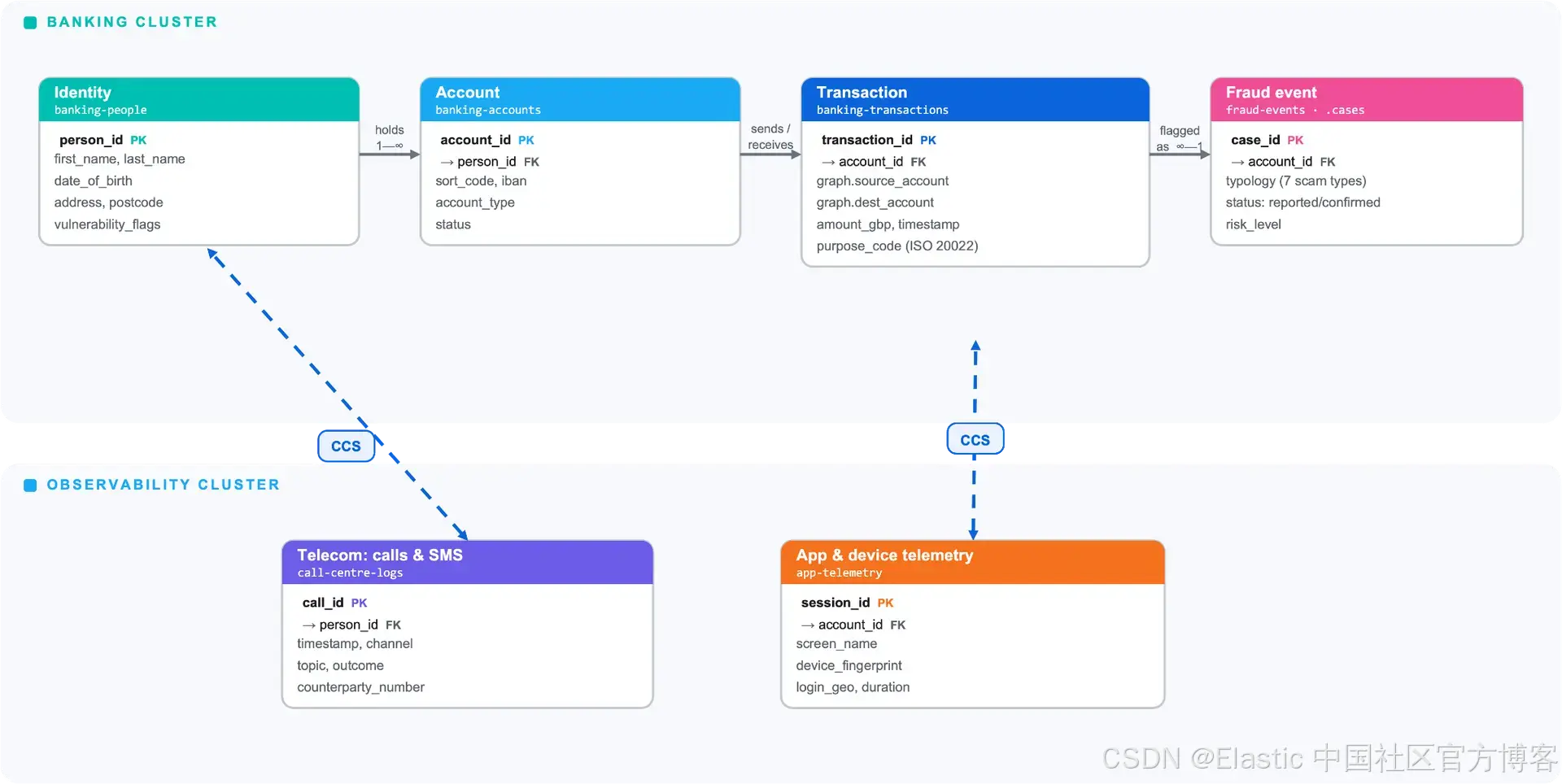
银行业交易
核心索引保存支付交易记录。每一条文档代表一次支付事件,包含相关方、金额、时间以及元数据等字段。
// Index: banking-transactions
{
"transaction_id": "a76fe1f9-c403-4855-bc61-22b0db37fc29",
"timestamp": "2025-01-20T23:47:12.341Z",
"account_id": "3f7932e3-9e69-4d69-aef5-41f281b3969b",
"amount_gbp": -15000,
"currency": "GBP",
"is_credit": false,
"is_debit": true,
"channel": "mobile_app",
"transaction_type": "faster_payment",
"payment_code": "XF",
"purpose_code": "INVESTMENT",
"description": "Investment deposit",
"counterparty_name": "CryptoTrade Ltd",
"counterparty_account": "94738291",
"counterparty_sort_code": "20-45-67",
"merchant_category": "6211",
"geo_location": "POINT (-0.1616 51.5296)",
"graph.source_account": "47-83-82_10985194",
"graph.source_bank": "Bank4",
"graph.dest_account": "20-45-67_94738291",
"graph.dest_bank": "Bank2",
"graph.payment_flow": "outbound",
"graph.amount_band": "large",
...
}有几个要点值得注意。
-
purpose_code和merchant_category字段在可用时包含来自 ISO 20022 的增强信息,使基于规则的系统可以与 AI agent 一起使用这些信号。 -
负数金额表示借记,同时通过
is_credit和is_debit flags进行快速过滤。 -
geo_location支持对交易模式进行空间分析。
在具备 ISO 20022 增强数据的情况下,付款用途代码、法人实体标识符(Legal Entity Identifiers)以及结构化汇款信息提供了额外信号。Elasticsearch 的无模式特性意味着我们可以将 ISO 8583 等传统格式与 ISO 20022 增强格式一起摄入到同一个索引中,而不需要在前期定义严格的固定 schema。
账户与人员
客户数据通常托管在 CDP(Customer Data Platform)中,但为了简化架构,我们将其放在同一个集群中。账户级数据存放在 banking-accounts 索引中,而客户身份与画像数据存放在 banking-people 中。这种拆分是有意设计的:调查人员在分析交易模式时无需访问个人身份信息,同时 RBAC(基于角色的访问控制)可以限制只有授权角色才能访问 PII 数据。
// Index: banking-accounts
{
"account_id": "7179a225-19b5-4b24-9aae-b50ad43cb15c",
"account_number": "96435152",
"account_type": "savings_account",
"account_status": "active",
"person_id": "79393ff4-3a32-4bae-9021-4566e6b5008c",
"bank_name": "Bank1",
"sort_code": "20-30-79",
"iban": "GB62BANK20307996435152",
"balance_gbp": 39920.61,
"currency": "GBP",
"opened_date": "2017-04-13T00:00:00.000Z",
...
}person_id 字段链接到 banking-people 索引,该索引保存客户身份、地址、信用记录、就业信息以及弱势标记(这些内容被单独存放在一个具有独立访问控制的索引中)。一个简化示例如下:
// Index: banking-people
{
"person_id": "4233d7fd-29aa-439d-8cc8-a07f1933128f",
"first_name": "Rebecca",
"last_name": "Brennan",
"date_of_birth": "1979-01-19T00:00:00.000Z",
"age": 47,
"address_line1": "244 Manor Terrace",
"city": "Blackpool",
"postcode": "FY1 6AN",
"location_geo": "POINT (-3.050282 53.836826)",
"credit_history.credit_score": 729,
"credit_history.vulnerability_flag": "socially_isolated",
"credit_history.total_debt_gbp": 6548.49,
"accounts": [
{ "account_id": "528a...", "account_number": "32540475",
"sort_code": "22-79-61", "balance_gbp": 3242.93 },
{ "account_id": "692e...", "account_number": "39261497",
"sort_code": "24-53-93", "balance_gbp": 2175.45 }
],
...
}应用遥测数据(可观测性集群)
可观测性集群保存来自银行自身移动端与网上银行应用的会话级遥测数据。这不是浏览历史或外部网站数据,而是来自机构自身服务的遥测信息,支付服务提供商对这些数据拥有合法访问权限。
// Index: app-telemetry (observability cluster, accessed via CCS)
{
"session_id": "sess-9f8e7d",
"customer_id": "C847392",
"timestamp": "2025-01-20T21:32:00Z",
"app_platform": "ios",
"event_type": "screen_view",
"screen_name": "payment_limits",
"session_duration_seconds": 8100,
"device_fingerprint": "fp-abc123",
"ip_address": "82.132.xxx.xxx",
"geo_city": "London",
...
}会话遥测数据揭示了仅靠交易数据无法发现的行为模式:客户在付款前在应用中停留的时间、他们访问的页面(尤其是支付限额页面)、设备指纹是否与其常用设备匹配,以及登录位置是否与历史记录一致。
呼叫中心日志
客户服务交互会以结构化元数据方式被索引,从而可以将服务电话与后续交易进行关联分析。
// Index: call-centre-logs
{
"call_id": "CALL-29481",
"customer_id": "C847392",
"timestamp": "2025-01-17T14:22:00Z",
"duration_seconds": 420,
"topic": "payment_limit_increase",
"outcome": "limit_raised",
...
}如何使用 ES|QL 检测资金中转账户(money mule)?
ES|QL 是 Elastic 的管道式查询语言,专为跨大规模数据集的探索性分析而设计。在我们的平台中,ES|QL 查询有两个作用:一方面,它们是 agent skills 可以以编程方式调用的工具;另一方面,分析师也可以在 Kibana 中直接使用它们进行临时探索。
下面是驱动该平台的关键查询。
mule 检测:识别资金 “直进直出” 的账户
这是平台中最重要的查询。它会检查每一个账户,计算资金流入与流出的总量,衡量资金停留的时间,并标记那些资金快速 “流入即流出” 的账户。
FROM banking-transactions
| STATS
incoming = SUM(CASE(is_credit == true, amount_gbp, 0)),
outgoing = SUM(CASE(is_debit == true, ABS(amount_gbp), 0)),
transaction_count = COUNT(*),
first_txn = MIN(timestamp),
last_txn = MAX(timestamp)
BY account_id
| EVAL
turnover_ratio = TO_DOUBLE(outgoing) / GREATEST(TO_DOUBLE(incoming), 1.0),
time_span_ms = TO_LONG(last_txn) - TO_LONG(first_txn),
days_active = time_span_ms / 86400000.0,
txn_frequency = TO_DOUBLE(transaction_count) / GREATEST(days_active, 1.0)
| WHERE incoming > 5000
AND turnover_ratio > 0.75
AND days_active < 180
| SORT turnover_ratio DESC, incoming DESC
| LIMIT 50示例输出:
account_id incoming outgoing txns turnover_ratio days_active
20-45-67_94738291 247,000 239,000 31 0.968 42.0
30-91-22_50271841 87,000 84,200 18 0.968 27.0
04-17-55_61398002 54,000 52,400 13 0.970 22.0
11-38-09_77450513 43,000 41,500 11 0.965 18.0
(top 4 of 50 results)turnover_ratio 接近 1.0 表示几乎所有流入资金都立刻流出;这是资金中转账户(mule account)的典型特征。days_active 过滤条件用于聚焦新开账户,而流入金额阈值用于过滤噪声数据。最终输出是按风险排序的可疑账户列表。
对可疑账户建模:谁在向其转账?
一旦某个账户被标记,下一步就是分析其资金流入模式。该查询会识别所有向指定目标账户转账的账户,并计算每个来源账户的总风险暴露。
FROM banking-transactions
| WHERE graph.dest_account == "20-45-67_94738291"
AND is_debit == true
| STATS
total_sent = SUM(ABS(amount_gbp)),
tx_count = COUNT(*),
first_payment = MIN(timestamp),
last_payment = MAX(timestamp)
BY graph.source_account, graph.source_bank
| SORT total_sent DESC示例输出:
graph.source_account graph.source_bank total_sent tx_count
20-30-79_88142251 Bank1 15,000 1
04-22-13_67391044 Bank3 14,200 1
11-90-56_20517783 Bank2 12,800 2
... ... ... ...
23 source accounts · £247,000 total这会展示所有源账户的完整列表——潜在的受害者。当某个账户在六周内出现 23 个不同来源,并且所有来源都向同一个目标账户发送大额资金时,这种模式就非常清晰。
向下游追踪网络
mule 网络通常是分层结构的。为了追踪资金在主 mule 账户之后的去向,我们将查询反转,查看出账流动:
FROM banking-transactions
| WHERE graph.source_account == "20-45-67_94738291"
AND graph.payment_flow == "outbound"
| STATS
forwarded = SUM(ABS(amount_gbp)),
tx_count = COUNT(*),
first_forward = MIN(timestamp),
last_forward = MAX(timestamp)
BY graph.dest_account, graph.dest_bank
| SORT forwarded DESC示例输出:
graph.dest_account graph.dest_bank forwarded tx_count
30-91-22_50271841 Bank4 112,400 8
04-17-55_61398002 Bank2 78,100 6
11-38-09_77450513 Bank5 48,500 4
3 downstream accounts · £239,000 forwardedagent 将这些查询串联起来:先对主 mule 的下游账户进行画像,然后对每一个账户重复运行同样的 mule 检测查询,以判断它们是否也属于洗钱网络的一部分。这种递归模式能够将单一的举报案例扩展为完整的网络级调查。
客户行为基线
为了判断某一笔交易对特定客户是否异常,我们会计算其历史行为基线,并进行对比:
FROM banking-transactions
| WHERE account_id == "3f7932e3-9e69-4d69-aef5-41f281b3969b"
AND is_debit == true
| STATS
avg_amount = AVG(ABS(amount_gbp)),
max_amount = MAX(ABS(amount_gbp)),
tx_count = COUNT(*),
first_txn = MIN(timestamp),
last_txn = MAX(timestamp)
| EVAL
flagged_amount = 15000,
amount_ratio = ROUND(flagged_amount / GREATEST(avg_amount, 1.0), 1),
time_span_ms = TO_LONG(last_txn) - TO_LONG(first_txn),
days_active = time_span_ms / 86400000.0amount_ratio 为 12 表示该被标记交易金额是客户典型支付金额的 12 倍。agent 会结合该指标,以及时间和渠道数据,共同作为欺诈风险评估的输入。
跨集群行为上下文
跨集群搜索允许单个 ES|QL 查询从可观测性集群中拉取数据。下面的查询会获取在可疑交易发生前数小时内,该客户的应用遥测数据:
FROM observability:app-telemetry
| WHERE account_id == "3f7932e3-9e69-4d69-aef5-41f281b3969b"
AND timestamp >= "2025-01-20T19:00:00Z"
AND timestamp <= "2025-01-21T00:00:00Z"
| STATS
session_count = COUNT_DISTINCT(session_id),
total_duration = SUM(session_duration_seconds),
screens_viewed = COUNT(*),
limit_views = SUM(CASE(screen_name == "payment_limits", 1, 0))
| EVAL hours_active = ROUND(TO_DOUBLE(total_duration) / 3600.0, 1)示例输出:
session_count total_duration screens_viewed limit_views hours_active
4 7,320 38 7 2.0当这一分析显示:某个平时习惯在午餐时间花 5 分钟处理银行事务的客户,却在深夜花了 2 小时在应用内操作,反复访问支付限额页面 7 次,随后又进行了异常大额转账时,整个图景就会变得清晰得多。这种行为上下文往往是“确定性欺诈判断”和“模糊可疑判断”之间的关键差异。
使用 Elasticsearch 分层存储扩展欺诈数据留存规模
欺诈调查平台只有在能够处理真实世界的数据规模以及满足监管留存要求时才具有实际价值。
数据规模
Elasticsearch 的分布式架构能够轻松应对这一点。同样的基础设施每天为企业客户处理数十亿级安全事件,也完全能够支撑支付交易级别的数据量(客户例如 BBVA)。
用分层存储满足监管留存
英国金融监管通常要求保存 7 年的交易数据。这意味着极其庞大的数据量。Elastic 的分层存储架构使这种成本在经济上可行:
-
热层(Hot tier,NVMe SSD):最近 7 到 30 天。用于活跃调查与实时告警,支持亚秒级查询性能。
-
温层(Warm tier,SSD):30 天到 1 年。足够用于历史案件复盘与模式分析。
-
冷层与冻结层(Cold tier / Frozen tier,对象存储):1 到 7 年。用于合规与审计查询,以及机器学习训练数据。
Logsdb 带来的成本降低
Logsdb 索引模式通过优化字段存储与索引方式,可将交易数据的存储成本降低高达65%。对于需要长期保存海量数据的平台来说,这种优化意味着从“可负担部署”到“成本不可承受部署”之间的关键差异。
在 Elasticsearch 上构建欺诈调查平台的关键经验
构建这个 Elasticsearch 欺诈调查平台过程中,我们总结了一些值得分享的重要经验,适用于任何正在构建类似系统的人。
| 经验要点为什么重要如何实践 | ||
|---|---|---|
| 从数据模型开始 | 清晰的数据 schema 能让 AI agents 准确理解查询结果。所有下游查询、skill 和仪表盘都依赖它。 | 提前定义明确的 mapping,例如字段名、类型和关系。在不同索引间统一字段命名,定义清晰的文档边界,并规划跨集群查询模式。 |
| 行为数据是关键差异点 | 仅有交易数据往往是模糊的。一笔 15,000 英镑的支付可能是购房、购车或欺诈。行为上下文(例如午夜两小时的应用使用、7 次访问支付限额页面、三天前的客服请求)才能将模糊转化为确定性判断。 | 在交易数据之外同时摄入应用会话遥测,并在调查阶段通过跨集群搜索进行联合查询。 |
| 跨集群搜索让架构可落地 | CCS 允许调查人员在遵守数据所有权边界的前提下跨银行与可观测性集群查询数据。如果没有它,就需要数据迁移或单独的聚合层。 | 将 CCS 视为结构性能力,而不是优化项。它是该架构在真实机构中可部署的关键前提。 |
下一步:AI agents 与工作流自动化
在数据模型与查询基础建立之后,第 3 部分将介绍构建在该架构之上的 AI agents:如何配置、使用哪些工具、workflow 自动化如何处理 SAR 报告生成与账户调查,以及一个端到端的完整调查流程示例(从告警到合规处置)。最终目标是构建一个统一、可查询的调查层,该层建立在许多机构已经在运行的基础设施之上。
准备好探索用于欺诈调查的 Elastic 吗?可以联系我们的金融服务团队,讨论基于你数据的概念验证(POC)、现有欺诈技术栈的架构评估,或关于 Elastic 如何融入你欺诈路线图的战略讨论。
原文:How to build a money mule detection platform on Elasticsearch - Elasticsearch Labs

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)