AI Agent 背后的 8 种 LLM
很多人第一次接触 AI Agent 时,都会有一个直觉:
Agent 不就是一个更聪明的大模型吗?

但当你真正把一个 Agent 系统拆开看,会发现它远比“一个模型”复杂得多。
它更像一支数字化团队:
有人负责理解需求,有人负责深度思考,有人负责看图识界面,有人负责调度流程,有人负责执行动作,还有人专门处理低成本的小任务。
也正是在这个意义上,AI Agent 里常会提到 8 种不同方向的 LLM:
GPT、MoE、LRM、VLM、SLM、LAM、HLM、LCM。
它们不是一套完全统一的官方分类,但用来理解 Agent 架构非常好用。
因为它们回答的是同一个问题:
在一个 AI Agent 里,不同模型分别扮演什么角色?
一、GPT:AI Agent 的“通用大脑”

如果说 AI 世界里有一个真正的“基石”,那一定是 GPT。代表模型如:GPT-4、GPT-4o、GPT-5.5。
它的全称叫:Generative Pretrained Transformer。翻译过来其实并不重要。你只需要理解一件事:GPT 的本质,就是一个超级通用的语言理解系统。它可以:
- 写文章
- 回答问题
- 编写代码
- 总结文档
- 翻译语言
- 做知识问答
- 进行对话
它最大的特点,不是某一个能力特别强。而是:“什么都会一点。”
这也是为什么,几乎所有 AI Agent 的底层,都离不开 GPT 类模型。
因为 Agent 的第一步,一定是:理解用户到底要干什么。
比如你说:“帮我整理一下最近 AI 圈的重要新闻,并做成一份简报。”
Agent 首先必须理解:
- 什么叫 AI 圈
- 什么叫重要新闻
- 什么叫简报
- 输出格式是什么
- 是否需要联网
而这一层“语言理解能力”,就是 GPT 最擅长的事情。所以在 Agent 世界里,GPT 更像是整个系统的基础认知中枢。
二、MoE:让 AI 拥有“专家团队”
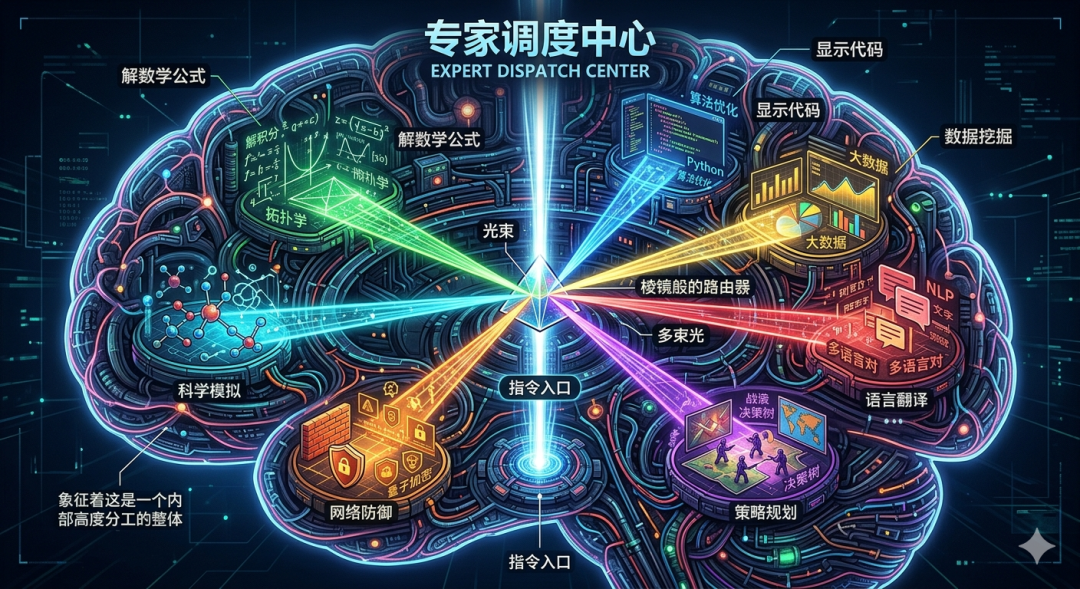
接下来是现在非常热门的一种架构:MoE。全称:Mixture of Experts。
中文通常翻译为:“专家混合模型”。这个名字其实特别形象。因为它真的很像现实里的专家团队。传统模型有点像:一个人什么都干。而 MoE 更像:不同问题,交给不同专家处理。比如:
- 数学问题 → 数学专家
- 编程问题 → 代码专家
- 翻译任务 → 多语言专家
- 推理任务 → 逻辑专家
系统会自动判断:当前任务该激活哪些专家。这带来一个非常大的优势:模型可以做得超级大,但推理成本不会无限爆炸。比如一个 MoE 模型总参数可能达到万亿级。但实际每次回答问题时,只激活其中一小部分专家。结果就是:
- 能力更强
- 成本更低
- 推理更高效
为什么很多新一代 Agent 开始偏爱 MoE?因为 Agent 本身就是复杂多任务系统。它既要写代码,又要查资料,还要规划任务、调用工具、处理文档。这种场景特别适合“专家分工”。所以 MoE,本质上是在给 AI Agent 搭建一支专业团队。
三、LRM:真正会“深度思考”的模型

最近一年,AI 圈最核心的变化之一,就是:模型开始越来越会“思考”。
这类模型,被称为:LRM。Large Reasoning Model,中文叫:大推理模型。代表模型:OpenAI o1、Gemini 2.5 Pro、Claude高端系列。它和传统 GPT 最大的区别是:GPT 更像“快速回答”。而 LRM 更像:“先认真想一遍,再回答。”它会:
- 分步骤思考
- 自己拆解问题
- 多轮推理
- 长链路分析
- 规划执行路径
为什么这件事重要?因为 AI Agent 最难的地方,其实不是聊天。而是:完成复杂任务。比如:“帮我分析三家 AI 创业公司的商业模式,并输出投资建议。”这不是一句话能完成的。它需要:搜索信息、分析商业逻辑、比较产品定位、判断市场空间、总结优劣势、输出决策建议。
这已经不是简单生成文字。而是真正意义上的“思考”。而 LRM,就是现在 Agent 系统里的核心推理引擎。很多人认为:AI Agent 的上限,本质上取决于 Reasoning 能力。
四、VLM:让 AI 第一次“看见世界”

过去的大模型,有一个非常明显的问题:只能看文字。但真实世界不是文字组成的,网页是图像、Excel 是图像、PPT 是图像、按钮是图像、视频更是图像。于是,VLM 出现了。VLM 的全称是:Vision-Language Model。视觉语言模型。它最大的价值,就是让 AI 不只是“读文本”。而是开始真正“看世界”。比如它可以:
- 看懂截图
- 理解网页布局
- 识别图表
- 阅读文档
- 分析 UI 界面
- 提取图片内容
- 识别视频画面
这一点,对于 AI Agent 来说至关重要。因为很多 Agent 的最终目标是自动操作电脑。而操作电脑,本质上就需要先看懂界面。所以现在非常火的:
- Computer Use
- Browser Agent
- 自动办公 Agent
- GUI Agent
背后都离不开 VLM。如果说 GPT 是 Agent 的大脑。那 VLM 更像是Agent 的眼睛。
五、SLM:小模型,才是真正的成本杀手

很多人现在一提 AI,就默认:模型越大越强。但真正做过企业 Agent 的人会发现:很多任务,其实根本不需要超大模型。于是,SLM 出现了。SLM:Small Language Model。小语言模型。它的参数规模通常更小:1B,3B,7B,13B甚至更小几百兆。相比超大模型:它更快、更轻、更便宜。
为什么这件事很重要?
因为 Agent 最大的问题之一,其实是:成本。如果一个 Agent 每执行一步都调用超大模型。成本会非常夸张。所以很多成熟系统会采用:“大模型 + 小模型”协同架构。例如:简单任务先交给 SLM:
- 分类
- 摘要
- 意图识别
- 关键词提取
- 数据清洗
只有复杂问题,才调用大模型。这样可以极大降低 Agent 的整体成本。
很多时候真正决定 Agent 能不能商业化落地的。不是模型能力,而是推理成本。而 SLM,恰恰是今天 AI 成本优化里最重要的一环。
六、LAM:AI 从“会说”到“会做”

这是 AI Agent 时代最关键的变化之一。
过去的大模型,本质上只是会聊天。但今天的 Agent 开始进入另一个阶段:真正执行任务。于是出现了一个非常重要的新概念:LAM,Large Action Model。大动作模型。它和传统 LLM 最大的区别是:LLM 负责“生成语言”,LAM 负责“执行动作”。比如:点击按钮、调用 API、自动发邮件、操作浏览器等。你会发现:这已经不是聊天机器人了。而是真正开始“干活”。这也是为什么,现在很多 AI 公司开始疯狂布局:Computer Use Agent。因为 AI 一旦拥有“行动能力”。整个行业会进入全新阶段。未来很多白领工作的核心流程,都可能被 Agent 自动化。而 LAM,本质上就是 Agent 的“手脚”。
七、HLM:让 Agent 学会“管理复杂任务”
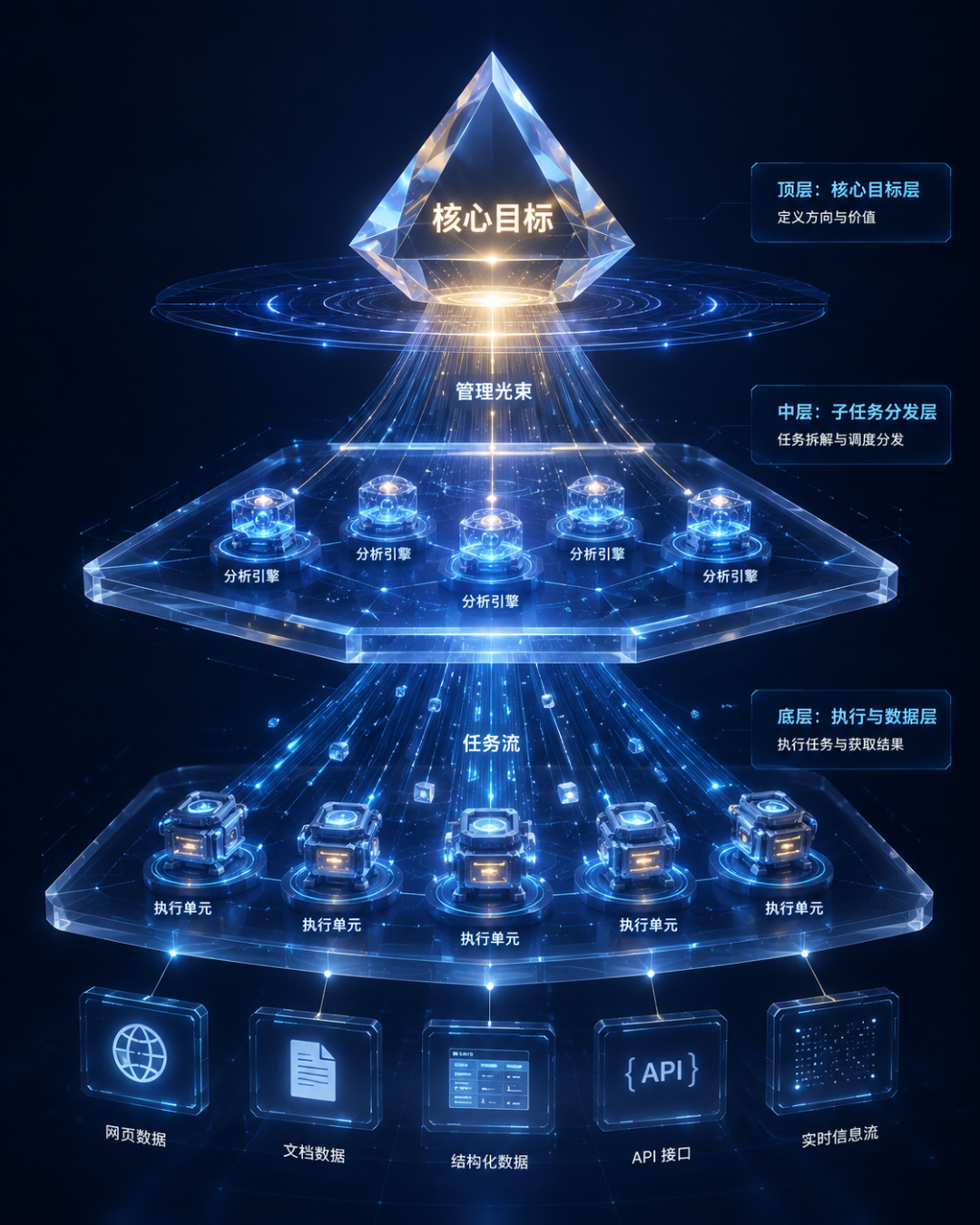
很多人低估了一件事:AI 最大的问题之一,不是能力不够。而是:上下文会混乱。任务一复杂,模型就容易:遗忘目标、逻辑漂移、上下文爆炸、重复推理、步骤失控。于是,HLM 出现了,Hierarchical Language Model,层级语言模型。
它的核心思想非常像公司管理结构。CEO 不会亲自执行所有任务。而是:高层负责目标,中层负责拆解,底层负责执行。HLM 也是一样,它会把复杂任务拆成不同层级。例如:最高层: “完成市场调研”;中间层:收集竞品,分析用户,总结趋势;底层:调搜索工具、读网页、整理数据。
这样做最大的好处是:复杂任务终于变得可管理。现在很多 Multi-Agent 系统,本质上都是 HLM 思想。它不是一个模型在干活。而是一个“AI 组织结构”。
八、LCM:AI 的下一阶段,也许是“概念理解”

最后一个方向,比较前沿。它叫:LCM,Large Concept Model,大概念模型。这个方向最核心的目标是:让 AI 不只是预测 token,而是真正理解“概念”。
什么意思?
今天的大模型,本质上仍然是在:一个词接一个词地生成。但人类思考很多时候不是这样。我们往往是:先理解整体概念、再组织语言。
比如你想到“创业公司”,脑子里出现的不是一个个 token。而是一整个概念网络:融资、团队、产品、市场、增长、竞争。
LCM 想做的,就是让 AI 更接近这种“概念级理解”。为什么它可能重要?因为很多 AI 的问题,其实都和 token 预测有关:幻觉、长推理漂移、逻辑不稳定、抽象能力不足。如果未来 AI 真能进入“概念推理阶段”。那 Agent 的认知能力,可能会发生巨大跃迁。虽然今天它还偏研究方向。但很多人认为:LCM 可能代表下一代 AI 的核心路线。
这 8 种模型,在 Agent 里怎么配合?

如果把 AI Agent 看成一个完整系统,这 8 类模型大致可以分成四层:感知层:VLM,负责看图、读界面、理解多模态输入。推理层:GPT、LRM、MoE,负责理解任务、组织语言、做复杂分析。执行层:LAM,负责把结果变成真正的动作。管理层:HLM、LCM、SLM,负责任务拆解、层级组织、轻量处理和概念抽象。
一个真正好用的 Agent,通常不是“一个超强模型单打独斗”,而是这几类能力协同起来。
这 8 种模型,其实分别承担了不同角色。它们之间的关系,大概可以理解为:
- GPT:负责理解和表达
- LRM:负责思考和推理
- VLM:负责感知世界
- LAM:负责真正行动
- HLM:负责流程管理
- MoE:负责专家分工
- SLM:负责低成本处理
- LCM:负责更高层概念抽象
举个简单例子:
用户说“帮我整理这份会议截图里的要点,查一下相关背景,然后生成一封发给团队的邮件”。这个过程可能会这样运行:
- VLM 先看截图,提取内容
- LRM 负责拆解任务和推理
- MoE 按任务类型调用擅长模块
- SLM 先做轻量摘要或分类
- HLM 负责组织流程
- LAM 执行邮件发送或文档创建
- GPT 负责最终文案生成
- LCM 则有机会在更高层帮助抽象会议主题和概念关系
这就是 AI Agent 的真实样子:不是一个模型,而是一套协作机制。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 1
1 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)