AI + Agent + Application:读 tau 源码,验证了一个 3A 架构猜想
我一直觉得一个好的 AI agent 框架,底层应该只有三层:模型适配层、编排引擎层、用户界面层。模型适配负责跟各种 LLM API 打交道,编排引擎管对话逻辑和工具调度,用户界面管怎么展示给人类。我把这叫做 3A 架构——AI + Agent + Application。
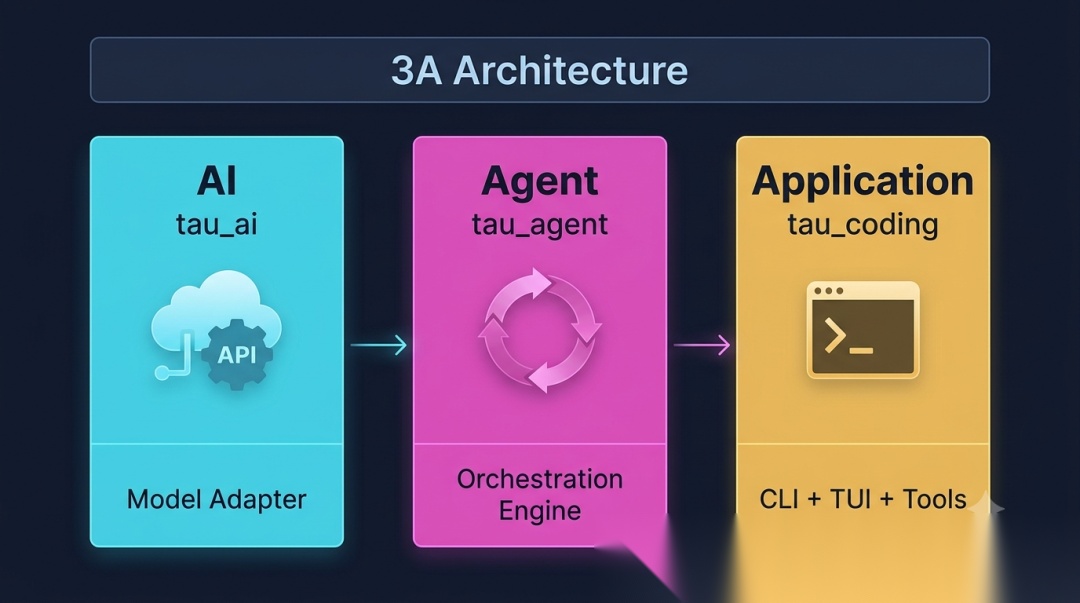
最近读了 tau 的源码,发现它刚好就是这样的:tau_ai(AI 层,Provider 适配)、tau_agent(Agent 层,循环引擎+会话管理)、tau_coding(Application 层,CLI+TUI+工具实现)。三层之间依赖方向单向不可逆:tau_coding → tau_agent → tau_ai。不是我强加的解读——tau 的作者显然也是深思熟虑过的。
文末“原文链接”可直达项目官方网址。
市面上 AI coding agent 太多了,Claude Code、Cursor、Aider、OpenCode,该有的花样应该都有人做过了。但 tau 是那种你读着读着会突然停下来、盯着某段代码想"等等,这里为什么要这么写"的项目。然后想明白了,就觉得"哦,真聪明"。
挑几个核心点聊。
yield 事件流:loop 是引擎,不是司机
大部分 agent 的对话循环都是一个黑盒——你调 run(),等它跑完,拿到结果。中间 LLM 在干什么、工具调没调、第几轮了,你一概不知。
tau 的做法是直接把 loop 写成 async generator:
async def run_agent_loop(...) -> AsyncIterator[AgentEvent]: yield AgentStartEvent() yield TurnStartEvent(turn=1) yield MessageDeltaEvent(\"我来读一下文件...\") yield ToolExecutionStartEvent() yield ToolExecutionEndEvent() yield AgentEndEvent()
每一步都 yield 一个事件出来。前端拿到这些事件想怎么渲染就怎么渲染,loop 本身不碰 UI。
这带来一个很有意思的分工。loop 什么都不拥有——对话记录是调用者传进来的 list,取消信号是调用者创建的,loop 只负责读数据、做决策、yield 事件。它是纯粹的"输入→输出"机器。
然后看 loop 的调用方,也就是 AgentHarness。它握着方向盘——管队列、管取消、管对话记录存哪。loop 不知道 harness 的存在,harness 不干预 loop 的逻辑。两者通过回调衔接。
我刚看到这里的时候觉得有点绕。后来画了张图才想明白:loop 定义"什么时候做",harness 定义"做什么"。 换 LLM 后端、换队列策略、换持久化方式,loop 一行不改。
市面上大部分 agent 的状态管理、UI 渲染、LLM 调用是搅在一起的。tau 用 yield 把这三层拆开了——而且不是靠什么复杂框架,就是一个 async generator。
全链路 Protocol:不继承、不 import、签名对了就行
Python 里定义接口要么用 ABC(抽象基类),要么用 Protocol(结构化子类型)。大部分项目选前者。tau 从头到尾全是 Protocol。
什么意思呢?比如 Provider 层只定义了一个 32 行的协议:
class ModelProvider(Protocol): def stream_response( self, *, model, system, messages, tools, signal=None ) -> AsyncIterator[ProviderEvent]: ...
实现方不需要 import ModelProvider,不需要 class OpenAICompatibleProvider(ModelProvider)。你只要把 stream_response 的签名写对了,类型检查器就认你是合法的 Provider。
这和 ABC 有什么实际区别?
用 ABC,你新增一个 Google Gemini Provider,得 import 基类、改继承链,万一基类接口变了你还得跟着改。用 Protocol,你写你的实现,完全不知道上层接口的存在——接口和实现之间零耦合。
再往上看一层,loop 里也只消费 ModelProvider 这个 Protocol。loop 不关心底层是 OpenAI 还是 Anthropic 还是本地 Ollama。换一个后端,上层代码一个字不改。
我刚学 Python 的时候觉得 Protocol 就是个"类型检查用的鸭子类型",没什么稀奇的。但 tau 让我意识到:在架构层面,Protocol 改的是依赖方向。 不是"上层依赖下层",而是"上层定义契约,下层自觉遵守"。实现方甚至不知道自己正在实现某个契约。
这和绝大多数 agent 项目用类继承组织代码的思路是完全两条路。
stream_response 的闭包:懒执行不用框架
看 Provider 的具体实现时,我注意到一个写法:
def stream_response(self, ...) -> AsyncIterator[ProviderEvent]: # 这是一般函数,不是 async def async def iterator() -> AsyncIterator[ProviderEvent]: client = self._get_client() async with client.stream(...) as response: yield ProviderTextDeltaEvent(...) return iterator()
stream_response 是同步函数,但返回的是 async generator。调用方可以直接 async for event in provider.stream_response(...)。
这解决了两个问题。
第一,Protocol 里定义的是 def 不是 async def。如果定义成 async def,消费方得先 await 拿到 generator 再 async for——两步变一步。
第二,网络的 I/O 延迟到了调用方真正开始迭代的那一刻。stream_response() 只是把参数塞进闭包然后返回,什么都不做。懒执行,靠的是 Python 自带的闭包机制和 async generator 的组合——不引入任何额外框架。

很 subtle 的写法。可能不是所有人都会喜欢,但我觉得很 Pythonic。
同文件树形会话:这玩意儿真的只有 Pi 和 tau 有
写代码的时候经常有这种情况:你让 agent 改了一堆东西,改到一半觉得方向不对,想回到某个点换个方案重新来。
大多数 agent 的做法是:线性回退(Cursor 的 “Restore checkpoint”),或者 fork 一个新文件(OpenCode 的 /fork、Claude Code 的 /fork)。前者你回退了就丢了之后的所有记录,后者你有了新文件但和旧的那个彻底断了联系。
tau 的做法是——所有对话存在同一个 JSONL 文件里,靠 parent_id 链组成一棵树:
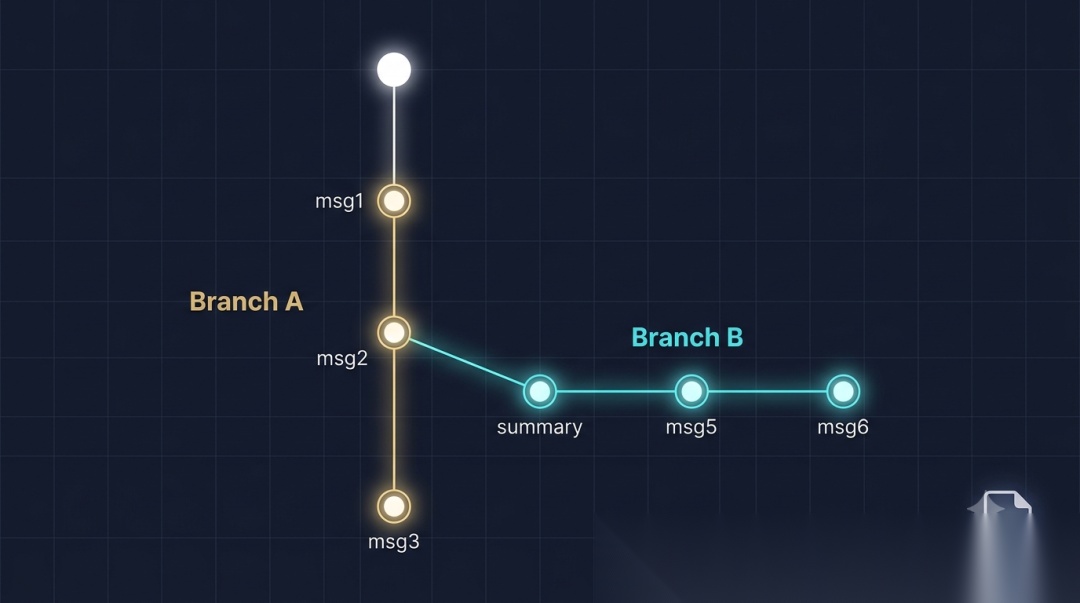
你想回到 msg2 换条路走?tau 在 msg2 后面插一条新消息,新消息的 parent_id 还是 msg2。旧的 msg3→msg4→分支A 完整保留。LeafEntry 只是一个指针,指向当前活跃分支,不删任何东西。
实现上靠的是一个 38 行的 path_to_entry() 函数——从任意 leaf_id 沿 parent_id 链逆推到根,翻转,就是这条分支的完整路径。恢复会话状态 = 按这个路径重放 JSONL 条目。
JSONL 文件只追加不修改。压缩上下文也不删旧消息,而是插入一条 CompactionEntry 标记"从这里开始忽略前面的消息"。
查了一圈,目前只有 Pi(tau 的设计灵感来源)和 tau 用了这种同文件树形会话。OpenCode 的 Issue #22067 有人在请求类似功能,Claude Code 也有 feature request 在提——但都没落地。
说实话这个功能日常用不一定每个人都需要。但它代表了一种态度:对话历史应该是一棵树,不是你走完之后就回不去的单向隧道。 tau 愿意在这个大多数人觉得"不重要"的地方下功夫,这点我挺佩服的。
最后说一下整体感受。
我读过不少 agent 项目的源码。有些是功能堆出来的——什么都有,但改一个地方要牵三个模块。有些是框架感很重——到处是继承链和依赖注入,看半天不知道哪行代码在真正干活。
tau 不一样。它的每一层都知道自己该做什么,不该做什么。Provider 只管翻译 API,Agent 只管事件流和循环逻辑,Session 只管追加记录和路径导航。依赖方向单一(tau_coding → tau_agent → tau_ai),不可逆。
如果你是想找一个功能最强的 agent 日用,tau 不一定适合你。但如果你想找一个代码能当教材读的项目,学习怎么用 Python 写出架构干净的 AI 应用——tau 可能比那些明星项目更有价值。

学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 0
0 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)