JetBrains 官宣: Codex 为默认Agent!
2026年6月,JetBrains 宣布在其 AI 助手中,将 OpenAI 的 Codex 设置为“推荐的智能体”(Recommended Agent)。这并非一次随意的合作,而是一个经过严谨数据验证、并深刻反映 JetBrains 产品哲学的决策。
为什么要设置一个“推荐的智能体”?
在 Codex 成为默认之前,JetBrains IDE 的 AI 用户需要自己从多个智能体(如 Junie、Claude Agent 或自带的 ACP 兼容智能体)中选择。这赋予了用户最高的自由度,但也带来了选择的负担。
JetBrains 观察到,随着模型能力的提升,智能体(Agent)能帮助用户完成比简单对话更多、更复杂的工作。因此,推荐一个开箱即用、能力均衡的智能体,能显著降低新用户的入门门槛,让用户能立刻体验到 AI 辅助编程的核心价值。这背后,是 JetBrains 一贯的“开箱即用、体验优先”设计理念的延续。
如何做出选择?基于“真实世界”的数据
JetBrains 的选择并非基于印象或合作关系,而是建立在一个名为 开发者生产力 AI 竞技场(DPAIA) 的开放基准测试上,结合了离线基准测试与在线 A/B 测试。
1. 评估标准:三个核心指标
JetBrains 从三个维度对候选智能体进行量化评估:
- 解决率:智能体在真实代码库中,成功完成 Bug 修复、功能开发等任务,并通过所有自动化测试的比例。这是衡量能力的核心。
- 成本:完成一项任务的中位数 token 消耗成本。这确保了推荐的智能体在提供高价值的同时,其使用成本对用户是合理的。
- 延迟:从发出指令到得到最终结果的端到端中位数时间。这直接影响开发者的工作流畅度。
JetBrains 将“成本”和“延迟”与“解决率”并列为核心指标,这非常务实。它表明 JetBrains 追求的是一种面向真实开发者的实用主义平衡,而非实验室环境下的极限性能。
如下是codex的数据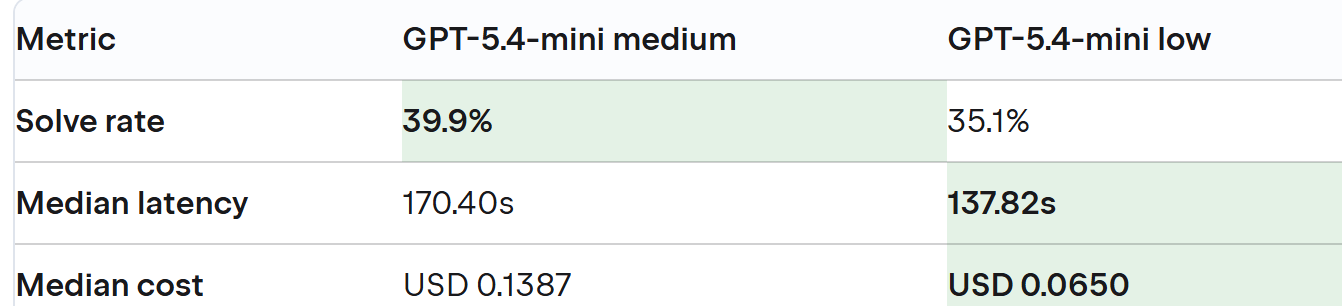
2. 严谨的测试流程
- 多语言、多场景的基准测试:数据集涵盖了 Java、C#、Python 三大生态,包含数百个来自真实代码库的任务,确保了评估的广泛性和代表性。
- 线上 A/B 测试验证:离线数据之外,JetBrains 还进行了真实用户参与的 A/B 测试。通过分析用户行为(如是否切换智能体、是否回到纯聊天模式)来验证离线结论,增加了决策的可信度。
数据驱动的选择:Codex vs. Junie
在最终候选者 Codex(GPT-5.4-mini medium)和 Junie(Gemini 3 Flash)之间,数据表现得极为接近,这从侧面印证了当前 AI 智能体的竞争已经进入了白热化阶段。
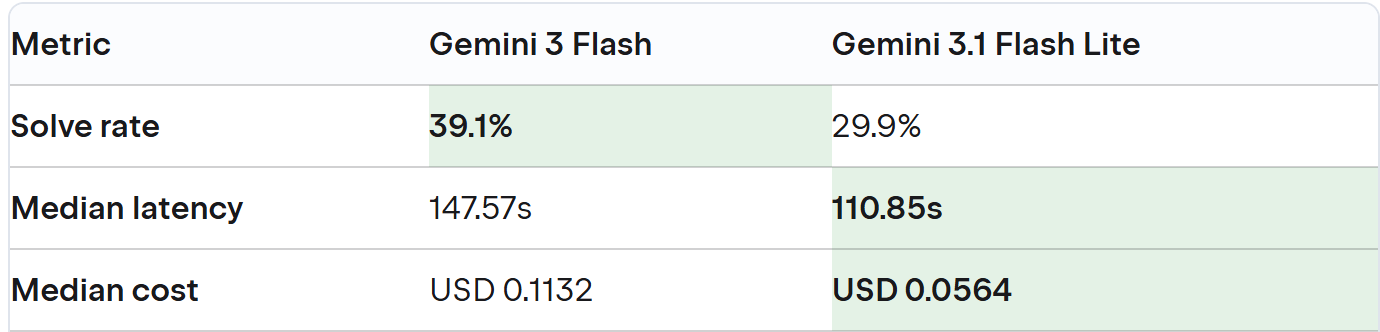
从表格可见,Codex 在综合解决率上略胜一筹,但 Junie 在延迟和成本上表现更好。两个智能体在不同语言上各有优势(例如 Codex 在 C# 上解决率更高,Junie 在 Java 上领先)。
最终决定性的因素来自于线上 A/B 测试中的 “用户留存、切换率和失败率” 等行为数据。在这些更能反映真实长期价值的指标上,Codex 最终胜出。
我认为,JetBrains 选择 Codex 作为推荐智能体,是一个集“用户、数据与战略”于一体的决策。
- 用户价值优先:通过数据驱动,为用户选择当下综合体验最好的智能体,降低了用户的选择成本,提升了即时满足感。
- 确立平台标准:通过建立 DPAIA 基准测试,JetBrains 向整个行业展示了一套科学、透明、可复现的 AI 编码工具评估标准。这增强了 JetBrains AI 平台的可信度,并为未来持续、客观地评估新模型/智能体奠定了基础。
- 保持开放,而非锁定:重要的一点是,推荐是“动态”的。JetBrains 明确表示,这并非永久决定,未来会基于新数据更新推荐。并且,用户始终可以自由切换到其他智能体。这种**“推荐但不强制”**的姿态,尊重了高级用户的选择权,也维护了 JetBrains 作为开放平台的形象。
总结
JetBrains 将 Codex 设为推荐 AI 智能体,是一次完美的产品、数据与战略结合的典范。它基于严谨的测试,做出了一个对当前用户最友好的选择,同时通过公开的基准测试和开放的切换机制,展现了其作为平台构建者的成熟心态。对于开发者而言,这意味着在 JetBrains IDE 中,可以以一个更低的起点,体验到当前最优秀的 AI 辅助编程能力,并且拥有不被锁定的自由。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 9
9 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)