法律 AI Agent:从架构到案例匹配的技术方案与工程实践
普通人遇到法律问题,第一反应往往不是"找律师",而是——“我这事算什么性质?该怎么办?”
劳动争议、民间借贷、婚姻纠纷、交通事故……这些高频法律场景,真正走到诉讼阶段的只是少数。大多数人卡在第一步:不知道自己的情况对应什么法律问题,也不知道该从哪开始。
这篇文章从整体架构讲到案例匹配模块的技术实现——LangGraph 工作流编排、ES + Qdrant 多路召回、LLM 精排、Guardrail 三层校验链。不做概念科普,只讲设计和代码。
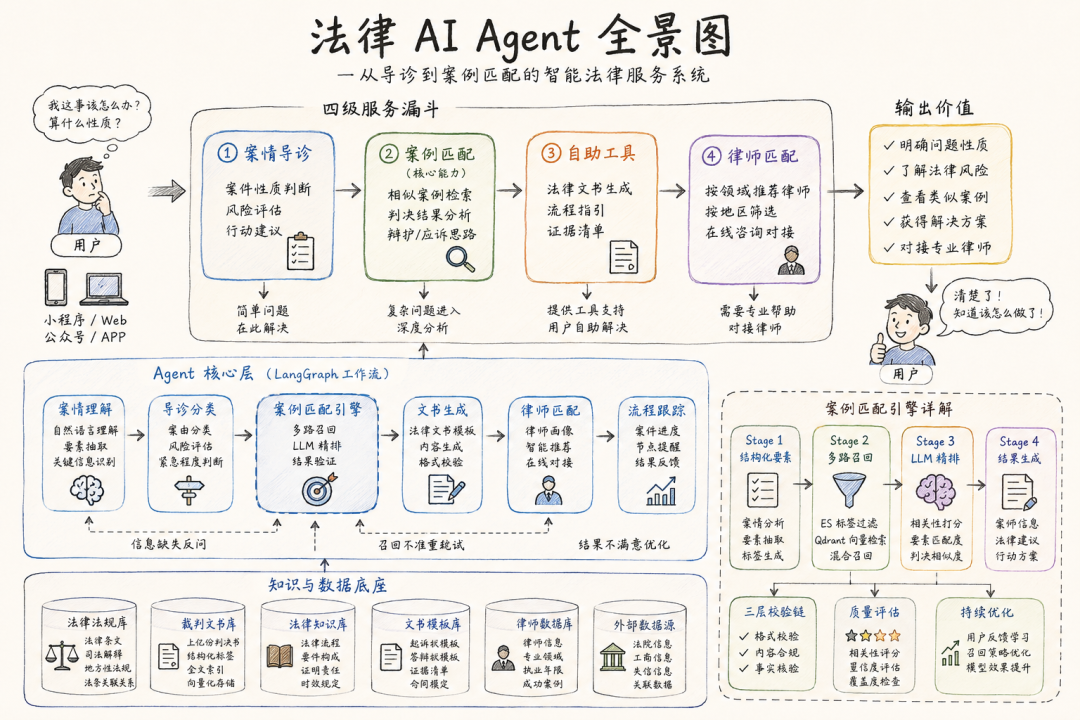
一、整体定位:四级漏斗
用户描述问题
↓
第一层:案情导诊
判断属于什么法律问题,评估严重程度,给出行动方向
↓
第二层:案例匹配(核心能力)
检索相似案例,分析判决结果,提供辩护/应诉思路参考
↓
第三层:自助工具
生成法律文书,提供流程指引和证据清单
↓
第四层:律师匹配
按领域/地区推荐律师
用户从导诊进入,根据问题的复杂程度停在不同的层级。简单问题导诊 + 自助工具就够了,复杂问题走到底层找律师。
二、整体架构
用户界面(小程序 / Web / 公众号)
│
┌─────▼────────────────────────────────────┐
│ Agent 核心层 │
│ │
│ 案情理解 → 导诊分类 → 行动建议 │
│ 事实提取 风险评估 分步指南 │
│ 要素识别 紧急度 材料清单 │
│ │
│ 案例匹配 → 辩护思路 │
│ 语义检索 策略推荐 │
│ 判决分析 法条引用 │
│ │
│ 文书生成 → 律师匹配 → 流程跟踪 │
└────┬───────────┬───────────┬─────────────┘
│ │ │
┌────▼───┐ ┌────▼────┐ ┌───▼───────────┐
│ 知识库 │ │ 案例库 │ │ 外部服务 │
│ │ │ │ │ │
│ 法律条文 │ │ 裁判文书 │ │ 律师信息 │
│ 司法解释 │ │ 按案由 │ │ 法院信息 │
│ 流程知识 │ │ 按语义 │ │ 工商信息 │
│ 文书模板 │ │ 判决结果 │ │ │
└─────────┘ └─────────┘ └───────────────┘
三、案例匹配:完整技术实现
案例匹配是 Agent 最有价值也最难的模块。用户说"老板不给工资还把我辞了",Agent 能从裁判文书库中找到事实最接近的案例,告诉用户类似情况法院怎么判的、赔偿范围多少、怎么主张权利。
3.1 LangGraph 工作流编排
整个流程有 4 个 Stage,但不是简单的线性流水线。Stage 1 发现关键信息缺失要回退问用户,Stage 3 精排结果太差要放宽召回条件重试。用 LangGraph 的状态图来编排是最自然的选择。
from langgraph.graph import StateGraph, END
from typing import TypedDict, Optional, List
# === 全局状态定义 ===
class LegalCaseState(TypedDict):
user_input: str
structured: Optional[dict] # Stage 1 结构化结果
missing_info: List[str] # 缺失的关键信息
tag_filtered_ids: List[str] # 标签过滤后的候选 ID
recall_candidates: List[dict] # 向量召回结果
reranked_top5: List[dict] # 精排结果
output: Optional[dict] # 最终产出
retry_count: int # 重试次数
max_retries: int # 最大重试
# === 构建状态图 ===
workflow = StateGraph(LegalCaseState)
workflow.add_node("extract_legal_elements", extract_legal_elements)
workflow.add_node("ask_missing_info", ask_missing_info)
workflow.add_node("tag_filter", tag_filter)
workflow.add_node("vector_recall", vector_recall)
workflow.add_node("llm_rerank", llm_rerank)
workflow.add_node("relax_recall", relax_recall)
workflow.add_node("generate_output", generate_output)
workflow.set_entry_point("extract_legal_elements")
# 有条件边:信息缺失 → 反问用户
workflow.add_conditional_edges(
"extract_legal_elements",
decide_missing_info,
{"ask_user": "ask_missing_info", "proceed": "tag_filter"}
)
workflow.add_edge("ask_missing_info", "extract_legal_elements")
# 召回链路
workflow.add_edge("tag_filter", "vector_recall")
workflow.add_edge("vector_recall", "llm_rerank")
# 精排不达标 → 放宽条件重试
workflow.add_conditional_edges(
"llm_rerank",
decide_retry,
{"acceptable": "generate_output", "retry": "relax_recall", "failed": END}
)
workflow.add_edge("relax_recall", "vector_recall")
app = workflow.compile()
为什么用 LangGraph 而不是 LangChain Chain? 因为流程中有多个条件分支和回退环路——信息缺失要回退到反问、精排不达标要放宽条件重试。Chain 是 DAG 结构,表达不了带环的流程;StateGraph 的循环边天然适合这种场景。
路由函数实现:
def decide_missing_info(state: LegalCaseState) -> str:
"""判断是否需要反问用户补充信息"""
if state["missing_info"] and state["retry_count"] == 0:
critical = ["amount_involved", "has_contract"]
for info in state["missing_info"]:
if info in critical:
return "ask_user"
return "proceed"
def decide_retry(state: LegalCaseState) -> str:
"""判断精排结果是否可接受"""
if not state["reranked_top5"]:
return "retry" if state["retry_count"] < state["max_retries"] else "failed"
top_score = state["reranked_top5"][0].get("overall_score", 0)
if top_score < 6.0 and state["retry_count"] < state["max_retries"]:
state["retry_count"] += 1
return "retry"
return "acceptable"
3.2 Stage 1:案情结构化
用户的口语化描述先转化为结构化法律要素。这一步做不好,后面全是错的。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
class LegalElements(BaseModel):
case_type: str = Field(description="案件类型:民事/刑事/行政")
case_category: str = Field(description="案由大类,如劳动争议")
sub_category: str = Field(description="案由小类")
employment_duration: Optional[str] = None
has_contract: Optional[bool] = None
unpaid_wages: Optional[dict] = None
termination_type: Optional[str] = None
amount_involved: Optional[str] = None
keywords: List[str] = Field(default_factory=list)
applicable_laws: List[str] = Field(default_factory=list)
missing_info: List[str] = Field(default_factory=list)
parser = PydanticOutputParser(pydantic_object=LegalElements)
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个法律案情分析专家。将用户的自然语言描述转化为结构化法律要素。
注意:
1. **只抽取明确提到的信息,不要猜测**
2. **如果关键信息缺失,在 missing_info 中标注**
3. **案由分类参考《民事案件案由规定》**
{format_instructions}"""),
("human", "{user_input}")
])
chain = prompt | llm | parser
输出结构化结果的同时,missing_info 字段驱动 LangGraph 的 ask_missing_info 节点反问用户补全信息:
def ask_missing_info(state: LegalCaseState):
questions = []
for k in state["missing_info"][:3]:
if k == "amount_involved":
questions.append("您的月工资是多少?这关系到赔偿金额的计算。")
elif k == "has_social_security":
questions.append("公司有没有给您缴纳社保?")
elif k == "has_contract":
questions.append("您和公司签过劳动合同吗?")
return {"messages": [AIMessage(content="/n".join(questions))]}
3.3 Stage 2:多路召回
裁判文书网有上亿份判决书,不能全量做向量检索。分两级:ES 标签过滤 + Qdrant 向量语义检索。
第一级:ES 标签精确过滤
用 Stage 1 的结构化标签做过滤,快速缩小候选集。选用 ES 而不是关系数据库,因为裁判文书除了结构化字段还有全文内容,ES 的倒排索引可以同时在结构化字段和文本字段上做混合过滤。
from elasticsearch import Elasticsearch
es = Elasticsearch("http://localhost:9200")
def tag_filter(state: LegalCaseState) -> LegalCaseState:
elements = state["structured"]
must_clauses = [
{"term": {"case_category": elements["case_category"]}},
{"terms": {"sub_category": [elements["sub_category"]]}},
{"range": {"year": {"gte": 2022, "lte": 2026}}},
]
if elements.get("has_contract") is False:
must_clauses.append({"term": {"has_contract": False}})
if elements.get("amount_involved") and elements["amount_involved"] != "未知":
amount = extract_number(elements["amount_involved"])
must_clauses.append({"range": {"amount_involved": {"lte": amount * 2}}})
body = {
"query": {"bool": {"must": must_clauses}},
"size": 5000,
"_source": ["case_id", "case_category", "fact_summary", "judgment"]
}
resp = es.search(index="judgments", body=body)
case_ids = [hit["_source"]["case_id"] for hit in resp["hits"]["hits"]]
return {"tag_filtered_ids": case_ids}
第二级:Qdrant 向量语义检索
在标签过滤后的候选集上,用事实描述做语义检索。选 Qdrant 而不是 Milvus:这个场景只需要单机部署、百亿级以内的向量量,Qdrant 一个 Docker 容器搞定,部署成本比 Milvus 低得多。
Embedding 模型选 bge-m3(1024 维)。法律文书中法条编号(“第82条”)、案例编号(“(2023)京01民终1234号”)中英文混写,bge-m3 的多语言能力在 1024 维下检索精度比 text-embedding-3-small 高 3-5 个百分点(在我们的 2000 条标注测试集上)。
from qdrant_client import QdrantClient
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("BAAI/bge-m3")
client = QdrantClient(host="localhost", port=6333)
def vector_recall(state: LegalCaseState) -> LegalCaseState:
case_ids = state["tag_filtered_ids"]
query_text = state["structured"].get("fact_summary", state["user_input"])
query_vector = model.encode(query_text).tolist()
# Qdrant 支持用 payload filter 缩小搜索范围
hits = client.search(
collection_name="judgments_by_category",
query_vector=query_vector,
query_filter={"must": [{"has_id": case_ids}]},
limit=50,
)
# 混合权重:0.6 × 向量相似度 + 0.4 × 标签匹配度
candidates = []
for hit in hits:
vector_score = hit.score
tag_score = compute_tag_match(state["structured"], hit.payload)
combined = 0.6 * vector_score + 0.4 * tag_score
candidates.append({
"case_id": hit.payload["case_id"],
"fact_summary": hit.payload["fact_summary"],
"judgment": hit.payload["judgment"],
"combined_score": combined,
})
candidates.sort(key=lambda x: x["combined_score"], reverse=True)
return {"recall_candidates": candidates[:50]}
为什么先做标签过滤再做向量检索? 因为"法律关系相似"和"事实描述相似"是两回事。两个案例都提到"欠薪",但一个是劳动合同纠纷(适用劳动法),一个是劳务合同纠纷(适用民法典),法律关系不同,判决依据完全不同。标签过滤确保候选集在法律关系上是同类的。
混合权重
def compute_tag_match(structured: dict, payload: dict) -> float:
score = 0.0
# 子案由一致给 0.5
if structured.get("sub_category") == payload.get("sub_category"):
score += 0.5
# 要素重叠比例
elements = structured.get("legal_elements", {})
payload_elems = payload.get("legal_elements", {})
overlap = sum(1 for k, v in elements.items()
if v and v != "未知" and payload_elems.get(k) == v)
total = sum(1 for v in elements.values() if v and v != "未知")
if total > 0:
score += 0.5 * (overlap / total)
return score
重试时的放宽策略
def relax_recall(state: LegalCaseState) -> LegalCaseState:
retry = state["retry_count"]
if retry == 1:
state["tag_filtered_ids"] = expand_category(state) # 案由扩大到父类
elif retry == 2:
state["tag_filtered_ids"] = remove_year_filter(state) # 去掉年份限制
elif retry >= 3:
state["tag_filtered_ids"] = None # 全库向量检索
return state
3.4 Stage 3:LLM 精排
向量召回回来的 TOP 50,还需要做一次精细比对。向量相似度衡量的是"措辞相似",不是"法律关系相似"。
用 LangChain 的 with_structured_output 实现多维评分:
from langchain_core.pydantic_v1 import BaseModel, Field
class CaseScore(BaseModel):
cause_match: int = Field(ge=1, le=10, description="案由匹配度")
fact_similarity: int = Field(ge=1, le=10, description="事实相似度")
dispute_focus: int = Field(ge=1, le=10, description="争议焦点")
reference_value: int = Field(ge=1, le=10, description="参考价值")
class RerankResult(BaseModel):
scores: List[CaseScore]
rerank_prompt = ChatPromptTemplate.from_messages([
("system", """你是一个法律案例比对专家。请从以下维度评分(1-10):
A. 案由匹配度 B. 事实相似度 C. 争议焦点 D. 参考价值
要严格评分,事实不相似就给低分。"""),
("human", "用户案情:{user_case}/n候选案例:{case_info}")
])
structured_llm = llm.with_structured_output(RerankResult)
rerank_chain = rerank_prompt | structured_llm
批量评分并加权聚合:
def llm_rerank(state: LegalCaseState) -> LegalCaseState:
candidates = state["recall_candidates"][:50]
scored = []
for i in range(0, len(candidates), 5):
batch = candidates[i:i+5]
result = rerank_chain.invoke({
"user_case": state["user_input"],
"case_info": [
{"case_fact": c["fact_summary"][:500],
"case_judgment": c["judgment"][:300]}
for c in batch
]
})
for idx, score in enumerate(result.scores):
scored.append({
batch[idx],
"overall_score": (
score.cause_match * 0.3 +
score.fact_similarity * 0.3 +
score.dispute_focus * 0.2 +
score.reference_value * 0.2
)
})
scored.sort(key=lambda x: x["overall_score"], reverse=True)
return {"reranked_top5": scored[:5]}
这份精排结果同时输入到判决统计(用 TOP 50 的判决结果做统计分析)和策略建议(用 TOP 5 的法院观点生成)。
3.5 Guardrail 实现
法律 Agent 的 Guardrail 和其他场景不同——它防护的不是"执行了危险操作",而是输出了误导性法律内容。
用 LangGraph 的 Condition 做第一道闸,自定义规则引擎做第二道,知识库检索做第三道:
def guardrail_check(state: LegalCaseState) -> str:
output = state["output"]
# 第一道:Agent 自检 — 绝对化表述拦截
if any(p in str(output) for p in ["保证", "一定", "100%", "肯定赢"]):
return "rewrite"
# 第二道:规则拦截
if state["structured"]["case_type"] in ("刑事", "行政"):
if "律师" not in str(output):
return "block"
if "不构成法律意见" not in str(output):
return "rewrite"
# 第三道:法条引用校验
cited_laws = extract_law_citations(str(output))
for law in cited_laws:
if not verify_citation(query_law_knowledge_base(law), str(output)):
return "rewrite"
return "pass"
# 注册为 LangGraph 条件边
workflow.add_conditional_edges(
"generate_output",
guardrail_check,
{"pass": END, "rewrite": "generate_output", "block": "blocked_output"}
)
法条引用校验的实现——用精确查询,不用向量检索。法条原文一字不能差,向量检索的召回率做不到 100%:
def extract_law_citations(text: str) -> List[str]:
import re
pattern = r"[《]?([^》]+?法)[》]?第(/d+)条"
matches = re.findall(pattern, text)
return [f"{m[0]}第{m[1]}条" for m in matches]
def query_law_knowledge_base(law_citation: str) -> str:
result = es.get(index="law_knowledge_base", id=law_citation)
return result["_source"]["original_text"]
四、安全性设计
法律 Agent 和其他场景最大的不同是:给错了建议,用户可能真的会输掉官司。
三条红线
- 不能给确定性结论。 不说"你一定能赢",说"类似案例胜诉率约 80%"
- 不能替代律师。 刑事案件、重大商事纠纷必须建议咨询律师
- 不能建议违法操作。 不指导毁灭证据、虚假陈述等
免责声明的分级
DISCLAIMERS = {
"civil": (
"⚠️ 以上分析基于公开数据和通用法律知识,不构成正式法律意见。"
"每个案件情况不同,建议咨询执业律师。"
),
"criminal": (
"🚨 您描述的情况可能涉及刑事/重大民事纠纷。"
"建议立即委托执业律师处理。本工具仅提供参考信息,"
"不能替代专业法律服务。"
),
}
这些是 Guardrail 代码强制追加的,不是 LLM 自觉加上的。如果 Guardrail 检测到输出中缺少免责声明,会触发 rewrite 强制补上。
五、关键的工程决策
案由分库 vs 全库统一检索
每个高频案由(劳动争议、民间借贷、婚姻家事、交通事故、买卖合同纠纷)在 Qdrant 里各一个 collection。这五类占了民事诉讼的 70% 以上。
COLLECTION_MAP = {
"劳动争议": "judgments_labor",
"民间借贷": "judgments_loan",
"婚姻家事": "judgments_family",
"交通事故": "judgments_traffic",
"买卖合同纠纷": "judgments_contract",
}
好处:检索范围小速度快、无跨案由语义噪音、不同案由可独立调优。代价:案由识别必须准确,新增案由需要建新库。
裁判文书预处理
原始裁判文书有几大问题:长(少则几千字多则几万字)、模板化(大量格式文本)、噪声多(OCR 错误)。预处理必须做 LLM 提取,只把 fact_summary(300 字以内)拿去 Embedding。
超过 512 token 长度的文本,bge-m3 的向量表示质量会明显下降。所以提取内容控制在 500 字以内做 Embedding。
冷启动策略
从最高人民法院发布的典型案例和指导案例开始——这些案例质量高、权威性强,数量不多(几千份)但覆盖主要案由。然后扩展到各省高院的裁判文书,最后再扩展到基层法院。
增量更新:每周跑一次增量 pipeline,新文书经过预处理 → Embedding → Qdrant upsert,不需要全量重建。
时效性
2020 年的案例和 2025 年的案例,法律可能有修改(如 2024 年民法典合同编司法解释)。默认只检索近 3 年,案例太少才放宽。
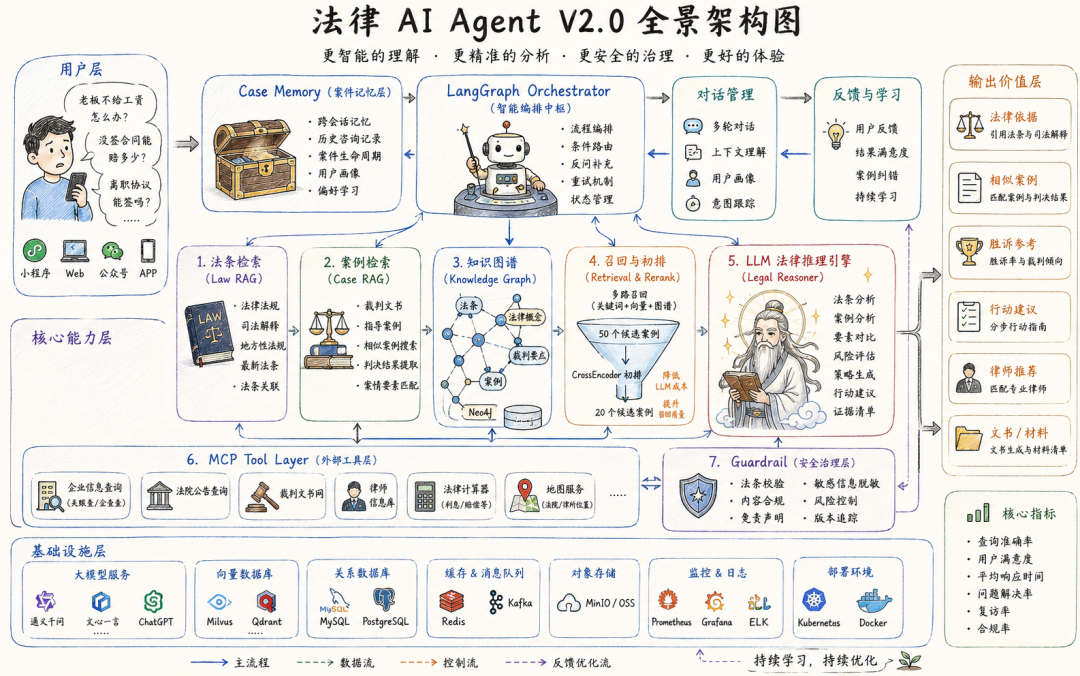
六、V2.0 升级:五个关键优化
上面这套方案上线跑通(以下简称 V1.0)之后,有几个问题会暴露出来。我们在迭代过程中识别了五个核心短板,对应做了 V2.0 的架构升级。
6.1 CrossEncoder 初排:解决 LLM 精排成本
V1.0 的问题: TOP 50 直接送 LLM 打分。如果用的 GPT-4.1 或 Claude,50 个 case 逐个看,单次查询仅精排就要几万 token,成本和延迟都扛不住。月活一万用户,光精排每个月烧掉几千美元。
V2.0 的改进: 在向量检索和 LLM 精排之间加一层 CrossEncoder 初排。
V1.0: ES → Qdrant (50) → LLM 精排 → TOP 5
V2.0: ES → Qdrant (50) → CrossEncoder (50→20) → LLM 精排 → TOP 5
CrossEncoder 比向量检索(Bi-Encoder)精度高,比 LLM 成本低一个数量级。
from sentence_transformers import CrossEncoder
# bge-reranker-v2 或 Qwen3-Reranker 均可
reranker = CrossEncoder("BAAI/bge-reranker-v2-m3")
def cross_encoder_rerank(state: LegalCaseState) -> LegalCaseState:
candidates = state["recall_candidates"][:50]
query = state["structured"].get("fact_summary", state["user_input"])
pairs = [(query, c["fact_summary"][:512]) for c in candidates]
scores = reranker.predict(pairs)
for idx, score in enumerate(scores):
candidates[idx]["crossencoder_score"] = float(score)
# 融合向量得分和 CrossEncoder 得分
candidates[idx]["combined_score"] = (
0.3 * candidates[idx]["combined_score"] +
0.7 * float(score)
)
candidates.sort(key=lambda x: x["combined_score"], reverse=True)
return {"recall_candidates": candidates[:20]} # 只保留 TOP 20 给 LLM
| 方案 | 单次成本 | 延迟 | 精度 |
|---|---|---|---|
| LLM 直接看 50 个 | $$$ | 10-20s | 最高 |
| CrossEncoder 50→20 + LLM 看 20 个 | $ | 2-3s | ≈ 持平 |
| 纯 CrossEncoder | $ | ~1s | 略低但有瓶颈 |
CrossEncoder 的得分(01)和向量余弦相似度(01)做加权融合。线上实验下来,0.7 × CrossEncoder + 0.3 × 向量相似度 效果最好,既保留了语义信息,又大幅压低了 LLM 调用量。
选型上 bge-reranker-v2-m3 和 Qwen3-Reranker 都可用。前者对中英文混写文本(法律文书场景)表现更好,后者在纯中文场景略优。
6.2 法条优先 + 联合推理:纠正成文法系逻辑
V1.0 的问题: 案例匹配→策略推荐,这套逻辑是美国判例法思维。中国是成文法系,裁判逻辑是法条 → 司法解释 → 指导案例,案例只是参考,不能作为判决依据。
只给用户看"类似案例怎么判",不给"法律依据是什么",在中国法律场景下是半成品。
V2.0 的改进: 召回链路改成法条召回 → 案例召回 → 联合推理。
V1.0: 案情结构化 → 案例检索 → 策略推荐
V2.0: 案情结构化 → ┌── 法条检索 (Law RAG)
├── 案例检索 (Case RAG)
└── 联合推理 (Legal Reasoner)
法条检索独立成一条召回链路:
def law_recall(state: LegalCaseState) -> LegalCaseState:
"""从法律知识库中检索相关法条"""
elements = state["structured"]
# 方法 1:基于案由的精确匹配
law_ids = es.search(index="law_knowledge_base", body={
"query": {"bool": {"must": [
{"term": {"applicable_categories": elements["case_category"]}},
]}},
"size": 10,
})
# 方法 2:基于关键要素的语义检索
query_text = " ".join(elements.get("keywords", []))
law_vectors = law_model.encode(query_text).tolist()
law_hits = law_client.search(
collection_name="laws",
query_vector=law_vectors,
limit=5,
)
return {"law_candidates": combine_law_results(law_ids, law_hits)}
联合推理阶段,LLM 同时看到法条原文和相似案例,生成的建议结构变为:
📋 分析结果
【法律依据】
劳动合同法第10条:建立劳动关系应当订立书面劳动合同
劳动合同法第82条:未签合同超过一个月,应支付双倍工资
劳动合同法第87条:违法解除劳动合同,应支付二倍经济补偿金
【相似案例参考】
案例1:张三诉XX公司……(以下为参考,不作为判决依据)
【策略建议】
基于上述法律依据和参考案例……
法条是依据,案例是参考。 用户先看到法律依据,再看案例,逻辑上更符合中国法律体系。
6.3 法律知识图谱:连接法条、概念与案例
V1.0 的问题: 法条库和案例库各自独立。当法条更新时(如 2024 年民法典合同编司法解释发布),旧案例引用的法条版本可能已经不适用。而且法条和场景之间的关联是隐式的,检索全靠语义相似度,精度不够。
V2.0 的改进: 建一个法律知识图谱(Neo4j),把法条、法律概念、适用场景、关联案例串起来。
from neo4j import GraphDatabase
class LawGraph:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def query_related(self, law_article: str) -> List[dict]:
"""查询某法条关联的场景、概念和案例"""
with self.driver.session() as session:
result = session.run("""
MATCH (l:LawArticle {article: $article})
OPTIONAL MATCH (l)-[:APPLIES_TO]->(s:LegalScenario)
OPTIONAL MATCH (l)<-[:BASED_ON]-(c:Case)
OPTIONAL MATCH (l)-[:RELATES_TO]->(concept:LegalConcept)
RETURN l.article AS article, l.content AS content,
collect(DISTINCT s.name) AS scenarios,
collect(DISTINCT c.case_id) AS cases,
collect(DISTINCT concept.name) AS concepts
""", article=law_article)
return result.single().data()
图谱结构(三元组示例):
劳动合同法第82条 — [适用于] → 未签劳动合同
劳动合同法第82条 — [适用于] → 双倍工资请求
劳动合同法第82条 — [关联] → 经济补偿金
张三诉XX公司案 — [依据] → 劳动合同法第82条
张三诉XX公司案 — [关键词] → 未签劳动合同
这种关联比向量检索精确得多。问"未签合同能拿多少钱",图谱直接找到第82条和关联案例,不需要语义匹配。
更关键的是法条变更追踪:
def check_law_update(law_article: str) -> Optional[str]:
"""检查法条是否有新版本"""
with graph.session() as session:
result = session.run("""
MATCH (l:LawArticle {article: $article})
WHERE l.effective_date < date() AND l.superseded_by IS NOT NULL
RETURN l.superseded_by AS new_article
""", article=law_article)
record = result.single()
return record["new_article"] if record else None
当法条被新法替代时,图谱能直接溯源到最新版本,避免引用已失效法条。
6.4 Case Memory:跨会话的案件上下文
V1.0 的问题: 用户的咨询不是一次性完成的。
第一天:"公司拖欠工资" → 系统抽取结构化信息
第二天:"公司让我签离职协议" → 系统重新抽取,不知道是同一个人同一个案件
第三天:"仲裁申请怎么写" → 再次重新抽取
每次都要 LLM 重新做法案要素抽取,浪费 token 不说,还丢失了上下文连贯性。
V2.0 的改进: 引入 Case Memory 层,用独立的持久化存储保存用户的案件上下文。
class CaseMemory:
"""跨会话的案件记忆"""
def __init__(self):
self.db = DuckDB("case_memory.db") # 轻量本地存储
self.db.execute("""
CREATE TABLE IF NOT EXISTS case_memory (
session_id VARCHAR,
case_id VARCHAR,
structured_data JSON,
created_at TIMESTAMP,
updated_at TIMESTAMP,
is_active BOOLEAN DEFAULT TRUE
)
""")
def get_active_case(self, session_id: str) -> Optional[dict]:
row = self.db.execute(
"SELECT structured_data FROM case_memory "
"WHERE session_id = ? AND is_active = TRUE "
"ORDER BY updated_at DESC LIMIT 1",
[session_id]
).fetchone()
return json.loads(row[0]) if row else None
def save_case(self, session_id: str, structured: dict):
"""持久化结构化结果"""
case_id = structured.get("case_id", str(uuid4()))
self.db.execute("""
INSERT INTO case_memory (session_id, case_id, structured_data,
created_at, updated_at)
VALUES (?, ?, ?, NOW(), NOW())
ON CONFLICT (case_id) DO UPDATE SET
structured_data = EXCLUDED.structured_data,
updated_at = NOW()
""", [session_id, case_id, json.dumps(structured)])
在 LangGraph 的入口处先查 Memory,有活跃案件则跳过 Stage 1 的结构化抽取:
def route_with_memory(state: LegalCaseState) -> str:
"""如果有活跃的案件记忆,跳过结构化抽取直接进入召回"""
memory = CaseMemory()
active = memory.get_active_case(state["session_id"])
if active and is_same_case(active, state["user_input"]):
state["structured"] = active
return "skip_extraction" # 直接跳到召回
return "extract"
这一层用 DuckDB 就够了——数据量小(用户维度的案件记录),不需要独立部署数据库服务。每个用户一个 session,每个 session 保留最近一个活跃案件的上下文。
6.5 MCP Tool Layer:接入外部数据源
V1.0 的问题: 所有知识都来自自有知识库。但法律场景中很多信息需要实时查询外部数据源——公司工商信息、法院公告、律师执业信息、裁判文书网最新判例。
V2.0 的改进: 通过 MCP(Model Context Protocol)标准协议接入外部工具。
Agent 推理层
↓
MCP Tool Layer
├── 企业信息查询(天眼查 / 企查查 API)
├── 法院公告查询
├── 律师执业信息查询
├── 裁判文书网检索
└── 工商注册信息查询
在 LangGraph 中,这些工具注册为可被 Agent 调用的节点:
from langchain_core.tools import tool
@tool
def query_company_info(company_name: str) -> dict:
"""查询企业的工商注册信息"""
# 通过 MCP 协议调用天眼查 API
return mcp_call("tianyancha", {"keyword": company_name})
@tool
def query_lawyer_info(name: str, region: str) -> List[dict]:
"""查询某地区的律师执业信息"""
return mcp_call("lawyer_db", {"name": name, "region": region})
@tool
def check_court_announcement(case_id: str) -> Optional[dict]:
"""查询法院公告信息"""
return mcp_call("court_api", {"case_id": case_id})
# 在 Legal Reasoner 节点中,Agent 根据场景自动调用工具
def legal_reasoner(state: LegalCaseState) -> LegalCaseState:
"""联合推理:综合法条、案例、外部数据生成建议"""
# Agent 根据推理需要自动调用工具
# 比如用户提到某公司 → Agent 自动调用 query_company_info
# 比如需要推荐律师 → Agent 自动调用 query_lawyer_info
result = reasoning_chain.invoke({
"user_case": state["user_input"],
"laws": state["law_candidates"],
"cases": state["reranked_top5"],
"tools": [query_company_info, query_lawyer_info, check_court_announcement],
})
return {"output": result}
MCP 的核心价值不是"能调外部 API"——这并不新鲜——而是标准化的工具定义和发现协议。未来法律科技生态中,法院、律所、数据服务商都暴露 MCP Server,Agent 可以即插即用,不用为每个数据源写定制集成代码。
V2.0 架构全景
用户
│
▼
┌──────────┐
│ Case │ ← 跨会话记忆
│ Memory │
└────┬─────┘
│
▼
LangGraph Orchestrator
│ │ │
▼ ▼ ▼
案件理解 法条检索 案例检索
(图谱) (Law RAG) (Case RAG)
│
▼
知识图谱 (Neo4j)
法条 ↔ 场景 ↔ 案例
│
▼
CrossEncoder (50→20)
│
▼
LLM 精排 (20→5)
│
▼
Legal Reasoner
(联合推理 + MCP Tool)
│
▼
Guardrail
│
▼
输出
V1.0 到 V2.0 的五个升级,本质上是同一个认知转变:
法律 AI Agent 不是搜索引擎。它不是在找"最像"的东西,而是在做"法律推理"。
这个转变体现在每一个改动里——法条优先于案例、知识图谱替代纯语义检索、CrossEncoder 加上 LLM 做两级精排而非让 LLM 独自扛、Memory 让 Agent 记住案情而非每次都重新理解、工具调用让 Agent 能核实信息而非全靠知识库。
如果说法学是一个"法条 × 事实 × 经验"的三元推理,V1.0 只解决了"事实 → 经验"这一条路径,V2.0 才补齐了另外两条。
| 层级 | V1.0 选型 | V2.0 升级 | 作用 |
|---|---|---|---|
| 工作流编排 | LangGraph StateGraph | LangGraph + Memory 路由 | 多阶段流转 + 条件回退 + 重试控制 |
| 结构化抽取 | LLM + Pydantic Output Parser | 同上 + Case Memory 跳过 | 口语化→结构化法律要素 |
| 法条检索 | ES 精确查询 | Law RAG + 知识图谱 (Neo4j) | 法条依据优先召回 |
| 标签过滤 | Elasticsearch | 同上 | 案由/要素筛选,千万级→万级 |
| 向量检索 | Qdrant + bge-m3 | 同上 | 语义相似度召回 |
| 初排 | 无 | CrossEncoder (bge-reranker-v2) | 低成本 50→20 过滤 |
| 精排 | LLM 看 50 个 → TOP 5 | LLM 看 20 个 → TOP 5 | 多维评分 |
| 联合推理 | 案例→策略建议 | 法条 + 案例 + MCP 工具联合推理 | 符合成文法体系 |
| 法条校验 | ES 精确查询 | + 图谱变更追踪 | 确保法条版本准确 |
| 跨会话记忆 | 无 | DuckDB Case Memory | 同案件多轮对话不重复抽取 |
| 外部工具 | 无 | MCP Tool Layer | 企业查询/法院公告/律师库 |
| Guardrail | LangGraph Condition + 规则 | 同上 + 法条版本校验 | 三层校验链 |
几个关键决策:
-
1. 用 LangGraph 而不是 Chain,因为流程带环(反问回退、重试放宽)
-
2. 先 ES 标签过滤再 Qdrant 向量检索,而不是全库向量搜索
-
3. 裁判文书必须预处理提取,不能用原文 Embedding(超过 512 token 质量下降)
-
4. 精排加一层 CrossEncoder 做初排,LLM 只看 20 个,成本降低 60%
-
5. 法条召回优先于案例召回——中国是成文法系,不是判例法
-
6. 法条引用用精确查询校验,不用向量检索;图谱追踪法条版本变更
-
7. Guardrail 是代码逻辑,不是说一句"仅供参考"
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)