【Loop Engineering】当我们不再手写 Prompt,而是设计 AI 的工作闭环
Loop Engineering 实战:从 Prompt 技巧到可验证的 AI Agent 工作闭环
文章目录
一、问题背景:为什么只会写 Prompt 已经不够了
过去两年,很多 AI 编程实践都围绕 Prompt 展开:
- 怎么把需求写清楚;
- 怎么补充上下文;
- 怎么让模型先分析再写代码;
- 怎么约束输出格式;
- 怎么让模型少犯明显错误。
这些能力仍然重要,但它们默认了一个前提:人始终站在循环中心。
例如让 AI 修复一个测试失败的问题时,传统流程通常是:
- 人复制失败日志给 AI;
- AI 给出修改建议;
- 人判断是否合理;
- 人应用修改;
- 人重新跑测试;
- 失败后再把新日志发给 AI;
- 人决定继续、回滚或停止。
当任务很小,这种方式可以接受。但当任务变成“持续扫描 PR”“每天修复文档失效链接”“自动补测试”“根据 CI 失败生成修复建议”时,瓶颈不再是某一轮 Prompt 写得好不好,而是:
- 谁来触发下一轮;
- 每一轮读取哪些上下文;
- 允许 Agent 做哪些动作;
- 如何判断动作是成功还是失败;
- 什么时候必须停止并交给人。
这就是 Loop Engineering 要解决的问题。
二、分析:什么是 Loop Engineering
Loop Engineering 可以定义为:
为 AI Agent 设计一个可持续运行、可验证、可停止的工作闭环,而不是依赖人一轮一轮手动提示。
它关注的不是“让 AI 多跑几轮”,而是把多轮工作背后的控制逻辑显式设计出来。
一个最小 Loop 可以表示为:
Trigger 触发
↓
Context 读取上下文
↓
Action 执行动作
↓
Verification 验证结果
↓
Decision 判断继续、重试、升级或停止
Prompt Engineering 关注单次交互质量,Loop Engineering 关注系统闭环质量。前者决定“这一轮答得怎么样”,后者决定“整个任务会不会失控、能不能复现、什么时候结束”。
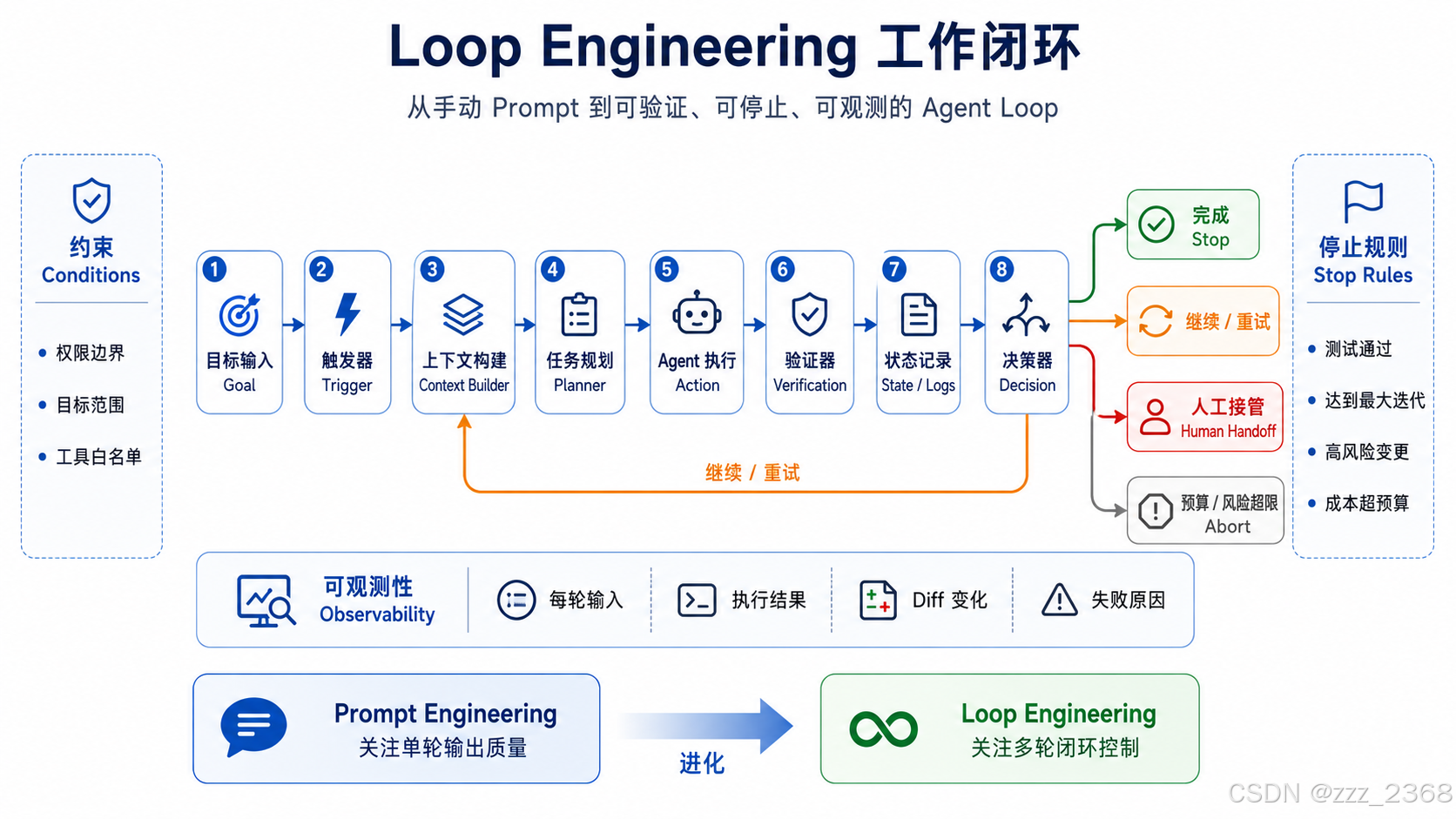
三、一个合格 Loop 的五个组成部分
1. Trigger:什么时候启动
Loop 不能随便启动,它必须有明确触发条件。
常见触发方式包括:
| 触发方式 | 示例 | 风险 |
|---|---|---|
| 定时触发 | 每天 9 点检查项目状态 | 可能处理过期上下文 |
| 事件触发 | PR 创建后自动 Review | 可能在权限不足时误操作 |
| 状态触发 | CI 失败后进入修复流程 | 可能反复处理同一个失败 |
| 人工触发 | 开发者输入目标后启动 | 依赖人的目标描述质量 |
一个没有 Trigger 的 Agent 只是聊天窗口;有了 Trigger,它才开始像一个工程系统。
2. Context:每一轮读什么
Agent 每次行动前都需要知道当前状态,但上下文不是越多越好。
CI 修复类 Loop 通常需要读取:
- 失败日志;
- 相关测试文件;
- 相关源码;
- 最近一次改动;
- 项目运行命令;
- 上一次 Loop 的执行记录。
不应该默认读取:
- 与当前失败无关的全仓库文件;
- 历史很久的旧日志;
- 包含密钥或账号的配置;
- 未经确认的大型二进制文件。
上下文选择错误会带来两个问题:一是模型被噪声干扰,二是敏感信息被带入不该进入的执行链路。
3. Action:这一轮允许做什么
Action 是 Agent 真正执行的部分,但它不等于“自动改代码”。
成熟的 Loop 应该把动作分级:
| 动作级别 | 允许行为 | 是否需要人工确认 |
|---|---|---|
| 只读 | 读取日志、总结问题、生成报告 | 通常不需要 |
| 低风险写入 | 修改测试、文档、局部代码 | 视项目规则决定 |
| 中风险写入 | 改业务逻辑、改依赖、改构建配置 | 建议需要 |
| 高风险操作 | 删除文件、改权限、改数据库、发布上线 | 必须需要 |
如果一个 Loop 没有动作边界,就很容易从“自动辅助”变成“自动破坏”。
4. Verification:如何判断做得对
Verification 是 Loop Engineering 的质量上限。
常见验证器包括:
- 单元测试是否通过;
- 类型检查是否通过;
- Lint 是否通过;
- 构建是否成功;
- Diff 是否超出范围;
- 是否修改了禁止目录;
- 是否引入敏感信息;
- 输出是否回答了原始目标。
没有 Verification 的 Loop,本质上只是“让 AI 自动跑”。它可能完成任务,也可能把错误自动放大。
5. Stop Rule:什么时候停止
Loop 最危险的地方不是做不了事,而是停不下来。
建议至少设计以下停止条件:
- 目标完成,停止;
- 测试通过,停止;
- 达到最大迭代次数,停止;
- 连续失败 N 次,停止;
- 修改范围超过阈值,停止;
- 触及高风险文件,停止;
- 成本超过预算,停止;
- 验证结果无法解释,停止并交给人。
Stop Rule 不是附加功能,而是安全边界。
四、可复现最小实验:自动修复一个测试失败
下面用一个最小 Python 示例验证 Loop 控制器的核心逻辑。这个示例不模拟完整大模型能力,只验证四件事:
- 能读取失败状态;
- 能执行一次最小修复;
- 能重新运行验证;
- 能在验证通过后停止。
1. 项目结构
loop_demo_project/
calculator.py
test_calculator.py
loop_demo.py
初始代码故意写错:
# calculator.py
def add(a, b):
return a - b
测试用例:
# test_calculator.py
from calculator import add
def test_add():
assert add(2, 3) == 5
2. Loop 控制器代码
import pathlib
import subprocess
import sys
ROOT = pathlib.Path(__file__).parent / "loop_demo_project"
SRC = ROOT / "calculator.py"
TEST = ROOT / "test_calculator.py"
MAX_ATTEMPTS = 3
def prepare_project() -> None:
ROOT.mkdir(exist_ok=True)
SRC.write_text(
"def add(a, b):\n"
" return a - b\n",
encoding="utf-8",
)
TEST.write_text(
"from calculator import add\n\n"
"def test_add():\n"
" assert add(2, 3) == 5\n",
encoding="utf-8",
)
def run_tests() -> subprocess.CompletedProcess[str]:
return subprocess.run(
[sys.executable, "-m", "pytest", "-q"],
cwd=ROOT,
text=True,
capture_output=True,
)
def apply_minimal_fix() -> None:
content = SRC.read_text(encoding="utf-8")
SRC.write_text(content.replace("return a - b", "return a + b"), encoding="utf-8")
def main() -> int:
prepare_project()
for attempt in range(1, MAX_ATTEMPTS + 1):
result = run_tests()
print(f"[attempt {attempt}] exit_code={result.returncode}")
print(result.stdout.strip())
if result.returncode == 0:
print("STOP: verification passed")
return 0
if attempt == 1:
print("ACTION: apply minimal fix to calculator.add")
apply_minimal_fix()
else:
print("STOP: failed after retry, escalate to human")
return 1
print("STOP: max attempts reached")
return 1
if __name__ == "__main__":
raise SystemExit(main())
3. 本地验证结果
执行命令:
python work/loop_demo.py
实际输出:
[attempt 1] exit_code=1
F [100%]
================================== FAILURES ===================================
__________________________________ test_add ___________________________________
def test_add():
> assert add(2, 3) == 5
E assert -1 == 5
E + where -1 = add(2, 3)
test_calculator.py:4: AssertionError
=========================== short test summary info ===========================
FAILED test_calculator.py::test_add - assert -1 == 5
1 failed in 0.12s
ACTION: apply minimal fix to calculator.add
[attempt 2] exit_code=0
. [100%]
1 passed in 0.01s
STOP: verification passed
这个实验能说明三个关键点:
- Loop 不是无限重试,而是在
MAX_ATTEMPTS内运行; - Action 不是随意改动,而是一次可解释的最小修改;
- Stop Rule 由测试结果触发,而不是由模型自称“已经修好”触发。
五、把最小实验扩展到真实 Coding Agent
真实项目里,apply_minimal_fix() 不会是简单字符串替换,而是调用 Coding Agent 生成补丁。但控制器的骨架不应该变:
读取失败日志
↓
定位相关文件
↓
生成候选修复
↓
应用最小补丁
↓
运行验证命令
↓
检查 Diff 范围
↓
通过则总结,失败则重试或升级
推荐把真实 Loop 拆成三层:
| 层级 | 职责 | 不应该做的事 |
|---|---|---|
| 控制层 | 决定触发、上下文、重试、停止 | 直接相信模型结论 |
| Agent 层 | 生成分析、补丁、说明 | 绕过验证器直接提交 |
| 验证层 | 运行测试、检查 Diff、安全扫描 | 用主观判断替代命令结果 |
这样设计的好处是:即使 Agent 生成了错误补丁,验证层也能拦住;即使验证失败,控制层也能限制重试次数并升级给人。
六、Loop Engineering 和 Agent Harness 的关系
可以把 Agent Harness 理解为承载 Agent 的运行外壳,把 Loop Engineering 理解为这个外壳里的控制策略。
Agent Harness 常见能力包括:
- 工具调用;
- 文件读写;
- Shell 执行;
- 浏览器操作;
- 权限控制;
- 日志记录;
- 人工确认。
Loop Engineering 关注的是:
- 什么时候调用这些能力;
- 每次调用前后如何记录状态;
- 什么结果算成功;
- 什么风险必须中断;
- 哪些情况交给人。
两者关系可以概括为:Harness 提供能力,Loop 决定能力如何被组织成可靠流程。
七、生产环境必须补上的安全边界
如果要把 Loop 放进真实研发流程,至少要补上以下边界。
1. 文件边界
明确允许修改和禁止修改的路径。
示例:
allow:
- src/**
- tests/**
- docs/**
deny:
- .env
- secrets/**
- migrations/**
- infra/**
如果 Loop 触及 deny 路径,应立即停止并请求人工确认。
2. Diff 边界
限制单轮改动范围。
例如:
- 单轮修改不超过 5 个文件;
- 单轮新增代码不超过 300 行;
- 不允许删除测试;
- 不允许修改锁文件,除非任务明确要求。
Diff 边界可以避免 Agent 为了修一个小问题引入大面积不确定改动。
3. 成本边界
长期运行的 Loop 必须限制成本:
- 最大迭代次数;
- 最大运行时间;
- 最大 Token 消耗;
- 最大工具调用次数;
- 失败后冷却时间。
没有成本边界的 Loop 很容易在同一个问题上反复消耗资源。
4. 人工升级边界
以下情况建议直接交给人:
- 测试失败原因不稳定;
- 修复需要改业务规则;
- 需要删除数据或迁移数据库;
- 需要改认证、支付、权限、加密逻辑;
- Agent 给出的解释和测试结果不一致;
- 连续两轮修改没有缩小失败范围。
人工升级不是 Loop 失败,而是工程系统的一部分。
八、如何判断一个 Loop 是否合格
可以用下面这张表做评审:
| 检查项 | 合格标准 |
|---|---|
| Trigger | 启动条件明确,不会无意义反复触发 |
| Context | 只读取任务相关信息,敏感信息有过滤 |
| Action | 动作有权限分级,高风险操作需确认 |
| Verification | 有命令、测试、Diff 或规则验证 |
| Stop Rule | 有完成、失败、超时、成本和风险停止条件 |
| Record | 每轮有日志,能复盘为什么继续或停止 |
| Escalation | 无法判断时能交给人,而不是继续猜 |
如果一个 Agent 流程只能回答“它做了什么”,但回答不了“为什么继续、为什么停止、凭什么判断成功”,它还不能算成熟的 Loop。
九、常见误区
误区 1:Loop Engineering 等于让 AI 自动改代码
不是。自动改代码只是 Action 的一种。很多高价值 Loop 只做只读分析,例如每天总结失败 CI、给 PR 标注风险、扫描文档过期链接。
误区 2:多跑几轮就是 Loop
不是。没有验证器和停止规则的多轮执行,只是重复调用模型。
误区 3:测试通过就一定可以合并
不是。测试通过只能证明已覆盖场景没有失败,还需要检查 Diff、风险路径、需求一致性和人工审核规则。
误区 4:上下文越多越好
不是。上下文越多,噪声、过期信息和敏感信息进入决策链路的概率越高。
十、结论
Prompt Engineering 仍然重要,但它解决的是单轮表达问题。Coding Agent 真正进入研发流程后,更关键的是 Loop Engineering:
- 用 Trigger 管理启动;
- 用 Context 管理输入;
- 用 Action 管理能力;
- 用 Verification 管理正确性;
- 用 Stop Rule 管理风险;
- 用 Record 和 Escalation 管理复盘与人工接管。
未来 AI 工程能力的分水岭,不只是“谁更会写 Prompt”,而是谁能把 AI 组织进一个可验证、可停止、可复盘的工程闭环。
不要把 Loop 设计成失控的自动化。一个好的 Loop 应该像一个谨慎的初级工程师:能做小步修改,能跑验证,知道何时停下,也知道什么时候必须请人判断。
参考资料
- Python 官方文档:
subprocess.run,用于说明示例中如何调用外部测试命令并读取退出码。 - pytest 官方文档:Get Started,用于说明示例中
pytest -q这类最小测试验证方式。
感谢阅读,记得点赞、关注、收藏,欢迎各位评论区交流!!!

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)