从聊天经验到工程规范:AI Agent 的规则回流机制
文档治理不是“多写文档”,而是让不同文档承担正确职责,并形成两个清晰流向。
一、Agent 读取流向

Agent 工作时,不应该一上来读取一大堆长文档,而应该按“渐进式披露”的方式获取上下文:
CLAUDE.md / AGENTS.md ↓docsspec.md
其中:
-
CLAUDE.md/AGENTS.md:入口和路由,告诉 Agent 该读什么、遵守什么; -
docs/**:跨 feature 复用的公共知识,比如架构、API 规范、日志规范、并发规范; -
constitution.md:项目宪法,沉淀长期不可违反的原则; -
spec.md:单个 feature 的事实、GAP、目标、范围、方案概述,是执行前的上下文边界定义。
这里有一个关键判断: 从文档治理视角来看,读取流向到 ***spec.md*** 就可以收敛了。
因为:
-
spec.md和plan.md本质上都属于执行阶段文档; -
它们更多是“如何做这件事”,而不是“项目长期规范是什么”;
-
后续的
plan.md、design、tasks等内容,属于具体任务执行过程,而不是规范体系的一部分。
核心原则是: 入口文档不要膨胀,规范文档不要混入执行细节,feature 文档不要承载项目级规则。
二、规则回流流向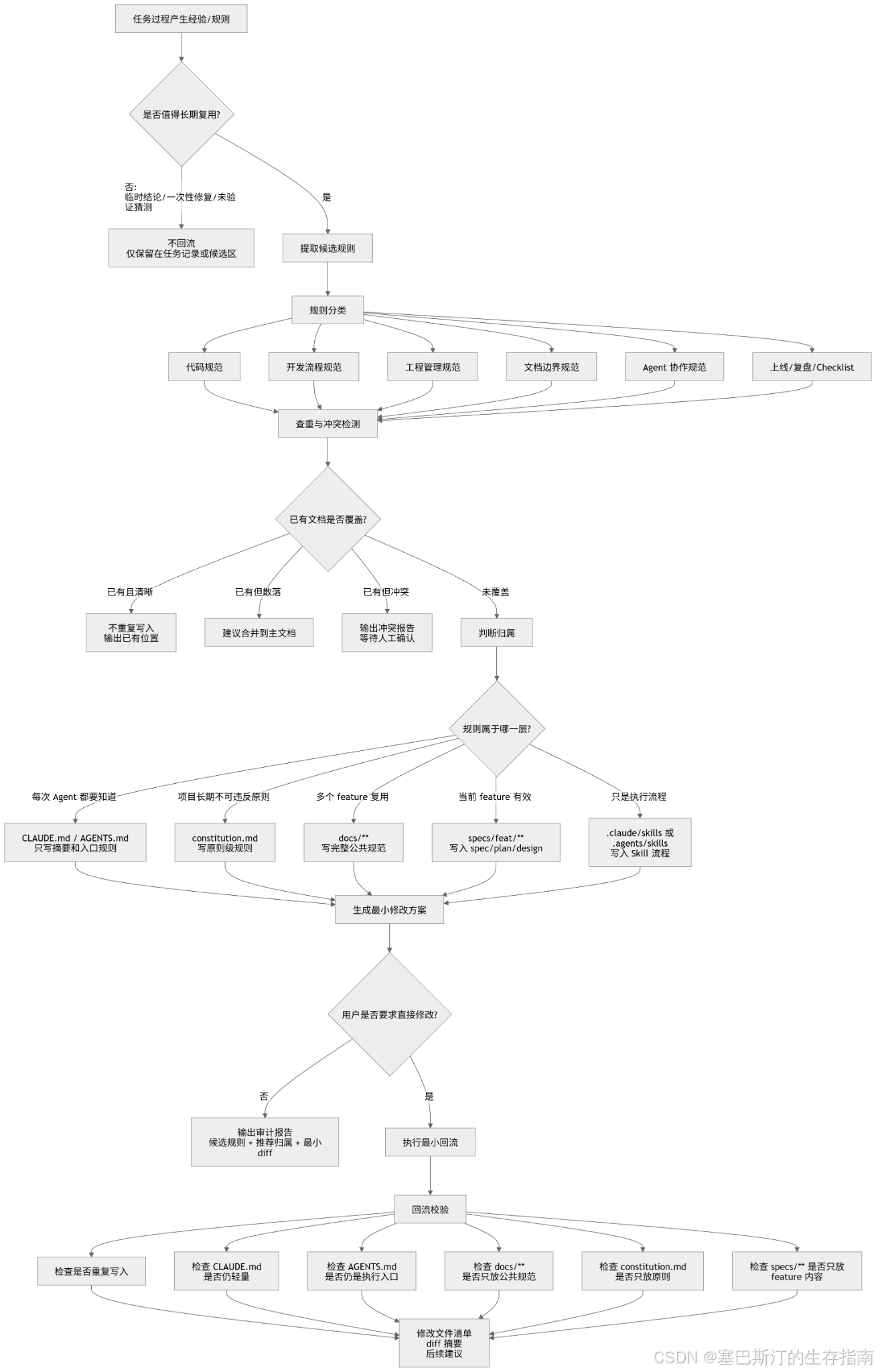
另一个更重要的流向,过程纠偏/任务结束后如何沉淀规则?
一次调研、一次代码 review、一次上线复盘,都会产生很多经验。但这些经验不能随便塞进 CLAUDE.md,也不能散落在聊天记录里。
更合理的做法是:
任务经验 / Review 结论 / 复盘问题 ↓提取候选规则 ↓判断是否长期有效 ↓查重与冲突检测 ↓判断文档归属 ↓回流到正确位置
归属可以这样判断:
每次 Agent 都要知道的 -> CLAUDE.md / AGENTS.md长期不可违反的原则 -> constitution.md多个 feature 复用的规范 -> docs/**单个 feature 有效的内容 -> specs/feat/**还没验证清楚的 -> 先放候选,不回流
这里同样有一个边界需要明确:
-
spec.md可以承载“当前 feature 的事实与决策”; -
但不应该承载“项目级规范”;
-
更不应该成为规则沉淀的主要位置。
比如一次 OCR 稳定性排查后,沉淀出:
OCR 调用必须具备 traceId、超时、重试分类和并发边界。
这条规则不应该完整塞进 CLAUDE.md。
更合理的归属是:
### 一、Agent 读取流向
- `constitution.md`:核心链路必须具备可观测性和容量边界;
- `docs/standards/logging-standard.md`:traceId、reviewId、attemptNo、durationMs、errorType 等日志规范;
- `docs/architecture/concurrency.md`:OCR 并发边界、Semaphore、RateLimiter、无界队列风险;
- `CLAUDE.md` / `AGENTS.md`:只保留一句入口提醒,涉及 OCR、并发、日志改动时必须阅读对应规范。
三、几个职责区的压缩总结
入口负责路由。docs 负责公共知识。constitution 负责原则。spec 负责需求边界(执行前上下文)。plan / design / tasks 属于执行过程,不属于规范体系。skill 负责复用流程。
这套结构背后的目标不是“让文档更多”,而是让 Agent 和人都能更稳定地协作:
-
新任务开始时,知道从哪里读上下文;
-
任务推进时,知道哪些内容写到哪里;
-
任务结束后,知道哪些经验值得回流;
-
后续 Agent 再执行类似任务时,不会重复犯错。
我理解这是 AI Agent 工程化里很关键的一步: 从一次性对话,走向可沉淀、可复用、可治理的项目知识系统。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)