Agentic Skill Routing 实战:别再把所有 Skill 塞进 AI Agent 上
Skill listing 的真实成本:不是 token 数字那么简单

图:高频 Skill 留在工作台,长尾能力进入可检索冷存储
Skill 的一个核心设计是渐进式加载。默认只把 metadata 放进上下文,真正的操作步骤、示例、脚本和参考资料等到触发后再读。这比把完整插件说明常驻上下文要合理得多。
但 metadata 也不是免费的。
常见 Skill 文件大概长这样:
skills/
lark-doc/
SKILL.md # metadata + body
references/
scripts/
lark-mail/
SKILL.md
code-review/
SKILL.md
SKILL.md 通常分成两层:
- frontmatter / metadata:name、description、tags、适用场景,默认参与路由。
- body:完整流程、注意事项、命令示例、错误处理,命中后再读。
这套结构在几十个 Skill 时很好用。到了几百个甚至几千个 Skill,麻烦开始出现。
第一,宿主通常会给 Skill listing 设置固定预算。预算超了怎么办?只能截断 description,甚至只保留 name。一个本来写得很清楚的“飞书文档读取、更新、图片插入与权限处理”,被截成“飞书文档读…”,路由质量自然会掉。
第二,Skill 数量越多,语义相似项越多。lark-doc、lark-wiki、lark-drive、lark-sheets 都和“飞书文件”有关;stock-analysis、china-stock-analysis、us-stock-analysis 都和股票有关。模型看到一堆短描述时,很容易被表面词拉走。
第三,常驻 listing 会让低频 Skill 持续占预算。一个一年用三次的 Skill,只要 enabled,就和每天都会用的 Skill 站在同一个上下文入口里。这对个人环境还能忍,对团队级 Skill 目录就不太现实了。
所以,Skill 管理的核心矛盾不是“怎么把所有 Skill 介绍得更短”,而是:哪些 Skill 应该常驻?哪些 Skill 应该退出上下文,但仍然能被找回?
被动 Top-K 路由为什么不够
一个自然反应是做检索。把 Skill 的 name、description、body 建索引;用户请求来了,embedding 召回 Top-K,再交给 reranker 或 LLM 选一个。
这条路当然能做,而且很多场景有效。但它有两个工程代价。
先说模型依赖。embedding、reranker、向量库、索引刷新、版本兼容,这些东西对平台团队不是大问题,对本地 Agent 用户和小团队就是额外负担。Skill 本来是为了降低使用门槛,最后又引入一套检索基础设施,味道有点不对。
再说交互形态。传统 Top-K 本质上是一次性函数调用:用户 query 进去,候选列表出来,Agent 只能消费结果。如果第一轮 query 抽错了词,或者候选里两个 Skill 很接近,Agent 很难像人一样“换个词再搜一下”“打开两个候选看看证据”“不确定就不要选”。
这就是被动检索的限制。它把 Agent 放在消费者位置,而不是搜索过程的操作者。
Agentic Search 的关键变化:让模型控制检索过程
Agentic Search 不神秘。它只是把搜索从“一次返回答案”改成“多步收集证据”。
一个更适合 Agent 的检索接口,至少要允许它做四件事:
- 从当前任务里抽关键词,而不是原样拿用户句子去搜。
- 看见候选为什么被召回,包括命中的字段、片段、分数和是否截断。
- 对少量候选做进一步检查,但不要一下子把全文全倒出来。
- 在证据足够时选择,在证据不足时停止或继续搜索。
这和近两年 Agentic RAG、Direct Corpus Interaction、grep-style harness 的讨论是一条线:检索器不再只是黑盒排序器,而是 Agent 可以操作的外部环境。
放到 Skill 管理里,思路会变成这样:

图:Agent 在 enabled Skill 与 metadata corpus 之间按证据路由
这里有一个边界很重要:select 之前,只看 metadata,不读被禁用 Skill 的 body。
这不是洁癖,而是上下文控制。搜索阶段如果每个候选都打开完整说明,Skill router 很快会退化成另一个上下文黑洞。metadata 足够时就选;metadata 不够时,最多检查少量候选;仍然不够,就承认低置信,而不是硬选一个看起来顺眼的。
禁用不是删除:低频 Skill 应该进入冷存储
Skill 管理里最容易被误解的是 disable。
很多人听到禁用,会以为能力消失了。更合理的理解是:禁用只是让它退出常驻 listing。文件还在,metadata 还在,路径还在,使用记录也可以继续记录。它只是从“每天站在上下文门口”变成“需要时可以被查到”。
这有点像内存和磁盘的关系。高频、基础、系统级 Skill 留在内存里;长尾 Skill 放到磁盘上。Agent 不应该每次启动都把整块磁盘读进上下文,它应该有一套索引和读取协议。
一个可维护的 Skill 冷存储,至少需要这些东西:
| 组件 | 作用 | 需要避免的问题 |
|---|---|---|
| metadata corpus | 保存 disabled Skill 的可检索字段,例如 name、description、aliases、tags、tools、domains、intents、examples | description 太短、字段缺失、同质 Skill 没有区分度 |
| stable ref | 用稳定引用指向候选,而不是直接把本地路径暴露给模型 | 路径泄露、路径变化、候选不可复现 |
| inspect 接口 | 允许 Agent 对少量候选查看更多 metadata | 一次性输出过多,重新制造上下文压力 |
| select 记录 | 把“为什么选它”写成可审计事件 | 路由不可追踪,后续无法优化 |
| restore 机制 | 能把 disabled Skill 恢复为 enabled | 禁用变成破坏性操作 |
这样处理后,Skill 数量增长带来的压力就不再线性压到上下文里。上下文里常驻的是少量高频 Skill,加一个 router 入口;长尾 Skill 通过 metadata corpus 被按需找回。
三个 primitive:search、inspect、select
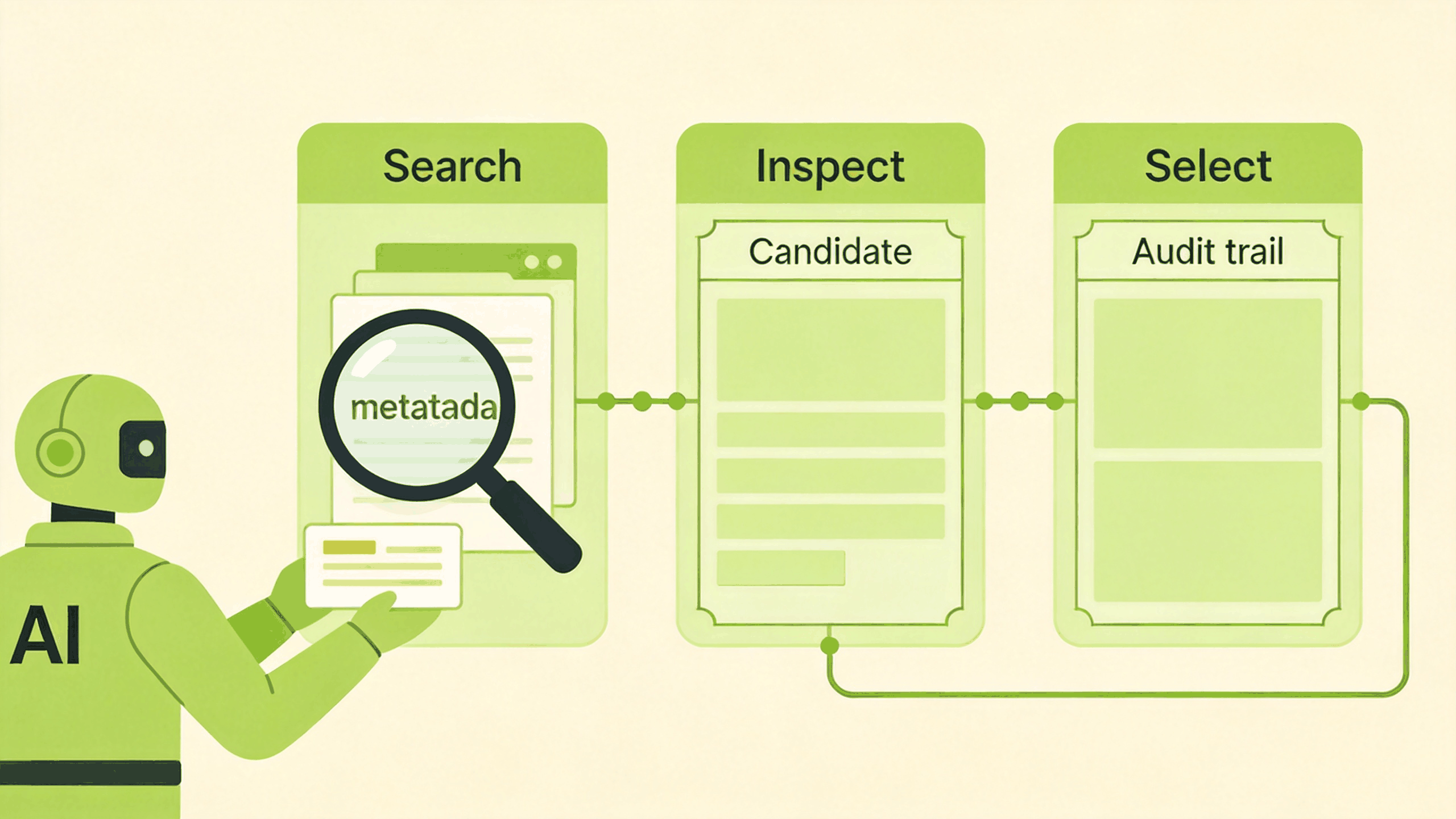
图:Agent 通过 search、inspect、select 逐步收集路由证据
我更倾向于把 Skill 路由拆成三个小工具,而不是做一个“一步到位”的 routeSkill(query)。
corpus search:低成本召回
search 接收 Agent 抽出来的关键词,返回一组候选。这里最好区分 must terms 和 probe terms。
比如用户说“读取飞书 docx 并提取第一章”,must terms 可以是 lark、docx,probe terms 可以是 document、fetch、extract。search 返回的不是最终答案,而是候选证据:ref、score、matched terms、description snippets、totalMatches、returned、truncated。
truncated 这个字段很有用。它告诉 Agent:当前 query 太宽了,候选被截断了,需要换词或加约束。没有这个信号,模型会误以为返回列表就是全部世界。
corpus inspect:只检查少量候选
inspect 用来处理“几个候选都像”的情况。它可以返回更完整的 metadata,例如 aliases、tags、tools、domains、intents、examples,但仍然不读 body。
这一步的重点是有界。不要让 Agent 一口气 inspect 50 个候选。通常 2-5 个就够了。Skill 路由不是信息检索比赛,它只是要帮当前任务找到一个能执行的能力入口。
corpus select:把选择变成记录
select 是闭环动作。Agent 必须给出 ref/id、原始 query、confidence 和 reason。CLI 再把 ref 解析成真实 disabled Skill,记录一次 routed use,最后返回 selected.skillMdPath。
这样做有两个好处。
第一,模型不能直接拿搜索结果里的路径乱读。第二,所有选择都有审计记录。以后你想知道哪些 disabled Skill 其实经常被找回,哪些从来没有被选中过,就有数据可看。
一个典型调用流程可以设计成这样:
agentic-skill-router skills corpus search \
--all "lark" \
--any "docx" \
--any "document" \
--any "extract" \
--limit 30 \
--json
agentic-skill-router skills corpus inspect corpus-xxx corpus-yyy --json
agentic-skill-router skills corpus select "corpus-xxx" \
--query "读取飞书 docx 并输出第一章" \
--confidence high \
--reason "metadata covers Lark docx fetching and document content extraction" \
--json
这个接口不炫,但边界清楚。Agent 负责判断,CLI 负责索引、分页、ref、JSON schema、缓存和选择记录。
Bash 直接搜文件,为什么不适合作为默认产品边界
如果只看研究验证,直接让 Agent 用 shell 搜本地 Skill 目录很诱人。find、grep、sed、awk 足够强,模型也能临场组合很多策略。中小规模目录里,这种 DCI 风格的做法甚至会非常准。
但它不适合当默认产品形态。
原因不是 bash 不强,而是太自由。今天模型写 grep -R,明天写 find | xargs,后天又加 head -20。路径里有空格怎么办?文件太多触发 ARG_MAX 怎么办?候选被 head 截掉怎么办?输出太长撑爆上下文怎么办?这些问题最后都会落到 prompt 里,prompt 越写越像一段脆弱的 shell 教程。
Tool-wrapped 的优势就在这里。把容易犯错的部分收到 CLI:路径枚举、缓存、索引、分页、截断提示、候选引用、schema 校验。Agent 还在做主动搜索,但它不必每次临场写一段不稳定的 pipeline。
换句话说,bash 适合调试 failure case,适合做研究对照;默认路径最好还是稳定 primitive。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)