Agent = Model + Harness:决定 AI 智能体上限的,往往不是模型而是“装具”
换了更贵的模型、调了无数版 Prompt,Agent 还是不好用?一线团队的实践告诉我们:决定智能体上限的,往往不是模型推理能力,而是你为它搭建的那套“工作环境”。本文用可复现的代码,讲透 Harness Engineering(装具工程)的核心思路与落地方法。
前言
在 AI Agent 领域,有一个反复被印证的规律:很多时候 Agent 表现差,锅不该让模型来背。
有一个非常著名的实验现象:针对同一个大模型,仅仅改变了它调用文件编辑接口的方式,其在编码基准测试中的得分就从 6.7% 暴增到 68.3%。模型本身一行没改,变的是它外部的系统——这就是 Harness Engineering(装具工程) 的威力。
很多开发者在 Agent 表现不佳时,第一反应是换更贵的模型,或者疯狂调 Prompt。但一线团队的实践证明:决定 Agent 表现上限的,往往不是模型推理能力,而是你为模型搭建的这套“工作环境”。
读完本文你将收获:
- 理解
Agent = Model + Harness这个核心公式; - 掌握 Smart Zone / Dumb Zone 上下文理论,以及 Context Resets 的工程实现;
- 学会用一份“地图式”的
AGENTS.md约束 Agent; - 能够用机械化手段(Linter + 结构测试)强制 Agent 守规矩;
- 拿到一份可直接复用的六层装具架构与落地优先级。
背景或问题:为什么“升级模型”经常不管用?
先抛出三个很多开发者都遇到过的现象:
- 换了更强的模型,Agent 仍然跑偏:换了最新的旗舰模型,但该幻觉还是幻觉,该绕圈子还是绕圈子。
- 上下文越长越“笨”:塞进去越来越多的需求文档、历史对话,Agent 反而开始忘事、格式混乱、提前收工。
- Prompt 越写越长,收益却递减:加了无数约束、注意事项、Few-shot,模型依旧在某些规则上反复违反。
这三个现象的共同根源都不在模型,而在 Harness。我们先把概念理清。
核心思路:Agent = Model + Harness
如果把大模型比作 CPU,那么 Harness 就是 操作系统。CPU 运算速度再快,如果操作系统天天崩溃、驱动乱飞,用户体验依然糟糕。
由此可以推导出一个核心公式:
Agent = Model + Harness
- Model(模型):负责推理、生成和意图识别。它是“大脑”。
- Harness(装具):指模型之外的整套工程环境,包括系统提示词、工具调用机制、文件系统、沙箱、编排逻辑、反馈回路以及约束机制。
模型只负责“大脑”的思考,而 Harness 负责把模型放进一个 可执行、可观察、可恢复、可验证 的工作空间里。
理解了这一点,就能解释开头的那个实验:6.7% → 68.3% 的飞跃,不是模型变强了,而是装具变好了。 同样的“大脑”,换一套更好的“工作台”,产出天差地别。
一句话总结:Harness 里的每个组件,本质上都编码了一个假设——模型单独做不好什么。 Prompt 调优是给模型“说教”,Harness 工程是给模型“造车间”。
实现步骤
下面我们把 Harness Engineering 拆成几个可落地的工程模块,每个都配可复现的代码。
步骤一:破解“上下文焦虑”——Smart Zone 理论
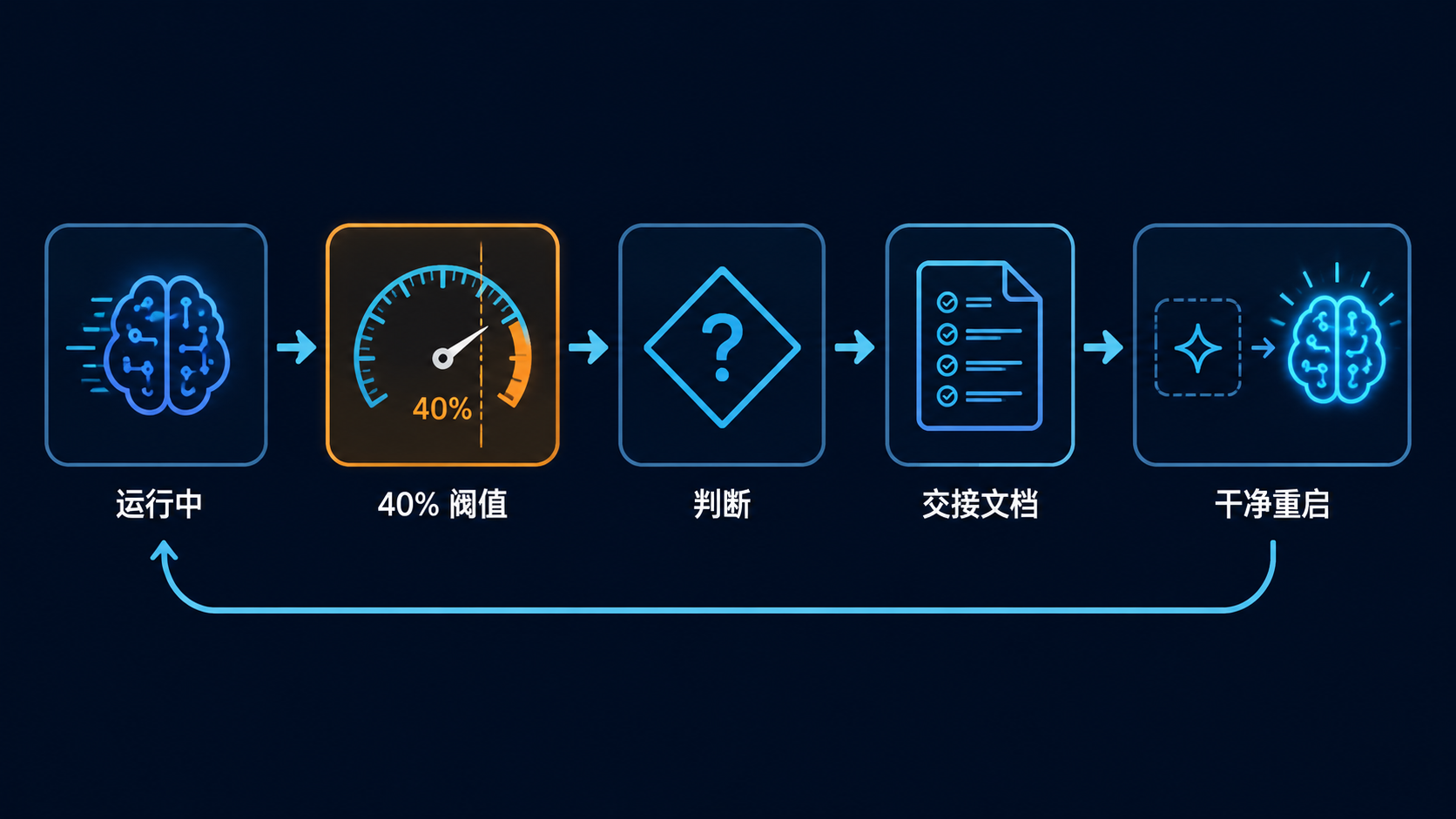
很多开发者迷信“长上下文”,认为 1M 甚至更长的窗口能解决所有问题。但实战中有一个残酷现象:168K 的上下文窗口,用到大约 40% 的时候,输出质量就会明显下降。
Dex Horthy 据此提出了 Smart Zone(聪明区)与 Dumb Zone(笨蛋区) 理论:
| 区间 | 上下文占比 | 典型表现 |
|---|---|---|
| Smart Zone | 0 ~ 约 40% | 推理聚焦、工具调用准确、代码质量高 |
| Dumb Zone | 超过约 40% | 幻觉增多、开始“绕圈子”、格式混乱 |
Anthropic 团队把这种现象称为 “上下文焦虑”:当上下文快填满时,强如顶级模型也会变得犹豫,甚至倾向于“提前收工”。
工程上的第一步,就是监控上下文利用率,别让 Agent 长时间待在 Dumb Zone。 下面是一个可复用的上下文占用监控示例(以 OpenAI SDK 的 token 计数为近似口径):
# context_monitor.py
# 上下文利用率监控:尽量把 Agent 保持在 Smart Zone(<= 40%)
from dataclasses import dataclass
@dataclass
class ContextWindow:
model_limit: int # 模型上下文窗口上限,例如 200_000
safe_ratio: float = 0.40 # Smart Zone 阈值,默认 40%
def used_ratio(used_tokens: int, cw: ContextWindow) -> float:
"""返回当前上下文利用率(0~1)。"""
return used_tokens / cw.model_limit
def should_reset(used_tokens: int, cw: ContextWindow) -> bool:
"""是否触发上下文重置。超过 Smart Zone 阈值即建议重置。"""
ratio = used_ratio(used_tokens, cw)
print(f"[ctx] 已用 {used_tokens}/{cw.model_limit} = {ratio:.1%}")
return ratio >= cw.safe_ratio
if __name__ == "__main__":
cw = ContextWindow(model_limit=200_000)
# 模拟一次长任务中累计消耗的 token
for used in [10_000, 70_000, 85_000]:
if should_reset(used, cw):
print("[ctx] ⚠️ 进入 Dumb Zone,建议执行 Context Reset!")
运行结果:
[ctx] 已用 10000/200000 = 5.0%
[ctx] 已用 70000/200000 = 35.0%
[ctx] 已用 85000/200000 = 42.5%
[ctx] ⚠️ 进入 Dumb Zone,建议执行 Context Reset!
避坑提示:不同模型对“长上下文衰减”的耐受度不同,40% 是经验阈值而非物理常数。建议在你的真实任务上跑一组基准(如固定用例集在不同上下文占用下的通过率),拟合出属于你自己业务的 safe_ratio。
步骤二:用 Context Resets + 结构化交接文档“重启”Agent
光监控还不够,进入 Dumb Zone 之后怎么办?Anthropic 的做法是 Context Resets(上下文重置):
当上下文接近饱和时,不只是简单压缩,而是 直接清空窗口,但通过一份 结构化交接文档 保留关键任务状态,再启动一个干净的 Agent 继续工作。
这就像进程遇到内存泄漏时重启并从检查点恢复——往往比带着沉重历史运行效果更好。

核心是那份“结构化交接文档”,它要能让新 Agent 无损接续。推荐结构如下:
# Handoff(交接文档)
## 任务目标
- 一句话目标:
- 验收标准(DoD):
## 当前进度
- 已完成:
- 进行中:
- 待处理:
## 关键决策与约束
- 架构约定:
- 不能违反的规则:
## 环境
- 工作目录:
- 运行命令:
- 依赖版本:
## 下一步动作
- 立刻要做的第一件事:
对应的编排伪代码(把“重置 + 交接”做成一个可复用函数):
# context_reset.py
# Context Reset 编排:生成交接文档 → 清空上下文 → 启动干净 Agent
from context_monitor import ContextWindow, should_reset
def build_handoff(state: dict) -> str:
"""把当前任务状态序列化为结构化交接文档。"""
template = """# Handoff(交接文档)
## 任务目标
- {goal}
## 当前进度
- 已完成:{done}
- 进行中:{doing}
- 待处理:{todo}
## 关键约束
- {constraints}
## 环境
- 工作目录:{cwd}
- 运行命令:{run_cmd}
## 下一步动作
- 立刻要做的第一件事:{next_step}
"""
return template.format(**state)
def run_agent_loop(task_state: dict, used_tokens: int, cw: ContextWindow):
"""Agent 主循环:检测到上下文焦虑时,重置并交接。"""
if should_reset(used_tokens, cw):
handoff_doc = build_handoff(task_state)
print("=== 生成交接文档 ===")
print(handoff_doc)
# 1. 清空历史上下文
# 2. 用 handoff_doc 作为新 Agent 的初始上下文
# 3. 启动一个干净的 Agent 继续工作
return "reset_done"
return "continue"
if __name__ == "__main__":
cw = ContextWindow(model_limit=200_000)
state = {
"goal": "给 RAG 检索模块补全单测,覆盖率 >= 80%",
"done": "检索器、重排序器单测完成",
"doing": "正在写 Prompt 模板单测",
"todo": "端到端集成测试、CI 配置",
"constraints": "禁止直连生产数据库,必须用 mock",
"cwd": "/project/rag-service",
"run_cmd": "pytest tests/ -q",
"next_step": "先补 tests/test_prompt.py 中模板渲染用例",
}
run_agent_loop(state, used_tokens=90_000, cw=cw)
关键点:交接文档是“检查点”,不是“聊天记录”。 只保留恢复任务所必需的结构化信息,丢掉冗余对话,新 Agent 才能轻装上阵。
步骤三:写一份“地图式”的 AGENTS.md
OpenAI 团队一年内人均 PR 数提升 10 倍,核心秘诀之一是他们对 Harness 的深度治理。其中非常关键的一条是:AGENTS.md 是“地图”,不是“说明书”。
OpenAI 的 AGENTS.md 文件只有约 100 行,作用更像一个 “目录”:它指向更深层的设计文档和执行计划,遵循 渐进式披露(Progressive Disclosure) 原则——先给 Agent 最关键的信息,需要细节时再引导它去翻阅特定子文档。这能有效避免 System Prompt 过长导致模型跑偏。
一个合格的“地图式” AGENTS.md 示例:
# AGENTS.md
本仓库是一个 RAG 检索服务。请在动手前先读下面的“地图”,按需查阅子文档。
## 你能在这里做什么
- 写业务代码、补单测、修 bug、做重构。
- 不要直接改生产配置;配置变更走 PR + 评审。
## 快速导航(按需阅读,不要一次全塞进上下文)
- 架构与设计:docs/architecture.md
- 编码规范:docs/coding-standards.md
- 如何跑测试:docs/testing.md
- 发布流程:docs/release.md
## 硬性约束(违反会被 Linter 拦截)
- 所有对外函数必须有类型标注。
- 新增依赖必须在 docs/dependencies.md 登记。
- 数据库访问必须经过 repository 层,禁止在 handler 里裸写 SQL。
## 任务流程
1. 先确认你要改的模块,去 docs/ 找对应文档读。
2. 改完后运行:make lint && make test。
3. 提 PR,标题用 [模块] 简述。
注意这里的两条工程纪律:
- 顶层只放“地图”:导航 + 硬性约束 + 流程,控制在 ~100 行。
- 细节下沉到子文档:Agent 需要时再
Read对应文件,避免一上来就把整个知识库塞进上下文,引发“上下文焦虑”。
这就是“地图而非说明书”的精髓:给方向,不给噪音。 一份动辄几千行的 System Prompt,往往是在给模型制造 Dumb Zone。
步骤四:机械化约束——Linter 与结构测试
OpenAI 团队坚信一句话:
“如果不能通过机械化手段强制执行,Agent 迟早会偏离轨道。”(If it cannot be enforced mechanically, agents will deviate.)
光写在 AGENTS.md 里的规则是不够的——模型会忘。正确做法是 编写自定义 Linter 和结构测试:当 Agent 的输出违反架构规范时,工具不只是报错,还会 直接给出修复指令。Agent 在修错的过程中,被自动“训练”得更符合团队规范。
下面演示一个最简单的“结构测试”:检查每个 Python 模块是否都有类型标注、是否避免了在 handler 层裸写 SQL(架构分层约束)。
# tests/test_structure.py
# 结构测试:用机械化手段强制 Agent 守规矩
import ast
from pathlib import Path
def _parse(path: Path) -> ast.Module:
return ast.parse(path.read_text(encoding="utf-8"))
def test_public_functions_have_type_hints():
"""硬性约束1:对外函数必须有返回类型标注。"""
offenders = []
for py in Path("src").rglob("*.py"):
tree = _parse(py)
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef) and not node.name.startswith("_"):
if node.returns is None:
offenders.append(f"{py}:{node.lineno} {node.name}() 缺少返回类型")
assert not offenders, "修复指令:给以下函数补全类型标注 -> \n" + "\n".join(offenders)
def test_no_raw_sql_in_handlers():
"""硬性约束2:handler 层禁止裸写 SQL,必须走 repository 层。"""
banned = {"execute", "executemany"}
offenders = []
for py in Path("src/handlers").rglob("*.py"):
tree = _parse(py)
for node in ast.walk(tree):
if (isinstance(node, ast.Attribute) and node.attr in banned) or (
isinstance(node, ast.Call)
and isinstance(node.func, ast.Name)
and node.func.id == "cursor"
):
offenders.append(f"{py}:{node.lineno} handler 中出现裸 SQL,请改走 repository 层")
assert not offenders, "修复指令:\n" + "\n".join(offenders)
运行:
pytest tests/test_structure.py -q
关键设计:断言失败信息不是干巴巴的报错,而是“修复指令”。 这正是 Harness 的精髓——把规范变成可执行、可反馈的闭环。Agent 跑测试 → 失败 → 读到修复指令 → 自动改正,循环往复就被“焊”进规范里。
进阶:把这类结构测试接进 CI(或 Agent 自检循环),任何偏离架构的 PR 会被 机械性拦截,而不是靠人 review。
步骤五:给 Agent 接入“自验证”能力
一个常见的翻车场景:Agent 写完代码,自认为没问题,实际一跑全是 bug。原因是它没有 验证手段。解决办法是 给 Agent 接入验证工具,让它像用户一样去操作运行中的应用。
例如用 Playwright 这类浏览器自动化工具,让 Agent 自己点开页面、截图、断言关键元素是否渲染:
# verify_ui.py
# 给 Agent 的自验证能力:跑起来后自己去页面验证
from playwright.sync_api import sync_playwright
def verify_login_page(url: str) -> bool:
"""Agent 写完登录页后,自己跑这段验证是否真的能用。"""
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url)
# 1. 关键元素是否存在
assert page.locator("input[name='username']").count() == 1, "缺少用户名输入框"
assert page.locator("input[name='password']").count() == 1, "缺少密码输入框"
assert page.locator("button[type='submit']").count() == 1, "缺少提交按钮"
# 2. 走一遍真实交互
page.fill("input[name='username']", "demo")
page.fill("input[name='password']", "demo123")
page.click("button[type='submit']")
page.wait_for_url("**/dashboard", timeout=5000)
browser.close()
return True
if __name__ == "__main__":
ok = verify_login_page("http://localhost:3000/login")
print("✅ 页面自验证通过" if ok else "❌ 页面自验证失败")
原则:能跑就不要“猜”。 让 Agent 把“我觉得没问题”升级成“我跑过了,断言通过”。这就是 Harness 里 可验证(verifiable) 这一层的价值。
步骤六:定期“垃圾回收”
AI 生成代码速度极快,副作用是 系统熵增:冗余文件、不一致文档、无人调用的函数会快速堆积。成熟的 Harness 会安排一个 后台 Agent 定期扫描并清理,防止熵增拖垮整个项目。
一个极简的“垃圾回收”巡检脚本思路(实际工程中由定时任务 / 后台 Agent 驱动):
# gc_scan.py
# 定期扫描冗余与不一致,交给 Agent 或人确认清理
import ast
from pathlib import Path
def find_unused_public_funcs() -> list[str]:
"""找出定义了但全仓库无人调用的对外函数(候选清理项)。"""
root = Path("src")
defs, calls = set(), set()
for py in root.rglob("*.py"):
tree = ast.parse(py.read_text(encoding="utf-8"))
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef) and not node.name.startswith("_"):
defs.add(node.name)
if isinstance(node, ast.Call) and isinstance(node.func, ast.Name):
calls.add(node.func.id)
return sorted(defs - calls)
if __name__ == "__main__":
unused = find_unused_public_funcs()
print("垃圾回收候选(未被调用的对外函数):")
for name in unused:
print(f" - {name}")
把这类扫描做成周期性任务,产出“候选清理清单”交人或 Agent 确认,就能把熵增控制在可接受范围内。
完整方案:六层装具架构与落地优先级
根据 OpenAI 和 Anthropic 的实战经验,一个成熟的 Harness 通常包含 六层架构,从基础的信息边界(L1)到最高级的约束与恢复(L6):
[!image-placeholder]
正文图 2:六层装具架构示意图,自下而上展示 L1 信息边界 → L2 工具沙箱 → L3 编排回路 → L4 可观察性 → L5 自验证 → L6 约束与恢复的层级关系。
建议文件:assets/2026-06-27-Agent-Model-Harness-装具工程/image-02.png
| 层级 | 名称 | 解决的问题 | 本文对应 |
|---|---|---|---|
| L1 | 信息边界 | 给 Agent 看什么、不看什么 | AGENTS.md 地图 |
| L2 | 工具与沙箱 | 可执行、可隔离的运行环境 | 文件系统 / 沙箱 |
| L3 | 编排与反馈回路 | 多步任务的推进与纠偏 | Context Reset |
| L4 | 可观察性 | 看 Agent 在做什么、用了多少上下文 | 上下文监控 |
| L5 | 自验证 | 让 Agent 自己证明“跑通了” | Playwright 自验证 |
| L6 | 约束与恢复 | 强制守规矩 + 出错可恢复 | Linter / 结构测试 / 交接文档 |
对于大多数团队,建议按以下 优先级 落地(先吃低垂的果实):
- 创建 AGENTS.md 并持续维护:每当 Agent 犯错,就工程化一个方案记录进去,形成持续积累的防错系统。
- 分层管理上下文:严格控制上下文利用率,尽量让 Agent 停留在 40% 的“聪明区”。
- 赋予 Agent 验证能力:给 Agent 接入浏览器自动化等工具,让它像用户一样验证自己的工作。
- 定期“垃圾回收”:后台 Agent 定期扫描并清理冗余代码和不一致文档,防止系统熵增。
常见问题与避坑
Q1:是不是只要 Harness 做得好,用便宜模型就够了?
不是。Agent = Model + Harness 是相加关系,不是替代关系。差的模型配上好装具会变好,但模型本身的能力下限依然存在;同样,好模型配差装具会被严重拖累。两者都要抓,但 在模型已经够用的前提下,优化 Harness 的边际收益往往远高于换更贵的模型。
Q2:40% 的 Smart Zone 阈值是绝对的吗?
不是。它是经验值,不同模型、不同任务类型会浮动。务必在自己的真实任务上做基准测试,拟合出属于你业务的阈值,而不是照搬数字。
Q3:Context Resets 会不会丢失重要信息?
会,如果交接文档写得不好。关键在于 交接文档是结构化检查点,而不是聊天记录——只保留恢复任务所必需的目标、进度、约束、环境、下一步,丢弃冗余对话。
Q4:结构测试会不会太重,拖慢 Agent?
不会。结构测试通常很轻(AST 解析级别),可以放在 Agent 自检循环里高频跑;重型的端到端测试才放 CI。轻约束高频跑、重验证按需跑,是工程上的平衡点。
Q5:Harness 要一直不变吗?
不要。随着模型能力升级,Harness 的设计空间也会移动,旧的保护机制可能会变成冗余甚至阻碍。 需要定期复盘:哪些约束是因为模型“以前做不好”才加的,现在模型变强了是否可以松绑。
总结
回到开篇那个实验:6.7% → 68.3% 的飞跃,模型一行没改,变的只是装具。
决定智能体上限的,往往不是模型本身,而是它所处的工程环境。我们用一张图收束全文:
Agent = Model + Harness
│
├─ L1 信息边界 → AGENTS.md(地图而非说明书)
├─ L2 工具与沙箱 → 可执行、可隔离
├─ L3 编排反馈 → Context Reset + 交接文档
├─ L4 可观察性 → 上下文利用率监控(守住 40%)
├─ L5 自验证 → Playwright 等让 Agent 自证
└─ L6 约束与恢复 → Linter / 结构测试 / 垃圾回收
记住两条心法:
- Harness 里的每个组件,都编码了一个假设:模型单独做不好什么。 想清楚这个假设,再决定要不要加这一层。
- 优秀的 AI 工程师不应只是“Prompt 调优师”,更应该是“装具架构师”。 通过精密的工程设计,为大模型打造一个能让其稳定发挥的“数字化工厂”。
下次 Agent 又翻车时,先别急着换模型——先问问自己:它的“装具”,到位了吗?

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)