为什么很多 AI Agent 一上线就开始烧钱?我在这个开源项目里看到了答案
嗨,我是小华同学,专注解锁高效工作与前沿AI工具!每日精选开源技术、实战技巧,助你省时50%、领先他人一步。👉免费订阅,与10万+技术人共享升级秘籍!

我的判断:
很多 AI Agent 不是输在模型不够强,而是输在每一步都用错了模型。
真正跑进生产环境以后,最麻烦的不是“能不能调通模型”,而是每一步该用哪个模型、花多少钱、失败了怎么办。
ClawRouter 这个开源项目,正好在尝试解决这件事。
先把问题说白
如果只是做一个聊天框,模型调用很简单:
用户问一句,模型答一句。
但 Agent 不一样。
它会拆任务、读文件、调用工具、写代码、跑命令、修错误。一个看起来简单的目标,背后可能是十几次甚至几十次 LLM 调用。
这时候就会出现一个很实际的问题:
| 选择 | 结果 |
|---|---|
| 全用最强模型 | 效果稳,但成本容易爆 |
| 全用便宜模型 | 成本低,但关键步骤容易翻车 |
| 手写规则判断 | 前期能用,后期维护麻烦 |
所以问题不是“接哪个大模型平台”,而是:
模型调用本身,需不需要一层路由系统?
ClawRouter 的答案:需要
ClawRouter 的定位,可以理解成:
在你的应用和模型供应商之间,加一个本地模型路由器。
你的应用还是按 OpenAI-compatible API 调用,但请求会先经过 ClawRouter。它会判断这次任务更适合免费模型、低成本模型,还是更强的推理模型。
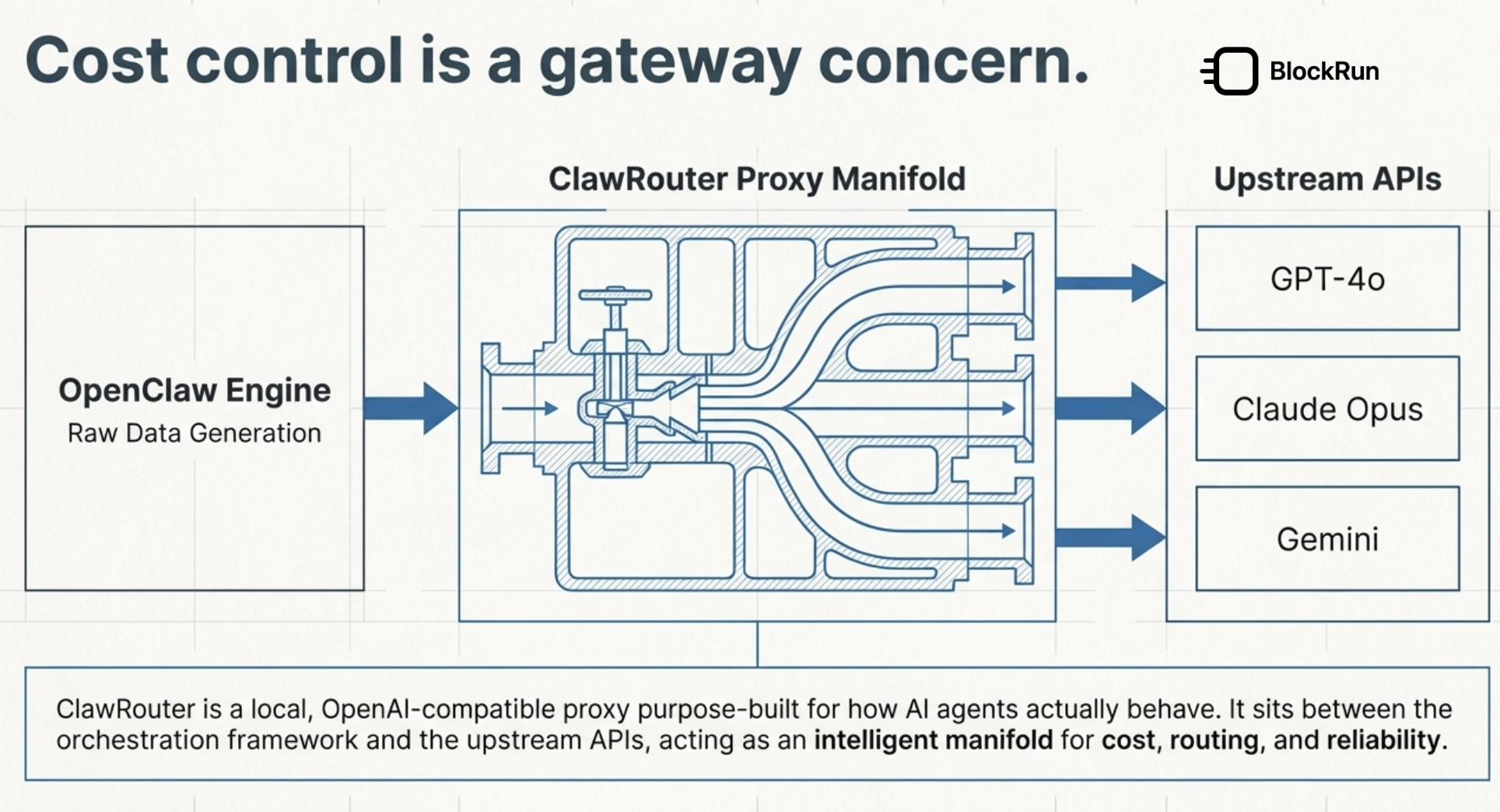
它主要处理这几类问题:
| 问题 | 对应能力 |
|---|---|
| 任务难度不同 | 智能路由 |
| 成本不可控 | 模型分层和预算控制 |
| 模型失败或限流 | fallback |
| Agent 上下文越来越长 | Token 压缩 |
| 多模型接口不统一 | OpenAI-compatible API |
这就比普通“模型聚合器”更进一步。
普通聚合器更像模型超市,ClawRouter 更像调度系统。
我觉得最有价值的是这 3 点
第一,它把“选模型”变成基础设施
很多团队刚开始做 AI 产品时,都会先用最强模型兜底。
这个选择很合理:先保证效果。
但当调用量上来以后,就会发现不是所有任务都值得用贵模型。
例如:
- 简单格式转换,不需要最强推理。
- 普通摘要,可以用中等模型。
- 复杂代码修复,才需要更强模型。
ClawRouter 的价值是把这些判断放到路由层,而不是让业务代码到处写规则。

第二,它把失败恢复前置了
模型调用失败不是偶然事件。
你可能遇到:
- 限流。
- 超时。
- 余额不足。
- 模型临时不可用。
如果一个 Agent 正在执行长任务,中途某一步失败,最好不要让整个任务直接崩掉。
所以 fallback 很重要。
更重要的是,fallback 不应该散落在业务逻辑里,而应该成为模型调用层的一部分。
第三,它开始治理长上下文
Agent 运行越久,上下文越容易膨胀。
工具返回、文件内容、错误日志、重复路径,都会慢慢堆起来。
这不只是“上下文窗口够不够”的问题,也是成本问题。
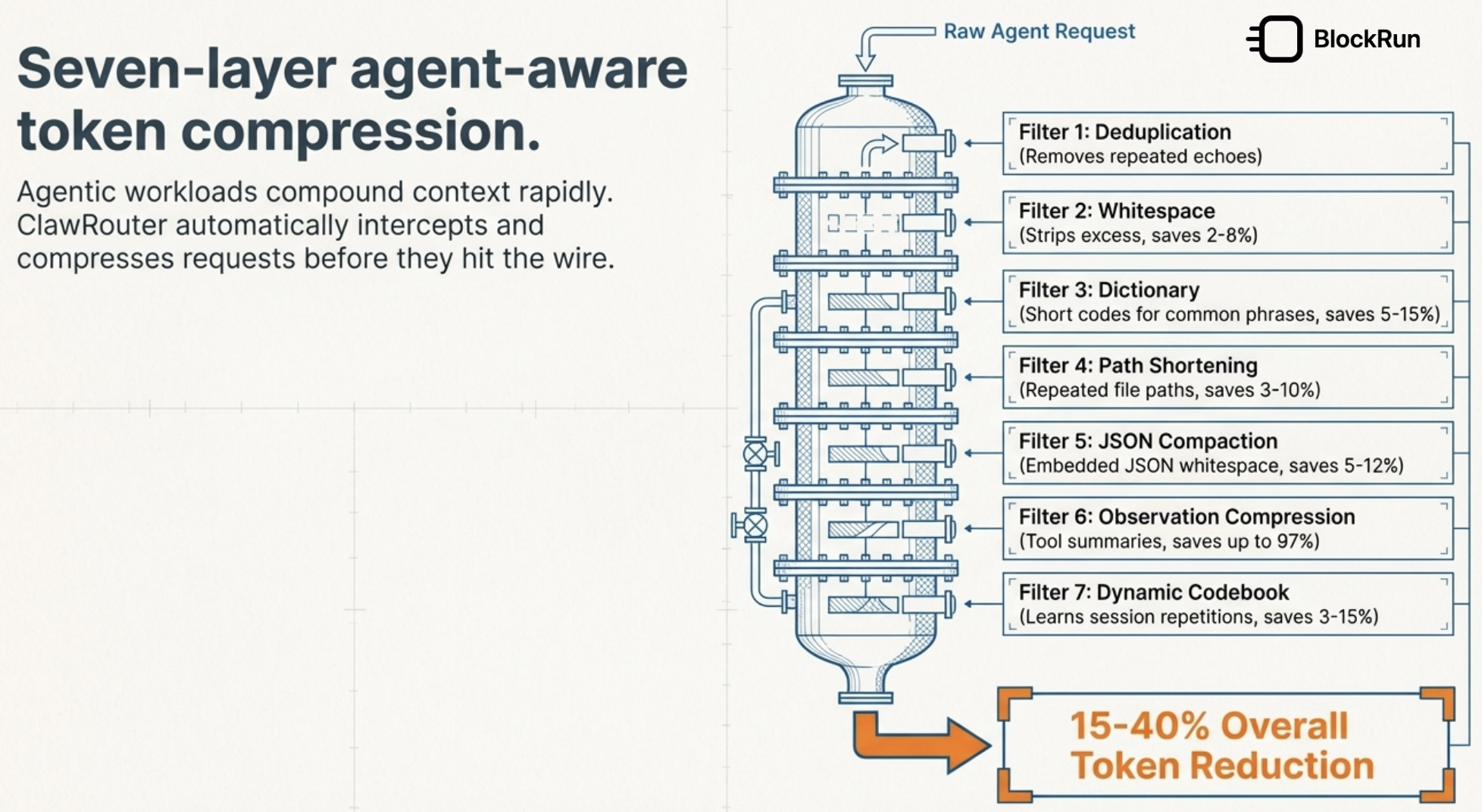
我更愿意把它理解成:
Agent 需要的不只是记忆力,还需要上下文卫生。
它适合谁关注?
我觉得这几类人可以看一下:
| 人群 | 关注点 |
|---|---|
| AI Agent 开发者 | 长任务、工具调用、失败恢复 |
| AI SaaS 团队 | 调用成本和模型分层 |
| 后端工程师 | 模型调用如何工程化 |
| 开源爱好者 | Agent 基础设施的新方向 |
如果你只是做一个小 Demo,它可能暂时不是刚需。
但如果你已经开始思考“模型成本怎么控”“Agent 怎么稳定跑完任务”,这类路由层会越来越重要。
不要把它神化
这个项目值得关注,但不等于能解决所有问题。
它不是本地推理框架,底层仍然依赖外部模型服务。
它的 x402 / USDC 微支付设计也比较前沿,对传统团队会有一点理解成本。
所以我更建议把它当成一种架构参考:
当 LLM 调用变多以后,模型选择、成本、fallback、上下文压缩,应该从业务代码里抽出来,变成一层可复用的基础设施。
最后
ClawRouter 最有意思的地方,不是“又接了多少模型”。
而是它提醒我们:
AI Agent 不是一次性问答工具,而是会持续运行的程序。只要它持续运行,模型调用就必须被调度、被治理、被观测。
这也是我觉得它值得收藏的原因。
后面如果继续拆,我会优先看它的路由策略、Token 压缩、fallback 机制,以及怎么接到自己的 Agent 项目里。
项目地址:
https://github.com/BlockRunAI/ClawRouter

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)