本地部署agent的方法
文章目录
一、前言
假设我们有一台windows的电脑,想要免费使用本地的AI Agent该如何做呢?首先我们要知道我们需要一个本地的AI模型作为API服务,然后我们需要一个Agent的外壳,这个外壳去请求本地的API。这样我们就拥有了本地Agent的能力。
一个比较简易的方案就是使用LM Studio部署本地AI模型+使用GenericAgent"作为agent的外壳
我自己电脑是4060Ti的显卡,显存16G,内存32G,这个配置运行本地Agent基本上没什么大问题。如果你没有这样的配置,只要你有独立显卡,并且显存不是低于8G那种,也是有可能可以部署本地agent的,但是因为显存小就会导致AI模型要进行CPU卸载,这样导致速度就很慢,而且也运行不了比较好的AI模型,但也许可以帮你完成一些简单的任务,你可以试试。
虽然这篇文章是并不是特定面向程序员的,但由于本地AI模型依赖CUDA和pytorch等深度学习环境,实际上还是有点难度的。
此外,agent的外壳你也不一定要选择GenericAgent,有很多Agent的外壳都可以,只要它能连上你本地的API都可以,但其他的Agent比较复杂。
注意:本地Agent能力较弱,部署后立刻命令它将“使用任何删除或者移动命令以及危险操作都需要询问”写入永久记忆,并且下达命令的时候严格限制可操作的文件范围,避免AI误删文件,尤其是不要让它做一些涉及到文件清理等危险行为。
二、操作步骤
1.下载安装LM Studio
https://www.lm-studio.me/
2.下载AI模型
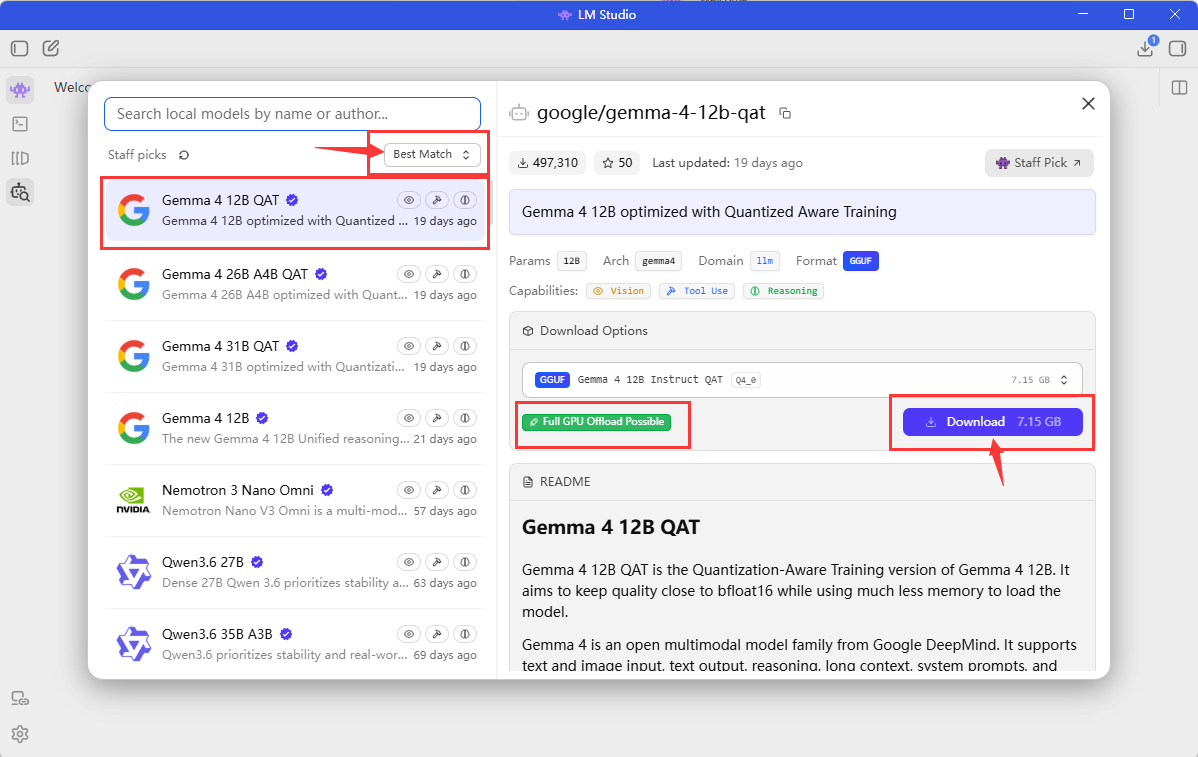
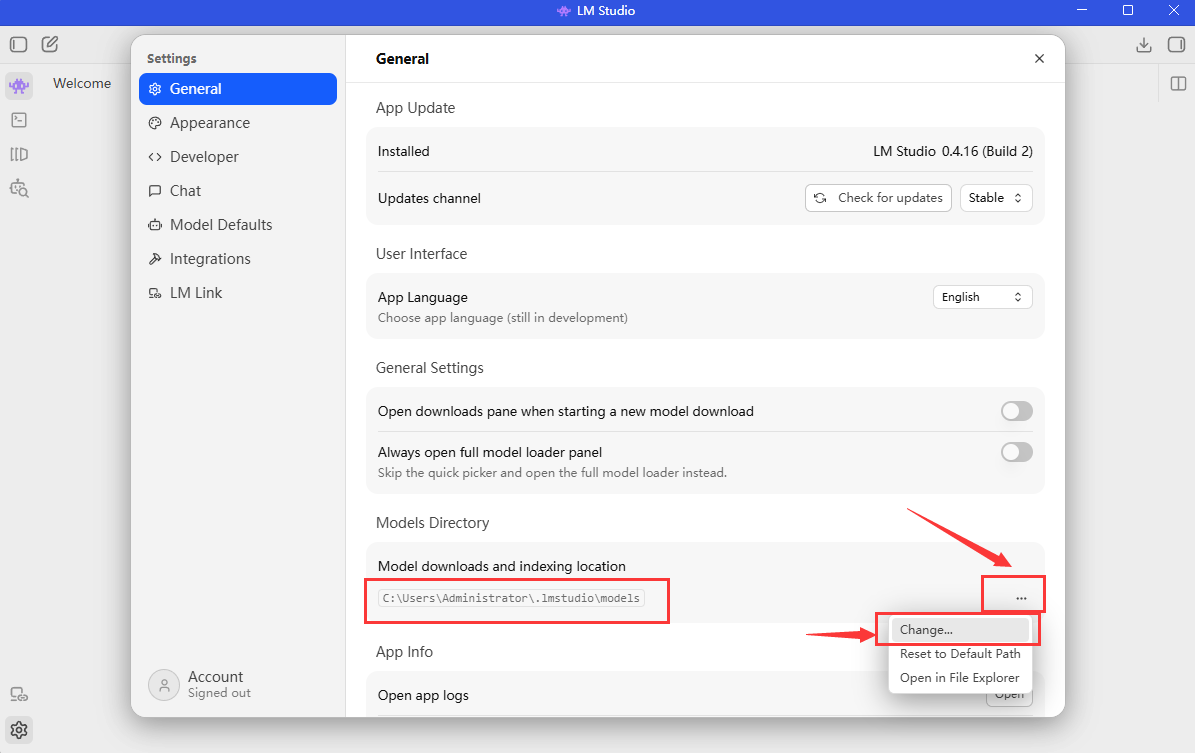
它这里如果你选择Best match排序的话,它会从上到下给你排序出它觉得最匹配你的电脑的AI模型。所以一般来说你选择第一个AI模型就行了,但是你要注意的是右边有个“Full GPU Offload Possible”,这个意思就是说,这个AI模型可以在你的GPU上完整运行,所以你点右边的Download就可以开始下载了,但是你在下载之前你最好按照下面的方式改一下模型下载位置,因为它默认下载位置是在c盘,你不改下载位置到D盘或者E盘,这对于你的C盘压力很大,因为一般好一点的AI模型都有接近8个G的大小。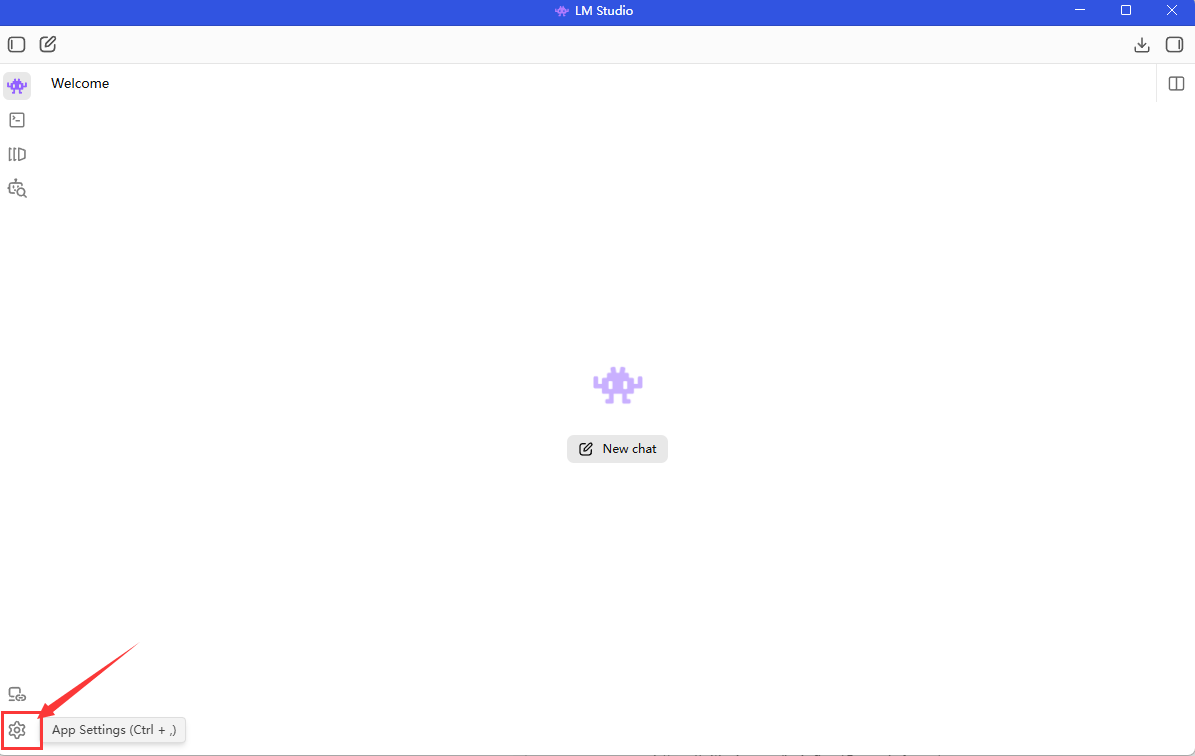
注:如果你点了另外一些模型,发现右边不是“Full GPU Offload Possible”,而是“Partial GPU Offload Possible”,这个意思就是这个AI模型无法完整地在你的GPU上运行,一个AI模型它可能由很多组件组成,每个组件如果都放进你的GPU里面运行就代表它完整地在你的GPU上运行,但是每个组件都要占用你的GPU显存,如果你的显存不够,一种方案就是把一些组件转移到CPU上运行,但这样的代价就是组件与组件之间的通信与在GPU和CPU之间来回传输信息,这样势必是很慢的。所以不要去安装带有“Partial GPU Offload Possible”的模型,除非你觉得慢点也没事,你就是想体验一下那个模型到底有多强,你可以试试。我只是提前告诉你,如果你要保证与AI交流的速度够快,要选择能够完整放在GPU上运行的AI模型。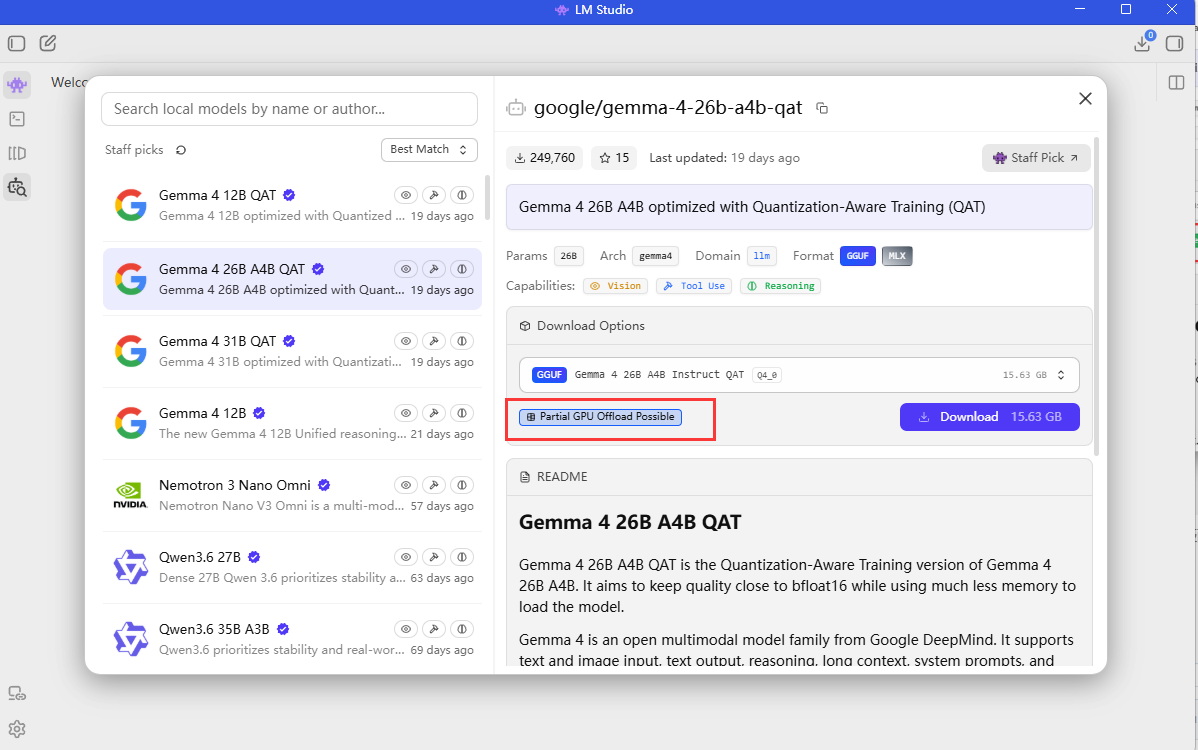
3.下载安装GenericAgent
https://github.com/lsdefine/GenericAgent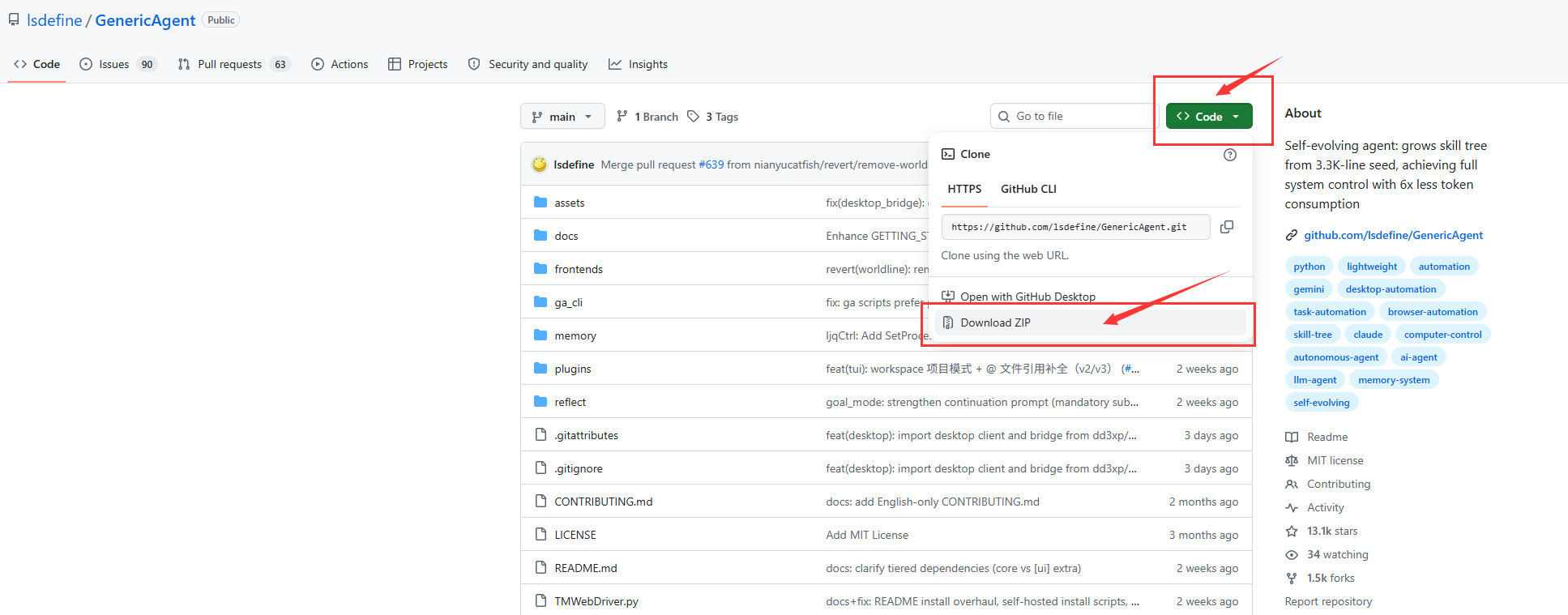
4.windows系统深度学习环境配置
参考:https://blog.csdn.net/shimingwang/article/details/155912711 (你可以暂时跳过第4节的VS安装,因为C++编译环境不是必要的)
5.windows系统python开源项目环境配置
参考:https://blog.csdn.net/shimingwang/article/details/155914241
6.本地AI模型开放自己的API
7.配置GenericAgent的访问本地AI模型的API
在你的GenericAgent里面新建一个mykey.py,然后
# GenericAgent — mykey.py 本地 LLM 配置
# 指向本地 http://127.0.0.1:1234 (OpenAI 兼容接口)
# ── 本地 LLM 配置(LM Studio / Ollama / vLLM / llama.cpp 等)──
native_oai_config = {
'name': 'local-llm', # 显示名 & mixin 引用名
'apikey': 'sk-no-key-required', # 本地服务一般不校验 key
'apibase': 'http://127.0.0.1:1234/v1', # ← 本地 API 地址
'model': 'google/gemma-4-12b-qat', # ← 改成你本地跑的模型名
'api_mode': 'chat_completions',
'max_retries': 3,
'connect_timeout': 10,
'read_timeout': 120,
}
# ── Mixin 故障转移(这里只配了一个,但结构留着方便以后加)──
mixin_config = {
'llm_nos': ['local-llm'],
'max_retries': 10,
'base_delay': 0.5,
}
配置完之后在你的conda环境里面运行python launch.pyw 就会弹出一个聊天窗口,你就可以让你的agent干活了
注:GenericAgent好像有桌面版,但是我没试过桌面版,因为桌面版可能改不了API地址
https://github.com/lsdefine/GenericAgent/releases/tag/desktop-portable-v0.1.3

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 1
1 0
0- 0


 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)