2026 AI/LLM黑话速通:Prefill、RLVR、GraphRAG,进阶概念怎么用?从小白到听懂面试官在说什么(下)
承接上篇第 12 节,本篇继续整理第 13 到第 20 个概念,重点放在推理加速、训练反馈、检索增强和 Agent 工程实践;文末会用两张表把上下两篇的概念放回同一套技术栈中对照理解。
13. Prefill / Decode:读题和答题
核心原理
一次 LLM 请求通常分为两个阶段:
| 阶段 | 类比 | 特点 |
|---|---|---|
| Prefill | 读题 | 一次性处理完整 prompt,可并行度高 |
| Decode | 答题 | 逐 token 生成,依赖 KV Cache |
Prefill 特点:
- 计算密集型。
- 主要消耗矩阵乘法算力。
- prompt 越长,这一阶段越重。
Decode 特点:
- 更偏内存带宽密集型。
- 需要频繁读取 KV Cache。
- 输出越长,这一阶段越明显。
工程实现
Prefill / Decode 增量推理伪代码:
def serve(prompt):
# Prefill:处理完整输入
logits, kv_cache = model.forward(prompt, past_kv=None)
# Decode:逐 token 生成
output_tokens = []
for _ in range(max_new_tokens):
# 从当前概率分布中选出下一个 token
next_token = sample(logits)
# 把生成结果追加到输出序列
output_tokens.append(next_token)
# 如果已经生成结束符,就不再继续解码
if next_token == eos:
break
# 只计算最新 token,并继续复用前面得到的 KV Cache
logits, kv_cache = model.forward(next_token, past_kv=kv_cache)
return output_tokens
实践建议
生产系统中可以根据负载做分离调度:
- 长 prompt 请求优先进入高吞吐 Prefill 资源池。
- 长输出请求需要更关注 Decode 阶段的延迟和 KV Cache 显存。
- 是否物理拆分 Prefill / Decode 节点,取决于系统规模、模型大小和网络传输成本。
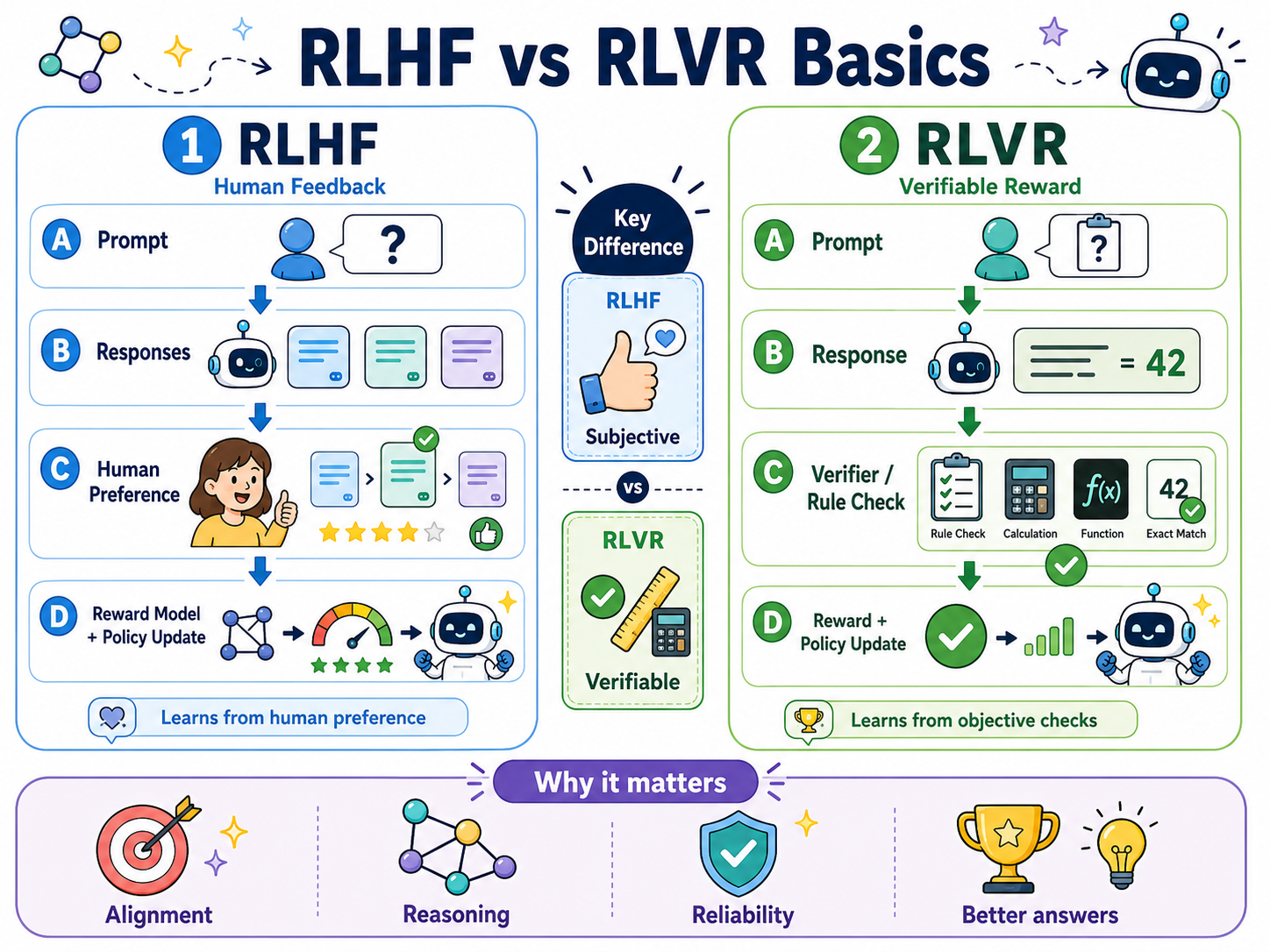
14. RLVR:把可验证结果变成训练奖励
核心原理
RLVR 是 Reinforcement Learning with Verifiable Rewards,即基于可验证奖励的强化学习。
它的核心思路是:
如果一个任务能自动判断答案好坏,就可以把这个判断结果直接当作奖励信号。
和依赖人类偏好打分的 RLHF(Reinforcement Learning from Human Feedback) 不同,RLVR 更强调可验证、可程序化、可复现的奖励。
典型场景包括:
- 数学题:答案是否匹配,符号推导是否等价;
- 代码题:单元测试是否通过;
- 结构化输出:JSON Schema 是否通过;
- 格式任务:字段是否齐全,类型是否正确;
- 工具任务:调用结果是否满足目标条件。
工程实现
奖励函数设计:
| 任务类型 | 奖励来源 |
|---|---|
| 代码任务 | 单元测试通过率、编译结果、静态检查 |
| 数学任务 | 答案匹配、符号验证、数值校验 |
| 结构化输出 | JSON Schema 校验、字段类型检查 |
| 工具调用 | API 返回状态、业务规则校验 |
训练流程概念版:
for prompt in train_prompts:
# 清空上一轮梯度,避免不同 batch 的梯度意外累积
optimizer.zero_grad()
# 同一个题目生成多个候选答案,方便比较好坏
responses = model.generate_many(prompt, n=8)
rewards = []
for response in responses:
# 用规则、测试或工具自动判断答案质量
reward = verify_with_rules_or_tools(prompt, response)
rewards.append(reward)
# 根据奖励计算强化学习目标,让高奖励答案更容易被生成
loss = rl_objective(responses, rewards)
loss.backward()
# 更新模型参数
optimizer.step()
实践建议
RLVR 很适合“答案能验”的任务,但不适合所有任务。
比如开放式写作、审美判断、战略建议这类任务,很难用一个确定规则判断“对”或“错”。这时如果强行设计奖励,可能会出现奖励黑客、格式投机或表面优化。
- 奖励函数要尽量可靠,不能只奖励“看起来像正确答案”。
- 对代码任务,单元测试要覆盖边界条件,避免模型钻测试漏洞。
- 对数学任务,要避免只看最终字符串匹配,最好支持等价表达式或数值验证。
- 奖励太稀疏时,训练会不稳定,可以加入过程约束、格式约束或更细粒度检查。
- RLVR 是后训练工具箱的一部分,不是替代 SFT、RAG 或人工评测的万能方案。
15. Test-time Compute:推理时计算
核心原理
Test-time Compute,也叫测试时计算或推理时计算,最值得关注的地方不是“推理本来就要花算力”,而是:在模型参数不再更新的情况下,主动增加推理阶段的计算,让模型在交付最终答案之前多生成、多比较、多验证、多搜索。
这个概念在推理模型兴起之后变得重要,是因为它把“模型能力提升”从单纯的训练阶段扩展到了推理阶段:预训练时代主要问“训练时多给多少数据和算力”,推理模型时代还要问“回答这一题时,值得给多少思考、搜索和验证预算”。
可以把它理解成三件事的组合:
- 生成更多可能性:一次不够,就生成多个候选答案或多条推理路径。
- 判断哪些更可靠:用投票、规则、测试、奖励模型或验证器筛选。
- 把推理当成搜索:不是只让模型顺着一个答案写到底,而是在多个中间状态之间扩展、回溯和选择。
三条实现路径
| 实现路径 | 简单理解 | 适合场景 | 主要局限 |
|---|---|---|---|
| N 选 1 / Best-of-N / 多数投票 | 一次生成多个候选答案,再用投票、打分或验证器选一个 | 答案容易比较、成本能接受的任务 | 如果候选里没有正确答案,再怎么选也没用 |
| 长链思维推理 | 让模型在回答前生成更长的推理过程,给自己更多中间步骤 | 数学、代码、逻辑推理、复杂分析 | 写得更长不等于推得更对,容易产生看似合理的错误推理 |
| 搜索 + 验证 | 把推理拆成多步,每一步生成多个可能方向,再通过验证器或奖励模型筛选 | 可验证、可分步的问题,如证明、规划、复杂 Agent 任务 | 工程成本高,效果依赖验证器质量 |
这三条路径并不互斥:简单系统可以只做多候选选择,复杂系统可能同时使用长链推理、搜索和验证。
实践建议
- 多数投票适合做基线,复杂任务更需要验证器、过程奖励或搜索。
- 不要只增加输出长度,真正有价值的是提高有效搜索密度。
- 在线搜索很强,但成本高;也可以把搜索得到的高质量轨迹沉淀为训练数据,用来提升后续模型。
16. Thinking Budget:给 AI 的思考预算
核心原理
Thinking Budget 是显式指定模型推理时可用的计算资源。
它可以表现为:
- 最大生成 token 数;
- 搜索宽度;
- 迭代次数;
- 时间预算;
- 可调用工具次数;
- 候选答案数量。
核心是在速度和深度之间做取舍。
工程实现
应用层预算参数:
在应用层加入类似参数:
thinking_budget
它不一定是模型 API 的原生参数,也可以是系统自己维护的调度策略。
策略示例:
| 任务类型 | Budget | 适合投入预算的原因 | 需要控制的上限 |
|---|---|---|---|
| 简单问答 | 低 | 通常可直接回答,额外推理步骤收益很小 | 避免为了“想得更久”增加无意义 token,优先降低成本和延迟 |
| 常规分析 | 中 | 需要适度拆解、对比和归纳,能从少量中间推理中受益 | 超过一定阈值后容易出现收益递减,要限制响应时间 |
| 代码 / 推导 / 复杂规划 | 高 | 多步推理、草稿验证、工具检查能明显提升可靠性 | 受最大上下文、生成 token、工具调用次数和 GPU 时间限制,不能无限拉高 |
| 实时对话 / 在线客服 | 低到中 | 用户更看重快速响应,只保留必要的理解和检查 | 思考越长等待越久,容易损害交互体验 |
| 高风险决策辅助 | 中到高 | 需要更充分的校验、引用和反思,降低遗漏风险 | 要把准确率提升与成本、延迟一起评估,必要时交给人工复核 |
调度伪代码:
class ThinkingScheduler:
def get_budget(self, query):
# 简单问题少花算力,优先降低延迟
if is_simple_question(query):
return 1
# 代码和数学更容易从多步推理或工具检查中受益
elif is_code_or_math_task(query):
return 8
# 普通分析任务使用中等预算
else:
return 3
实践建议
- 不要把“思考预算”简单等同于“越大越好”。
- 对用户可见的产品,要提供速度与质量之间的清晰选择。
- 对企业场景,要把成本、延迟和成功率放在一起评估。
17. Speculative Decoding:让小模型先写,大模型来审
核心原理
Speculative Decoding,即推测解码/投机推断。该方法实现了在不降低目标大模型输出质量的前提下,减少大模型逐 token 解码的次数,从而提升生成速度、降低延迟和成本。
它的思路是:先让一个便宜的小模型,也叫 draft model,快速生成几个候选 token;再让大模型,也叫 target model,一次性并行验证这些候选 token。
如果候选 token 被接受,就直接使用;如果某个位置不被接受,则从修正后的目标分布中重新采样。
**核心指标:**接受率(acceptance rate)。
接受率越高,加速效果越明显。
很多文章会把推测解码讲成:
小模型先猜,大模型看看猜得对不对。
这个说法便于理解,但不够严谨。
更准确地说,大模型不是只看“小模型猜出的下一个 token,是不是自己最想生成的那个 token”。它会比较这个候选 token 在小模型和大模型各自判断中有多大可能性,再决定接受还是拒绝,从而尽量让加速后的生成结果,接近“完全由大模型自己一步步生成”的结果。具体的算法原理在这位老师的博客写的很好:https://charlestar.github.io/2026/05/12/%E6%8E%A8%E6%B5%8B%E8%A7%A3%E7%A0%81SpeculativeDecoding%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5/
通俗易懂的讲,Speculative Decoding能够提升生成速度的核心原因是:
普通解码:大模型生成 4 个 token,要跑 4 次大模型。
推测解码:小模型先猜 4 个 token,大模型只跑 1 次来验证这 4 个 token。
普通解码:
Prompt → 大模型 → token1
Prompt + token1 → 大模型 → token2
Prompt + token1 + token2 → 大模型 → token3
Prompt + token1 + token2 + token3 → 大模型 → token4
大模型跑了 4 次。
推测解码:
小模型先猜:token1 token2 token3 token4
Prompt + token1 + token2 + token3 + token4
→ 大模型一次 forward
→ 同时得到 4 个位置的概率
工程实现
基本步骤:
- Draft 模型自回归生成
k个候选 token。 - Target 模型对这
k个候选 token 做一次批量验证。 - 对候选 token 逐个做接受 / 拒绝判断。
- 一旦拒绝,就从修正后的目标分布中采样,并结束本轮。
- 继续下一轮推测解码。
实践建议
- Draft 模型要足够快,也要和 target 模型分布足够接近。
- Draft 模型与 target 模型最好使用一致或兼容的 tokenizer。
k不是越大越好;过大时接受率下降,反而浪费计算。- 适合输出比较可预测的场景,例如代码补全、格式化文本、结构化回答。
18. GraphRAG:基于知识图谱的RAG
核心原理
GraphRAG 是在 RAG 基础上引入知识图谱或图结构。
传统 RAG 更擅长找相关片段;GraphRAG 更适合处理关系密集、需要跨文档整合的问题,例如:
- A 依赖哪些 B?
- 某项目和哪些系统有关?
- 某客户投诉和哪些版本变更有关?
- 一个组织内部有哪些主题、社区和关系链?
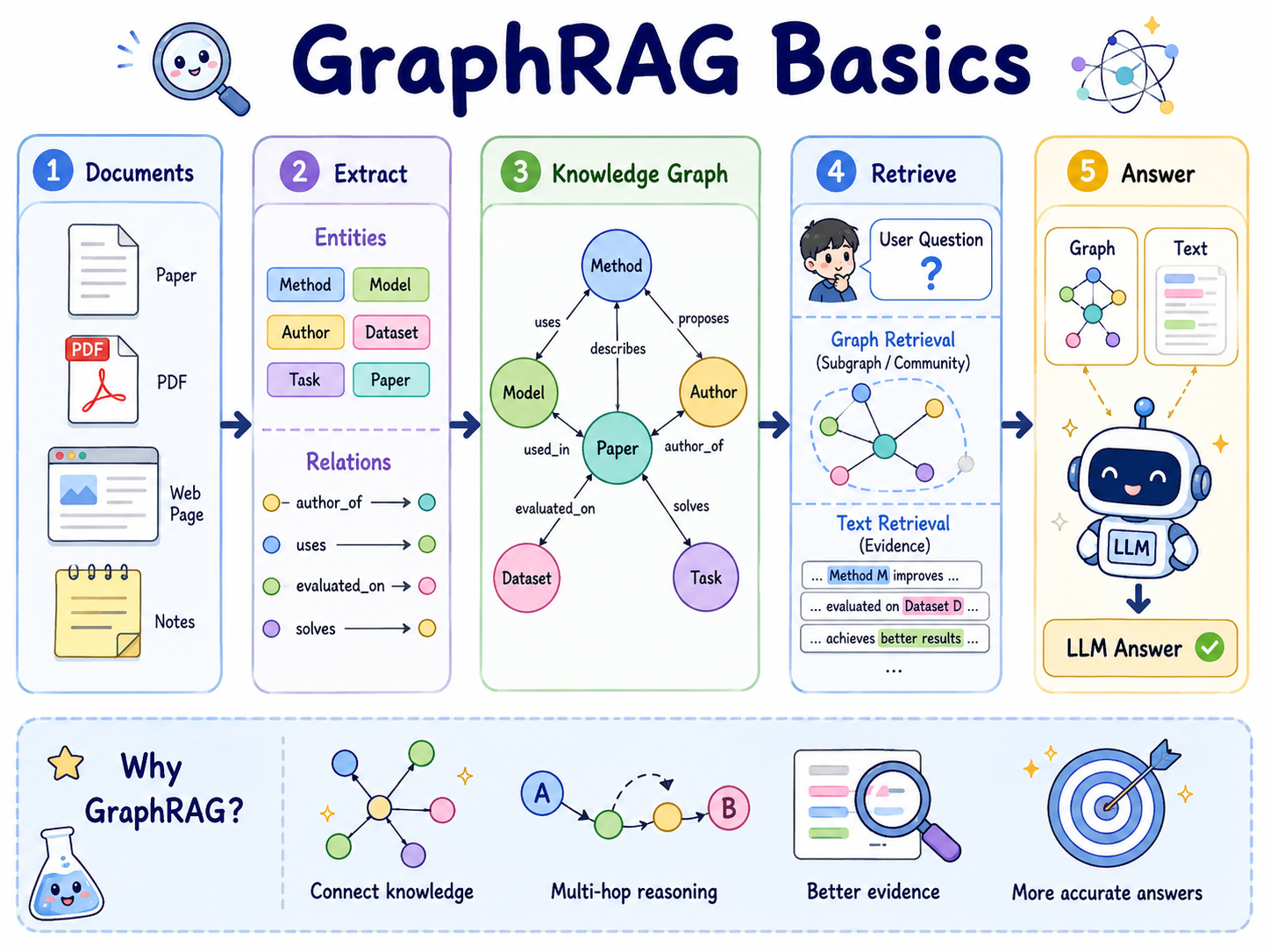
工程实现
构建流程:
- 从文档中抽取实体、关系、事件或主题。
- 构建图结构,例如实体关系图、社区图或主题图。
- 对图进行聚类或社区发现。
- 为图节点、社区或关系生成摘要。
- 查询时根据问题召回相关图结构和文本证据。
- 将图结构描述与文本证据一起交给模型回答。
实际例子:客户投诉归因
假设知识库里有三类材料:客服工单、版本发布记录、系统依赖文档。负责售后的技术支持收到投诉后,问AI助手:
客户 Alpha 升级到 3.2.1 后订单支付失败,可能和哪些系统变更有关?
普通 RAG 可能只召回“支付失败”的工单片段;GraphRAG 会先把材料抽成图关系:
(Alpha)-[:提交]->(工单 T-1023)
(工单 T-1023)-[:提到]->(payment-service)
(版本 3.2.1)-[:修改]->(payment-service)
(版本 3.2.1)-[:引入]->(签名算法调整)
(payment-service)-[:依赖]->(auth-service)
查询时可以沿着“客户 → 工单 → 服务 → 版本变更 → 依赖服务”这条关系链召回证据:
MATCH (c:Customer {name: 'Alpha'})-[:SUBMITTED]->(t:Ticket)-[:MENTIONS]->(s:Service)
OPTIONAL MATCH (r:Release {version: '3.2.1'})-[:CHANGED]->(s)
OPTIONAL MATCH (r)-[:INTRODUCED]->(change)
OPTIONAL MATCH (s)-[:DEPENDS_ON]->(dep:Service)
RETURN t.id, s.name, r.version, change.name, dep.name
最终交给模型的上下文就不只是几个相似文本片段,而是:
图结构摘要:Alpha 的工单 T-1023 提到 payment-service;版本 3.2.1 修改了 payment-service,并引入签名算法调整;payment-service 依赖 auth-service。
原文证据:工单中的错误描述、发布记录中的变更说明、依赖文档中的服务链路。
用户问题:客户 Alpha 升级到 3.2.1 后订单支付失败,可能和哪些系统变更有关?
这样模型更容易回答:“优先排查 3.2.1 中 payment-service 的签名算法调整,以及它与 auth-service 的鉴权兼容性。”
实践建议
- 对小型 FAQ 或简单知识库,普通 RAG 往往已经够用。
- 对长报告、组织知识、跨文档主题分析,GraphRAG 更有优势。
19. Worktree:给每个 AI 分一个独立工位
核心原理
工作树严格意义上并不算LLM相关的黑话,只是在AI coding“更高更快更强”的过程中,该工具的优势逐渐凸显。Git Worktree 允许在同一仓库下创建多个独立工作目录,是AI辅助代码开发时代的神器。
在普通开发里,它的作用是让你不用反复切分支,也能同时打开多个分支。
在 AI Agent 辅助的开发过程中,它更像是给每个 Agent 或每个任务分配一张独立工位:
主仓库 main
├─ ../wt-fix-login 分支 agent/fix-login,交给 Agent A 修登录问题
├─ ../wt-add-tests 分支 agent/add-tests,交给 Agent B 补测试
└─ ../wt-update-docs 分支 agent/update-docs,交给 Agent C 改文档
这些目录共享同一份 Git 仓库历史,但各自有独立的文件树、分支和未提交状态。
这样做的好处是:多个 Agent 可以并行工作,互不覆盖对方正在修改的文件;每个 Agent 的改动也可以单独测试、单独审查,最后再决定是否合并回主分支。
为什么我们要在开发中使用worktree:
| 优点 | 说明 |
|---|---|
| 节省磁盘空间 | 多个 worktree 共享同一套 Git 对象库,不需要像多次 git clone 那样复制完整 .git 历史。 |
| 远程状态同步 | 一个 worktree 执行 git fetch 后,其他 worktree 通常也能看到更新后的远程引用。 |
| 本地分支互相可见 | 在一个 worktree 中提交的本地分支,可以在其他 worktree 中直接查看,方便对照进度。 |
| 配置集中管理 | Git config、alias、hooks 等配置可以复用,避免多个 clone 重复配置。 |
| 适合并行开发 | 每个任务或 Agent 使用独立目录和分支,互不覆盖改动,最后统一 review 和合并。 |
工程实现
典型流程:
- 为每个任务创建一个独立分支和 worktree。
- 把 Agent 的工作目录限制在对应 worktree 中。
- Agent 在自己的 worktree 里修改、运行测试、提交结果。
- 主仓库统一 review、比较差异并合并。
创建两个 Agent 工作区:
git worktree add -b agent/fix-login ../wt-fix-login main
git worktree add -b agent/update-docs ../wt-update-docs main
此时可以让两个 Agent 分别在不同目录中运行:
Agent A 的 cwd = ../wt-fix-login
Agent B 的 cwd = ../wt-update-docs
如果两个 Agent 都改了同一个文件,冲突会在合并阶段暴露,而不是在工作过程中互相覆盖。
实践建议
- 多个 Agent 并行处理不同 issue。
- 避免多个任务在同一个工作目录里相互覆盖。
- 避免未提交状态相互污染。
- 便于回滚和审查。
- 每个任务都要绑定清晰分支名。
- Agent 修改前先同步主分支,减少后续冲突。
- 合并前要跑测试和代码审查。
- 临时 worktree 要及时清理,避免仓库膨胀。
- Worktree 只隔离代码目录和 Git 状态,不等于安全沙箱;运行命令、访问网络、改数据库仍然需要额外权限控制。
把这些概念串起来看
假设你要做一个 AI 编程助手,可以这样理解整套技术栈:
| 目标 | 对应技术 |
|---|---|
| 底层模型成本可控 | MoE |
| 推理成本和速度优化 | KV Cache、Prefill / Decode、Speculative Decoding、Quantization |
| 长材料处理 | Long Context、RAG、Context Engineering |
| 复杂任务推理 | Test-time Compute、Thinking Budget |
| 能力对齐 | RLVR、LoRA / QLoRA |
| 知识检索 | RAG、GraphRAG |
| 工具连接 | Agents、MCP |
| 隔离与审计 | Sandbox、Worktree、Hooks |
进一步拆成四个核心问题:
| 核心问题 | 对应概念 |
|---|---|
| 怎么更快? | MoE、KV Cache、Prefill / Decode、Speculative Decoding、Quantization |
| 怎么更会解决问题? | RLVR、Test-time Compute、Thinking Budget |
| 怎么处理长材料? | Long Context、RAG、GraphRAG、Context Engineering |
| 怎么连接真实世界? | Agents、MCP |
| 怎么安全干活? | Sandbox、Worktree、Hooks |
总结一下
2026 年的 LLM 相关概念,已经不只是“模型参数多大”这么简单。
真正重要的变化是:
AI 正在从聊天框,变成一个能接工具、会查资料、能写代码、能按流程执行任务的数字员工。
本篇只是建立直觉性的理解,真正做到方法应用,还需要对各个概念进行深入的理解和研究。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)