Harness Engineering · 从 Demo 到生产的最后一公里
当所有人都在卷模型,谁来保证Agent不再"脱缰"?
Harness Engineering · 从 Demo 到生产的最后一公里
📌 导语
你是否遇到过这样的场景?Demo 演示时,AI Agent 表现堪称完美——精准回答、流畅调工具、逻辑清晰得让人惊叹。然而一旦部署到生产环境,短短几小时就事故频出:幻觉频发、工具误用、无限循环、上下文丢失……
问题不在模型,而是缺少一套让聪明变得可靠的**“缰绳”**——这就是今天的主角:Harness Engineering(驾驭工程)。
一、Agent = 模型 + 缰绳
2026 年 2 月,HashiCorp 联合创始人 Mitchell Hashimoto 在构建 AI 编码代理时,形成了一个核心习惯:每当发现代理犯错,就将修复方案永久工程化到运行环境中,使同类错误在结构上难以再发生。
他把这个实践叫做 “engineering the harness”。
几周之内,OpenAI、Anthropic 等机构迅速采纳。随后 LangChain 发布了实证数据:同一个模型,仅更换 Harness 架构,Terminal Bench 2.0 基准得分从 42% 跃升至 78%。 36 个百分点提升——没有换模型、没有换数据、没有换提示词。
🧮 核心公式
Agent = Model + Harness
模型是那匹强壮而快速的马,Harness 是缰绳、马鞍和辔头的完整系统。
Harness 的目的不是限制马的能力,而是将强大但可能失控的力量,转化为可靠、可预测、可管理的生产力。
二、从提示词到缰绳:三代演进
Harness Engineering 并非凭空出现,它站在此前两代实践之上:
第一代 · 2022-2024 — Prompt Engineering 提示词工程
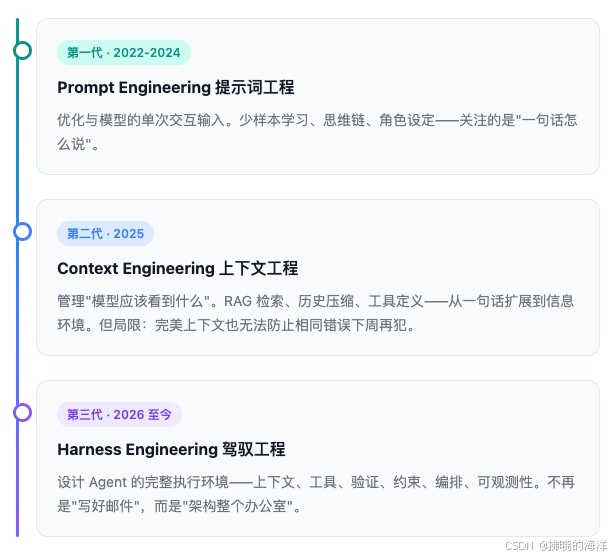
Prompt ⊂ Context ⊂ Harness
三者是包含关系,每一代都吸收前一代,然后向上攀升
三、四大核心机制
如果你要把 Harness 落地,核心就是四个词:约束、告知、验证、纠正。它们构成一个完整的治理闭环:

🔒 约束:不是"别删数据",而是让删数据的工具不存在
📌 案例:Nexad 团队
早期把规则写在文档里,Agent"在压力下经常遗忘"——30-40% 时间消耗在人工质量保障。后来构建 8 个自定义 Linter,将业务规则编码为自动检查。约束消除了低效探索路径。
📌 案例:Stripe
400 余个内部工具通过 MCP 服务器统一暴露,但每个代理会话仅能访问其子集。高风险场景下,甚至从 schema 级别移除写操作工具——不是告诉代理"别删数据",而是让删数据的工具根本不存在。
✅ 验证:双层体系
| 类型 | 速度 | 成本 | 确定性 | 典型应用 |
|---|---|---|---|---|
| 计算型验证 | 毫秒~秒级 | 低 | ✅ 确定 | Linter、类型检查、测试 |
| 推理型验证 | 秒~分钟级 | 较高 | ⚠️ 非确定 | AI代码审查、语义分析 |
💡 Anthropic 创新
生成器与评估器分离架构:主代理完成编码后,生成子代理(使用相同模型但完全隔离的上下文)进行代码审查,仅接收 git diff 和规则文件,角色定位为**“持怀疑态度的高级审查者”**。以极低成本实现约 90% 的代码质量保障。
四、ETCLOVG:七层架构看懂 Harness
CMU、耶鲁、Amazon 的综述论文提出了系统化的七层分类法——前四层让 Agent 能跑起来,后三层让 Agent 跑得稳、跑得安全:
| 层级 | 名称 | 含义 | 类比 |
|---|---|---|---|
| E | 执行环境与沙箱 | Agent 在哪运行,如何限制风险 | 给马一个安全的围场 |
| T | 工具接口与协议 | 工具如何描述、发现、调用 | 缰绳连接马鞍和马镫 |
| C | 上下文与记忆 | 管理模型每步看到什么,状态如何延续 | 骑手观察路况的方式 |
| L | 生命周期与编排 | 单/多 Agent 如何协作运行 | 骑手的骑行策略 |
| O | 可观测性与运维 | 如何追踪、监控、归因 | 仪表盘和 GPS |
| V | 验证与评测 | 如何判断任务是否真的完成 | 成绩单和考核 |
| G | 治理与安全 | 权限、审计、人工介入 | 骑术规范和安全规则 |
📊 关键数据
SWE-bench 上,同一模型 Claude Opus 4.5 在不同 Agent Harness 中成功率从 2% 到 12%,6 倍差距完全来自 Harness 设计。评估对象应该是"模型+Harness 组合",而不是孤立模型。
五、棘轮原则:Harness 只收紧,不放松
🔧 棘轮原则 Ratchet Principle
每当 Agent 犯错,不是修复输出,而是修复 Harness,使同类错误永不再发生。
| 问题 | 修复方式 |
|---|---|
| Agent 不知道规则? | → 写入 CLAUDE.md(引导) |
| Agent 知道规则但违反? | → Hook 强制执行(传感器) |
| Agent 缺少信息? | → 添加 Skill 或 MCP(上下文管道) |
| Agent 用了危险工具? | → 收紧权限(护栏) |
| Agent 上下文被污染? | → 用子 Agent 隔离(编排) |
| Agent 崩溃无人知晓? | → 加监控(可观测性) |
⚡ Hashimoto 规则:AGENTS.md 中的每一行都应追溯到一次真实的 Agent 失败。如果指不出具体是哪次错误催生了这行规则,就删掉它。零条理想化规则。
六、88% 的失败率说明什么?

OpenAI Codex 团队提供了目前最具说服力的案例:3 人工程师团队,5 个月,超过 100 万行生产代码完全由 AI 代理编写,零人工直接编写。工程师的核心职责不是写代码,而是设计代理工作的环境和结构。
“最大的教训不是关于 GPT-5 的编码能力,而是当我们停止关注模型本身,开始构建使代理可靠的工具、反馈回路和支撑系统时,进展才真正加速。”
—— OpenAI Codex 团队
⚠️ 边界意识
所有成功案例都是绿地项目。将 Harness 应用于十年历史的遗留代码库,Böckeler 明确指出是"更为复杂的问题"——类似于在从未运行过静态分析的代码库上首次运行,你会被警报淹没。
七、你的 Harness 从哪里开始?
不需要框架,不需要大笔投资。从手边的工具开始:
- 写一个精简的 AGENTS.md —— 500行以内,只写 Agent 无法从代码推断的信息:构建命令、测试命令、风格规则、禁止模式
- 添加计算型验证 —— Linter、类型检查、格式化,每次变更都运行
- 设一个 Hook —— PreToolUse 拦截危险操作,PostToolUse 验证输出格式
- 建立记忆系统 —— MEMORY.md 记录跨会话经验,每个纠错都留下痕迹
- 用子 Agent 隔离 —— 执行任务用子 Agent,审查任务用独立上下文
然后遵循棘轮原则:每次 Agent 犯错,就收紧 Harness。
只紧不松。
📌 核心总结
2026 年是 AI Agent 从"演示级聪明"走向"生产级可靠"的关键转折点。
当所有人都在卷模型参数、卷基准测试分数时,真正决定 Agent 能否在生产环境中可靠运行的,不是模型本身,而是包裹模型的那个"壳"——约束、告知、验证、纠正——完整的 Harness 系统。
🐴 模型是马,Harness 是缰绳。好马须配好鞍。
Agent = Model + Harness
在换一匹更贵的马之前,先检查你的缰绳——它通常提供最高的投资回报率。
💬 你遇到过 Agent "脱缰"的问题吗?
是幻觉、工具误用、还是上下文丢失?欢迎在评论区分享你的经历和解决思路
#HarnessEngineering #AIAgent #Agent工程 #AI可靠性 #生产级AI

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)