GitHub 狂揽 4万+ Star!这个项目直接让你省下 60–95% 的 Token
大家好,我是Java1234_小锋老师。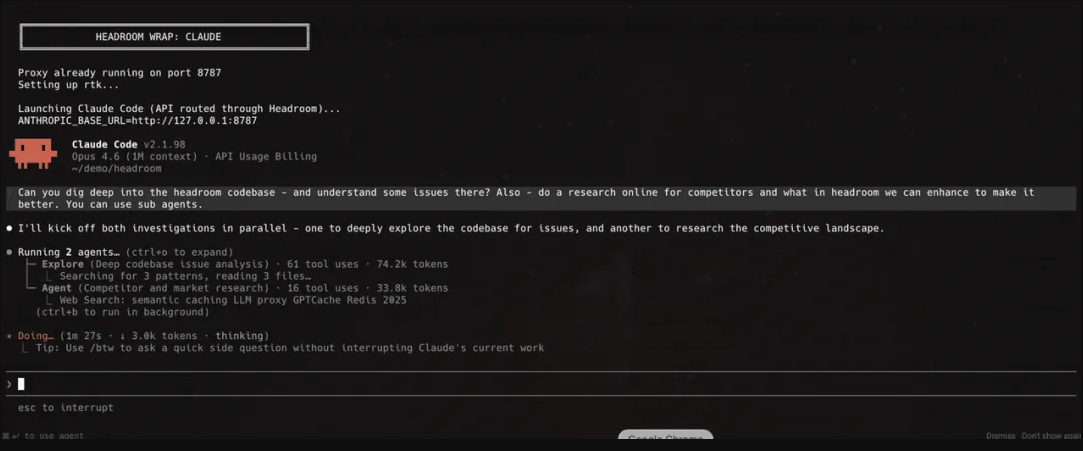
先说说:Token 到底烧在哪了?
如果你经常用 Claude Code、Cursor、Codex 这类 AI 编程助手,大概都有过这种体验:
- 搜一下代码,返回 100 条结果,一下子就是好几万 Token
- 读日志、查 Issue、跑工具,每一轮对话都在往上下文里堆东西
- 模型不仅要「读」你发过去的内容,还要「写」回复——两边都算钱
问题往往不在你的问题本身,而在工具输出、日志、RAG 检索结果、历史对话这些「背景噪音」。它们占了大头,但真正有用的可能只有一小部分。
Headroom 就是专门解决这个问题的。它在你的应用和 LLM 之间加了一层「压缩滤镜」:把要发给模型的内容先瘦身,模型该答对的还是答对,Token 却能少掉 60%~95%。
Headroom 是什么?
Headroom 是一个开源的 AI Agent 上下文压缩层,由 Tejas Chopra 发起,目前在 GitHub 上已有 4 万+ Star。
它压缩的对象包括:
- 工具调用返回的结果(比如代码搜索、文件读取)
- 日志和报错信息
- RAG 检索到的文档片段
- 文件内容和对话历史
几个关键特点:
| 特点 | 说明 |
|---|---|
| 本地运行 | 数据留在你的机器上,不经过第三方 API |
| 可逆压缩 | 原文会缓存在本地,模型需要时可以再取回 |
| 多种接入方式 | 库、代理、MCP 服务器,怎么方便怎么来 |
| 跨 Agent 记忆 | Claude、Codex、Cursor 等可以共享压缩后的上下文 |
它怎么工作的?
可以把 Headroom 想象成一条「预处理流水线」:你的 Agent 本来要直接把一大坨内容扔给模型,现在先经过 Headroom 筛一遍。
简单说就是三步:
- 识别内容类型——JSON 走 JSON 的压缩器,代码走 AST 分析,普通文字走专用小模型
- 智能压缩——去掉重复、冗余和低价值信息,保留关键内容
- 原文备份——压缩后的内容带着一个「哈希 ID」,模型觉得不够用时可以按需取回
另外还有一个 CacheAligner:很多云厂商会对相同前缀做 KV 缓存,Headroom 会尽量让每次请求的前缀保持稳定,让缓存真正命中,进一步省钱。
三种用法,挑一种就行
Headroom 不绑死某一种技术栈,常见有三种接入方式:
1. 代理模式(最省事)
headroom proxy --port 8787
把你的 AI 客户端指向本地 8787 端口,不用改一行业务代码,任何语言、任何框架都能用。
2. 一行命令包装 Agent
headroom wrap claude # 或 codex / cursor / aider / copilot
直接帮你启动代理并拉起对应的编程 Agent,Claude Code、Cursor、Codex 等都支持。
3. 库/SDK 嵌入
Python:
from headroom import compress
compressed = compress(messages, model="claude-sonnet-4-20250514")
TypeScript:
import { compress } from 'headroom-ai';
const compressed = await compress(messages, { model: 'gpt-4o' });
如果你用 LangChain、Agno、Vercel AI SDK、LiteLLM 等框架,也都有对应的集成方式。MCP 客户端可以跑 headroom mcp install,获得 headroom_compress、headroom_retrieve 等工具。
CCR:压缩了还能找回来
传统压缩有个两难:压狠了怕丢信息,压轻了省不了钱。
Headroom 的 CCR(Compress-Cache-Retrieve) 机制把这个矛盾化解了:
也就是说:压缩是 aggressive 的,但数据不是「删掉了」,而是「暂存了」。模型觉得 15 条结果够用就省 90% Token;觉得不够,一个工具调用就能把原文拉回来。
真实场景能省多少?
项目官方在真实 Agent 工作负载上做过测试,数据比较有说服力:
| 场景 | 压缩前 | 压缩后 | 节省比例 |
|---|---|---|---|
| 代码搜索(100 条结果) | 17,765 | 1,408 | 92% |
| SRE 故障排查 | 65,694 | 5,118 | 92% |
| GitHub Issue 分类 | 54,174 | 14,761 | 73% |
| 代码库探索 | 78,502 | 41,254 | 47% |
准确率方面,在 GSM8K、TruthfulQA、SQuAD v2 等基准测试上,压缩前后得分基本持平,有些场景甚至略有提升——去掉噪音后,模型反而更聚焦。
另外,Headroom 还能压缩模型写回来的内容(输出 Token)。开启 HEADROOM_OUTPUT_SHAPER=1 后,可以减少「好的,让我来……」这类废话,以及重复粘贴已有代码的习惯,对 Opus 这类输出单价更高的模型尤其划算。
适合谁用?不适合谁?
比较适合:
- 每天用 AI 编程 Agent,Token 账单看得心疼的人
- 工具输出、RAG 检索结果经常很大的 Agent 应用开发者
- 同时在 Claude、Codex、Cursor 之间切换,想要共享上下文的人
- 需要激进压缩、但又不能接受「压完找不回来」的场景
可以跳过:
- 只用单一云厂商自带的对话压缩,且不需要跨 Agent 能力
- 运行环境完全沙箱化,不能跑本地进程
怎么开始?
安装(Python 3.10+):
pip install "headroom-ai[all]"
或者 Node 环境:
npm install headroom-ai
快速体验三步走:
# 1. 安装(见上)
# 2. 选一种模式
headroom wrap claude # 包装编程 Agent
# 或
headroom proxy --port 8787 # 纯代理模式
# 3. 查看节省效果
headroom perf
首次运行会下载约 500MB 的压缩模型(Kompress-base),之后会缓存在本地,只下一次。
写在最后
AI Agent 时代,上下文管理正在变成和模型选型一样重要的「基础设施」。Headroom 的思路很直接:不是让模型变聪明,而是别让模型读垃圾。
4 万 Star 说明大家确实被 Token 账单折磨得不轻。如果你也在跑 Agent、搭 RAG、或者天天用 Cursor 写代码,不妨花一分钟装个 Headroom 试试——本地跑、开源免费、压缩可逆,试错成本很低。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)