LlamaIndex 和 LangChain 并非绝对的“二选一”竞品,而是互补关系
·
这个 Python 工程架构不仅完全可以,而且是目前构建企业级、生产级 AI 应用的最佳实践之一。
在业界,LlamaIndex 和 LangChain 并非绝对的“二选一”竞品,而是互补关系。将两者结合,能够完美发挥各自的优势,构建出既具备强大检索能力,又拥有复杂业务编排能力的系统。
以下是该架构的合理性分析及落地建议:
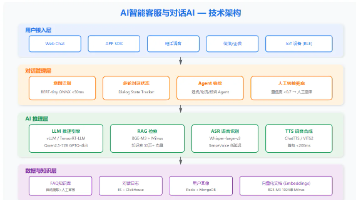
1. 为什么这是一个优秀的架构?
这种架构的核心逻辑是职责分离:
- LlamaIndex 专注“数据与检索”:作为数据框架,它在处理异构数据(PDF、数据库等)、语义级分块、构建复杂索引(如向量、知识图谱)以及重排序(Reranking)方面具有天然优势。它能让大模型更精准地获取上下文,减少幻觉。
- LangChain 专注“编排与交互”:作为通用 LLM 框架,它擅长将多个组件(如提示词、模型、记忆、工具)链接起来,处理多轮对话、多智能体(Agent)协作和复杂工作流。
2. 推荐的落地架构模式(混合架构)
在实际工程中,建议采用**“LlamaIndex 作为检索微服务 + LangChain 作为上层编排”**的架构:
- 底层数据平面(LlamaIndex):使用 LlamaIndex 处理所有文档的加载、分块、Embedding 向量化,并接入 Qdrant 向量数据库。同时,利用其内置的高级检索策略和重排序(Reranker)模型,确保召回的文档片段高度相关。
- 上层推理平面(LangChain):将 LlamaIndex 封装为 LangChain 中的一个“检索工具(Retriever Tool)”或独立的微服务 API。LangChain 的 Agent 在接收到用户请求后,可以调用 LlamaIndex 获取精准知识,再结合其他外部工具(如计算器、网页搜索、SQL查询)完成复杂任务,最后通过 Memory 组件管理多轮对话状态。
3. 该架构的显著优势
- 极致的检索精度:避免了 LangChain 在复杂 RAG 场景下需要大量手动组装检索逻辑的痛点,直接利用 LlamaIndex 成熟的索引和重排序机制。
- 强大的扩展性:当业务需要增加新工具或复杂决策逻辑时,LangChain 的生态和 Agent 能力可以无缝接入,而无需重构底层数据管道。
- 清晰的代码边界:数据治理与业务逻辑解耦,后期无论是更换向量数据库、升级重排序模型,还是调整 Agent 策略,都可以独立进行,极大降低了维护成本。
总结:你规划的 LlamaIndex (Embedding/分块/检索/重排序/Qdrant) + LangChain 架构非常科学。它既保证了知识库问答的“准”,又赋予了应用处理复杂任务的“智”,是非常适合长期迭代的企业级 RAG 系统选型。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)