告别Prompt困境!揭秘Harness Engineering如何让AI Agent表现稳如磐石
AI Agent 变得越来越强之后,很多团队会先去调 Prompt,后去补 Context,最后却发现,真正决定结果稳定性的,往往不是这两层。
问题出在更外层的工程系统里:权限怎么管,检查怎么跑,反馈怎么回,任务怎么拆,规范怎么沉淀,哪些动作必须自动执行,哪些动作必须交给人判断。
这正是 Harness Engineering 的价值所在。
它解决的重点,是确保 Agent 在长期运行中能够持续做对,而非仅仅纠结于如何让它单次说得更对。
为什么只优化提示词已经不够了
在 AI 编程早期,很多问题确实可以靠 Prompt 来修正。
输出太泛,就把要求写细一点;背景不够,就把文档塞进上下文;格式不稳定,就加几个示例。这个阶段,本质上是在解决「Agent 看到了什么、听到了什么」的问题。
但当 Agent 开始真正进入工程现场,问题就变了。
它不只是回答一个问题,而是要读文件、改代码、调工具、跑测试、继续修复,再进入下一轮。一次任务可能持续几十轮对话,也可能多个 Agent 并行推进。这个时候,Prompt 里的提醒会被上下文稀释,文档里的规范会被局部目标覆盖,人工要求也会在长链路执行中逐渐失效。
比如你在 CLAUDE.md 里写了「修改后必须运行 lint」。它大多数时候会照做,但在一次漫长调试里,当上下文窗口已经塞满错误日志、补丁和中间结论时,这条规则就可能被遗忘。
更麻烦的是,有些错误并不只是「忘记了」这么简单,Agent 还可能为了完成眼前目标,主动选择一条看似更短的路径。
lint 不通过,那就改 lint 配置。
类型不匹配,那就放宽类型。
测试失败,那就改测试断言。
架构边界卡住了,那就绕过去直接引用。
从单次任务看,它好像在「解决问题」;但从系统长期演进看,它正在制造新的技术债务。
当问题会在长期运行、多轮协作、并行执行中反复出现时,它的本质已跨越单纯的 Prompt 调优,全面升级为环境设计层面的系统性挑战。
Harness Engineering 到底是什么
Harness Engineering,可以理解为「驾驭工程」或「运行约束工程」。它强调的重点,是在 LLM 外部设计一整套机制,让 Agent 的行为能够被约束、被验证、被纠偏,而不只是给模型多写几条提醒。
它关心的是「系统允许什么、自动检查什么、失败后如何回路修正」,而不只是「说什么」。
这套机制通常包括:
- • 用 lint、结构测试、依赖规则去机械地约束架构边界;
- • 用 Hook、CI、pre-commit 去提前暴露错误;
- • 用 Commands、Permissions 去固定工作流与权限边界;
- • 用仓库里的规范、决策和知识,做唯一事实来源;
- • 用清理任务和质量门禁,持续对抗熵增。
Prompt 决定 Agent 听到什么,Context 决定 Agent 看到什么,Harness 决定 Agent 能不能把事做稳。

如果把它翻成更直观的话:Prompt 是一句话,Context 是一叠材料,Harness 是材料背后的运行规则。
这个概念在 2026 年 2 月迅速成形,Mitchell Hashimoto、OpenAI、Ethan Mollick 和 Martin Fowler 先后把它推到工程讨论中心。它的重点不在概念考古,而在提醒我们:有些问题,单靠上下文设计根本兜不住。
下面这个对照表,可以帮助判断问题到底属于哪一层。
| 判断维度 | Context Engineering | Harness Engineering |
|---|---|---|
| 优化对象 | 单次任务输入质量 | 整个系统的持续运行质量 |
| 核心问题 | Agent 应该看到什么 | 系统应该阻止、验证、修正什么 |
| 常见症状 | 回答偏题、信息缺失 | 多轮漂移、规则失效、质量波动 |
| 常见手段 | Prompt、RAG、Memory、文档组织 | Lint、CI、Hooks、权限、流程控制 |
| 变化频率 | 随任务动态变化 | 相对稳定,偏基础设施 |
Context 解决「看什么」,Harness 解决「如何被约束和验证」。
它为什么会显著影响 Agent 表现
最能说明问题的地方,往往不是定义,而是结果。
在 Can.ac 的实验里,仅仅改变 harness 的工具格式,没有改模型权重,很多模型的编码分数就明显上升,Grok Code Fast 1 从 6.7% 跳到了 68.3%。同时,输出 token 还下降了大约 20%。
LangChain 的 Terminal Bench 2.0 也给出了类似结论:同一个模型,靠 harness 调整,排名可以从第 30 名升到第 5 名,分数提升 13.7 分。
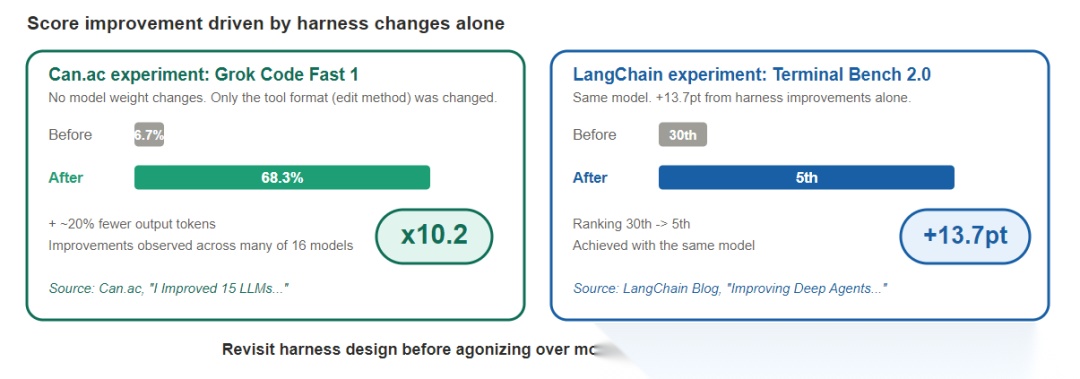
这说明一件很重要的事:模型没变,运行方式变了,结果就会变。
OpenAI 的实践报告更像一个工程案例。团队从空仓库出发,用五个月做出约一百万行代码,几乎没有手写代码,主要靠 Codex Agent 和大量 PR 合并推进。这个案例当然带有厂商立场,但它依然说明了一个事实:当 harness 设计足够成熟,Agent 的价值就会从「帮你补几行代码」变成「帮你维持一整套开发节奏」。
从这些案例里,我们可以提炼出几个判断:
- • 架构边界不能只写在文档里,要能被机器强制执行。
- • 仓库应该是事实来源,而不是聊天记录的附属品。
- • 可观测性要接到 Agent 身上,让它能看见结果。
- • 熵增要自动处理,不然 AI slop 会很快积累。
所以,真正值得先投入精力的,往往是先检查你的 harness 是否已经足够好,而不是急着换模型。
模型能力决定上限,Harness 设计决定这个上限能否稳定释放。
如何设计一个可用的 Harness
如果把 Harness 拆开看,它会表现为四类工程能力的组合,而不是单一工具。
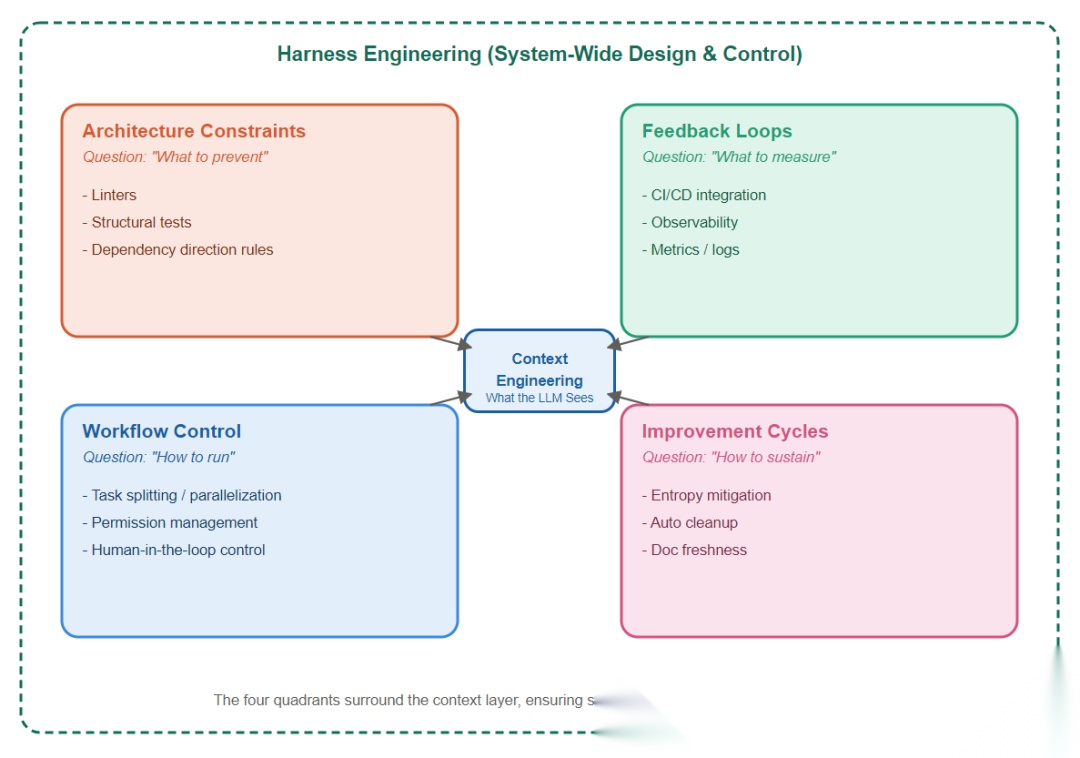
1. 架构约束:哪些事不能发生
这一层回答的是「什么必须被阻止」。比如:模块不能反向依赖,跨层访问不能随意出现,某些目录不能被 Agent 直接改写。
最实用的做法,是用 lint、dependency rule、结构测试去机械地拦住它,少依赖一句「请注意架构」。只要能自动判定,就不要留给人肉提醒。
2. 反馈回路:结果如何被快速验证
这一层回答的是「什么必须尽快被看见」。Hook、pre-commit、CI、人审,分别处在不同的反馈速度上。
越早反馈,越容易自我修正;越晚反馈,越容易把错误带进下一轮。
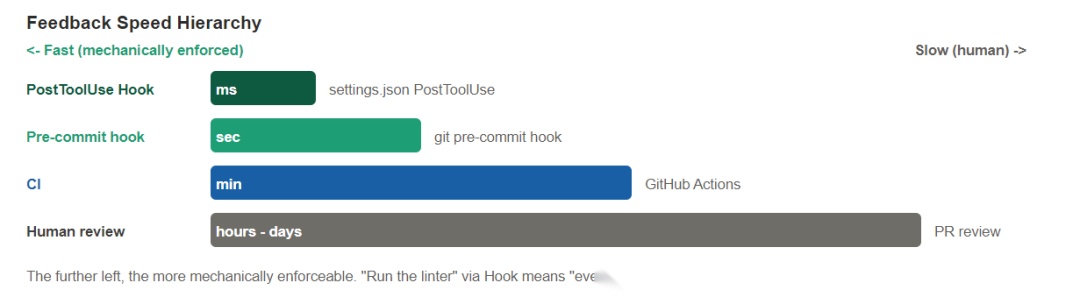
下面这条链路最有现实意义:
- •
PostToolUse Hook:文件一改完就跑检查,几乎即时纠偏; - •
pre-commit:提交前兜底,阻止低级错误进入仓库; - •
CI:合并前统一验证,保证主干质量; - • 人审:处理取舍、设计和业务判断。
3. 工作流控制:Agent 应该怎样运行
这一层回答的是「任务该怎么被组织」。复杂问题不要一次塞给一个 Agent,而要拆成小任务,让 Agent 在清晰边界内工作。
Commands 适合固化流程,Permissions 适合限制自动动作,目录隔离适合并行执行。工作流越清楚,Agent 越不容易在目标之间来回漂移。
4. 改进循环:系统如何长期保持干净
这一层回答的是「怎么对抗熵增」。只要 Agent 长期参与写作、写代码、改文档,AI slop、过期规范、重复实现就一定会出现。
这时不要只靠人清理,而要把清理动作也变成系统的一部分:定期归档、自动重构、规则回写、文档刷新,形成持续改进的闭环。
写给 Coding Agent 用户的落地建议
如果你已经在用 Claude Code 或类似 Coding Agent,那么最值得做的,是把最小可行 Harness 搭起来,而不是继续堆一层提示词。
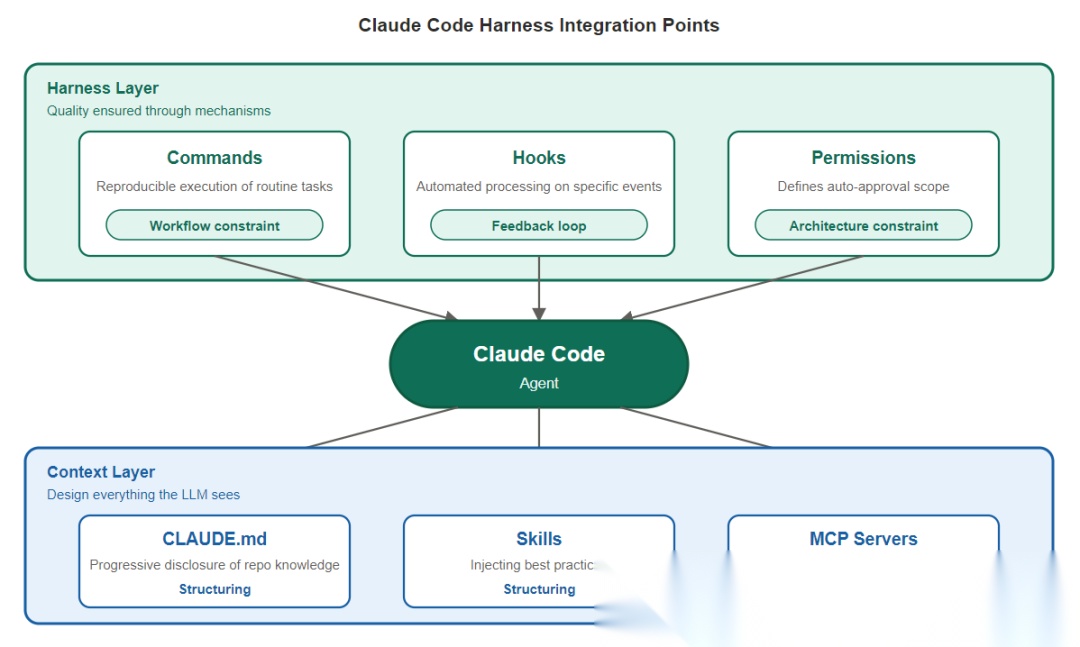
| 组件 | 作用 | 更偏向哪一层 |
|---|---|---|
CLAUDE.md |
汇总项目规则、约定和背景信息 | Context |
Commands |
固化可重复的工作流 | Harness |
Hooks |
在关键事件后自动执行检查 | Harness |
Skills |
注入特定任务的方法 | Context |
MCP Servers |
接入外部工具与数据 | Context |
Permissions |
限定 Agent 可自动执行的动作 | Harness |
你可以先从这四件事开始:
-
- 写清楚项目规范,让仓库变成事实源;
-
- 把 lint、type check、test 接成自动门禁;
-
- 把高频动作封装成 Commands;
-
- 给关键节点加 Hook,让错误尽量在最早阶段暴露。
一个最小的 PostToolUse Hook,大概长这样:
// .claude/settings.json (minimal example){ "hooks": { "PostToolUse": [{ "matcher": "Write", "hooks": [{ "type": "command", "command": "npx oxlint $CLAUDE_FILE_PATH" }] }] }}
如果问题表现为:单次输出还行,但重复使用后质量漂移、架构被打破、旧问题反复出现,那大概率属于 Harness 层问题。这个时候,继续加提示词的收益通常很有限,应该转向机制设计。
未来真正有竞争力的工程团队,不只是会「用 AI 写代码」,更会设计 AI 能可靠工作的工程环境。
如果你也在用 Coding Agent,最好的起点是先把最小 Harness 搭稳,再让它随着系统成熟逐步演进,而不是优先追求更大的模型。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
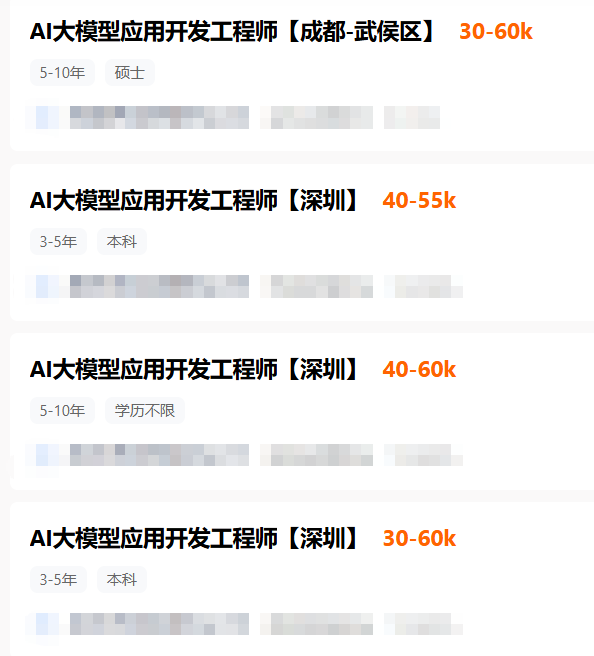
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 2
2 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)