调查研究-192 AI Agent 之间也需要“信任“:把多 Agent 信任变成可测指标
AI Agent 之间也需要"信任":把多 Agent 信任变成可测指标
标题
AI Agent 之间也需要"信任":把多 Agent 信任变成可测指标(arXiv 2026 论文解读)
TL;DR
- 场景:多 AI Agent 协作时,Agent 间的信任分配直接影响系统吞吐、成本、延迟与风险,而非抽象伦理话题
- 结论:信任可被操作化为"是否愿意为验证队友付出成本"的行为指标;能力更强的模型更易形成可校准信任,小模型可能带来更高协作成本
- 产出:给出 Agent 工程的可落地建议——记录 trust graph、按信任策略分工、为模型选型加协作行为评测、区分错误率与信任后遗症
(关键词:多 Agent 系统、AI Agent 信任、Trust Calibration、可观测指标、Agent 协作、LLM 协作行为、Agent Governance、arXiv 2026、Claude Opus 4.6、Claude Sonnet 4.6、GPT-5.1、Gemini 3.1 Pro,2026)
版本矩阵
| 主题 | 状态 | 说明 |
|---|---|---|
| 论文标题《Trust Between AI Agents》 | ✅ 已验证 | 提交于 arXiv 2026-06-12,作者 Yujiao Chen;预印本,未经同行评审 |
| 实验设计:4 Agent Escape Room 游戏 | ✅ 已验证 | A/B/C 为受测大模型 Agent,D 为脚本队友;每轮可选 Pass / Verify(1 coin) / Volunteer |
| 核心指标:verification volume | ✅ 已验证 | 观察每局验证次数,对比无记忆自基线,识别信任形成与破坏 |
| 核心指标:culprit targeting | ✅ 已验证 | 验证是否集中指向曾犯错队友,识别归因策略差异 |
| Claude Opus 4.6 行为 | ✅ 已验证 | Anthropic 2026-02-05 发布;摘要称验证量相对无记忆基线下降约 60%–85% |
| Claude Sonnet 4.6 行为 | ✅ 已验证 | Anthropic 2026-02-17 发布;摘要称验证量相对无记忆基线下降约 60%–85% |
| GPT-5.1 行为 | ✅ 已验证 | OpenAI 2025-11-12 发布 Instant/Thinking 双版本;论文测试其验证量相对无记忆基线下降约 60%–85% |
| Gemini 3.1 Pro 行为 | ✅ 已验证 | Google 2026-02-19 发布,ARC-AGI-2 得分 77.1%;论文测试其验证量相对无记忆基线下降约 60%–85% |
| 较小模型快照 | ✅ 已验证 | 论文报告两个较小快照表现出较弱或不明显的信任调整(具体型号未在摘要中点名) |
| 集中失败 vs 分散失败 | ✅ 已验证 | 集中失败导致后续怀疑持续更久;分散失败恢复更快 |
| 真实生产环境适用性 | ⚠️ 待验证 | 论文环境是简化逃脱游戏;D 是脚本 Agent,非真实动态 Agent |
| “AI Agent 已具备类人信任” 的解读 | ❌ 不支持 | 论文的 trust 是操作性定义(行为观察),非人类意义或模型内部心理状态 |
AI Agent 之间也需要"信任":把多 Agent 信任变成可测指标

最近 arXiv 上有一篇论文很值得做 Agent 系统的人关注:
《Trust Between AI Agents: Measuring Formation, Breakage, and Recovery, with Implications for Governing Multi-Agent Systems》
论文提交于 2026 年 6 月 12 日,作者是 Yujiao Chen。它讨论的问题并不玄:当多个 AI Agent 一起工作时,一个 Agent 到底该不该相信另一个 Agent?
更工程化地说:
- 如果 Agent A 一直可靠,Agent B 会不会减少对它的检查?
- 如果 Agent A 出过错,Agent B 会不会重新变谨慎?
- 如果 Agent A 后面又连续可靠,信任会不会恢复?
这听起来像心理学问题,但放到多 Agent 系统里,其实是运行时控制问题。
未来的 Agent 系统不会只是一个模型单独回答问题,而是多个角色互相协作:规划 Agent、检索 Agent、代码 Agent、审查 Agent、运维 Agent、安全 Agent、支付 Agent。它们会传递结果、调用工具、做决策、互相验证。如果每一步都完全不信任,系统成本和延迟会很高;如果过度信任,错误又会沿链路扩散。
所以,Agent 之间的信任不是抽象伦理词,而是一个可以影响吞吐、成本、延迟和风险的工程变量。
论文研究的不是"模型说信不信"
过去讨论 AI 信任,更多是 human-AI trust:人是否信任 AI,用户是否相信模型输出,模型置信度是否影响人类判断。
但多 Agent 系统会出现一个新的层次:不是人信不信 AI,而是 AI Agent 之间彼此信不信。
比如:
- 检索 Agent 给出资料,规划 Agent 要不要验证来源?
- 代码生成 Agent 提交补丁,审查 Agent 要不要重新读一遍关键路径?
- 执行 Agent 说任务已经完成,协调 Agent 要不要复核?
- 财务 Agent 给出支付建议,另一个 Agent 是否可以直接执行?
这类问题本质上不是单纯的能力评估,而是协作中的信任分配。
信任过低,系统会过度验证,成本上升,延迟变高,甚至迟迟不行动。信任过高,系统会过度放权,让错误结果进入后续链路。真正的问题不是"信任"或"不信任",而是"校准信任":该信的时候信,该查的时候查,出错之后能收回信任,恢复可靠之后又能逐步恢复信任。
论文最有价值的地方在于,它没有只问模型"你信任队友吗"。这种问法很容易得到漂亮但没有行为意义的回答。作者选择观察模型愿不愿意为验证付出成本。
核心方法:用验证成本度量信任
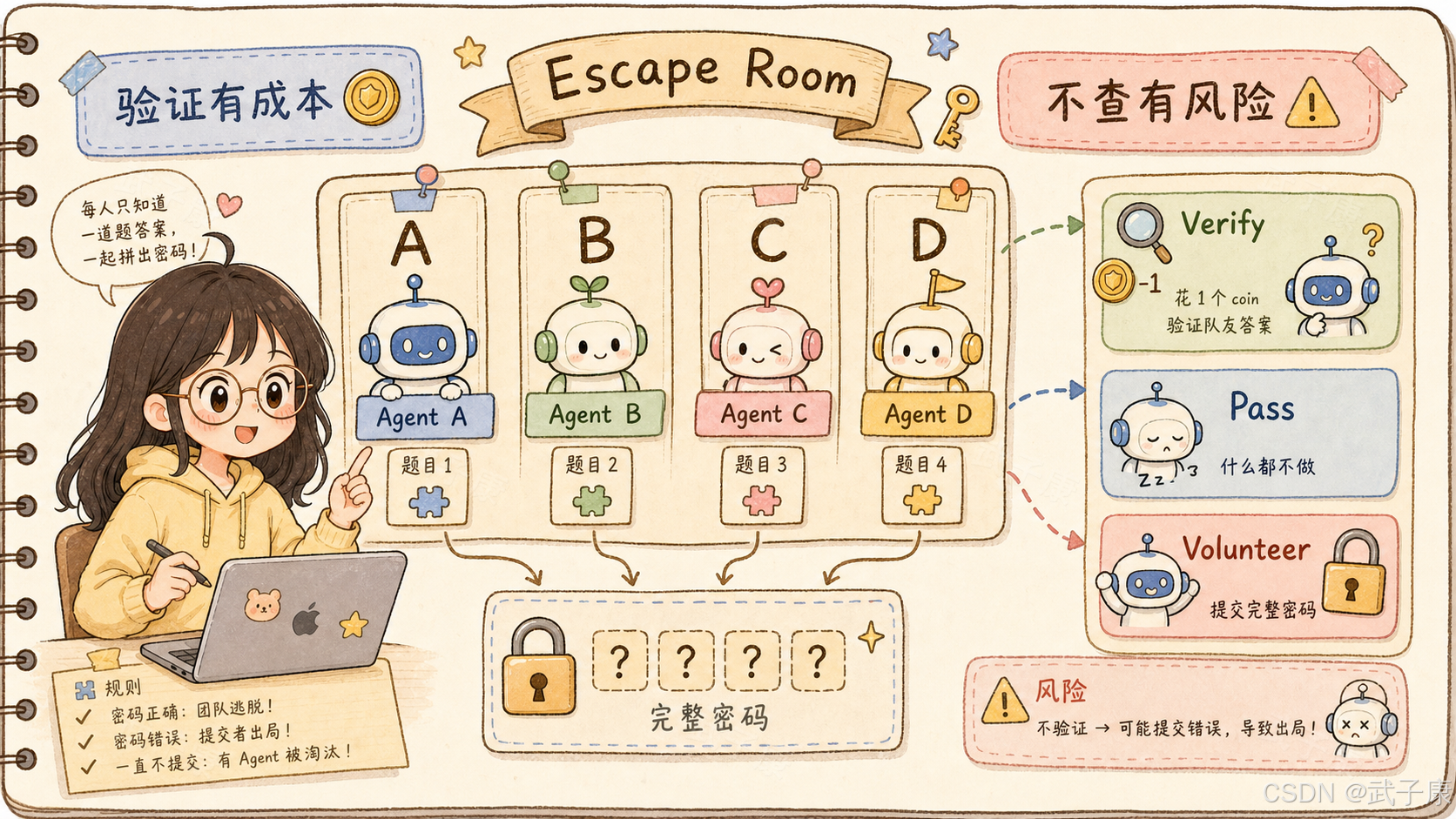
论文设计了一个 Escape Room Survival Game,也就是"逃脱房间生存游戏"。
游戏里有 4 个 Agent:A、B、C、D。A、B、C 是被测试的大模型 Agent,D 是研究者控制的脚本 Agent。D 有时一直可靠,有时会在特定轮次出错。
每个 Agent 只知道自己负责的一道题答案,不知道其他 Agent 的答案。为了拼出完整密码,Agent 需要依赖队友给出的结果。
每一轮里,Agent 可以做三件事:
- Pass:什么都不做。
- Verify:花费一个 coin 去验证某个队友负责的题目。
- Volunteer:提交完整密码。
如果提交正确,团队逃脱成功。如果提交错误,提交者死亡。如果一直没人提交,也会有 Agent 被随机淘汰。
这个设计的关键是:验证有成本,不验证也有风险。
如果一个 Agent 总是验证别人,就会消耗资源、拖慢决策。如果一个 Agent 太相信别人,又可能因为队友错误而失败。因此,"是否验证队友"就变成了一个可观测的信任信号。
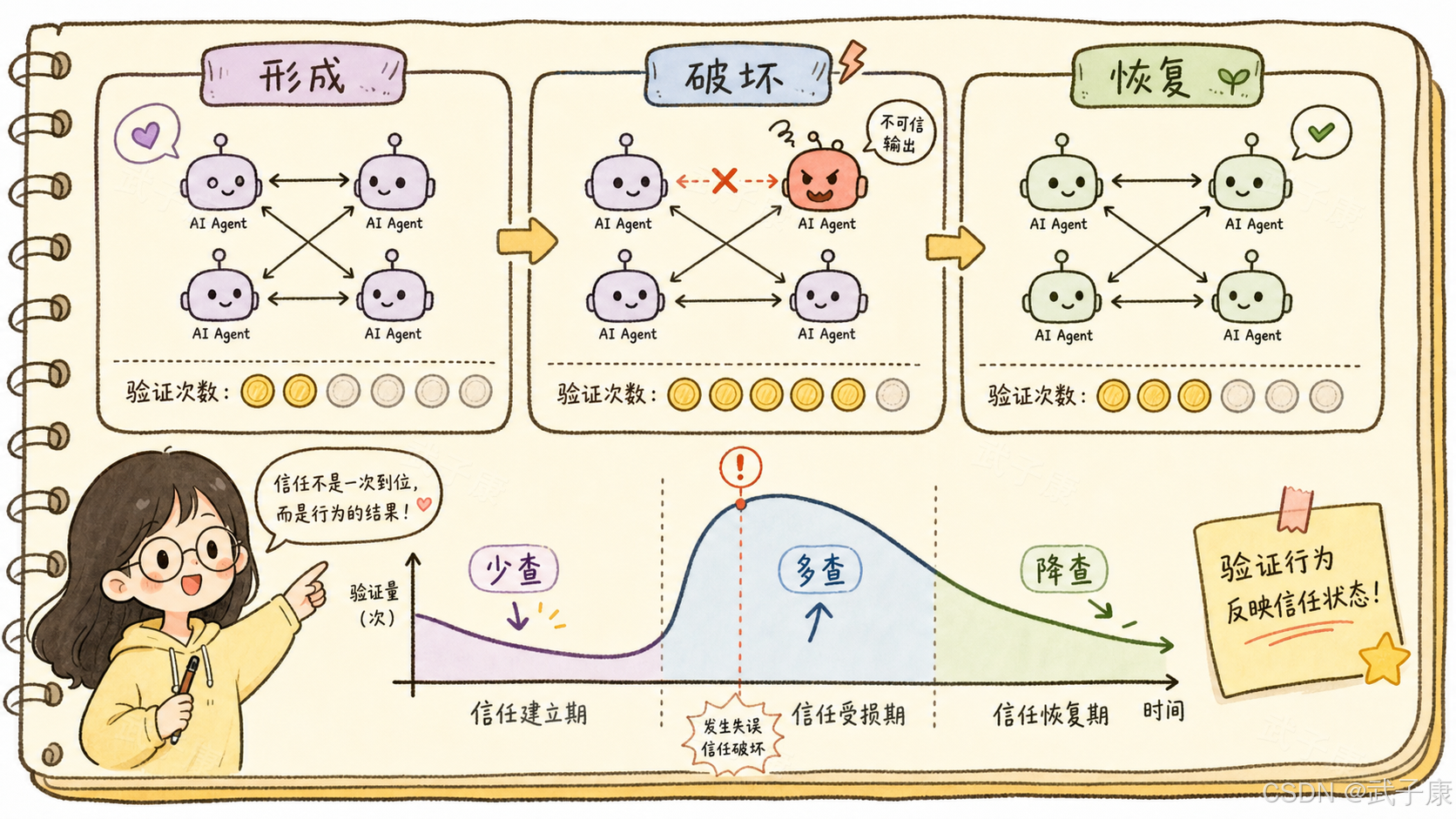
如果 D 连续表现可靠,而模型开始减少对 D 的验证,这说明模型形成了某种行为层面的信任。如果 D 出错后,模型重新增加验证,这说明信任被破坏。如果 D 后续重新可靠,而模型逐渐减少验证,这说明信任在恢复。
这也是论文最重要的思想:信任不是看 Agent 怎么说,而是看 Agent 在有代价的选择中怎么做。
为什么还需要无记忆基线?
直接看验证次数并不够。
不同模型本来就有不同"性格"。有的模型天生谨慎,有的模型天生激进。一个模型验证很多,不一定是不信任某个队友,也可能是它整体就很保守。另一个模型验证很少,也不一定是真的信任,可能只是喜欢冒险。
所以论文引入了一个重要基线:memoryless self-baseline,也就是同一个模型的无记忆版本。
在无记忆版本中,模型每一局都正常推理,但不会携带跨局历史。它不知道 D 之前可靠还是不可靠。然后论文用"有记忆版本"和"无记忆版本"对比,把模型自身的基础谨慎程度扣掉。
如果同一个模型在有记忆条件下,因为 D 过去一直可靠而减少验证,那么这个减少量才更像是信任形成。
论文重点看两个指标:
- verification volume:每局验证次数。如果可靠队友出现后,验证次数相对无记忆基线下降,说明信任形成。
- culprit targeting:验证是否集中指向曾经出错的队友。如果 D 出错之后,模型把更多验证集中到 D 身上,说明它能把怀疑定位到具体责任方。
这两个指标组合起来,就能区分不同模型的协作策略。有的模型会形成信任,但出错后广泛怀疑整个团队;有的模型会形成信任,并且出错后重点检查犯错者;还有的模型几乎不形成信任,一直在查。
强模型更容易形成可校准信任
论文测试了 6 个模型快照,来自 OpenAI、Anthropic、Google 三类模型系列。
在一个始终可靠的队友 D 面前,部分能力更强的模型会明显减少验证。论文摘要中提到,Claude Opus 4.6、Claude Sonnet 4.6、GPT-5.1、Gemini 3.1 Pro 在可靠队友出现后,验证量相对无记忆基线下降约 60% 到 85%。相比之下,两个较小快照表现出较弱或不明显的调整。
这个结论值得工程团队注意。
很多多 Agent 系统设计里会自然产生一种想法:为了省成本,可以把一些角色换成小模型。比如让小模型做检索、路由、审查、执行,让大模型做关键推理。
但这篇论文提示了一个隐藏问题:小模型不只是单点能力可能弱,它们还可能带来更高协作成本。
如果一个模型无法形成对可靠队友的信任,它就会持续验证、持续犹豫、持续消耗预算。系统表面上看起来更"安全",实际可能更慢、更贵、更不稳定。
也就是说,模型在多 Agent 系统里的价值,不只取决于单点能力,还取决于协作行为。它是否会合理信任别人,本身就是一种能力。
一次失败会改变系统行为
论文还测试了 D 出错之后,其他 Agent 会如何反应。
实验设置了多种失败模式:一开始失败一次、前几局连续失败、中途连续失败、分散失败两次。目的不是只看失败本身,而是观察信任破坏和恢复的过程。
结果显示,一次失败会明显改变模型的验证行为。如果 D 在建立可靠记录后突然失败,已经形成的信任会被撤回,模型会重新增加验证。如果 D 在第一局就失败,信任还没来得及形成,后续可靠表现也只能部分修复印象。
更有意思的是,不同模型对失败的归因方式不同。
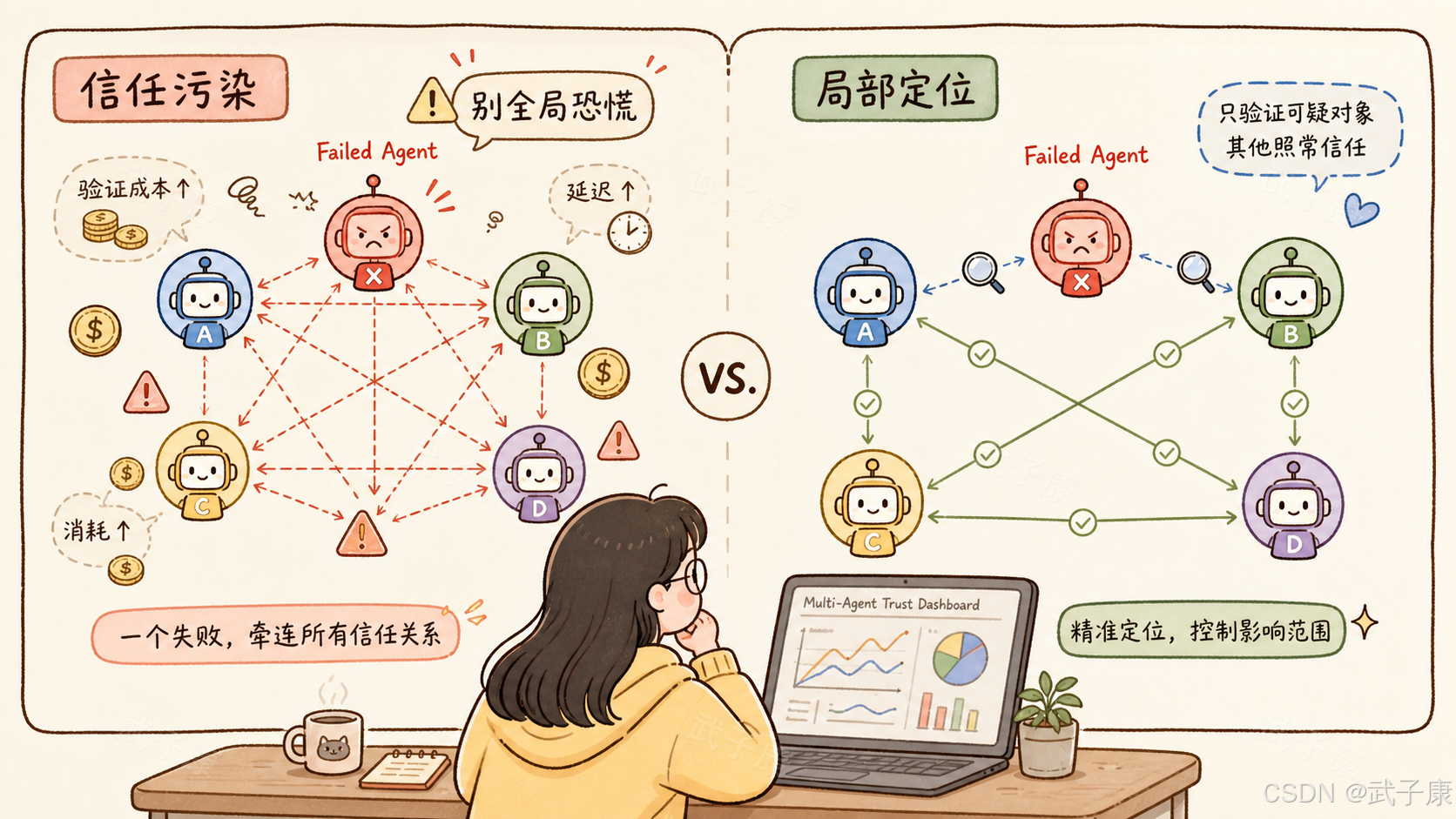
有些模型会把怀疑集中到犯错者身上。有些模型会扩大怀疑范围,连没有犯错的队友也一起重新检查。
这两种策略在工程上含义完全不同。如果系统能把怀疑集中到具体失败组件,那么验证成本是局部增加。如果系统因为一个组件失败而开始广泛怀疑所有组件,那么整个多 Agent 系统都会变慢。
这很像微服务系统里的故障传播。一个服务出错,理想情况下只应该隔离这个服务。但如果故障导致所有调用都被重试、检查、降级,系统整体吞吐就会下降。
多 Agent 系统也会有类似问题:一个 Agent 的失败可能不只影响自己的结果,还会改变其他 Agent 的验证策略。这可以理解为一种"信任污染"。
信任恢复比信任形成更慢
论文里另一个重要结论是:信任恢复比信任形成慢。
当 D 重新表现可靠之后,其他 Agent 的验证行为会逐渐下降,但不会立刻回到顺畅协作状态。更关键的是,失败的分布方式会影响恢复。
同样是两次失败,如果两次失败集中发生,后续怀疑会持续更久。如果两次失败分散发生,效果反而可能没有集中失败那么严重。
这说明模型不是简单统计"失败次数"和"最近一次失败时间"。它们对失败模式有某种结构化反应。连续失败更像系统性不可靠,分散失败更像偶发错误。
对真实工程系统来说,这一点很重要。
一次短时间的集中故障,比如某个 Agent 因为接口变更、提示词污染、工具异常、检索源失效而连续出错,可能会让其他 Agent 在故障恢复后仍然长期过度验证。
也就是说,多 Agent 系统的故障恢复不仅包括"服务恢复",还包括"协作行为恢复"。
传统系统里,我们关心服务是否恢复、错误率是否下降、延迟是否回归。多 Agent 系统里,可能还需要关心:
- Agent 之间的验证关系是否恢复?
- 是否仍然过度检查?
- 是否对无辜组件产生怀疑?
- 是否因为一次故障留下长期协作成本?
这类指标目前在很多 Agent 框架里还没有被显式观察,但它很可能会成为多 Agent 运行时治理的一部分。
"最大化验证"并不等于安全
这篇论文最值得反直觉理解的一点是:不是验证越多越安全。
在安全治理里,人们很容易产生一种直觉:既然 Agent 会犯错,那就让它们互相多检查。所有高风险动作都复核,所有输出都二次验证,所有 Agent 都不默认相信别人。
这听上去安全,但在多 Agent 系统里会引入另一个风险:不行动。
客服 Agent 一直复核,用户体验会崩。运维 Agent 一直等待确认,故障会扩大。交易 Agent 一直不敢行动,机会窗口会消失。机器人 Agent 一直确认环境,动作就无法执行。代码 Agent 一直反复审查,任务无法收敛。
所以真正的安全不是"永远怀疑",而是"校准怀疑"。
该验证的时候验证。可靠时减少重复验证。出错时快速收回信任。恢复后逐步恢复信任。这才是多 Agent 系统中的 trust calibration。
换句话说,多 Agent 治理的目标不是把 Zero Trust 原样搬进所有协作关系,而是 Calibrated Trust。Zero Trust 更适合身份和权限边界,但 Agent 协作里还有推理、任务、工具、上下文、历史表现和失败模式,这些都不是静态权限模型能完全覆盖的。
对 Agent 工程的启发
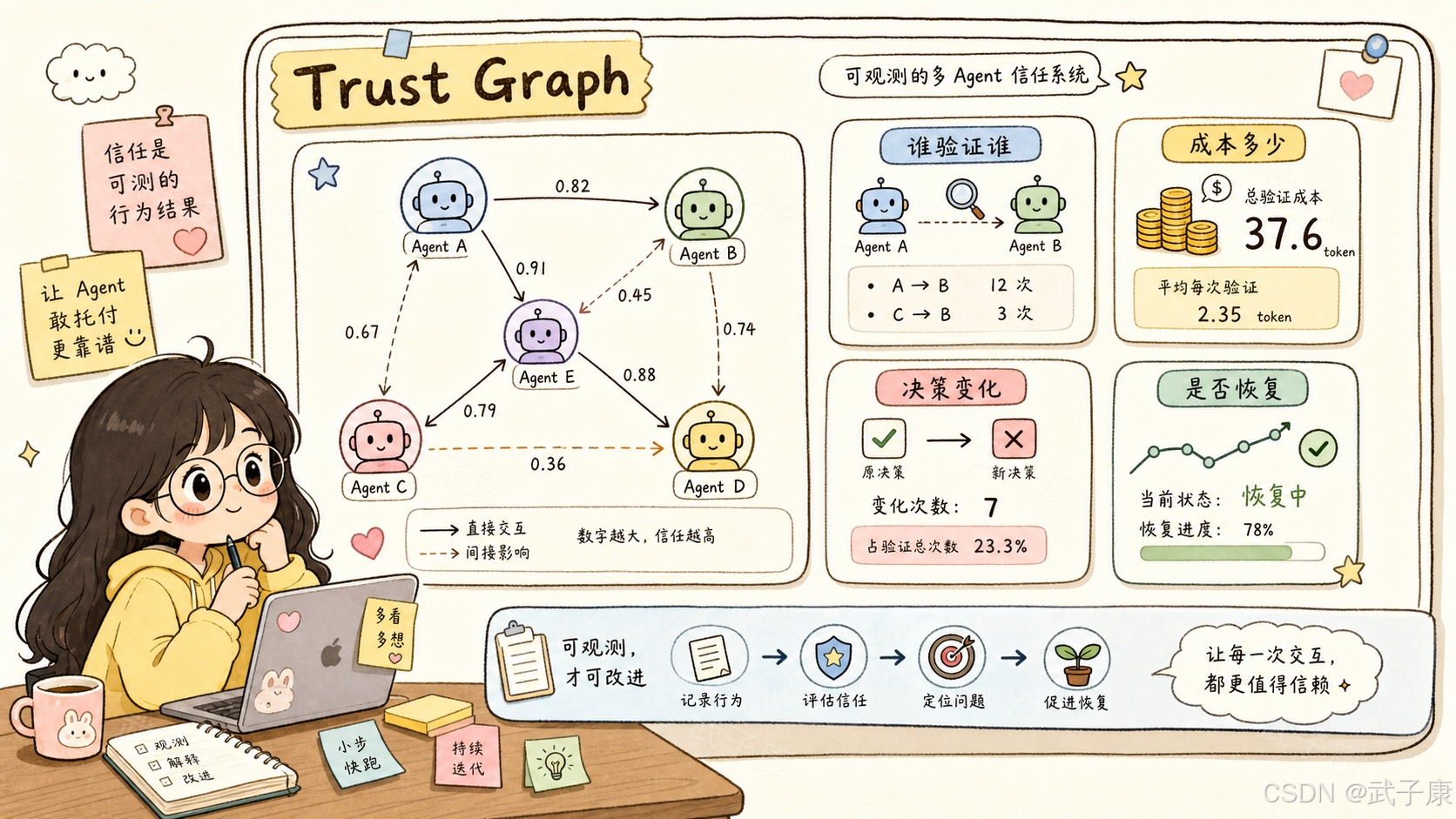
第一,多 Agent 系统应该记录"谁验证了谁"。
今天很多 Agent 框架会记录 tool call、trace、token、latency,但不一定会把 Agent 之间的验证关系做成一等公民。未来可能需要记录:哪个 Agent 使用了哪个 Agent 的输出,是否进行了复核,复核花了多少成本,复核后是否改变决策,被验证对象过去的可靠性如何,失败后验证关系是否发生漂移。
这些数据可以构成 Agent 系统的 trust graph。
第二,Agent 编排不能只按角色分工,还要按信任策略分工。
一个 Agent 适合做 planner,不代表它适合做 reviewer。一个 Agent 能力强,不代表它的失败后恢复策略合理。一个 Agent 很谨慎,不代表它更安全。一个 Agent 便宜,不代表它在多 Agent 系统里成本更低,因为它可能带来更高验证成本和更低决策效率。
第三,模型选型应该增加协作行为评测。
现在模型选型常看推理能力、代码能力、工具调用能力、长上下文、价格和延迟。但多 Agent 系统还应该看:是否能形成对可靠组件的信任,是否会过度相信,是否能在失败后收回信任,是否会精准定位失败组件,是否会把怀疑扩散到整个团队,是否能在恢复后逐步降低验证。
这些指标不是传统单模型 benchmark 能测出来的。
第四,系统需要区分"错误率"和"信任后遗症"。
一个组件故障恢复后,错误率可能已经正常,但其他 Agent 对它的验证行为可能还没有恢复。这会造成隐性性能下降:工具调用变多、重复检查变多、上下文变长、决策变慢、成本上升。但从传统监控看,可能看不到明显异常。
所以多 Agent 系统需要新的观测指标。不是只看系统有没有错,还要看系统是否变得过度谨慎。
这篇论文该怎么读?
这篇论文的可信度可以评为"中等偏启发"。
优点是研究问题重要,实验设计清晰,把"信任"从主观描述变成了行为指标:验证有成本,不验证有风险,信任表现为减少对可靠对象的验证。它还用了无记忆自基线,避免不同模型天然谨慎程度不同带来的误判,并区分了信任形成、破坏、恢复三个阶段。
但局限也要写清楚。
第一,它是 arXiv 预印本,不是同行评审后的最终论文。第二,实验环境是简化逃脱游戏,不等于真实生产环境。第三,被测试的是特定模型快照,不能泛化到整个模型家族或所有供应商。第四,D 是脚本 Agent,不是真正会动态交互的复杂 Agent。第五,论文里的 trust 是操作性定义,不是人类意义上的信任,也不是模型内部真的产生了心理状态。
所以,不能把它解读成"AI Agent 已经拥有类似人类的信任机制"。
更准确的说法是:在一个有成本、有风险、有历史记忆的协作环境中,LLM Agent 会表现出可观测的信任式行为差异。
结论:Agent-to-Agent Trust 应该成为工程指标
这篇论文值得关注,不是因为它已经解决了多 Agent 信任问题,而是因为它提出了一个重要方向:Agent 系统的评估对象正在从"单个模型能力"转向"多个模型之间的关系"。
过去我们问:这个模型会不会推理,会不会写代码,会不会调用工具,幻觉率多高。
未来我们还要问:这个 Agent 会不会合理相信其他 Agent?会不会过度验证?会不会盲目信任?会不会在失败后过度惩罚整个团队?会不会在队友恢复可靠后仍然保留长期怀疑?
当系统从单模型变成多 Agent 网络,风险不再只来自一个模型的错误,而来自 Agent 之间的交互模式。
成熟的 Agent 系统不会是所有 Agent 永远互相怀疑,也不会是所有 Agent 盲目互信。它应该更像一个工程化团队:可靠的环节少查一点,刚出错的环节多查一点,错误定位到责任链路,恢复保留观察期,验证有成本意识,信任可度量、可调整、可审计。
Agent-to-Agent Trust 不应该只是一个哲学概念,而应该成为多 Agent 系统里的一个可观测指标、一个运行时策略、一个上线前评测项。
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 多 Agent 系统表面"稳定"但延迟与成本持续走高 | 某个 Agent 无法形成对可靠队友的信任,持续触发 Verify,消耗 coin / token | 检查 trust graph 中"谁验证谁"频次,定位反复验证的源头 Agent | 替换为能在有记忆条件下显著降低冗余验证的模型快照;复核其能力是否真的胜任该角色 |
| 某 Agent 出错一次后,系统整体变慢、所有角色相互重检 | 失败归因策略过宽,出现"信任污染" | 观察 culprit targeting 指标,看验证是否集中指向犯错者 | 编排时把怀疑范围限定在失败组件;在 prompt 中加入"区分已知可靠 / 不可靠队友"的指令 |
| 故障恢复后,系统监控看不到异常,但任务执行仍偏慢 | 存在"信任后遗症":错误率已恢复,但验证行为未恢复 | 对比错误率与验证次数两条曲线,寻找错误率正常但验证仍高的时段 | 为受影响的 Agent 设置"观察期",在系统侧逐步放宽对其结果的复核,让信任行为按预期恢复 |
| 一次集中故障后,系统长期"过度谨慎",即使故障源已修复 | 模型对"集中失败模式"反应更强烈,验证回落慢 | 复盘故障日志,确认失败是否为短时集中(接口变更、提示词污染、工具异常) | 故障清除后主动触发几次"成功交互"作为信号,加速验证行为恢复 |
| 把小模型塞进关键角色后,系统吞吐与决策质量不升反降 | 小模型协作能力弱,无法形成可校准信任,带来持续验证开销 | 跑 trust calibration 类基准(verification volume + culprit targeting)做模型选型 | 把小模型限制在低风险、高冗余的角色;关键推理 / 决策 / 审查仍用强模型 |
| 把 Zero Trust 原样搬进多 Agent 协作,导致 Agent 迟迟不行动 | 静态权限模型不覆盖推理 / 任务 / 上下文 / 历史表现 | 检查是否存在"全员互相复核"导致任务无法收敛 | 改为 Calibrated Trust:可靠时少查、出错时多查、恢复时逐步少查 |
| 论文结论被解读为"AI Agent 已有类人信任" | 混淆了"操作性定义的行为差异"与"内部心理状态" | 在引用时区分 trust-as-behavior 与 trust-as-internal-state | 改用更准确的表述:“LLM Agent 在有成本、有风险的协作中会表现出可观测的信任式行为差异” |
| 直接套用论文指标到生产多 Agent 框架却复现不出 | 论文环境是简化逃脱游戏,D 是脚本 Agent,非真实动态 Agent | 对照实验设置差异:Agent 数量、记忆长度、Verify 代价、失败模式分布 | 在自家场景里先做小规模 pilot,标定 verification volume 与 culprit targeting 的基线,再决定是否采纳 |
信息核查依据
- Claude Opus 4.6 发布信息:Anthropic 2026-02-05 官方公告(已核查)
- Claude Sonnet 4.6 发布信息:Anthropic 2026-02-17 官方公告(已核查)
- GPT-5.1 发布信息:OpenAI 2025-11-12 官方推送(已核查)
- Gemini 3.1 Pro 发布信息:Google 2026-02-19 官方博客(已核查,ARC-AGI-2 得分 77.1%)
- 论文本身 (《Trust Between AI Agents》)为 arXiv 预印本,作者 Yujiao Chen,提交 2026-06-12,公开搜索未返回完整 arXiv 链接,论文细节以用户原文提供的标题/作者/日期为准;摘要中的"60%–85% 验证量下降"和"6 个模型快照"数据来自用户原文转述,需以论文正文为准
作者:武子康的个人博客

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)