AI Agent 记忆压缩:长对话不崩,成本不炸,关键决策不丢
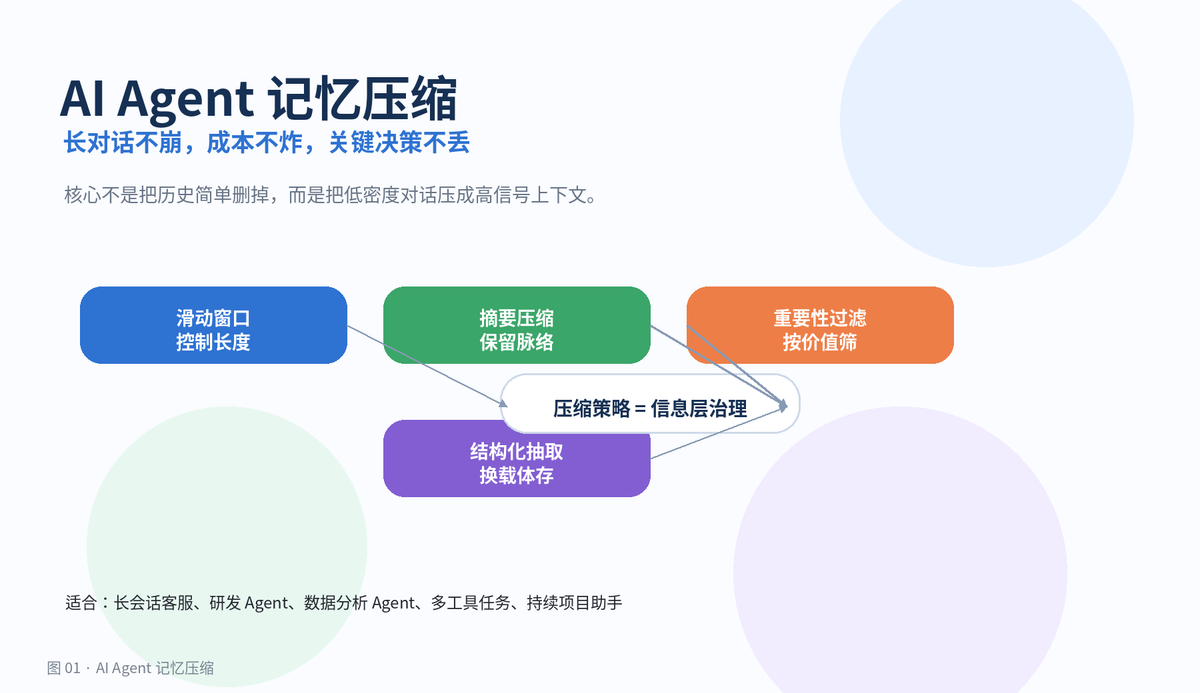
记忆压缩不是“把聊天记录删掉”,而是把低密度历史变成高信号上下文,让 Agent 在有限窗口里继续保持目标、决策和约束的一致性。
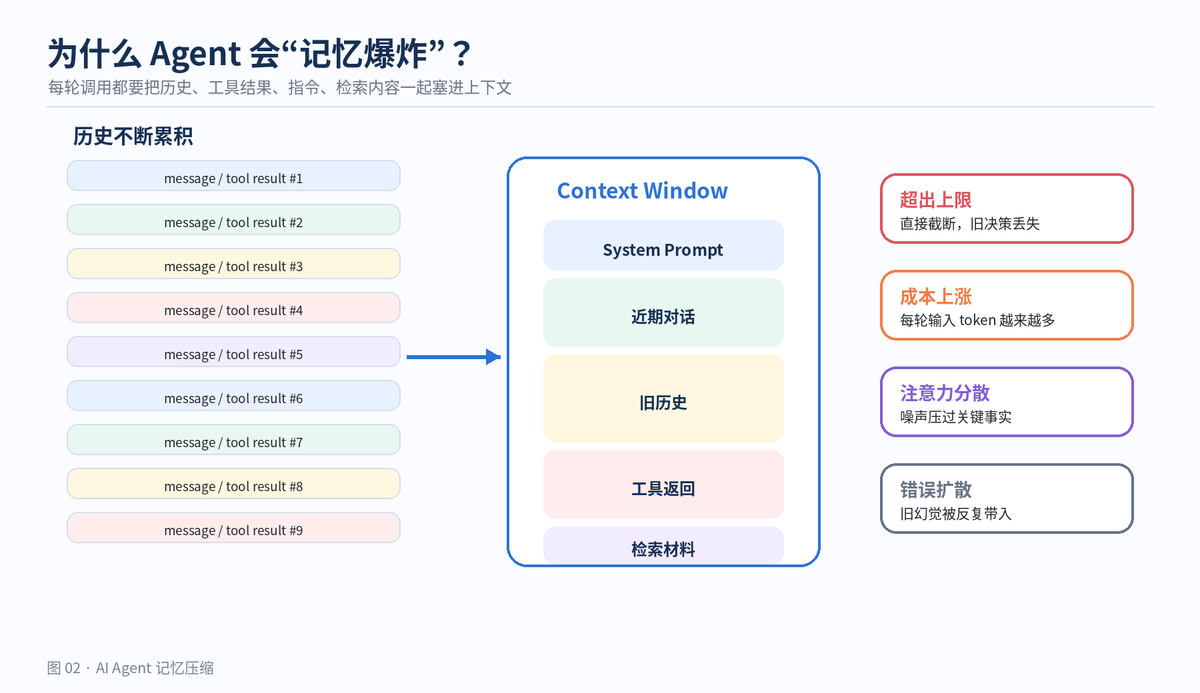
做 Agent 的时候,最容易踩的坑不是模型不会回答,而是它聊着聊着开始“忘事”。前面明明确认过方案 B,后面又重新推荐方案 A;用户已经说预算只有 5 万,下一轮又给出 20 万方案。表面看是模型不稳定,本质上往往是上下文管理失控。
LLM 每次生成回答时,依赖的是本次请求传入的上下文。对话历史、工具返回、检索材料、系统提示词、业务规则,都会挤在同一个 context window 里。窗口有限,成本也有限,噪声更是会干扰推理。
记忆压缩要解决三件事:
第一,别让历史撑爆上下文;
第二,别让无关内容拖慢推理;
第三,别把关键决策、约束和状态压没了。
1. 记忆压缩到底在压什么?
很多人把记忆压缩理解成“只保留最近几轮”。这只是最粗糙的一种做法。真正的工程视角,是把记忆分成三层:
原始日志:每条用户消息、助手回复、工具调用、工具结果都完整保留,用于审计和回放。
工作上下文:每次调用模型时真正塞进 prompt 的内容,必须短、准、干净。
长期记忆:用户偏好、关键决策、项目状态、实体关系等高价值信息,不能只靠原始对话保存。
压缩的目标不是删除历史,而是减少“当前这一步要读的 token”。原始日志可以保留在数据库里,模型当前只需要看到与任务相关、信息密度高、互相不冲突的那部分。
这一点和上下文工程的思路一致:Agent 需要把正确的信息放进上下文,而不是把所有信息都放进去。长上下文不是免费的,过多上下文会带来成本、延迟、注意力分散和错误传播。
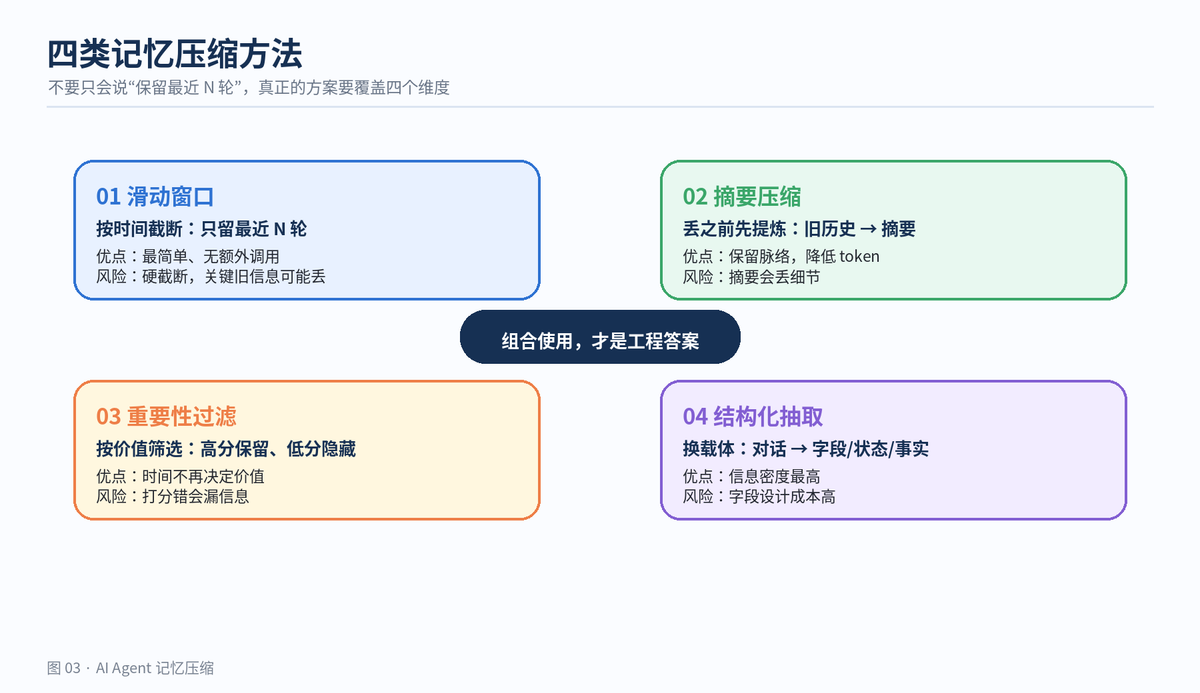
2. 方法一:滑动窗口,最简单也最危险
滑动窗口就是只保留最近 N 轮对话,超出的旧消息直接移出 prompt。它像手机聊天窗口,只显示最近内容。
它的优点非常明显:实现简单、没有额外 LLM 调用、延迟低、成本低。对短问答、一次性任务、历史依赖弱的场景,滑动窗口完全够用。
但它的缺点也很致命:按时间删除,不按价值删除。三周前确认的关键决策,可能比昨天的闲聊重要得多,但滑动窗口会先把它丢掉。

滑动窗口按时间截断,容易误删早期关键决策
一个最小实现如下:
def trim_messages(messages, max_turns=8):
"""只保留最近 max_turns 轮消息。适合短对话,不适合关键状态依赖强的任务。"""
if len(messages) <= max_turns:
return messages
return messages[-max_turns:]工程建议:滑动窗口可以做兜底,但不要单独承担“长期记忆”。复杂 Agent 至少要配合摘要或结构化记忆。
3. 方法二:摘要压缩,丢之前先提炼
摘要压缩是对滑动窗口的改进。旧历史即将被移出 prompt 时,不直接丢,而是先压成一段摘要。后续 prompt 中保留这段摘要,再加上最近几轮原文。
这个方案最适合长对话。近期消息保留细节,远期历史保留脉络。它的关键不在“总结”,而在“结构化总结”。如果只是让模型随便写一段摘要,很容易把以后需要的细节漏掉。
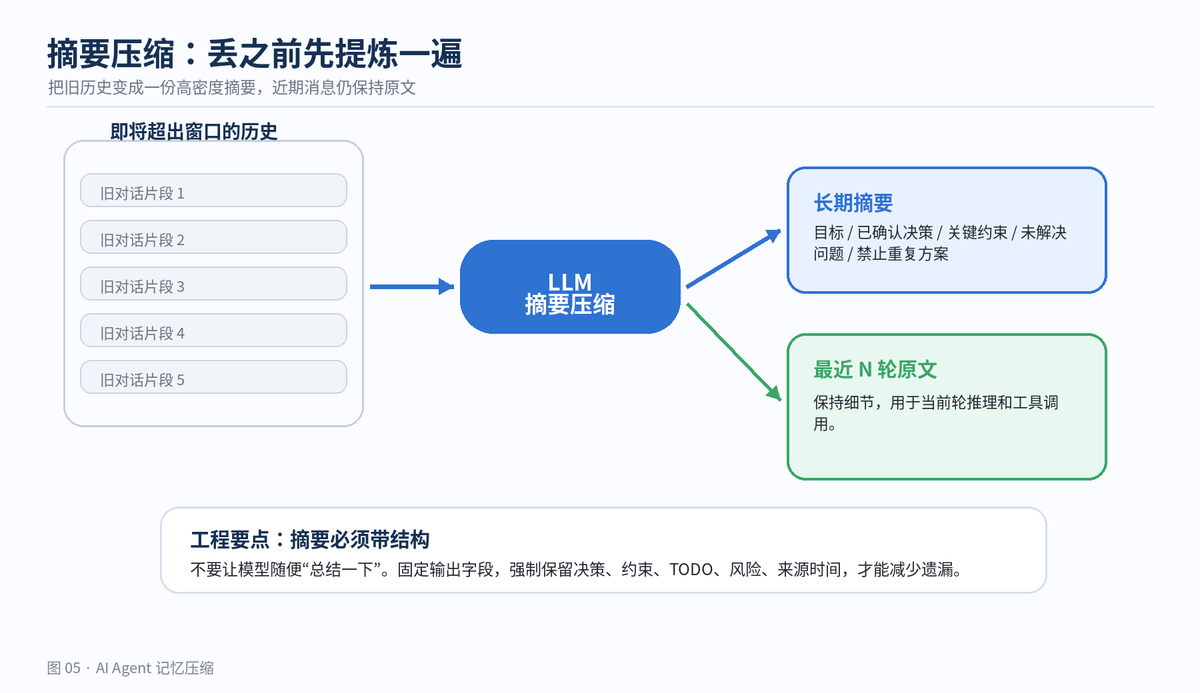
摘要压缩用摘要替代旧历史,同时保留近期原文
建议用固定模板约束摘要内容:
SUMMARY_SCHEMA = """
请把即将移出窗口的历史压缩为以下字段:
1. 用户目标:当前到底要完成什么;
2. 已确认决策:已经拍板的方案、结论、选择;
3. 关键约束:预算、技术栈、时间、合规、安全边界;
4. 待办事项:下一步需要继续完成的任务;
5. 禁止重复:已经否决的方案、不要再问的问题;
6. 证据来源:这些结论来自哪些轮次或工具结果。
只保留事实,不要发挥。
"""更稳的做法是层级式摘要。最近 10 轮保持原文,10 到 50 轮压成中期摘要,50 轮之前进一步压成长期摘要。这样既能保留近处细节,也能保留远期决策。
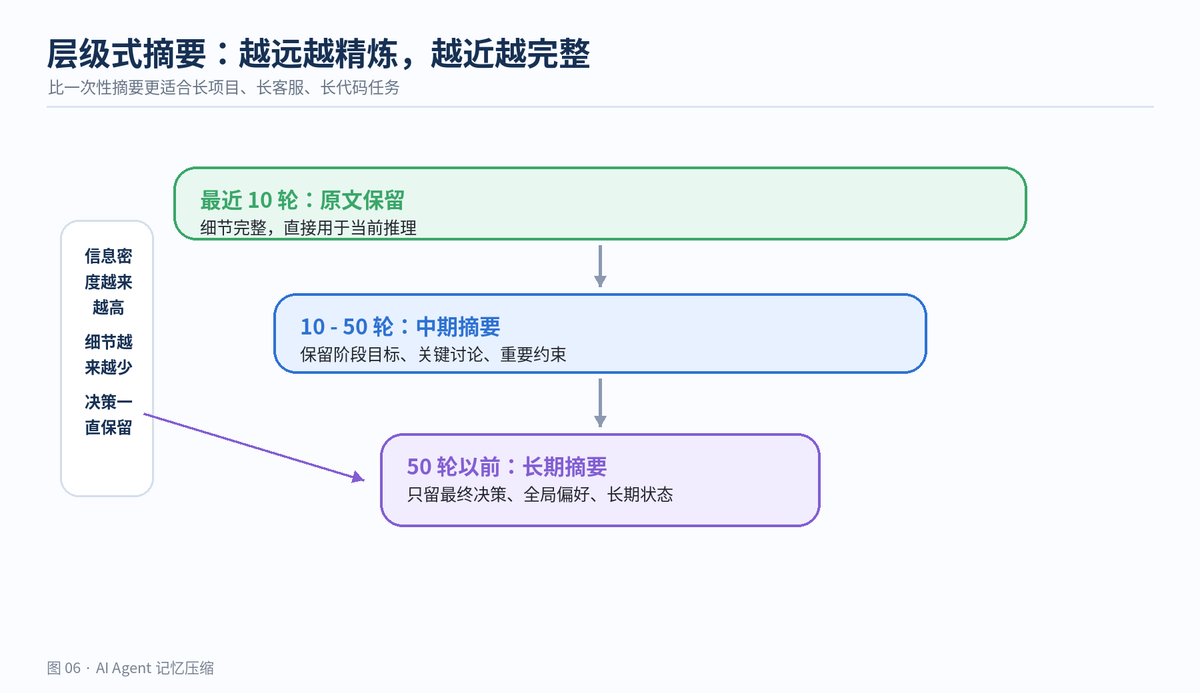
层级式摘要让远期历史越来越精炼
可以用 token 阈值触发压缩:
def should_compress(token_count, max_context, recent_tool_tokens=0):
"""超过上下文预算的 70%,或单次工具返回过大,就触发压缩。"""
if token_count > max_context * 0.70:
return True
if recent_tool_tokens > 2000:
return True
return False
async def compact_history(messages, llm):
old_part = messages[:-8]
recent_part = messages[-8:]
summary = await llm.summarize(old_part, schema=SUMMARY_SCHEMA)
return [{"role": "system", "content": "历史摘要:" + summary}] + recent_part4. 方法三:重要性过滤,按价值筛,不按时间筛
时间不等于重要性。重要性过滤的思路是给每条记忆打分,只有高价值内容才进入 prompt。低价值内容不一定删除,可以保留在原始日志里,只是在当前这一步不展示给模型。
常见评分因素包括:是否包含用户明确决策,是否包含约束条件,是否被后续引用,是否和当前任务阶段相关,是否来自可信工具,是否已经被新的信息覆盖。

重要性过滤把高价值信息挑出来,而不是按时间一刀切
一个简单的规则评分版本如下:
KEYWORDS = ["确认", "决定", "必须", "预算", "不要", "已否决", "兼容", "截止"]
def score_memory(text, referenced=False, current_topic_hit=False):
score = 0
for kw in KEYWORDS:
if kw in text:
score += 15
if referenced:
score += 25
if current_topic_hit:
score += 30
if "闲聊" in text or "天气" in text:
score -= 20
return max(0, min(score, 100))
def select_memories(memories, min_score=60):
return [m for m in memories if m["score"] >= min_score]进阶做法是 Observation Masking。它不是删除低分历史,而是在不同阶段动态遮蔽。写代码时显示需求、接口、约束;测试阶段显示验收标准和 bug;复盘阶段显示错误记录。信息还在,只是当前不让模型读。
5. 方法四:结构化抽取,换一种载体存信息
前三种方法默认历史仍然是“文本”。结构化抽取则进一步追问:我们真的需要把原始对话塞回 prompt 吗?很多业务里,真正有价值的是对话里产生的事实和状态。
比如用户偏好 Python、预算上限 5 万、方案 B 已确认、方案 A 已否决、必须兼容移动端。这些内容写成结构化字段,比一大段对话更稳定、更短、更容易更新。
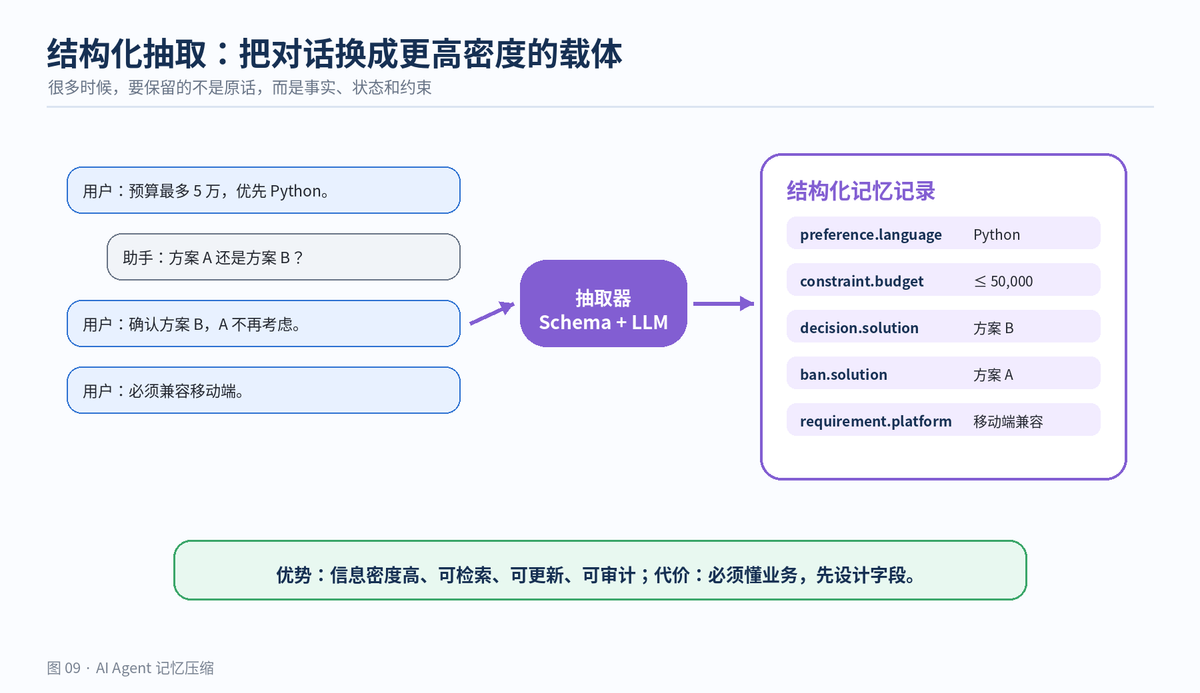
结构化抽取把对话压成高密度事实记录
结构化记忆可以这样定义:
from dataclasses import dataclass
from datetime import datetime
@dataclass
class MemoryRecord:
user_id: str
key: str # 例如 decision.solution
value: str # 例如 方案 B
confidence: float
source_turn_id: str
updated_at: datetime
expires_at: datetime | None = None
def to_prompt(records: list[MemoryRecord]) -> str:
lines = []
for r in records:
lines.append(f"- {r.key}: {r.value}(置信度 {r.confidence:.2f})")
return "当前已知长期记忆:
" + "
".join(lines)结构化抽取的优势是信息密度高、可审计、可更新。缺点是业务设计成本高。你必须先知道哪些字段值得存,字段冲突怎么处理,用户撤回记忆怎么删除,旧记忆什么时候过期。
6. 主动压缩:工具返回后立刻压,不要等窗口爆了
很多 Agent 的上下文不是被聊天撑爆的,而是被工具结果撑爆的。一次搜索返回 10 篇文章,一次代码检索返回 20 个文件片段,一次数据库查询返回几千行数据。模型读完后,真正有用的可能只有几条结论。
主动压缩的做法是:工具返回后立即生成证据卡,把原始工具结果写入日志或对象存储,prompt 里只保留结论、来源、置信度和下一步影响。
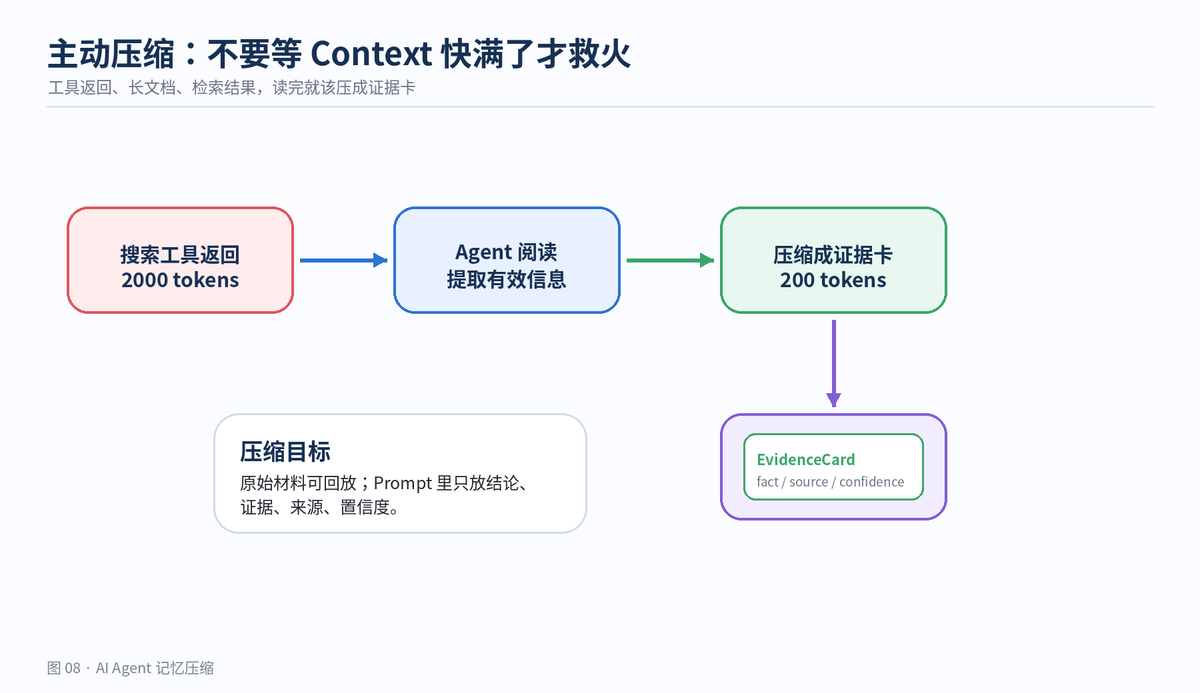
主动压缩适合工具调用频繁的 Agent
def compress_tool_result(tool_name, raw_result):
"""工具结果不直接长期留在 prompt 里,而是压成证据卡。"""
return {
"tool": tool_name,
"facts": extract_key_facts(raw_result),
"source_ref": save_raw_result(raw_result),
"confidence": estimate_confidence(raw_result),
"impact": "影响后续方案选择或参数填写"
}触发时机不要只看 token 阈值。更合理的触发点包括:任务阶段结束、工具返回过大、准备进入新任务、需求发生变化、旧方案被新决策覆盖、准备生成长文档或长代码。
7. 生产级方案:压缩不是函数,是一条流水线
真正上线时,记忆压缩通常不是一个单独函数,而是一条上下文装配流水线。原始日志负责可追溯,摘要仓库负责保留脉络,结构化记忆负责保留状态,向量记忆负责按语义召回,Prompt Assembler 负责把这些材料按预算装配进去。
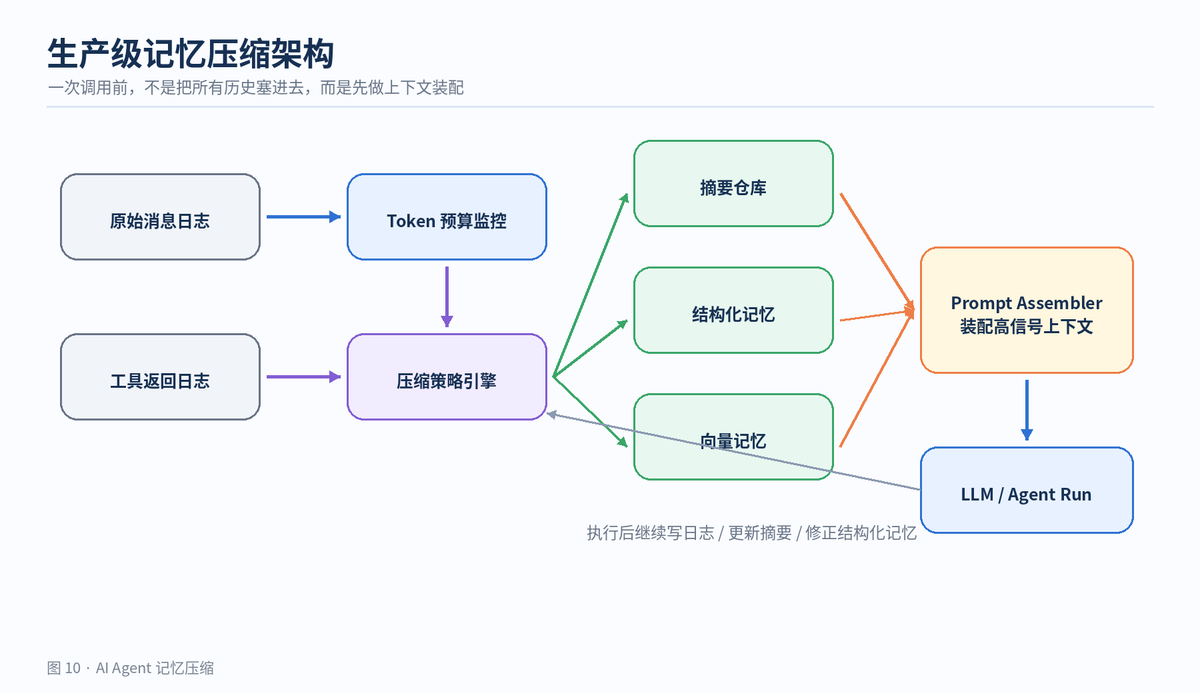
这个架构的关键点有三个:
原始记录不丢:摘要可能出错,结构化抽取可能漏字段,所以原始日志必须可回放。
压缩结果可版本化:每次摘要和结构化更新都要记录来源、版本、时间,方便排查。
Prompt 装配可解释:每次模型调用到底带了哪些摘要、哪些记忆、为什么带,要能在日志里看到。
一个简单的装配伪代码:
def build_context(user_id, current_task, recent_messages):
long_summary = summary_store.get(user_id)
structured = memory_store.query(user_id, task=current_task)
retrieved = vector_store.search(current_task, top_k=5)
context_parts = [
system_prompt(),
format_summary(long_summary),
format_structured_memory(structured),
format_retrieved_memories(retrieved),
format_recent_messages(recent_messages[-8:]),
]
return fit_into_token_budget(context_parts, max_tokens=24000)8. Prompt Caching:它不是记忆压缩,但可以一起用
记忆压缩解决的是信息层问题:哪些内容值得进入 prompt。Prompt Caching 解决的是计算层问题:已经决定要带进去的稳定前缀,能不能少算几次。
比如 system prompt、工具说明、长期记忆摘要,在多轮对话中经常不变。如果这些稳定前缀可以被缓存,后续请求就能复用计算结果,降低延迟和成本。

判断标准:压缩前先问“这段内容还该不该让模型读”;缓存前再问“这段内容是否稳定且会被多次复用”。
9. 选型指南:先稳,再省,再智能
不要一上来就做最复杂的记忆系统。选型要看业务压力。对话短,就用滑动窗口;任务长,就用窗口加摘要;有明确业务状态,就做结构化抽取;工具返回很长,就做主动压缩;高频调用,再叠加 Prompt Caching。
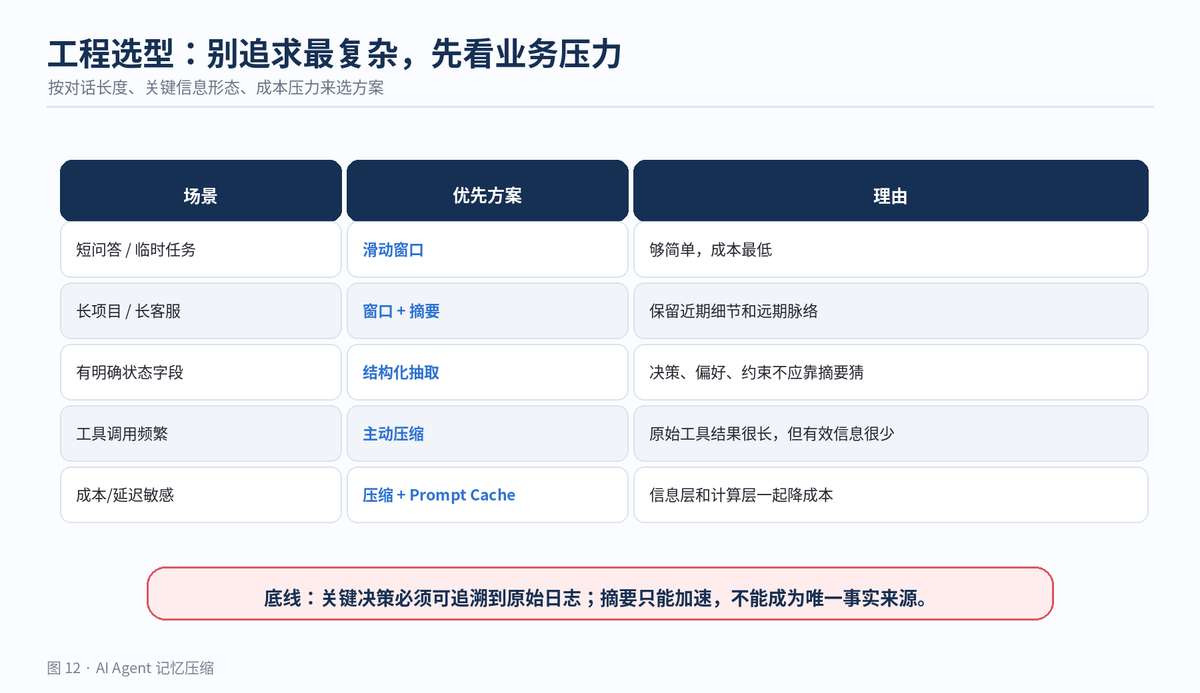
实际落地可以按三阶段推进:
第一阶段:滑动窗口 + 摘要。先把上下文长度控制住,避免长会话直接崩。
第二阶段:关键事实结构化。把用户偏好、明确决策、项目状态从摘要里拿出来,独立存储。
第三阶段:主动压缩 + 观察遮蔽 + 缓存。把工具结果、检索材料、长链路任务做成更精细的上下文治理。
10. 常见坑:记忆压缩最怕“压错”
记忆压缩不是越短越好。压得太狠,模型会失去任务连续性;压得太松,模型又会被噪声干扰。更危险的是摘要把错误信息写成了“事实”,后面每一轮都继续引用,形成上下文污染。
上线前至少要加这些护栏:
摘要必须保留来源:每个关键决策能追溯到原始轮次或工具结果。
关键状态不能只存在摘要里:用户偏好、预算、已确认方案、禁止事项要结构化保存。
压缩前先去重:重复工具结果、重复检索片段、重复解释不应进入摘要。
摘要要可修正:用户纠正后,要更新摘要和结构化记忆,不能让旧记忆继续生效。
删除要可执行:用户要求忘记某件事时,原始日志、摘要、结构化记忆、向量索引都要同步处理。
11. 面试回答版本
如果面试官问“Agent 对话历史越来越长,context 快撑满了怎么办”,不要只说保留最近 N 轮。可以这样回答:
我会把记忆压缩分成四类:滑动窗口、摘要压缩、重要性过滤和结构化抽取。滑动窗口控制长度,但有硬截断风险;摘要压缩在丢弃前保留脉络,最好做成层级摘要;重要性过滤按价值筛选,而不是按时间删除;结构化抽取把关键决策、用户偏好、约束条件转成字段,信息密度最高。工程上通常是滑动窗口 + 摘要兜底,关键事实结构化保存,工具结果主动压缩,最后再用 Prompt Caching 降低重复计算成本。
这套回答能体现两个点:第一,你知道压缩不是一种方法,而是一组策略;第二,你知道 Prompt Caching 和记忆压缩不是一回事,一个在信息层,一个在计算层。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 1
1 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)