AI Agent 多智能体系统:从单打独斗到团队协作
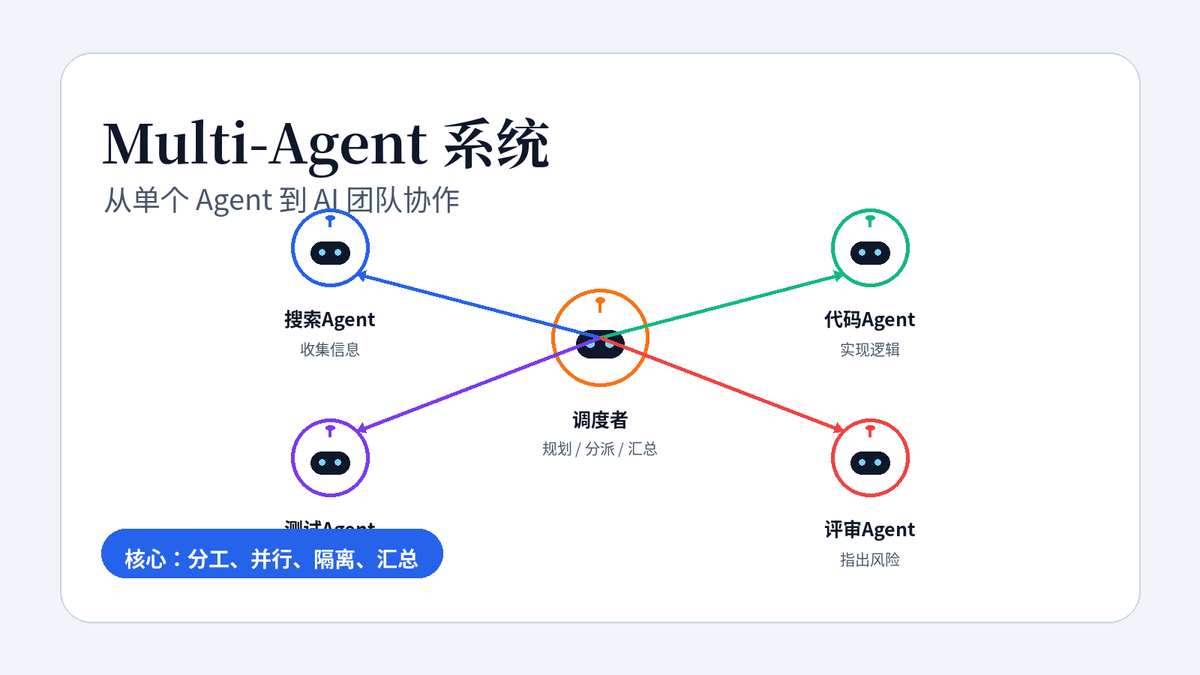
Multi-Agent 的直观模型:一个调度者,多个专业 Agent 协同完成复杂任务。
面试官问:你了解 Multi-Agent 吗?为什么要用多个 Agent,而不是一个 Agent 直接干到底?
很多人的第一反应是:多个 Agent 效率更高。这个回答没有错,但太浅。Multi-Agent 真正解决的是两个结构性问题:单个 Agent 的上下文有限,单个 Agent 的专业能力也有限。复杂任务一多,它就像一个人同时做产品、研发、测试、文档和评审,很快会混乱。
Multi-Agent 的核心,不是“多放几个大模型”。它更像一个 AI 团队:有人负责拆任务,有人负责检索,有人负责编码,有人负责测试,有人负责评审,最后由一个调度者汇总结果。
1. Multi-Agent 到底是什么?
Multi-Agent 是由多个具备不同角色、工具和上下文的 Agent 组成的协作系统。每个 Agent 不再试图“什么都懂、什么都做”,而是只负责自己擅长的那一块。
比如做一份 AI 行业竞品分析报告,一个 Agent 负责搜索资料,一个 Agent 负责提炼功能差异,一个 Agent 负责整理表格,一个 Agent 负责风险评审。它们之间通过任务、消息、结果和状态传递协作。
Single-Agent 是一个全能选手;Multi-Agent 是一个分工明确的小团队。
2. 为什么单个 Agent 会撑不住?
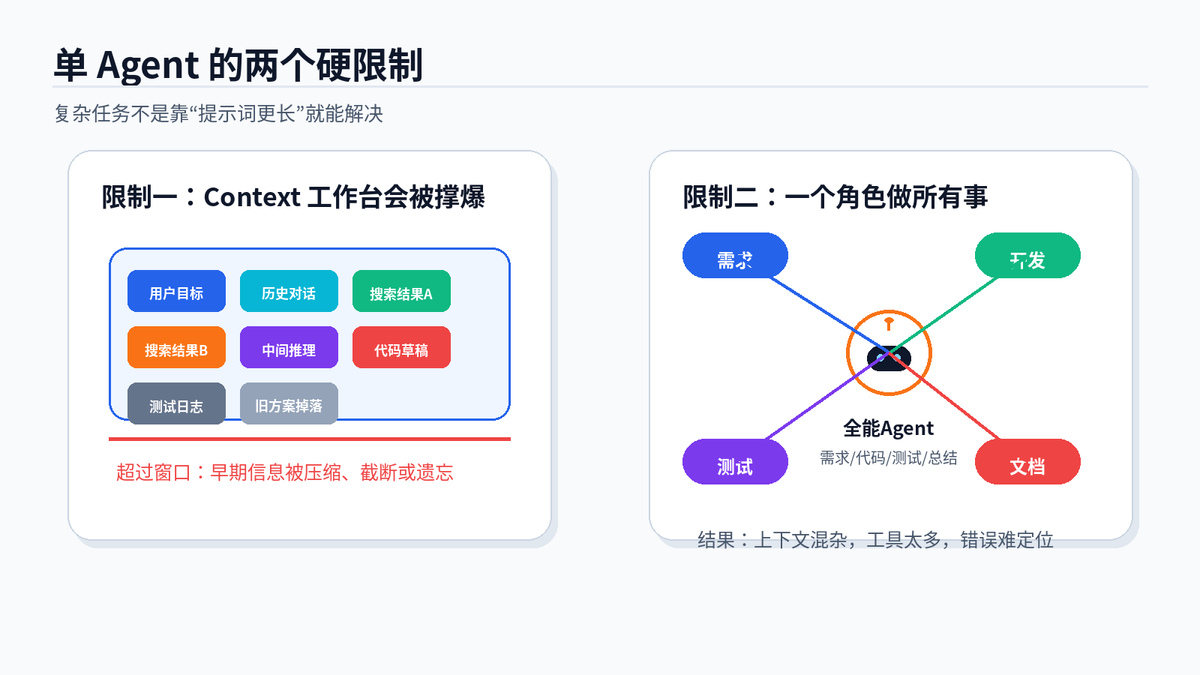
单 Agent 的两个硬限制:Context 工作台会被撑爆,角色能力也会互相干扰。
第一个限制是 context window。LLM 每次工作都要把指令、历史对话、工具返回、中间推理和候选答案放进同一个上下文窗口。资料一多,早期信息就会被压缩或挤掉。不是模型不努力,是工作台真的放不下。
第二个限制是专业分工。让一个 Agent 同时做需求分析、代码开发、测试验证和总结汇报,它会被不同任务的上下文互相干扰。工具太多时,它还容易选错工具,或者在错误的中间结果上继续推理。
Multi-Agent 的做法,是把大工作台拆成多个小工作台。每个 Agent 只看自己需要的信息,减少干扰,也让失败边界更清楚。
3. Multi-Agent 的三种协作方式
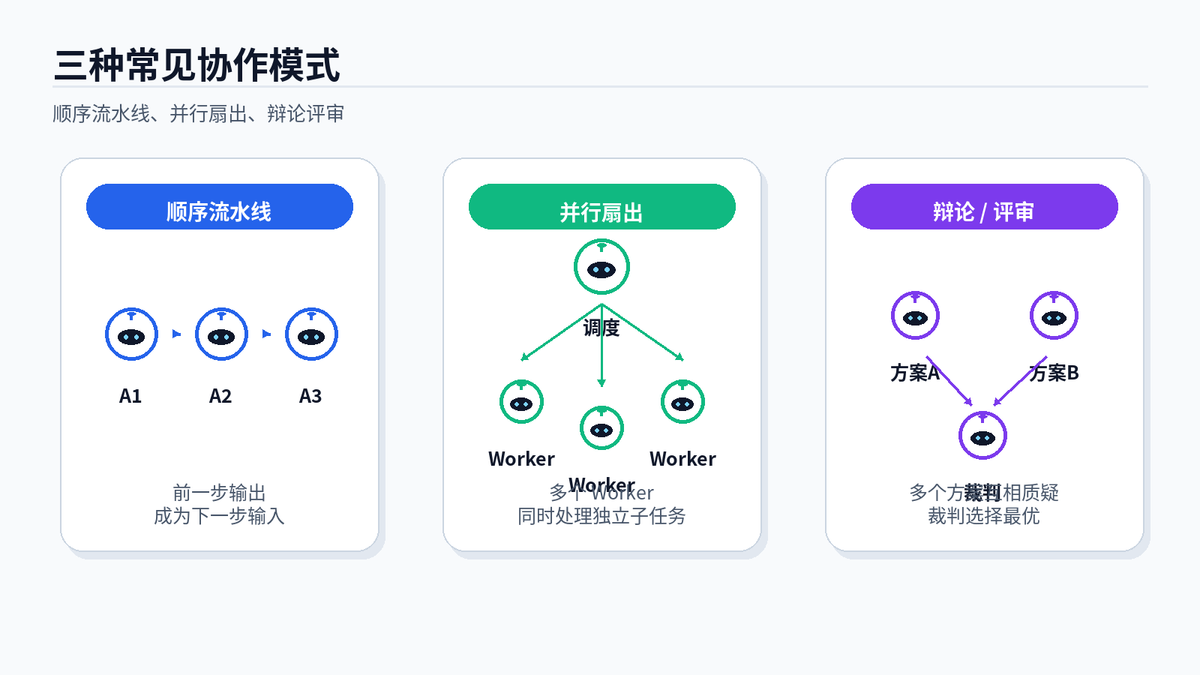
顺序流水线、并行扇出、辩论/评审,是多 Agent 最常见的三类协作模式。
顺序流水线:适合流程明确的任务。比如先做需求分析,再做代码实现,再做测试,最后写说明文档。每一步的输出都是下一步的输入。
并行扇出:适合多个子任务互不依赖的场景。比如同时搜索多个竞品、同时检查多份文件、同时让多个 Agent 分析不同方案,最后统一汇总。
辩论/评审:适合质量要求高、容易犯错的决策。多个 Agent 给出不同方案,评审 Agent 找漏洞、比证据、做裁决。代码审查、方案选型、投资研究、法律条款分析,都适合加一层评审。
4. 分开工作台:每个 Agent 只保留必要上下文
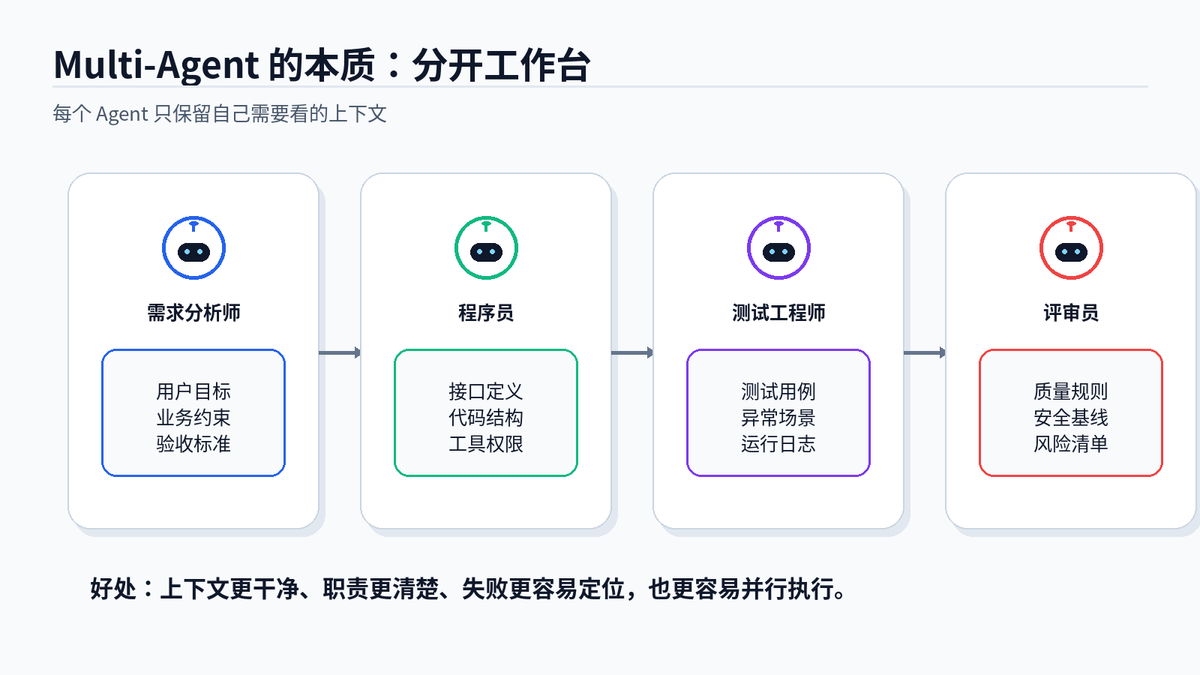
把复杂任务拆给不同角色,每个 Agent 的上下文更干净,输出也更稳定。
单 Agent 做复杂任务时,context 里会混着用户目标、搜索结果、代码草稿、测试日志、评审意见。信息越多,越容易乱。
多 Agent 不是简单并发,而是上下文隔离。需求分析师 Agent 不需要看到所有测试日志,测试 Agent 也不需要知道用户最初的闲聊历史。只给它必要信息,反而更准。
这也是多 Agent 和普通函数调用最大的区别:函数只拆执行步骤,Agent 还拆角色、上下文、工具权限和责任边界。
5. 中心化和去中心化,工程上怎么选?
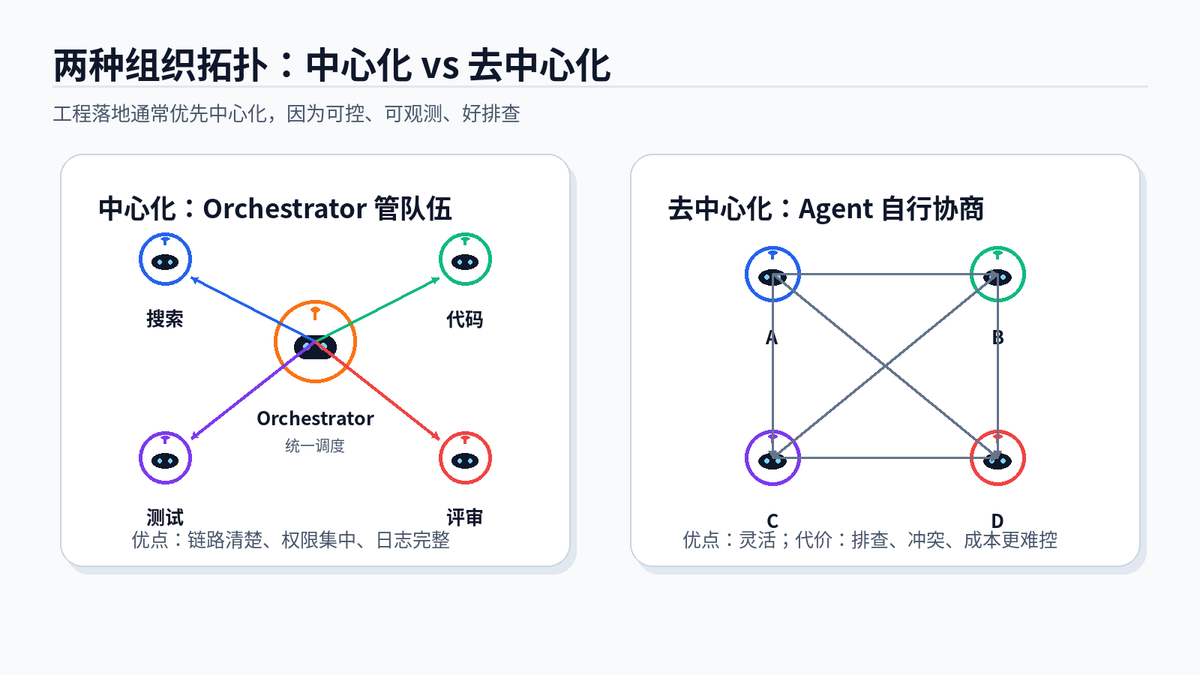
中心化方案里,Orchestrator 负责拆任务、分配 Worker、收集结果和最终汇总。它像项目经理,Worker Agent 像不同岗位的专家。
去中心化方案里,Agent 之间可以直接协商、互相转交任务。它更灵活,但容易出现循环调用、职责不清、成本失控和日志难追踪。
生产环境通常先用中心化。原因很现实:调度路径清楚,权限集中,日志容易串起来,出了问题能知道是哪个 Agent、哪一步、哪个工具调用导致的。
6. 最常用的生产范式:Orchestrator-Workers
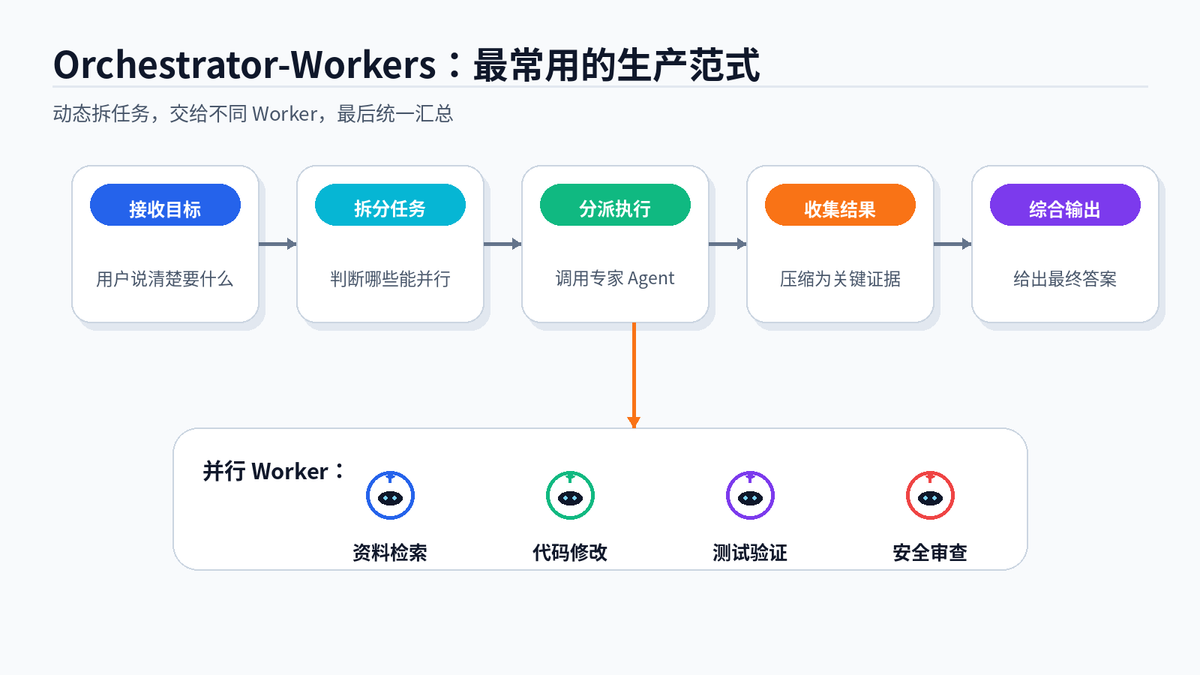
Orchestrator-Workers 是目前最常见、也最容易落地的多 Agent 架构。它的关键不是提前把所有步骤写死,而是让调度者根据输入动态判断:哪些任务要拆,哪些任务能并行,哪些结果需要复核。
比如用户说“帮我分析这个开源项目能不能用于生产”。Orchestrator 可以拆成四个 Worker:代码结构分析、依赖安全分析、文档成熟度分析、社区活跃度分析。四个 Worker 并行跑,最后汇总成一份结论。
核心伪代码可以这样理解:
class Task:
def __init__(self, goal, role, input_context):
self.goal = goal
self.role = role
self.input_context = input_context
class Orchestrator:
def plan(self, user_goal):
return [
Task("梳理需求", "analyst", user_goal),
Task("实现代码", "coder", user_goal),
Task("生成测试", "tester", user_goal),
Task("审查风险", "reviewer", user_goal),
]
def run(self, user_goal):
tasks = self.plan(user_goal)
results = parallel_run(tasks) # 可并行执行
checked = self.verify(results) # 统一校验
return self.summarize(checked) # 最终汇总注意,这段代码不是把 Agent 写成固定脚本,而是强调三个工程点:任务对象要结构化,执行结果要可追踪,最终答案要经过统一汇总。
7. Agents-as-Tools 和 Handoff 的区别
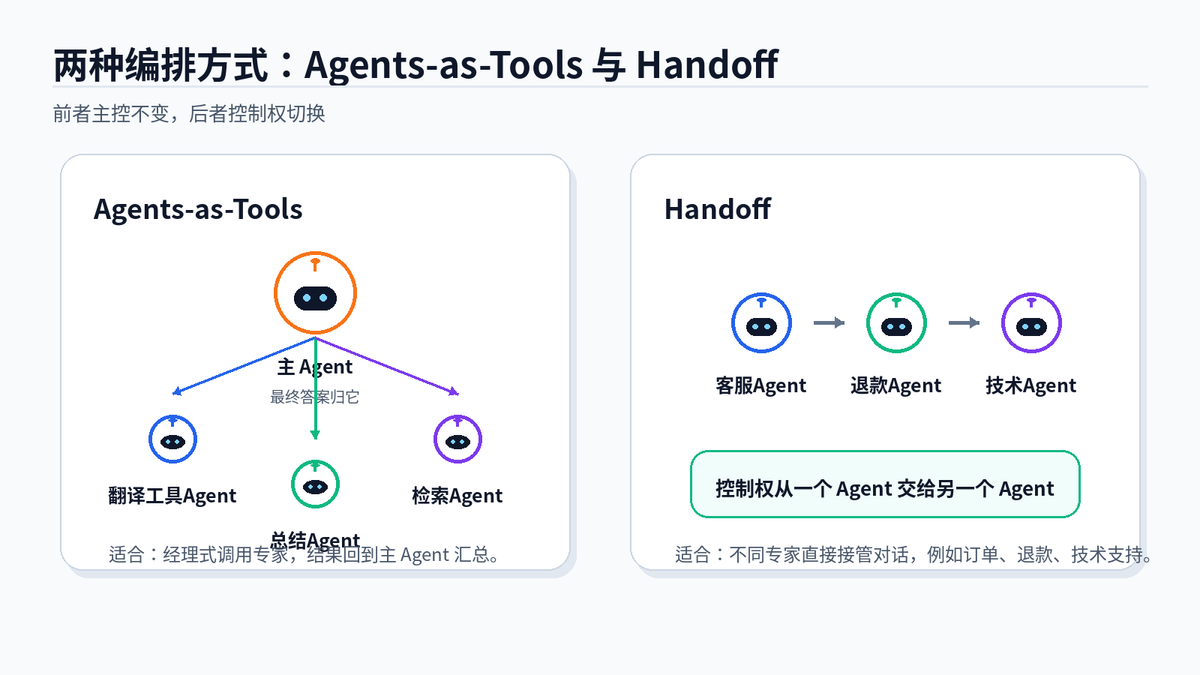
Agents-as-Tools 是主 Agent 调专家;Handoff 是控制权从一个 Agent 切到另一个 Agent。
Agents-as-Tools:主 Agent 始终负责最终答案。它把专家 Agent 当成工具调用,比如调用“摘要 Agent”“检索 Agent”“翻译 Agent”,拿到结果后自己汇总。
Handoff:当前 Agent 判断自己不适合继续处理,就把控制权交给另一个 Agent。比如客服 Agent 发现用户要退款,就转给退款 Agent;发现是技术故障,就转给技术支持 Agent。
两者的取舍很简单:如果最终答案应该由一个主 Agent 统一把关,用 Agents-as-Tools;如果任务天然需要不同专家接管对话,用 Handoff。
8. 多 Agent 之间怎么通信?
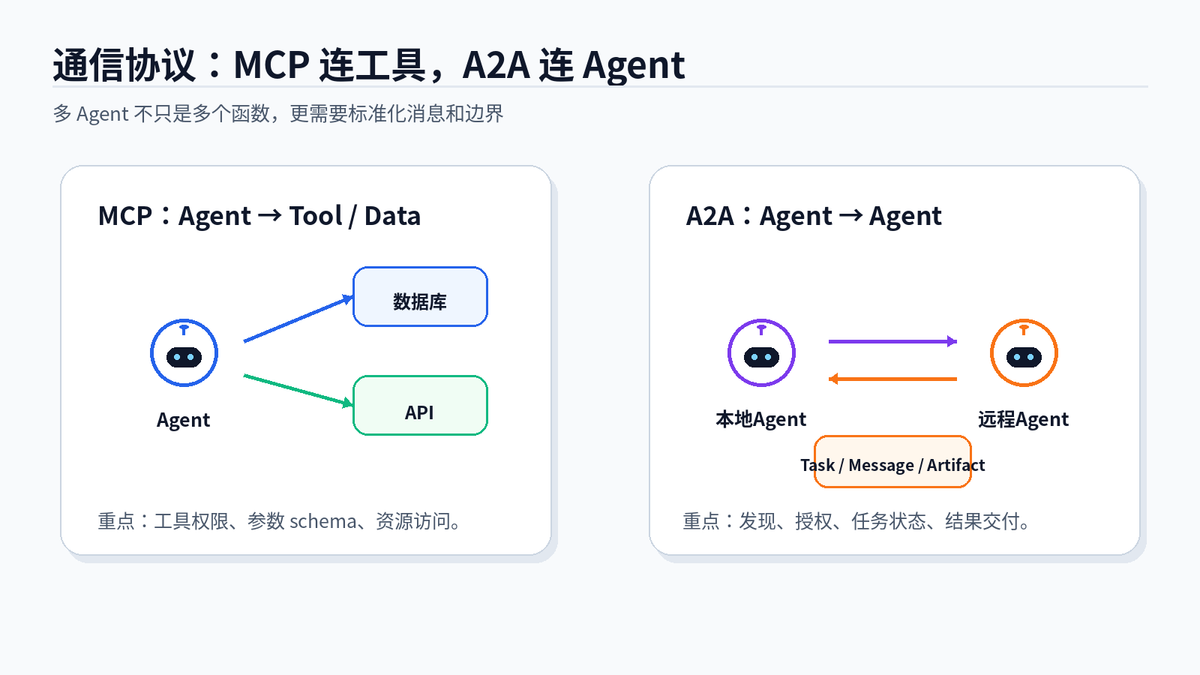
MCP 更偏 Agent 连工具,A2A 更偏 Agent 连 Agent,两者是互补关系。
多 Agent 不能只靠自然语言互相喊话。工程上至少要定义四类对象:Task、Message、Artifact、Status。
Task 表示要做什么;Message 表示 Agent 之间传递的上下文;Artifact 表示产物,比如报告、代码、文件、测试结果;Status 表示任务状态,比如 pending、running、failed、done。
当系统跨服务、跨团队、跨框架时,通信协议会变得更重要。MCP 解决 Agent 如何安全连接工具和数据源;A2A 解决不同 Agent 如何发现彼此、委托任务、交换结果。
一个更工程化的消息结构:
from pydantic import BaseModel
from typing import Literal, dict
class AgentMessage(BaseModel):
trace_id: str
task_id: str
sender: str
receiver: str
intent: Literal["delegate", "result", "review", "handoff"]
content: str
artifacts: list[str] = []
metadata: dict = {}
class AgentResult(BaseModel):
task_id: str
status: Literal["done", "failed", "need_human"]
summary: str
evidence: list[str]
cost_tokens: int有了结构化消息,系统才能做审计、重试、限流、权限判断和成本统计。没有这些,多 Agent 很快就会变成一堆不可控的对话记录。
9. 框架怎么选?
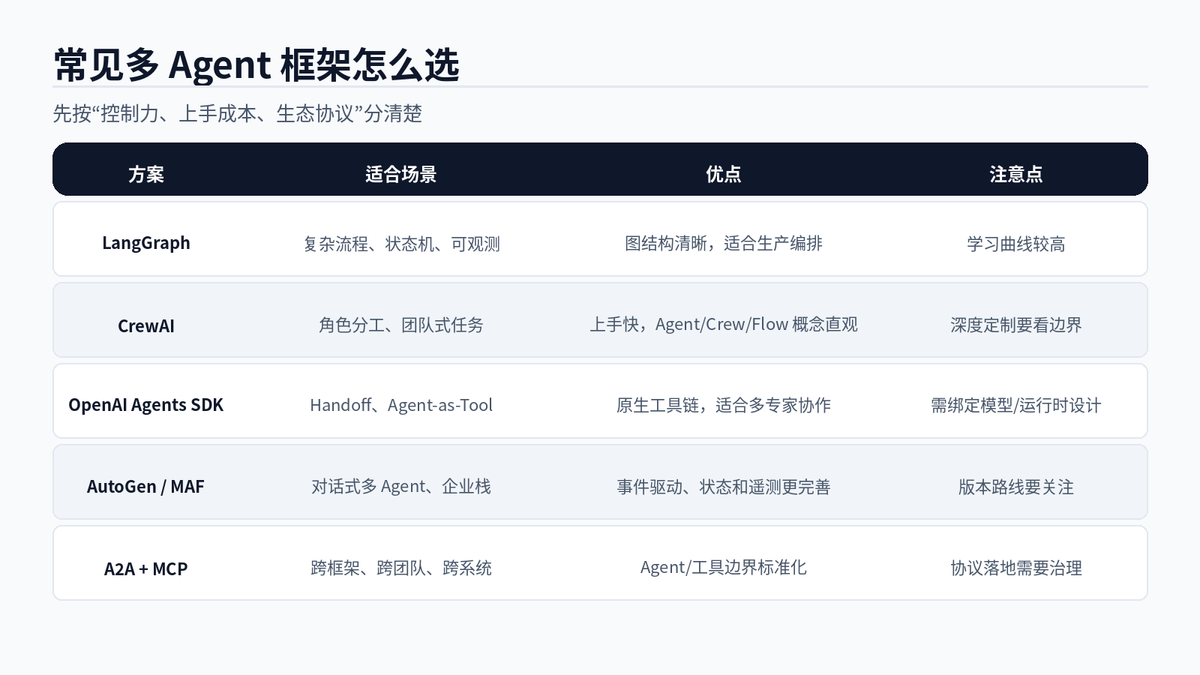
LangGraph 更适合需要强控制的图工作流。你可以把每个 Agent、工具、判断节点都放进状态图里,适合复杂业务流程。
CrewAI 更强调角色、任务、团队协作。它的 Agent、Crew、Flow 概念比较直观,适合快速搭建角色分工型应用。
OpenAI Agents SDK 更适合围绕工具调用、Handoff、Agents-as-Tools 构建多专家系统。AutoGen / Microsoft Agent Framework 更适合对话式协作、事件驱动和企业级状态管理。
A2A 和 MCP 不一定替代这些框架。更准确地说,框架负责“怎么编排”,协议负责“怎么互通”。
10. 生产级架构应该长什么样?

一个能上线的 Multi-Agent 系统,不能只有 prompt。至少要有入口层、调度层、执行层、基础设施层和治理层。
入口层负责用户、权限、租户和审计。调度层负责路由、规划和转交。执行层负责不同专业 Agent。基础设施层提供工具网关、记忆库、消息队列和结果仓库。治理层负责日志、成本、安全和评测。
很多 Demo 看起来很酷,但上线就崩,原因往往不是模型不行,而是缺少状态管理、权限边界、失败重试和可观测性。
11. 多 Agent 不是越多越好

多 Agent 最大的坑,是系统看起来更聪明,实际更难控。Agent 之间可能重复搜索、互相放大错误、循环调用、消耗大量 token,甚至拿到不该用的工具权限。
所以要给每个 Agent 设计最小权限,只开放它需要的工具。要给每个任务设置最大轮次、超时时间、预算上限和失败退出条件。要让每一步都有 TraceID,能回放当时的输入、工具调用、输出和决策理由。
真正专业的 Multi-Agent,不是 Agent 数量多,而是分工清楚、上下文干净、边界可控、结果可验证。
12. 什么时候才值得上 Multi-Agent?
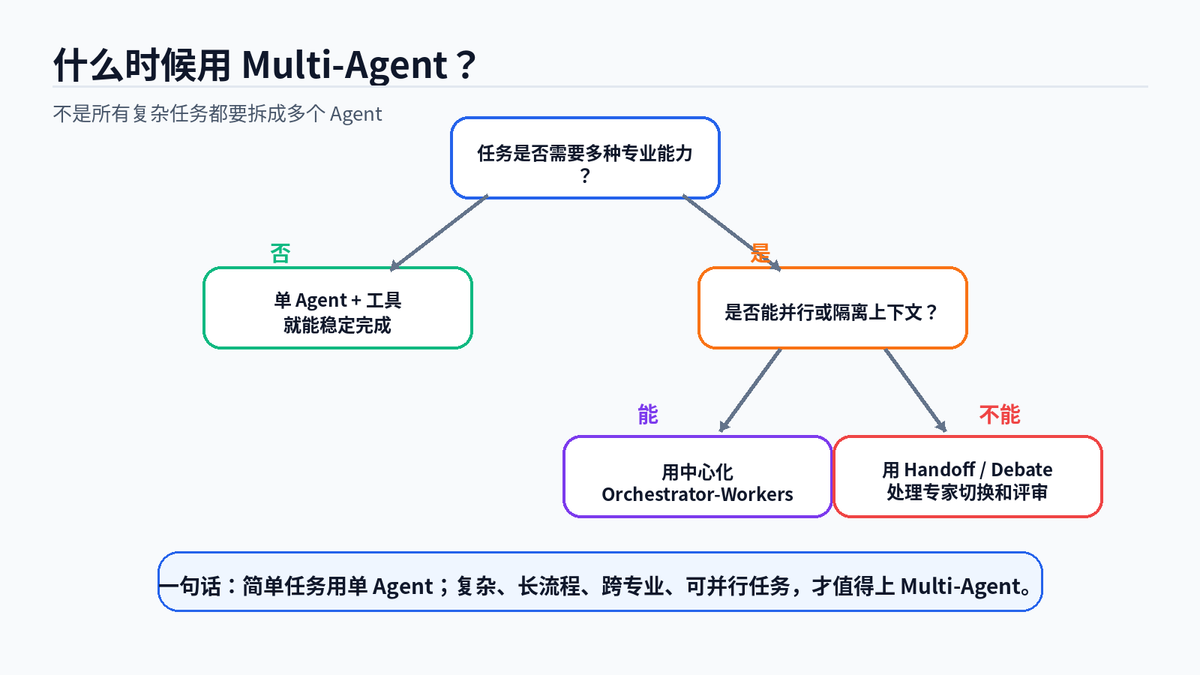
选型原则:简单任务用单 Agent;跨专业、可并行、长流程任务再上 Multi-Agent。
如果任务很短、工具很少、上下文很清楚,单 Agent 就够了。强行拆成多个 Agent,只会增加延迟和成本。
如果任务跨多个专业领域,需要并行处理,需要隔离上下文,需要多个团队独立维护,或者需要评审机制,那就适合 Multi-Agent。
最实用的判断标准是:如果一个 Agent 的 prompt 已经塞满角色说明、工具说明、业务规则、长文档和历史结果,而且经常选错工具、漏掉信息、难以排查,那就该考虑拆成多 Agent 了。
13. 面试和项目里怎么总结?
面试回答不要只说“多个 Agent 更高效”。要讲清楚三个点:第一,context window 有硬上限,复杂任务会撑爆上下文;第二,单个 Agent 让它身兼数职,专业度会下降;第三,多 Agent 可以通过专业分工、并行执行、上下文隔离和评审机制提升稳定性。
项目落地时,优先从中心化 Orchestrator-Workers 做起。先把任务拆成结构化 Task,再为每个 Agent 配最小工具权限,执行结果写入统一状态机,所有调用都打 trace,最后再加评审 Agent 和自动评测。
Multi-Agent 不是把一个问题丢给更多模型,而是把复杂任务拆成一个可协作、可追踪、可控制的 AI 团队。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 1
1 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)