LangChain八股-面试问答篇1
思维导图速览
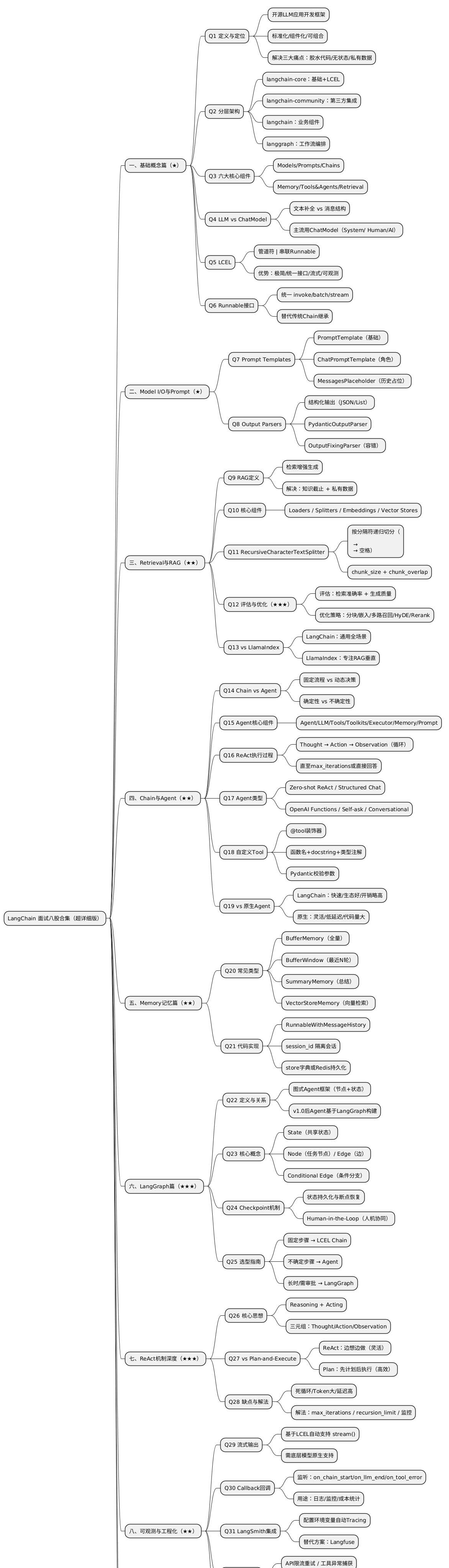
一、LangChain 基础概念篇
Q1:什么是 LangChain?它的核心定位是什么?
LangChain 是一个开源的大语言模型(LLM)应用开发框架,由 Harrison Chase 于 2022 年 10 月发起。核心定位是为 LLM 应用开发提供一套标准化、组件化、可组合的开发套件,大幅降低复杂 LLM 应用的开发门槛。
它将 LLM 应用开发的全流程拆分为可复用的独立组件(提示词模板、文档加载器、检索器、工具、记忆模块等),开发者可像搭积木一样自由组合这些组件,快速搭建从简单对话机器人到复杂 AI Agent、生产级 RAG 系统等各类 LLM 应用。
核心解决三大问题:
-
标准化封装:LLM 应用开发涉及模型调用、向量库、工具集成等多个环节,每个环节都有不同的提供商和 API,LangChain 把这些都封装成统一的接口
-
快速组装:把常见功能抽象成独立组件,几行代码就能搭出一个 RAG 应用或 Agent
-
复杂流程编排:提供 Chain 链式调用、Memory 记忆管理、Agent 自主决策等高级能力
加分项:
-
核心设计理念是组件化 + 可组合,基于 LCEL 实现了统一的
Runnable接口 -
相比原生 LLM API,解决了胶水代码冗余、组件复用难的问题
-
相比 LlamaIndex,LangChain 通用性更强;LlamaIndex 更聚焦于 RAG 垂直场景
LangChain 有什么优缺点?
-
优点:生态丰富、组件齐全、快速上手
-
缺点:过度封装隐藏细节、版本迭代快 API 变化大、生产环境有一定性能开销
Q2:LangChain 的分层架构是怎样的?
LangChain 采用分层架构设计:
| 层级 | 说明 |
|---|---|
| langchain-core | 提供基础抽象与 LCEL,是组件协同的核心 |
| langchain-community | 第三方集成模块,覆盖 Model I/O、Retrieval、Tool 等 |
| langchain | 包含 Chains、Agents、Retrieval 等核心业务组件 |
| langgraph | 编排多个节点,负责整个工作流的调度与状态跳转 |
Q3:LangChain 的六大核心组件是什么?
LangChain 包含六个核心模块:
| 组件 | 作用 |
|---|---|
| Models(模型) | 封装各类 LLM 和 Embedding 模型,支持多提供商无缝切换 |
| Prompts(提示词) | 提供 PromptTemplate 模板管理,支持变量插值、FewShot 示例 |
| Chains(链) | 把多个组件串联起来形成执行流程,前一个组件的输出作为后一个组件的输入 |
| Memory(记忆) | 在对话中保持上下文,支持多种记忆策略 |
| Tools & Agents(工具与智能体) | Tools 封装外部功能,Agent 自主决策调用什么工具 |
| Retrieval(检索) | 负责从外部数据源检索相关信息(Document Loaders、Text Splitters、Vector Stores 等) |
⚠️ 面试易错点:
-
❌ 漏说 Memory 或 Retrieval/Document Loaders,显得不懂完整应用流程
-
❌ 只说组件名称,没说核心作用和应用场景
-
✅ 建议按“一次请求的生命周期”来讲:输入 → Prompt → Model → (Retriever/Tool) → Output Parser
Q4:LLM 和 ChatModel 有什么区别?
| 对比维度 | LLM | ChatModel |
|---|---|---|
| 输入输出 | 纯字符串(文本进→文本出) | 消息结构(HumanMessage、SystemMessage、AIMessage 列表) |
| 典型代表 | 早期 GPT-3 | ChatGPT、通义千问、文心一言 |
| 适用场景 | 文本补全 | 对话交互 |
实际开发中 ChatModel 是主流用法,因为它支持角色区分,可以用 SystemMessage 设定模型行为。
Q5:什么是 LCEL?它的核心优势是什么?
LCEL 全称 LangChain Expression Language(LangChain 表达式语言),是 LangChain 官方主推的链构建方式,核心语法是通过 | 管道符将实现了 Runnable 接口的组件按业务逻辑串联。
python
chain = prompt | model | output_parser
chain.invoke({"question": "Python如何处理异常?"})
核心优势:
-
语法极简:一行代码即可构建复杂工作流,无需定义冗余的类
-
统一接口:所有 LCEL 对象都实现了
Runnable接口,具有统一的invoke、batch、stream、astream方法 -
自动流式输出:无需额外代码即可实现 token 的流式传输
-
强大的并行能力:使用
batch可以并行处理多个输入 -
内置可靠性:支持故障重试、回退机制
-
原生可观测:无缝对接 LangSmith,自动追踪每一步的输入输出
Q6:Runnable 是什么?和传统 Chain 有何差异?
Runnable 是 LangChain 的标准执行接口,被大多数组件实现(模型、解析器、检索器、甚至编译后的 LangGraph 图)。它提供一致的 invoke / ainvoke / batch / stream API,便于在不同组件间可组合、可替换。
与传统 Chain 的差异:
-
传统 Chain(如
LLMChain)是类继承方式,扩展需要写子类 -
Runnable是接口协议方式,任何实现了该接口的对象都可以通过|管道符组合 -
LCEL 基于
Runnable构建,是 LangChain 当前官方推荐的标准范式
二、Model I/O 与 Prompt 篇
Q7:Prompt Templates 的作用是什么?有哪些类型?
Prompt Templates 用于结构化管理和动态生成提示词,将业务逻辑与提示词解耦。
常见类型:
-
PromptTemplate:基础模板,支持变量插值(如"请将{input}翻译成英文") -
ChatPromptTemplate:对话消息模板,支持SystemMessage、HumanMessage、AIMessage角色 -
MessagesPlaceholder:消息占位符,用于动态插入历史消息列表
Q8:为什么需要 Output Parsers(输出解析器)?
LLM 输出的是文本或 Message 对象,而程序需要的是结构化数据(字符串、JSON、Pydantic 对象等)。Output Parser 的作用就是将 LLM 的非结构化输出转换为程序可直接使用的格式。
常见类型:
-
StrOutputParser:直接返回字符串 -
PydanticOutputParser:使用 Pydantic 模型定义输出结构,自动解析为对象 -
OutputFixingParser:修复格式不正确的输出 -
CommaSeparatedListOutputParser:解析逗号分隔的列表
三、Retrieval 与 RAG 篇
Q9:什么是 RAG?它解决了什么问题?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种通过外部知识库增强大模型生成能力的技术架构。它解决了 LLM 的两个核心缺陷:
-
知识冻结:LLM 的知识截止于训练数据
-
私有数据无法访问:LLM 无法访问企业私有文档
核心流程:用户查询 → 向量检索 → 检索相关知识片段 → 拼接上下文 → LLM 生成回答。
Q10:LangChain 中 Retrieval 的核心组件有哪些?
| 组件 | 说明 |
|---|---|
| Document Loaders | 从 PDF、网页、数据库等 50+ 数据源加载文档 |
| Text Splitters | 将长文本按语义单元切分 |
| Embeddings | 将文本转化为浮点数向量 |
| Vector Stores | 存储向量并做相似度搜索(Chroma、FAISS、Pinecone、Milvus) |
| Retriever | 给定查询返回文档的抽象接口,Vector Store 可通过 .as_retriever() 转换 |
Q11:为什么推荐使用 RecursiveCharacterTextSplitter?它是如何工作的?
RecursiveCharacterTextSplitter 是 LangChain 最推荐也是最常用的文本切分方式。
工作原理:它会按分隔符优先级递归切分(默认顺序:\n\n → \n → 空格 → 字符),尽量保持段落、句子、词的语义完整度。
关键参数:
-
chunk_size:每个分块的最大长度 -
chunk_overlap:分块之间的重叠长度(避免上下文被截断)
Q12:如何评估和优化 RAG 系统的效果?(★★★ )
评估维度:
-
检索准确率:是否召回了相关文档(召回率、精确率)
-
生成质量:答案是否准确、完整、有无幻觉
优化策略:
-
分块策略优化:调整
chunk_size和chunk_overlap,根据文档类型选择合适的分隔符 -
嵌入模型选型:平衡精度与速度(如
BAAI/bge-small-en-v1.5适合通用场景) -
向量数据库选型:FAISS(内存计算)、Chroma(开箱即用)、Pinecone/Milvus(生产环境)
-
检索策略增强:
-
混合检索:结合关键词检索(BM25)和向量检索,分配权重
-
HyDE:假设性文档嵌入,先用 LLM 生成假设答案再检索
-
Rerank(重排序) :对召回结果进行二次排序
-
-
查询改写:对用户问题进行改写或扩展,提升检索效果
⚠️ 面试官追问:“你的 RAG 项目有没有做过优化?优化了什么?效果如何?从多少优化到多少?优化了准确率还是召回率?”——建议结合具体项目数据回答。
Q13:LangChain 和 LlamaIndex 的区别是什么?
| 对比维度 | LangChain | LlamaIndex |
|---|---|---|
| 定位 | 通用 LLM 应用开发框架 | 专注于 RAG 和数据索引 |
| 覆盖场景 | 从基础对话到复杂 Agent 全场景 | 更聚焦于 RAG 垂直场景 |
| 优势 | 通用性强、生态丰富、组件齐全 | RAG 能力深度优化、索引策略丰富 |
选择建议:需要 Agent、工具调用等复杂能力选 LangChain;主要做文档问答 RAG 可考虑 LlamaIndex。
四、Chain 与 Agent 篇
Q14:Chain 和 Agent 有什么区别?
| 对比维度 | Chain | Agent |
|---|---|---|
| 执行方式 | 固定的执行流程,数据按预设路径流动 | 动态决策,模型自己判断 |
| 适用场景 | 确定性任务(如“检索→回答”) | 不确定性任务(如“查天气→发邮件”) |
| 灵活性 | 低 | 高 |
| 可控性 | 高 | 低 |
通俗理解:
-
Chain 像“客服工作流程”,将多个步骤串联(如“查询处理→RAG 检索→生成回答”)
-
Agent 像“资深客服主管”,能自主决策“是否调用工具”“调用哪个工具”
Q15:LangChain Agent 的核心组件有哪些?它们如何协作?
核心组件:
-
Agent(智能体) :决策中枢,解析用户输入,决定调用工具或直接响应
-
LLM(大语言模型) :提供推理能力,驱动 Agent 决策
-
Tools(工具) :执行具体任务的函数/接口(搜索、计算、API 调用)
-
Toolkits(工具包) :相关工具的集合
-
AgentExecutor(执行器) :运行 Agent 的引擎,管理执行循环、处理错误、控制步数
-
Memory(记忆) :存储对话历史和工具结果(可选但重要)
-
Prompt Template:结构化指令,引导 LLM 理解 Agent 角色和工具用法
协作流程:
text
用户输入 → Agent(理解意图)+ LLM(生成工具调用)+ Prompt Template
↓
决策:调用工具 or 直接回答
↓(调用工具)
Tools/Toolkits 执行 → 工具结果 → 更新 Memory
↓
返回最终响应给用户
Q16:描述一次 LangChain Agent 的完整执行过程(ReAct 模式)
Agent 基于 ReAct 架构(Reasoning + Acting),即推理与行动交替进行。
完整执行过程:
-
接收用户输入
-
Agent 将用户输入 + 可用工具描述 + 对话历史组装成 Prompt,调用 LLM
-
LLM 返回决策:直接回答 或 调用某个工具
-
如果是工具调用,AgentExecutor 执行工具并获取结果
-
将工具结果返回给 LLM,继续推理(Observation 观察阶段)
-
重复步骤 3-5,直到 LLM 决定直接回答或达到迭代上限(
max_iterations) -
返回最终答案给用户
核心机制:Agent 在一个循环中运行工具以实现目标,持续运行直到满足停止条件。
Q17:LangChain 中有哪些类型的 Agent?各有什么特点?
| Agent 类型 | 特点 | 适用场景 |
|---|---|---|
| Zero-shot ReAct | 无记忆,每次调用独立决策,基于工具描述选择工具 | 简单任务、无状态工具调用 |
| Structured Chat ReAct | 支持复杂多工具调用,输出结构化指令(JSON) | 多步骤规划、工具组合 |
| OpenAI Functions | 专为 OpenAI 函数调用优化,提示工程简化 | 深度集成 OpenAI 模型 |
| Self-ask | 自问自答模式,分解问题为子问题再调用工具 | 多跳问答(Multi-hop QA) |
| Conversational | 内置对话记忆管理 | 多轮交互 |
Q18:如何在 LangChain 中自定义一个 Tool?
方式一:使用 @tool 装饰器(推荐):
from langchain.tools import tool
@tool
def search_weather(location: str) -> str:
"""查询指定城市的实时天气"""
# 调用天气 API
return f"{location}天气:晴,25℃"方式二:使用 Pydantic 验证输入参数:
from pydantic import BaseModel, Field
class WeatherInput(BaseModel):
location: str = Field(description="城市名称")
@tool(args_schema=WeatherInput)
def search_weather(location: str) -> str:
# 实现逻辑
pass关键点:
-
函数名、文档字符串(docstring) 和类型注解会被 Agent 用于理解工具用途和参数格式
-
使用 Pydantic 验证输入,避免 LLM 传参错误
-
异常处理:捕获工具执行错误,返回明确的错误信息
Q19:LangChain Agent 和原生 Agent(如 OpenAI Function Calling)有什么区别?
| 特性 | LangChain Agent | 原生 Agent |
|---|---|---|
| 开发速度 | 快:提供高层 API | 慢:需手动处理提示、工具调用 |
| 灵活性 | 中:框架约束 | 高:完全自定义 |
| 性能开销 | 略高:多层抽象 | 低:直接调用模型 |
| 工具生态 | 丰富:内置大量工具 | 有限:需自行实现 |
| 维护性 | 高:标准化接口 | 中:代码量大 |
| 适用场景 | 快速构建复杂 Agent、多工具协作 | 简单工具调用、低延迟场景 |
选择建议:快速原型 → LangChain;对性能极致要求、需完全控制 → 原生 Agent。
五、Memory 记忆篇
Q20:LangChain 中 Memory 的常见类型有哪些?
| Memory 类型 | 说明 | 适用场景 |
|---|---|---|
| ConversationBufferMemory | 完整保存所有历史消息 | 短对话、消息量小 |
| ConversationBufferWindowMemory | 只保留最近 N 轮对话 | 控制 token 消耗 |
| ConversationSummaryMemory | 自动总结历史对话 | 长对话,需保留关键信息 |
| VectorStoreMemory | 使用向量检索相关历史记忆 | 超长对话、个性化助手 |
| Entity Memory | 提取和存储实体信息 | 需要记住用户偏好、实体关系 |
Memory 的核心作用:解决大模型“无状态”问题,支持多轮对话——比如用户先问“苹果手机”,再问“它的价格”,Memory 能记住“它”指苹果手机。
Q21:如何实现带记忆的对话链?(代码题)
使用 LCEL + RunnableWithMessageHistory(LangChain 1.0 推荐写法):
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
# 1. 定义提示词模板(含历史占位符)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个乐于助人的AI助手。"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
# 2. 构建 LCEL 链
model = ChatOpenAI(model="gpt-4o-mini")
chain = prompt | model
# 3. 注入记忆能力
store = {}
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 4. 包装为可带记忆执行的 Runnable
with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history"
)
# 5. 调用
response = with_history.invoke(
{"input": "我的名字叫小明"},
config={"configurable": {"session_id": "user_001"}}
)
print(response.content)六、LangGraph 篇
Q22:LangGraph 是什么?与 LangChain 的关系是什么?
LangGraph 是建立在 LangChain 核心之上的图式(graph-based)智能体与工作流框架,用节点(Node)+ 共享状态(State) 来组织分支、循环和多步代理。
与 LangChain 的关系:
-
LangChain 是高层框架,提供组件和 LCEL 编排能力,适合线性流程
-
LangGraph 是底层编排运行时,基于图的状态管理,支持条件分支、循环重试与人工干预
-
二者非替代关系,而是抽象层级互补——从 LangChain v1.0 开始,Agent 抽象已构建于 LangGraph 之上
适用场景:需要可控性、可靠性与复杂流程的应用(而非简单串链)。
Q23:LangGraph 的核心概念有哪些?
| 概念 | 说明 |
|---|---|
| State(状态) | 在节点之间传递的共享数据,通常用 TypedDict 或 Pydantic 模型定义 |
| Node(节点) | 执行具体任务的函数(如 LLM 调用、工具执行) |
| Edge(边) | 节点之间的连接,定义执行流向 |
| Conditional Edge(条件边) | 根据状态动态选择下一个节点 |
| Checkpointer(检查点) | 状态持久化,支持断点恢复 |
Q24:LangGraph 的 Checkpoint 机制是什么?为什么重要?
Checkpoint 机制是 LangGraph 的状态持久化与断点恢复能力。
核心价值:
-
持久化执行:服务器崩溃后可以从检查点恢复执行
-
Human-in-the-Loop(人机协同) :节点之间可以暂停,等待人工审批或补全信息
-
调试能力:可以回溯到任意节点的状态
面试官追问:“LangGraph 这块有没有做 human in the loop?”——回答要点:interrupt 和 checkpoint 一旦真的用在审批、补全、半自动流程里,省掉的胶水代码是实打实的。
Q25:什么时候用 Chain?什么时候用 Agent?什么时候用 LangGraph?
| 业务场景 | 推荐方案 | 理由 |
|---|---|---|
| 固定步骤(如:先检索,后回答) | LCEL Chain | 流程确定,成本最低,延迟最小,易于维护 |
| 不确定步骤(如:帮我在网上查天气并发送邮件) | Agent(ReAct) | 需要 LLM 自主判断调用哪个 API,灵活但稍慢 |
| 长时运行/需人工介入(如:自动写周报→人工审批→自动发送) | LangGraph | 支持状态持久化、断点续传、Human-in-the-Loop |
七、ReAct 机制深度篇
Q26:什么是 ReAct?它的核心思想是什么?
ReAct 全称 Reasoning + Acting(推理 + 行动),是一种让 LLM 在推理(Thought) 和行动(Action) 之间交替进行的 Agent 架构。
核心三元组:
-
Thought(思考) :LLM 分析当前状态,思考下一步做什么
-
Action(行动) :执行具体操作(调用工具、查询知识库等)
-
Observation(观察) :获取行动结果,作为下一轮思考的输入
ReAct 的价值:它不是一种算法,而是一种工程契约——把 LLM 的推理过程和外部工具的调用组织成一个可观测、可控制的循环。
Q27:ReAct 和 Plan-and-Execute 有什么区别?
| 对比维度 | ReAct | Plan-and-Execute |
|---|---|---|
| 执行方式 | 推理和行动交替进行(边想边做) | 先制定完整计划,再按计划执行 |
| 灵活性 | 高:可根据中间结果调整 | 低:计划制定后不易改变 |
| 适用场景 | 任务不确定、需动态调整 | 任务明确、步骤可预知 |
| 效率 | 可能多轮交互 | 计划阶段一次性完成 |
面试官追问:“ReAct 和 Plan-and-Execute 你选哪个?”——这道题没有标准答案,关键在于结合具体场景说明取舍。
Q28:ReAct 有什么缺点?如何解决?
缺点:
-
可能陷入死循环:Agent 反复调用相同工具不退出
-
Token 消耗大:每轮都要将 Thought/Action/Observation 全部拼入上下文
-
延迟高:多轮 LLM 调用串行执行
解决方案:
-
设置
max_iterations限制最大迭代次数 -
使用 LangGraph 的
recursion_limit控制递归深度 -
使用 Plan-and-Execute 替代纯 ReAct(适合步骤明确的场景)
-
结合 LangSmith 监控 Agent 行为,及时发现异常循环
八、可观测性与工程化篇
Q29:LangChain 如何实现流式输出?
基于 LCEL 构建的链自动实现 stream / astream,既可流式最终输出,也可在 RAG 中流式中间步骤(如改写、检索、整合)。
实现方式:
-
最简单:设置
streaming=True参数 -
更精细:使用回调函数(
CallbackHandler)控制流式输出的粒度
注意:是否能逐 token 流式输出,取决于底层模型提供商的原生能力。
Q30:LangChain 的 Callback 回调机制是什么?有什么用?
Callback 是 LangChain 的事件监听机制,允许你在执行过程中的关键节点插入自定义逻辑。
可监听的阶段:
-
on_chain_start/on_chain_end:链开始/结束 -
on_llm_start/on_llm_end:LLM 调用开始/结束 -
on_tool_start/on_tool_end:工具调用开始/结束 -
on_retriever_start/on_retriever_end:检索开始/结束 -
on_chain_error/on_tool_error:错误处理
主要用途:日志记录、监控、流式传输、成本统计、调试。
Q31:如何把链的每一步“自动打点”到 LangSmith?
把 LangSmith 的环境变量配置好后,运行 LangChain 代码就会自动产生日志/调用树。
bash
export LANGCHAIN_TRACING_V2=true export LANGCHAIN_API_KEY=your-api-key export LANGCHAIN_PROJECT=your-project-name
不用 LangSmith 也能观测吗? 可以,社区也有开源方案(如 Langfuse)通过回调/中间件实现 tracing 与指标。
Q32:LangChain 应用中的错误和异常如何处理?
需要在多个层面考虑异常处理:
-
大模型 API 调用异常:网络超时、限流、余额不足——用
try-except捕获,临时性错误(超时)自动重试,永久性错误(余额不足)及时报警 -
工具执行异常:在工具函数内部捕获异常,返回明确的错误信息给 Agent
-
解析异常:使用
OutputFixingParser修复格式不正确的输出 -
Agent 循环失控:设置
max_iterations限制
Q33:LangChain 的批处理与异步如何使用?
所有 Runnable 都支持:
-
invoke/ainvoke:同步/异步单次调用 -
batch/abatch:同步/异步批量处理
# 批量处理
results = chain.batch([{"input": "你好"}, {"input": "再见"}])
# 异步流式
async for chunk in chain.astream({"input": "你好"}):
print(chunk, end="")便于做高吞吐批处理或低延迟并发调用,无需为每种组件写不同的调用代码。
九、综合场景题(★★★)
Q34:如果你来设计一个 Agent 框架,LangChain 的劣势是什么?你会如何改进?
LangChain 的主要劣势:
-
过度封装:隐藏了底层细节,排查问题困难
-
版本迭代快:API 变化大,升级成本高(如
LLMChain被废弃) -
生产环境性能开销:多层抽象带来额外延迟
-
学习曲线陡峭:概念多、组件多
改进思路:
-
根据场景做适度封装,不盲目使用所有组件
-
建立版本锁定机制,避免生产环境频繁升级
-
对核心路径做性能优化,减少不必要的抽象层
-
结合 LangGraph 替代传统 Agent,获得更好的可控性
Q35:LangChain 项目从原型到生产,你会关注哪些工程化问题?
-
可观测性:接入 LangSmith/Langfuse,监控调用链路和成本
-
错误处理:API 限流重试、工具异常降级
-
性能优化:使用
batch并行处理、选择合适的向量数据库 -
状态管理:生产环境使用 Redis 等持久化存储替代内存存储
-
版本管理:锁定 LangChain 版本,避免 API 变更导致生产故障
-
安全:工具调用的权限控制、输入输出过滤
附录:面试备考建议
使用建议:
-
先吃透实战内容,再结合本文理解记忆
-
面试时优先答核心得分点
-
结合自己的实战项目补充细节,效果翻倍
-
拒绝死记硬背,理解比背诵更重要
持续更新完善。。。。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)