CodeGraph 代码图谱实战:AI Agent 为什么不该再从 grep 开始?
导语
代码 Agent 真正卡住的地方,往往不是模型不会写代码,而是它不知道该先看哪里。
面对一个陌生仓库,Agent 通常会先列目录,再搜关键词,接着打开几个文件,猜一个入口点,发现不对后再重复一轮。这个过程看起来像人在熟悉项目,实际成本很高:工具调用多,Token 被大段源码吃掉,模型还容易被相似文件带偏。大仓库里尤其明显,Agent 花了很多推理预算在“找路”上,而不是理解业务链路本身。
CodeGraph 解决的是这个前置问题:先把代码库加工成可查询的语义图,再让 Agent 面向符号、调用链、影响面和上下文子图提问。它不替代编译器、测试和人工 review,但很适合承担“代码结构导航层”的角色。
这篇文章按工程视角拆开 CodeGraph:它如何建索引,如何补全框架语义,如何通过 CLI / MCP 接入 Agent,以及在真实开发流里该怎么用、哪里不能盲信。
Agent 为什么不该一直从 grep 开始

图:Agent 从关键词搜索转向语义代码图谱导航
传统代码检索默认把仓库当作文本集合。这个假设对人还勉强够用,因为人会把搜索结果、目录结构、命名习惯和经验放在一起判断。Agent 不一样,它每走一步都要消耗上下文和工具调用预算。
典型链路大概是这样:

图:传统 Agent 依赖目录与关键词反复找入口
问题不在 grep 本身。问题是“结构性问题”被降级成了“文本命中问题”。
比如用户问“登录请求最终怎么写入数据库”,Agent 真正需要的是路由、handler、service、repository、ORM 调用之间的关系。它不需要先看到 20 个包含 login 的文件。再比如用户问“改这个方法会影响谁”,答案应该来自调用图,而不是一次次全文搜索。
CodeGraph 的思路更直接:把这些关系提前算出来。Agent 提问时,查询对象不再是“文件里有没有某个字符串”,而是“图上哪些节点和边与这个问题相关”。
CodeGraph 的定位:本地代码图谱,不是又一个搜索框
CodeGraph 可以理解为一个本地优先的代码语义索引系统。它会解析源码,抽取函数、类、路由、组件等节点,再把调用、继承、导入、路由绑定、组件引用等关系写进本地 SQLite。
对外它主要提供两类入口:
| 入口 | 更适合谁用 | 典型用途 |
|---|---|---|
| CLI | 开发者、脚本、CI 流程 | 查符号、查调用方、做影响面分析 |
| MCP Server | Claude、Cursor、LangChain、OpenAI Agents 等 Agent 框架 | 让模型直接调用结构化代码工具 |
常用工具可以按问题类型来理解:
| 工具 | 解决的问题 |
|---|---|
codegraph_search |
某个符号、函数、类在哪里定义 |
codegraph_context |
围绕一个自然语言问题组装相关代码上下文 |
codegraph_trace |
追踪一条执行路径或调用链 |
codegraph_callers |
|
/codegraph_callees |
谁调用我、我调用谁 |
codegraph_impact |
某个变更可能影响哪些下游节点 |
codegraph_node |
查看单个符号的结构化详情 |
codegraph_explore |
同时展开多个相关实现 |
codegraph_files |
查询索引后的文件结构 |
codegraph_status |
检查索引状态和同步情况 |
这里有个重要边界:CodeGraph 不是运行时观测系统。它擅长静态结构,不负责证明某条分支在线上是否真的走到。动态加载、反射、运行时注入这类场景,它只能尽力推断。
离线建图:把“找入口”的成本前移
CodeGraph 的核心收益来自一个朴素的取舍:构建索引时多花一点时间,查询时少让 Agent 瞎转。
整体链路可以压成四层:
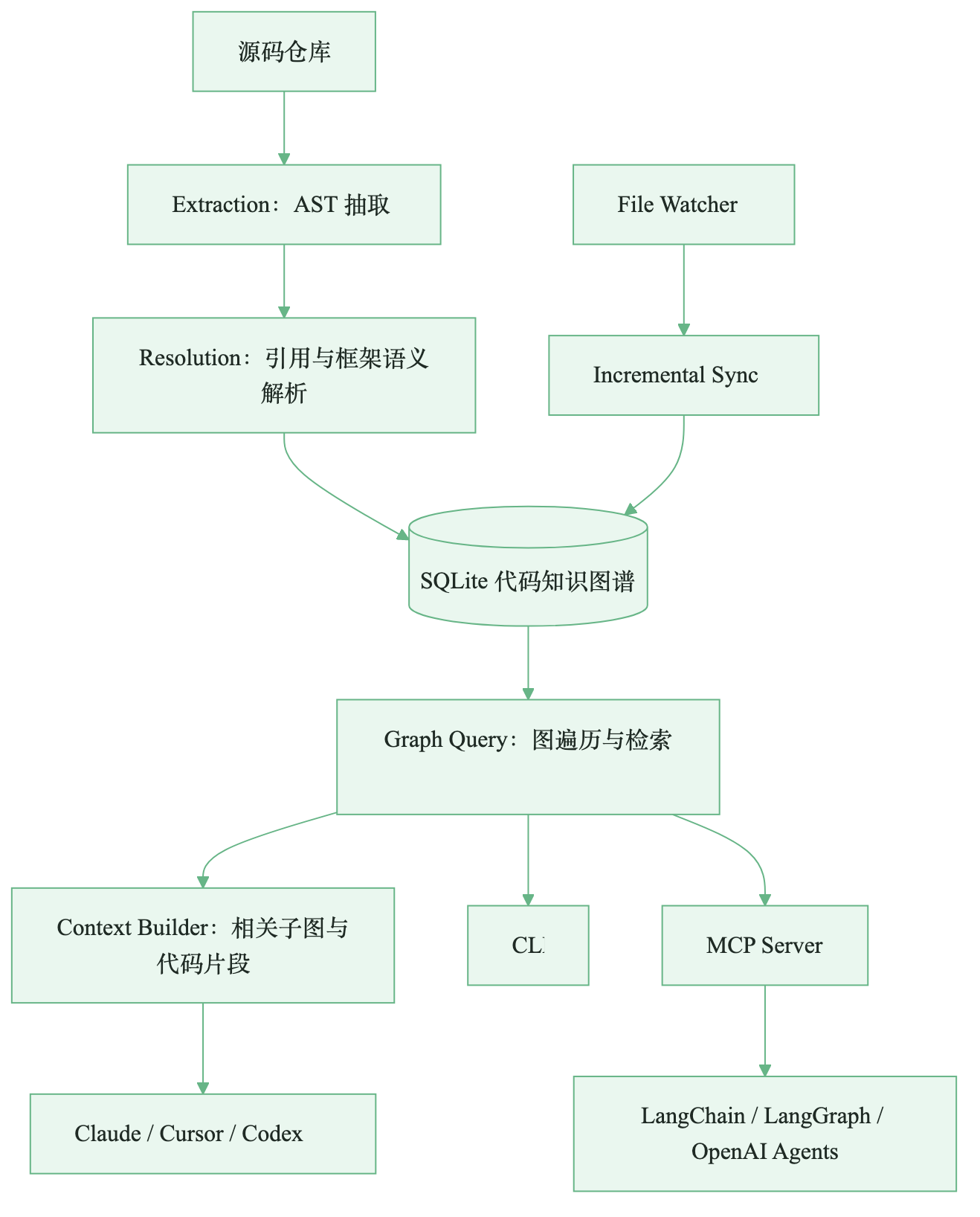
图:从源码抽取到图查询再到 Agent 上下文
这张图背后有三个关键动作。
第一,Extraction 负责把源码拆成结构化元素。CodeGraph 使用 tree-sitter 和 WASM 解析多语言代码,通过 worker thread 并行处理文件。函数、类、接口、路由、组件会变成节点;调用、继承、导入会变成边。解析阶段暂时无法确定的关系会先落到 unresolved_refs。
第二,Resolution 负责把“看起来像调用”的文本关系补成真实关系。比如 foo() 到底是当前文件里的函数、import 进来的方法,还是类成员?Express 的 app.post('/login', loginHandler) 又该怎么连接到 handler?这一步决定了图谱是否真的比全文搜索更有价值。
第三,Graph Query 和 Context Builder 把图转成 Agent 能直接消费的答案。Agent 不需要拿到整个仓库,只需要拿到与问题有关的子图、关键代码片段和路径说明。
数据模型:文件、符号、关系和未决引用
图:源码经过抽取和解析后沉淀为本地语义图谱
CodeGraph 的底层模型不复杂,复杂的是边的质量。
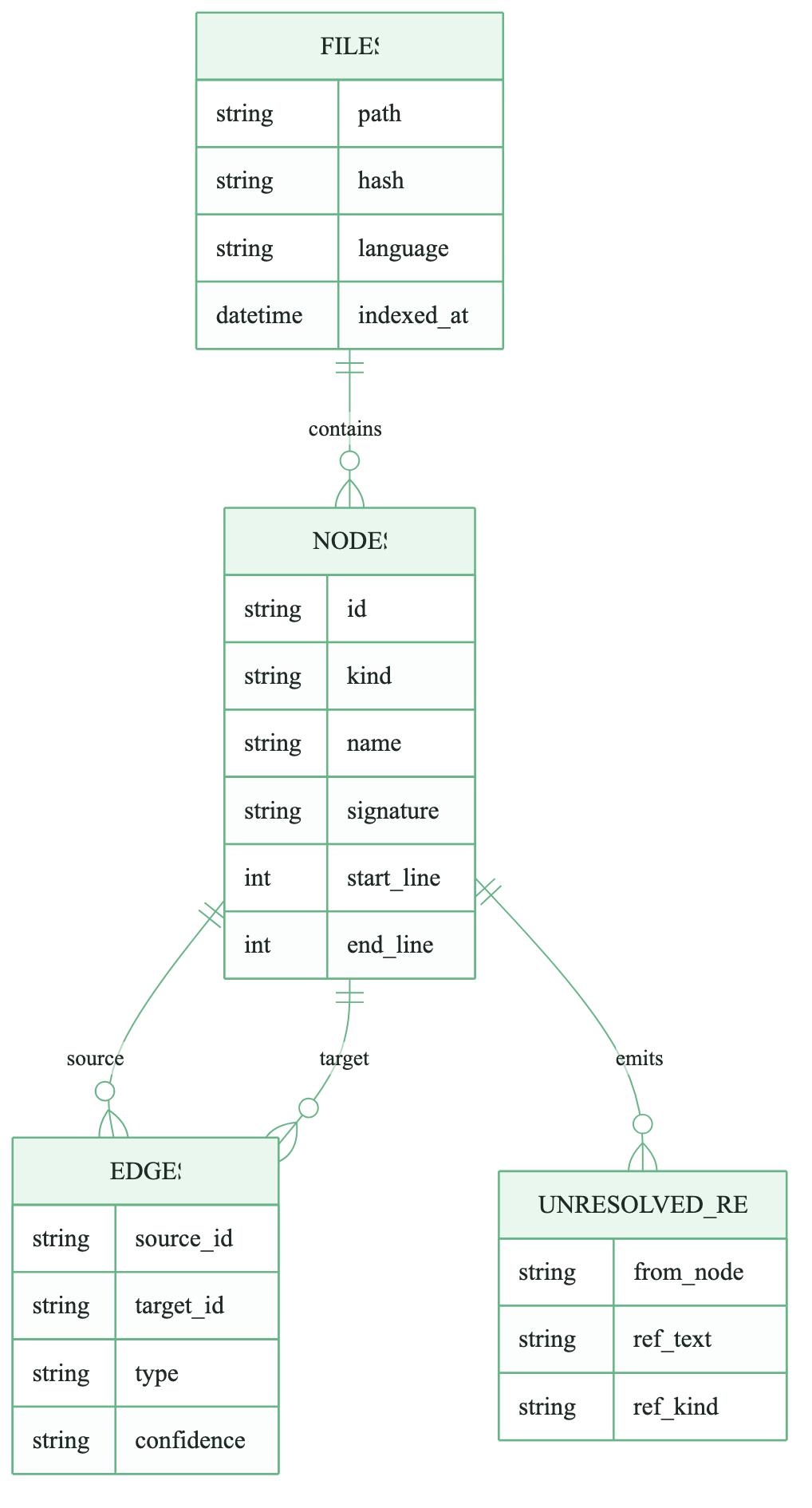
图:文件、节点、关系和未决引用构成代码图谱
几张表的职责很清楚:
| 表 | 保存什么 | 为什么重要 |
|---|---|---|
files |
路径、hash、语言、索引时间 | 判断文件是否变化,支撑增量同步 |
nodes |
函数、类、路由、组件等符号 | Agent 查询的基本对象 |
edges |
调用、继承、导入、路由绑定等关系 | 调用链、影响面、上下文构建都依赖它 |
unresolved_refs |
抽取阶段还没确定的引用 | 留给解析层补全,避免过早丢信息 |
如果只抽节点,CodeGraph 只是一个更规整的符号索引。真正让它有用的是边:谁依赖谁,谁调用谁,哪个 URL 进入哪个 handler,哪个 React 组件渲染了哪个子组件。
Resolution:代码图谱的难点在“懂框架”
AST 能告诉我们“这里有个函数调用”,但很多工程语义不写在普通调用里。
后端框架里,路由到 handler 可能来自装饰器、注解、配置或注册函数;前端框架里,组件依赖藏在 JSX、模板或编译约定中;跨端项目里,JS 到 Native 的桥接关系更不会自然变成一条普通函数调用边。
CodeGraph 的解析层要处理这些关系:
| 场景 | 文本搜索看到的东西 | 图谱应该补出的关系 |
|---|---|---|
| Express / NestJS | URL 字符串、handler 名称 | POST /login→loginHandler |
| Spring / Django / FastAPI | 注解、装饰器、方法定义 | Controller / route → action 方法 |
| React / Vue / Svelte | JSX、模板标签、组件 import | 父组件 → 子组件 |
| React Native / Expo | NativeModule、Bridge 导出 | JS 可调用 API → Native 实现 |
| 普通模块系统 | 相对路径、别名、包名 | import 标识符 → 真实定义 |
这一步也是风险来源。框架规则越多,覆盖面越好;规则没覆盖到的动态行为,就只能靠启发式补边。工程上更稳妥的做法是把边的来源和置信度一并保存,Agent 回答时能区分“精确解析”和“推断结果”。
Context Builder:让 Agent 拿到“可回答的子图”
codegraph_context 是 CodeGraph 最适合 Agent 的能力。它不是简单返回搜索结果,而是围绕一个自然语言问题组织上下文。
一个典型流程如下:
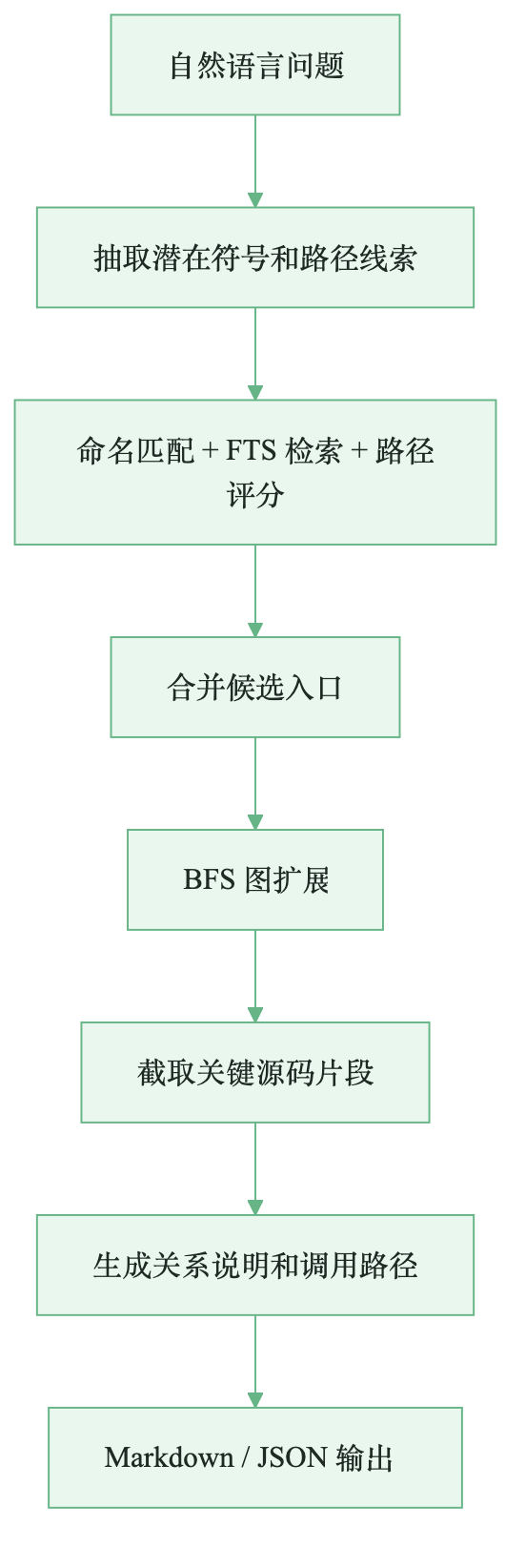
图:自然语言问题被压缩成可回答的相关子图
这比“把搜到的文件都扔给模型”更克制。Agent 得到的是已经压缩过的结构:入口点、主要链路、相关符号、关键代码块、可能的下游影响。它仍然可以继续 Read 某些文件,但不必把探索路径从零开始走一遍。
我的建议是:
- 问“在哪里定义”时,用
search; - 问“这个功能怎么跑起来”时,用
context; - 问“请求如何穿过系统”时,用
trace; - 问“改这里会影响什么”时,用
impact; - 已经锁定一个符号后,再用
node或直接读源码。
先结构,后细节。这个顺序对 Agent 很重要。
索引保鲜:不要让 Agent 信过期的图
代码图谱最怕一件事:索引刚建好,代码马上变了。
CodeGraph 用文件监听和增量同步降低这个问题。开发者保存文件后,FileWatcher 记录 pending files,通过 debounce 合并短时间内的连续修改,再触发同步。同步完成前,MCP 工具返回结果时会带上 stale 提示,告诉 Agent 哪些文件刚改过,相关结论可能过期。
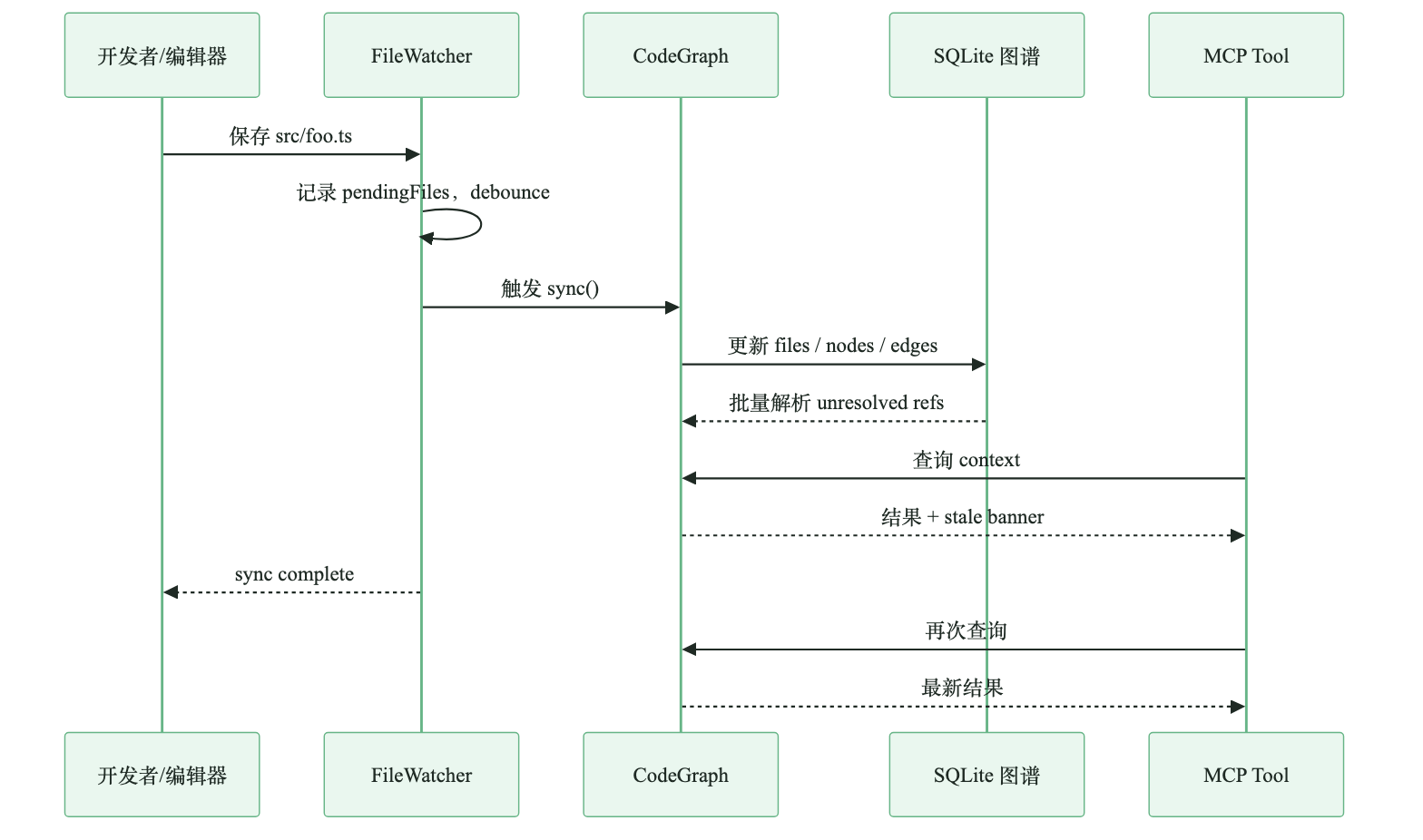
图:文件变化后的增量同步与 stale 提示
这个设计比“假装图永远正确”更诚实。Agent 可以继续信任未变更文件的结构结论;对刚保存的文件,直接读取源码更稳。
MCP 接入:把代码图谱变成 Agent 的本地工具
CodeGraph 通过 MCP 暴露能力后,Agent 框架不需要理解它的内部实现,只要把它当作一组工具调用。
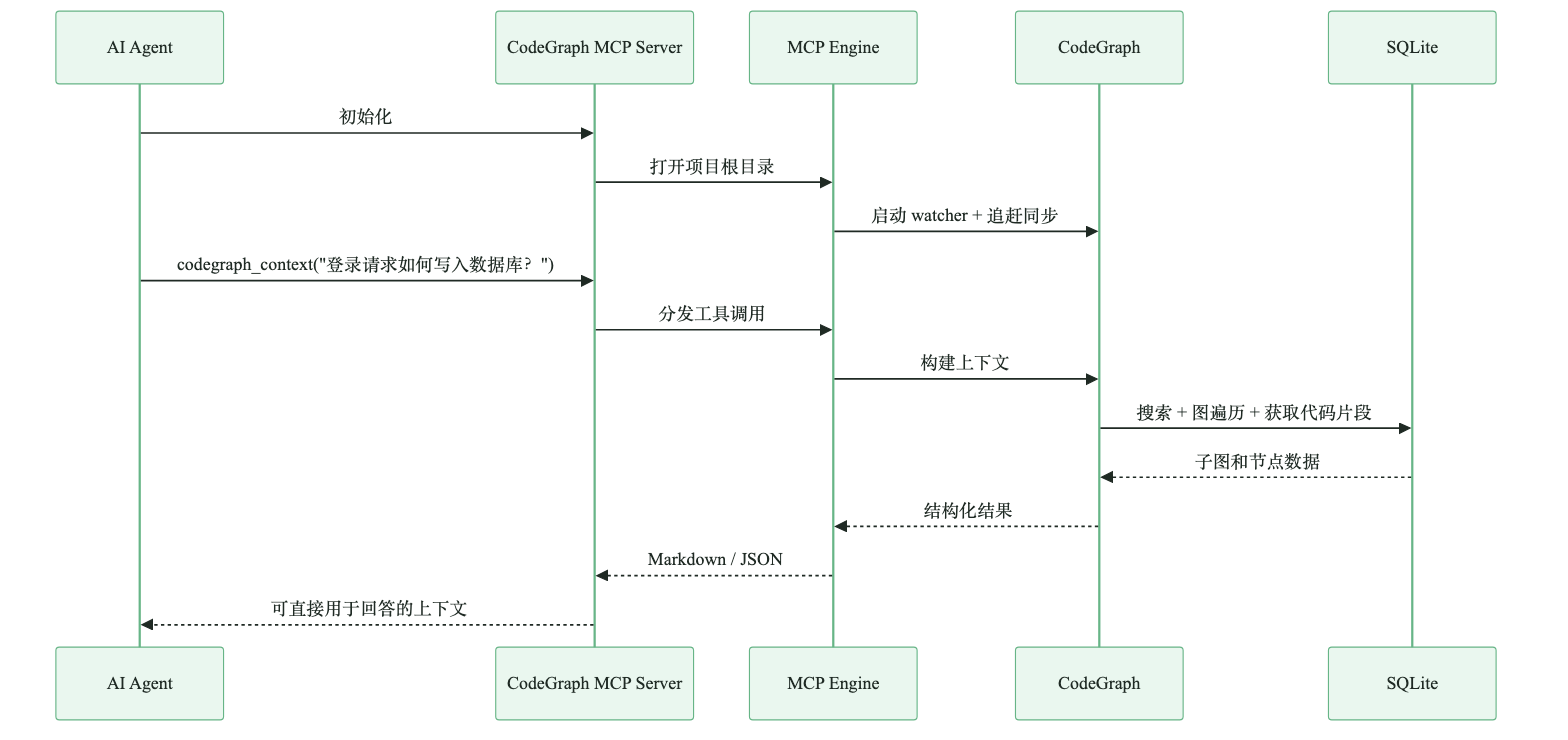
图:Agent 通过 MCP 查询本地代码图谱
这里有两个工程点值得保留。
一个是共享后台进程。Cursor、Claude Desktop、脚本工具可以连接同一个 codegraph serve --mcp 进程,避免每个客户端都重新索引。
另一个是同步窗口提示。文件刚变化时,工具结果会明确告诉 Agent 哪些信息可能旧。这会减少“模型拿旧索引强行推理”的风险。
Python Agent 的两种接入写法
如果项目里已经安装了 CodeGraph,可以先建索引:
cd /path/to/your-projectcodegraph init -i
没有全局安装时,也可以用 npx 启动 MCP 服务:
npx -y @colbymchenry/codegraph serve --mcp --path /path/to/your-project
LangChain / LangGraph
LangChain 体系里,langchain-mcp-adapters 可以把 MCP tools 转成 LangGraph Agent 可用的工具。
pip install langchain-mcp-adapters langgraph langchain-openai
如果不想依赖全局命令,把 MCP 启动参数改成:
"command": "npx","args": [ "-y", "@colbymchenry/codegraph", "serve", "--mcp", "--path", "/path/to/your-project",]
OpenAI Agents SDK
OpenAI Agents SDK 支持 stdio MCP server,接入方式更薄一些。
pip install openai-agents
CLI 和 Skill:把原子命令封成稳定动作
CLI 适合开发者直接验证,也适合放进自动化脚本。
# 初始化并建立索引
codegraph init -i
# 查看索引状态
codegraph status
# 搜索符号
codegraph query UserService
# 根据问题构造上下文
这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)