同样接数据库,凭什么别人的 AI 智能体不胡说
这两年「智能体直接操作数据库」「和你的数据对话」的演示满天飞,干净 schema 上跑起来像变魔术。可你有没有过这种经历:一把它接到真实的生产库上,它就开始一本正经地胡说八道?
国产大模型卷得飞起,Claude、GPT 一代比一代聪明,但模型再强,接上你那张几百表的老数据库,照样能把账算错。
问题到底出在哪——是模型不够聪明,还是它压根就没「看见」你的数据?
我们做过一个实验。把一个能力出众的 LLM 智能体摆到一个真实的生产环境 PostgreSQL 数据库面前,问了一个再简单不过的问题:
「我们上个季度的退款总额是多少?」
智能体写出了这样的查询:
SELECT SUM(amount) FROM refunds_audit WHERE created_at > '2024-01-01';
自信满满。语法完美无缺。却完全错了。
-
refunds_audit是一张变更日志表,并不是当前状态。
-
created_at用错了日期列。
-
它完全忽略了
refunds_2024_q1这个分区。 -
它从未去关联
orders表,而这个问题恰恰需要那里的上下文。
智能体并不蠢。它是盲的。
它能看见结构——表名、列类型——却看不见含义。再多的提示词工程也治不好这种失明。你必须给它一双眼睛。
正是这个缺口,让那么多「与你的数据对话」的演示在干净的 schema 上看起来如同魔法,一到真实的 schema 上就分崩离析。
问题所在:目录只有结构,没有语义
每个数据库都自带一个目录。PostgreSQL 有 information_schema 和 pg_catalog。它们告诉你有什么:表、列、类型、键、索引。
它们没有告诉你的,是这些东西各自意味着什么:
-
哪些表是真正的业务数据,哪些只是迁移记录表(
flyway_schema_history)、调度器(qrtz_triggers)或审计噪声? -
customer_id几乎可以肯定是要关联到
customers.id的——尽管从来没有声明过外键? -
events_2021 … events_2025是同一张逻辑表的五个物理分区?
-
带
_audit的表是用来记录历史的,绝不能拿它来做当前状态查询?
人类分析师要花上数月才能学会这些。LLM 智能体则一无所知。它看到的是一串扁平的名字,只能靠猜。而猜,正是问题的根源。
「智能体直接操作数据库」这类产品真正的瓶颈,从来不是模型,而是落地依据(grounding)。
简单来说:智能体和数据库讲的不是同一种语言
可以这样理解。
LLM 智能体精通语言——意图、问题、目标。你的数据库精通结构——表、类型、键。
谁也听不懂对方的话。
缺的是一个夹在中间的翻译官:一层持久、可审阅的语义,智能体读它来为自己的答案找到依据,人类读它来建立信任并加以纠正。
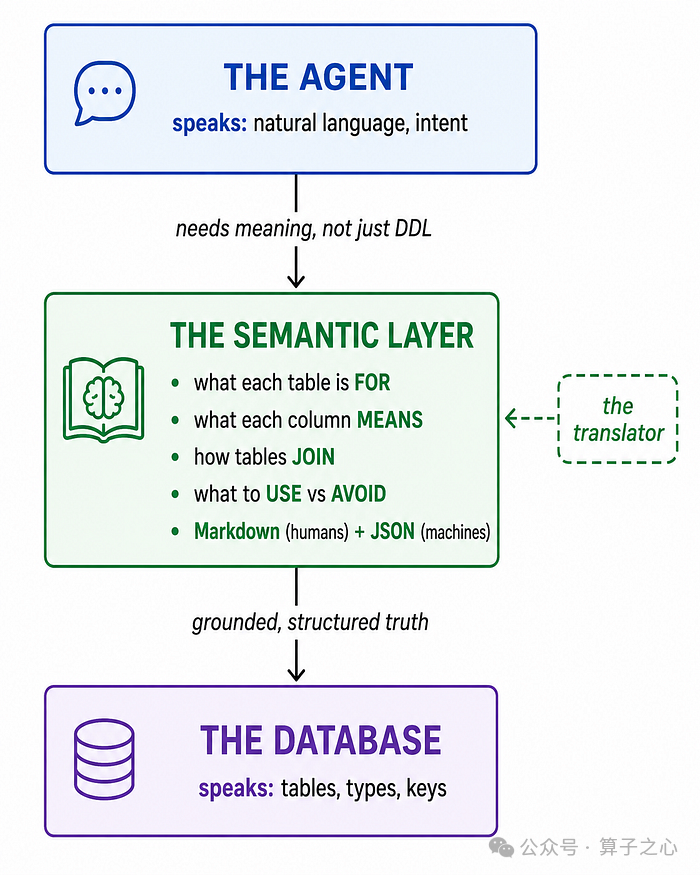
这个中间层,本质上是一份「契约」。 它在 git 里做版本管理,像代码一样被审阅,每当有人纠正它,它就变得更好。
这正是 SchemaScribe 背后的理念——一个开源工具,用一条命令就能从任意 PostgreSQL 数据库构建出这一层。
SchemaScribe 究竟是怎么工作的(深入剖析)
SchemaScribe 是一条五阶段的流水线。每个阶段都相互隔离、可测试、可替换。阶段 1–4 今天就能用。 阶段 5 才是你用来打造自己产品的地方。
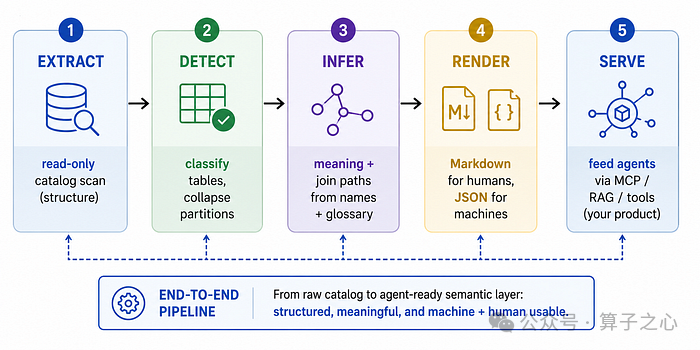
阶段 1 —— 提取(只读、批量、有韧性)
连接以只读方式打开,并启用autocommit=True和语句超时。它只对系统目录运行 SELECT。
它绝不会写入你的数据库——这是设计上的保证,而非口头承诺。
conn.set_session(readonly=True, autocommit=True)
autocommit 在这里有一个微妙的运维意义:一次耗时的元数据扫描不应该一直占着一个事务,从而阻塞你正在检视的那个生产副本上的 vacuum。
提取过程避开了经典的 N+1 查询陷阱。它不是每张表一条查询,而是每个 schema 中每种元数据类型只发一条批量查询——列、主键、外键、统计信息、注释、索引——然后在内存里把行分好组。
对于一个 400 张表的 schema,这意味着约 7 条查询,而不是约 2,800 条。
还有两个在生产环境中很关键的细节:
-
表的统计信息取自
pg_class,而不是information_schema。
reltuples和pg_total_relation_size()比逐行计数快得多,而在一张巨大的表上,你绝不会想仅仅为了给它写文档就去跑一遍COUNT(*)。 -
每一次取数都包了一层重试装饰器
,它会把瞬时错误(
OperationalError、InterfaceError)和编程错误区分开来。对前者它会带退避地重试;对后者,它会立即重新抛出——因为重试一个拼写错误只是白白浪费时间。
@retry_on_db_error() def get_columns(self, schema): ...
阶段 2 —— 识别(对表分类,折叠分区)
正是在这里,结构开始变成含义。两项工作:
给每张表分类,按名字、按优先级顺序——第一个匹配的胜出:

img_001
折叠分区。 一组正则阶梯能识别按时间分区的名字,并把它们折叠进一个逻辑条目:
detect_partition("events_2024", cfg) == ("events", "yearly") detect_partition("events_2024_06", cfg) == ("events", "monthly") detect_partition("events_2024_q1", cfg) == ("events", "quarterly")
于是 events_2021 … events_2025 就合并成了一个带年份范围的 events 页面——而不是五个几乎一模一样、把文档淹没的页面。
一个安全阀(min_partition_group_size,默认值 2)能防止它把那些只是碰巧以数字结尾的表也给折叠了。
阶段 3 —— 推断(在不触碰数据库的前提下得出含义)
这一阶段纯粹依据名字、类型和一份可配置的术语表工作。它从不查询你的数据——所以它连一行数据都泄露不了。
对于列,它会沿着一组启发式规则的阶梯逐级推断:
infer_column_meaning("customer_id") → "Reference to the Customer record" infer_column_meaning("created_at") → "Timestamp when this record was first created" infer_column_meaning("total_amount") → "Total monetary amount" infer_column_meaning("is_active") → "Whether this record is currently active"
一份内置的术语表涵盖了那些通用的名字(id、created_at、currency,甚至包括 isin、lei 这类公开的金融标识符)。其余的则交由后缀/前缀规则(_id、_at、_amount、is_、_flag……)处理,最后兜底落到一个「人类可读化」的方案上。
对于关系,它会综合两路信号:
那个置信度标签,正是诚实之所在。这个工具会在它只是在猜的时候,老老实实告诉你。
最重要的一条规则: 如果数据库里有一条真实的 COMMENT ON TABLE,它会压过一切猜测。每一行推断出来的内容都会被打上 _(inferred from naming)_(依据命名推断)的戳。绝无悄无声息的编造。
它还会生成一行密度很高的摘要,专门写来给 LLM 做简报:
public.orders是一张核心业务表,有 4 列,以
id为键,约 2,300,000 行。
阶段 4 —— 渲染(给人看的 Markdown,给机器看的 JSON)
Jinja2 模板把组装好的元数据转成:
docs/ ├── summary/ │ ├── database_overview.md ← start here │ └── schema_index.json ← machine-readable index └── schemas/public/ ├── schema_overview.md ├── schema_metadata.json └── tables/ ├── orders.md └── customers.md
每张表的页面都包含通俗易懂的用途说明、一张带推断含义的列表格、显式 + 推断的关系、示例查询、一行 AI 摘要,以及一节**「需要留意的坑」**。
JSON 是同样的内容,只是结构化了,供 RAG 流水线和工具链使用。
阶段 5 —— 提供服务(你的产品)
因为输出是纯粹的 Markdown + JSON,它能接入任何服务方案:一个 RAG 检索包、一个给智能体喂工具的 MCP 服务器、函数/工具描述,或是一份微调语料。
SchemaScribe 刻意止步于此。它是基底,而不是聊天机器人。
生产环境的考量(这部分把真正的工具和演示区分开来)
安全。 只读会话、语句超时(默认每条查询 2 分钟)、autocommit 让你不会在副本上占着事务。把它指向一个带只读凭证的只读副本,然后安心睡觉。
长时间运行的韧性。 给一个 400 张表的生产数据库写文档可能要花不少时间,而连接是会掉的。SchemaScribe 用三种机制来应对:
-
按 schema 隔离
——一个出问题的 schema 会被捕获、记录下来,然后这次运行继续进行。它不会让整个流程中止。
-
一个检查点文件
记录已完成的 schema。
--resume会跳过那些已经成功的工作。 -
一份
FAILURE_REPORT.md会准确列出哪些东西没能写成文档,这样你就可以只重试那些失败项。
conn = reconnect_if_needed(conn, config.database) # survives idle timeouts mid-run
可观测性。 清爽的进度打到控制台,完整的细节写进 schemascribe.log,而慢查询(>5 秒)会连同其耗时一起记录下来,这样你就能发现某条目录查询在一个庞大的 schema 上吃力的情况。
成本。几乎为零。 没有 LLM 调用,没有数据出口流量——它读取的是目录元数据,而不是你的数据行。推断靠的是确定性的启发式规则,而不是模型。
可调性。 零配置,开箱即用。一个小小的 YAML 文件就能覆盖一切——分区模式、用于关联推断的引用表、领域词汇,以及一份叠加合并在默认之上的术语表,因此你只需指定增量部分。密钥留在环境变量里(PG* 变量永远胜出),绝不会进 YAML。
这套设计规避的常见错误
1. 把推断出来的含义当成绝对真理。 对策:每一处猜测都打了标签,而真实的数据库注释永远凌驾其上。把输出当成一份强力的初稿,由人来审阅——而不是金科玉律。
2. N+1 查询风暴。 逐张表写文档会拿成千上万次往返来狂轰目录。改为按 schema 批量处理。
3. 为了行数去跑COUNT(*)。 在一张十亿行的表上,这是自找的宕机。用 pg_class.reltuples 估算值。
4. 在生产副本上占着一个长事务。 autocommit + 只读能避免阻塞 vacuum。
5. 让信号淹没在噪声里。 没有分类和分区折叠,你的智能体会把 events_2019 … events_2025、flyway_schema_history 和 qrtz_triggers 当成平起平坐的同类。做好分类和折叠,让业务表脱颖而出。
说到底,决定 AI 智能体靠不靠谱的,往往不是你换了多强的模型,而是你有没有先把数据的「含义」喂给它。
你现在用 AI 智能体在碰自己的数据库吗?踩过哪些「它一本正经胡说」的坑,评论区聊聊。
-------------------------------------------------------------
# 微信公众号:算子之心

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)