【Harness Engineering】从概念到初步实践
Harness学习指南:Harness Engineering 完全指南
前言
随着AI浪潮的兴起,大语言模型(LLM)和 Agent 技术快速发展,越来越多的企业开始尝试利用 AI 构建智能应用。然而,在实际开发过程中,人们很快会发现一个问题:让 AI "写代码" 很容易,但让 AI "稳定、准确、可持续地完成复杂工程任务" 却并不容易。
在一个真实的软件项目中,需求分析、架构设计、代码实现、测试验证、文档生成以及持续迭代,都不是一次性完成的工作,而是一个需要不断规划、执行、校验和修正的工程化过程。如果缺少统一的流程控制,AI 很容易出现上下文丢失、任务遗漏、实现偏离需求、重复修改甚至整体失控等问题。
正是在这样的背景下,**Harness Engineering(编排工程)**逐渐成为 AI 工程领域的重要实践方向。它并不是一种新的模型,也不是一种新的开发框架,而是一套围绕 AI 工作流进行设计、组织、约束和验证的方法论。其核心目标是:让 AI 不只是"会做事",而是能够按照工程规范,把事情持续、准确地做好。
对于刚接触这一概念的开发者而言,Harness Engineering 往往显得比较抽象:什么是 Harness?它与 Prompt Engineering、Context Engineering 有什么区别?为什么越来越多的 AI Agent 项目开始强调 Harness?又该如何将它真正应用到一个从 0 到 1 的项目开发过程中?
本文将围绕这些问题展开,从 Harness Engineering 的基本概念出发,结合实际开发流程,逐步介绍其核心思想、关键组成部分以及初步实践方法。希望通过通俗而系统的讲解,帮助读者建立对 Harness Engineering 的整体认知,并为后续构建更加稳定、可靠的 AI Agent 工程体系奠定基础。

一、认识Harness Engineering
1.1 什么是Harness Engineering
参考链接:Harness Engineering(驾驭工程) | 菜鸟教程
Harness Enginnering翻译过来就是【驾驭工程】。我们可以把大模型比作一匹马,那如果我们要更好的去驾驭,就需要通过“马具”来进行约束。
Harness Engineering(驾驭工程)是围绕 AI 智能体设计和构建约束机制、反馈回路、工作流控制和持续改进循环的系统工程实践。
它不优化模型本身,而是优化模型运行的环境。核心哲学八个字:人类掌舵,智能体执行(Human Steer, Agent Execute)。
Harness一词来自马具——缰绳、马鞍、嚼子——这是一套引导强大但不可预测的动物的完整装备。驾驭工程不是去削弱 AI 的能力,而是为它打造一套黄金缰绳,让它跑得又快又稳。
这个概念由 HashiCorp 联合创始人 Mitchell Hashimoto 在 2026 年 2 月 5 日首次提出,六天后 OpenAI 在百万行代码实验报告中正式采用这一术语,随后 Martin Fowler 撰文深度分析,一个月内成为开发者社区的高频词。
harness engineering is the idea that anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent will not make that mistake again in the future.
—— Mitchell Hashimoto
1.2 为什么需要Harness Engineering
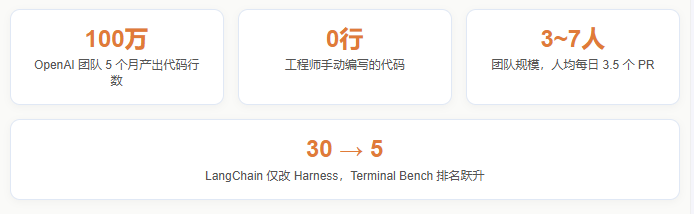
LangChain 的案例尤其有说服力:底层模型一个参数都没动,仅仅通过优化外部驾驭环境(文档结构、验证回路、追踪系统),编码 Agent 在 Terminal Bench 2.0 的得分从 52.8% 飙升至 66.5%,全球排名从第 30 位跃升至第 5 位。
五个独立团队也得出了相同结论:瓶颈不在模型智能,而在基础设施。
▲Harness与其他框架的关系
▲AI工程范式的三次跃迁

| 范式 | 核心问题 | 优化对象 | 交互模式 |
|---|---|---|---|
| 提示词工程 | 怎么把话说清楚 | Prompt 的措辞、格式、示例 | 一问一答 |
| 上下文工程 | 怎么给 AI 喂信息 | 文档、代码片段、历史对话 | 信息注入 → 生成 |
| 驾驭工程 | 怎么让 Agent 可靠工作 | 约束、反馈回路、控制系统 | 人类掌舵,Agent 执行 |
一个好记的类比:
Prompt Engineering:对马喊话的技巧
Context Engineering:给马看的地图
Harness Engineering:给马造一条高速公路,配上护栏、限速牌和加油站
二、Agent常见失败模式
Anthropic 工程师在长时间运行 Agent 的过程中,总结了三种典型的翻车姿势,正是驾驭工程要解决的核心痛点:
失败模式1:试图一步到位(One-shotting)
Agent倾向于在一个会话里把所有功能都做完。结果是上下文窗口耗尽,留下一堆没有文档的半成品代码,下一个会话启动时只能花大量时间猜测之前发生了什么。
失败模式2:过早宣布胜利
在项目后期,当部分功能已经完成后,Agent会环顾四周,看到已有进展就直接宣布任务完成一-即使还有大量功能未实现。
失败模式3:过早标记功能完成
在没有明确提示的情况下,Agent写完代码就标记为完成,却没有做端到端测试。单元测试或cur 命令通过了不代表功能真正可用。
此外,智能体还有一个危险特性:它非常擅长模式复制。代码库里有什么模式,它就忠实地复制并放大一一包括坏模式和架构漂移。这意味着不加约束的Agent会以惊人的速度积累技术债务。
三、驾驭工程的四大护栏
综合 OpenAI、Anthropic、LangChain 和 Martin Fowler 的实践,Harness 可以归纳为四个核心组件,即四根"护栏":
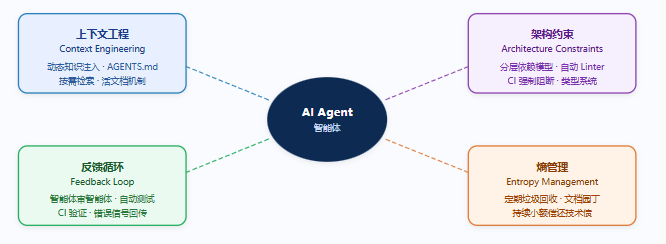
护栏一:上下文工程(Context Engineering)——新员工手册
就像给新员工一本详细的工作手册,AGENTS.md是AI智能体进入代码仓库时看到的第一份指南。但这不是一本静态的1000页说明书——上下文是稀缺资源,过多的指导反而会挤掉任务,代码和相关文档的空间,变成陈旧规则的坟场。
更好的做法是:提供一个稳定,小巧的入口点,然后教Agent根据当前任务按需检索和拉取更多的上下文。Mitchell Hashimoto的Ghostty 项目AGENTS.md 里每一行都对应一个历史Agent失败案例-——文档是活的反馈循环,不是静态制品。
护栏二:架构约束(Architecture Constraints)——缰绳
OpenAI 团队建立了严格的层级依赖模型:
Types → Config → Repo → Service → Runtime → UI
下层不能反向依赖上层。所有架构规则被编码为自定义 Linter 规则,违反即 CI 阻止合并——无论代码是人写的还是 AI 写的。
有个关键细节:Linter 的错误信息本身也是上下文工程。它不只说你违反了规则 X,而是解释为什么这个规则存在、正确做法是什么,这样 Agent 读到错误后就能自我理解并修正,不需要人类介入。
护栏三:反馈循环(Feedback Loop)——智能体审智能体
传统开发中,人类工程师负责代码审查(Code Review)。在驾驭工程中,这个工作变成了智能体对智能体的方式:Codex 在本地审核自身更改,请求额外审查,循环往复直到通过。
反馈循环中的钩子可以运行预定义的测试套件,并在失败时带着错误信息循环回到模型,或者提示模型独立评估其代码。如果 AI 写的测试用例通过了带有 Bug 的代码,Harness 就会判定测试无效,强迫它重新思考测试边界。
护栏四:熵管理(Entropy Management)——垃圾回收
随着时间推移,软件系统会逐渐混乱(熵增),技术债务会积累。OpenAI 采用持续小额偿还的策略,而不是等问题严重时集中处理——他们把这个方法形象地称为垃圾回收,并认为技术债务就像高息贷款。
具体措施:定期运行后台 Codex 任务扫描偏差、更新质量等级、发起针对性重构 PR。此外还有一个专门的 Doc-gardening Agent(文档园丁代理),在后台自动扫描文档与代码之间的不一致,发现过时内容就自动提交 PR 修复——Agent 为 Agent 维护文档。
四、Harness核心组件
综合OpenAl、 Anthropic、LangChain 和 Martin Fowler 的实践,Harness 可以归纳出一些核心组件
上下文工程(Context Engineering)——新员工手册
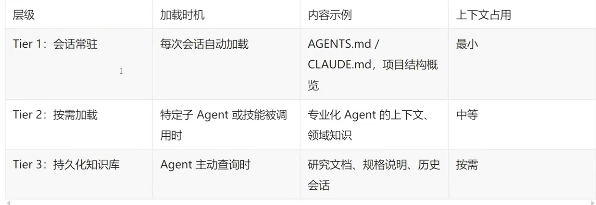
核心原则:Agent应当恰好获得当前任务所需的上下文一不多不少。
每个团队都独立发现,将所有指令塞进一个文件无法扩展。解决方案是分层上下文与渐进式披露;【OpenAI】使用AGENTS.md作为动态反馈循环文件,每当Agent遇到失败时更新。
【Anthropic】使用大量README和每次会话频繁更新的进度文件。
【Horthy】 倡导"频繁有意识压缩”(Frequent Intentional Compaction)。
【Vasilopoulos (2026 论文)】将上下文形式化为三层:热记忆 (Hot Memory) 、领域专家 (Domain Experts) 、冷记忆知识库(Cold-Memory Knowledge).。
▲实践建议——三层上下文体系:
五、Agent 专业化 (Agent Specialization)
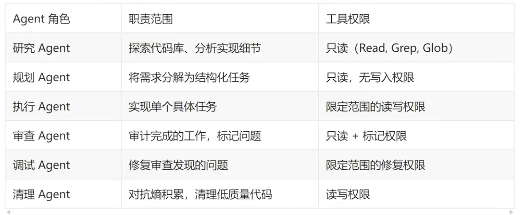
核心原则:专注于特定领域、拥有受限工具的Agent优于拥有全部权限的通用Agent.。
Carlini (Anthropic C编译器项目):将Agent专业化为编译器核心、去重、性能优化和文档四类角色。
Vasilopoulos:部署了 19个领域特定Agent。
Huntley:使用子Agent来保持主Agent上下文的清洁。专业化不仅是组织性的一一它本身就是上下文管理策略。每个专家因为携带更少的无关信息,所以运行在“Smart Zone”内。
实践中的角色分工:
持久化记忆(Persistent Memory)
核心原则:进度持久化在文件系统上,而非上下文窗口中。每次新Agent会话从零开始,通过文件系统制品重建上下文。Anthropic解决这一问题的方案堪称经典:
初始化Agent:首次会话使用专门的prompt,要求模型建立初始环境一init.sh脚本、claude-progress.txt进度文件和初始git提交。
编码 Agent:后续每次会话要求模型在做出增量进展的同时,留下结构化更新。每个编码Agent的典型会话启动流程如下:
1.运行pwd查看工作目录
2.读取git log和进度文件,了解最近的工作
3.读取feature list文件,选择最高优先级的未完成功能
4.启动开发服务器,运行基础端到端测试
5.确认基本功能正常后,开始新功能开发
关键发现:使用JSON格式追踪feature状态比 Markdown更有效,因为Agent 不太可能不恰当地修改或覆盖结构化数据。
结构化执行 (Structured Execution)
核心原则:将思考与执行分离。研究和规划在受控阶段进行,执行基于验证过的计划,验证通过自动化反馈(测试,Linter、CI)和人类审查完成。
所有团队都施加了刻意的执行序列:理解一规划一执行一验证。
OpenAI:使用声明式prompt和反馈回路。轻量的计划用于小变更,复杂工作通过带有进度和决策日志的执行计划完成,并检入仓库。
Huntley:将规划模式与构建模式分离。
Horthy 的Research-Plan-Implement 工作流围绕上下文管理精心设计。
人工检查点的价值:审查计划远比审查代码快。当规格正确时,实现自然可靠。当规格有误时,可以在500行代码生成之前及时纠正。
架构约束(Architecture Constraints)-缰绳
OpenAI团队建立了严格的层级依赖模型:
Types → Config → Repo → Service → Runtime → UI
下层不能反向依赖上层。所有架构规则被编码为自定义Linter规则,违反即CI阻止合并一一无论代码是人写的还是AI写的。
有个关键细节:Linter的错误信息本身也是上下文工程,它不只说你违反了规则x,而是解释为什么这个规则存在、正确、做法是什么,这样Agent读到错误后就能自我理解并修正,不需要人类介入。
反馈循环(Feedback Loop)--智能体审智能体
传统开发中,人类工程师负责代码审查(CodeReview)。在驾驭工程中,这个工作变成了智能体对智能体的方式:Codex在本地审核自身更改,请求额外审查,循环往复直到通过。
反馈循环中的钩子可以运行预定义的测试套件,并在失败时带着错误信息循坏回到模型,或者提示模型独立评估其代码。如果AI写的测试用例通过了带有Bug的代码,Harness就会判定测试无效,强迫它重新思考测试边界。
熵管理(Entropy Management)-垃圾回收
随着时间推移,软件系统会逐渐混乱(熵增),技术债务会积累,OpenAI采用持续小额偿还的策略,而不是等问题严重时集中处理——他们把这个方法形象地称为垃圾回收,并认为技术债务就像高息贷款。
具体措施:定期运行后台Codex任务扫描偏差,更新质量等级,发起针对性重构PR。此外还有一个专门的Doc-gardening Agent(文档园丁代理),在后台自动扫描文档与代码之间的不一致,发现过时内容就自动提交PR修复Agent, 为Agent 维护文档。
六、Harness业界最佳实战案例
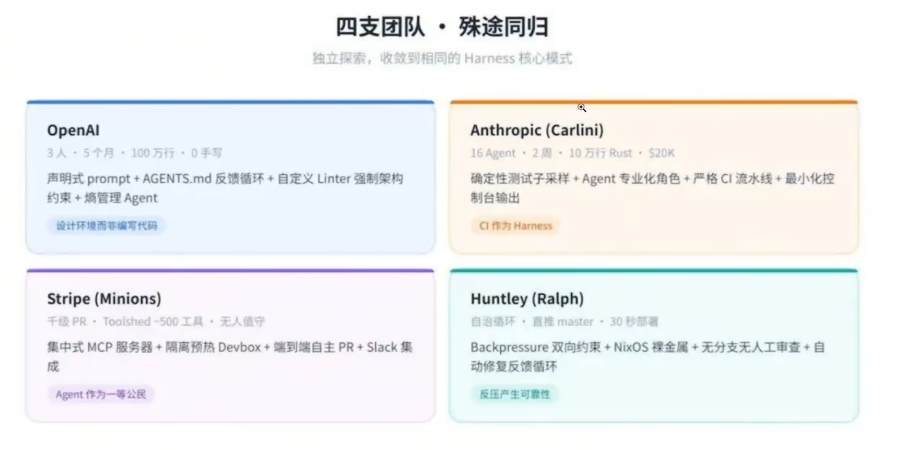
6.1 Openai:百万行代码的零手写实验
五大Harness原则:
原则1:设计环境,而非编写代码。工程师的工作转向为Agent准备高效运行的环境。当Agent卡住时,不是"更加努力",而是诊断"缺少什么能力”并让Agent自己构建该能力。
原则2:机械化地执行架构约束。他们为每个领域定义了
依赖方向→TypesConfig→RepoServiceRuntime→UI——并用自定义Linter和结构测试自动检测违规。文档中记录是不够的;如果不能机械化地强制执行,Agent就会偏离。原则3:将代码仓库作为唯一事实源。写在Slack讨论或Google Docs中的知识对Agent来说等于不存在。所有团队知识都作为版本控制的制品放置在仓库中。
原则4:将可观测性连接到Agent。他们将Chrome DevTools连接到运行时,使Agent 能够捕获DOM快照和截图。
通过赋予查询日志和指标的能力,"将启动时间降至800ms以下"变成了可度量的目标。原则5:对抗熵。最初团队每周五花20%的时间手动清理"AI Slop”(低质量生成物)。这后来被自动化为Codex运行的后台任务一清理吞吐量与代码生成吞吐量成正比扩展。
自定义Linter的巧妙设计:当Agent 违反架构约束时,错误消息不仅标记违规--还告诉 Agent如何修复。工具在Agent工作时同时"教会”它。
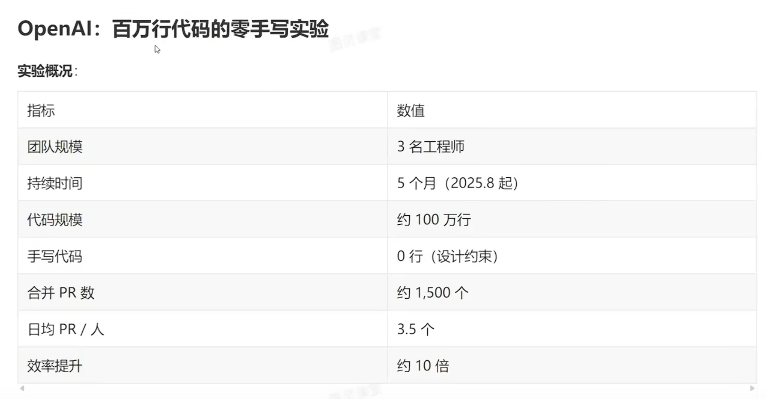
6.2 Anthropic:16个Agent 构建 C 编译器
Carlini 的C编译器项目可能是目前最硬核的Agent自主开发压力测试.
项目数据: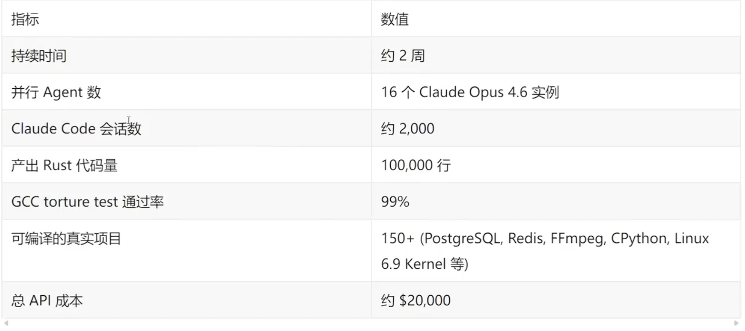
关键Harness设计:
上下文窗口污染缓解:最小化控制台输出,日志写入文件,使用grep友好的错误格式(ERROR:[reason]单行),预计算聚合统计而非输出原始数据。
Agent时间盲区:Claude"无法感知时间,如果放任不管,会乐于花几个小时运行测试而不是推进工作。”解决方案:确定性测试子采样。每个Agent运行随机1-10%的测试,但子采样对单个Agent是确定性的,跨VM是随机的--所以集体覆盖了完整的测试套件。
专业化而非通用化:随着项目成熟,Agent 承担了专门角色一一核心编译器工作、去重(LLM生成的代码经常重新实现已有功能)、性能优化、代码质量和文档。
CI作为Harness:接近尾声时,Claude在实现新功能时频繁破坏现有功能。修复方案是一个更严格的CI流水线——用Harness层面的解决方案应对模型层面的问题。
Carlini自己的总结很到位:“我必须不断提醒自己,我是在为Claude写这个测试框架,不是为自己写。
6.3 Anthropic:长时间运行 Agent 的有效 Harness
Anthropic工程团队从另一个角度切入——跨上下文窗口的连续性问题——来研究Harness设计.
核心痛点:长时间跑的Agent必须在一个个独立会话里工作,每次新会话启动时对前一次做了什么一无所知。就像一个项目组全是轮班工程师,每个人上岗时对之前的进展一脸懵。
两阶段解决方案:
初始化 Agent:使用专门的prompt建立初始环境,包括init.sh脚本、claude-progress.txt 进度日志和初始 git 提交。
编码Agent:每次后续会话要求模型做出增量进展,然后留下结构化更新。
四大失败模式与对策:

浏览器自动化测试:为Claude提供Puppeteer MCP等测试工具后,Agent 能够识别和修复仅从代码层面无法看到的bug,显著提升了端到端验证的效果。


七、Harness行业应用落地准则
综合OpenAl、Anthropic、LangChain、Stripe、HashiCorp 等多个独立信息源,业界在以下六个方面已形成明确共识:
| # | 共识 | 核心观点 |
|---|---|---|
| 1 | 瓶颈在基础设施,不在模型智能 | 五个独立团队得出相同结论。仅改变 Harness 工具格式,就能让模型得分从 6.7% 跳到 68.3% |
| 2 | 文档必须是活的反馈循环 | 静态文档是坟场,动态文档才有价值。让后台 Agent 定期清理过时文档并提交 PR |
| 3 | 思考与执行分离 | 复杂任务不可能在单个上下文窗口内完成,需要 Orchestrator + Worker 分层架构,状态持久化到外部存储 |
| 4 | 上下文不是越多越好 | 上下文是稀缺资源。巨大的指令文件会挤掉任务空间,应按需检索、动态注入 |
| 5 | 约束必须自动化 | 人工 Review 是瓶颈。护栏要编码为 Linter、CI、类型系统,让机器来执行而非人 |
| 6 | 工程师角色在转变 | 从代码的编写者变成环境的建筑师。最大的工程挑战是设计让 Agent 可靠工作的控制系统 |
八、Harness 项目开发应用实战
需求:基于 Harness Engineering 从0到1开发一个Java项目
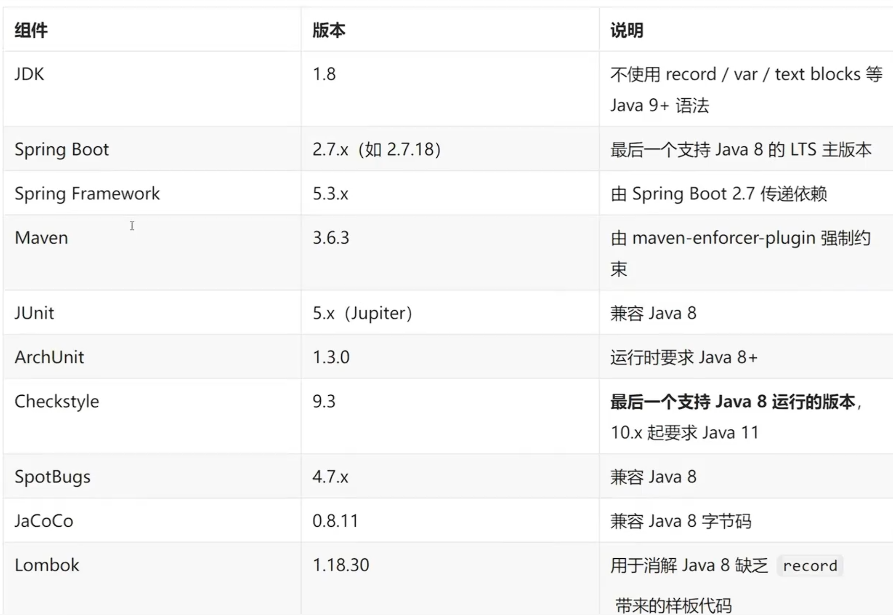
8.1 环境准备
技术栈:Spring Boot 2.7.x +Java 1.8 + Maven 3.6.3
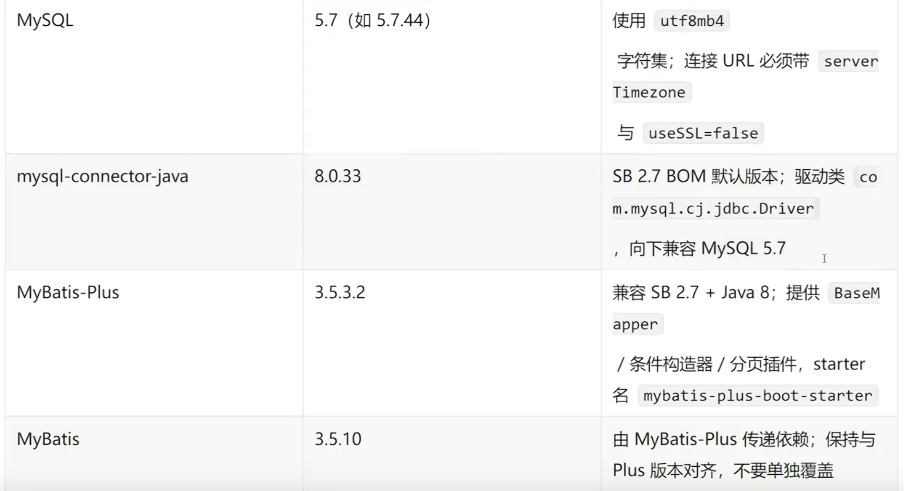

8.2 落地路线图:三步走
在动手之前,先画清楚路线。Harness Engineering的落地不是"一把梭”,而是渐进式的:

不要一步到位。很多人失败就在于想一次性搭完所有基础设施。阶段1已经能带来显著提升,阶段2是质变点,阶段3是锦上添花。
阶段1:信息层——让Agent“看得懂”你的项目
AGENTS.md:写地图,不写百科全书
OpenAI用“地图模式”替代超长指令文件。这里给出可以直接拷贝使用的模板。
反面教程(别这么写)

问题:挤占上下文窗口、难以维护、Agent很难定位需要的信息。
正确做法(直接用):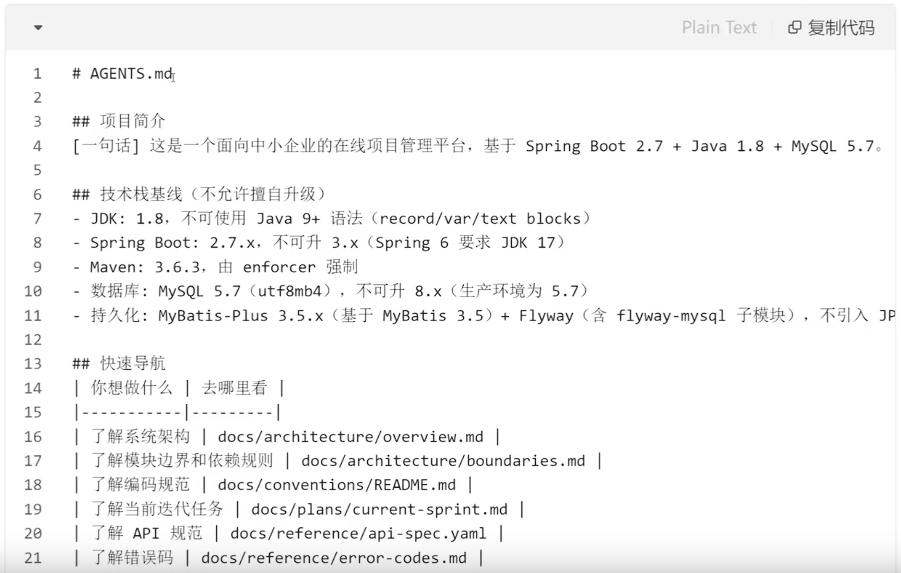
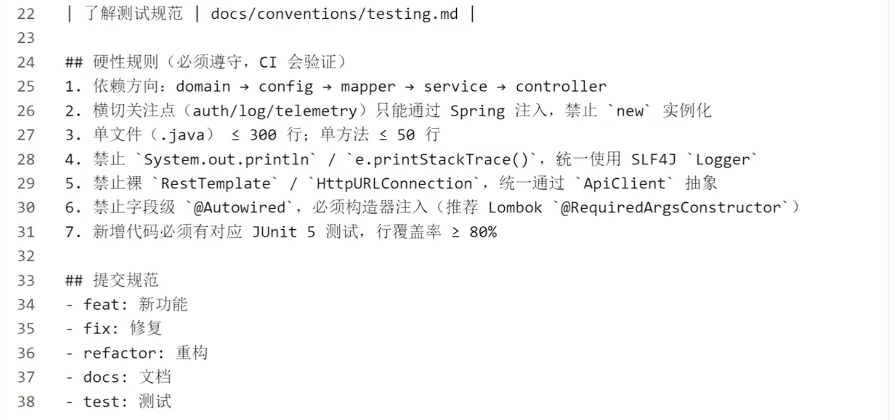
关键设计原则:
▲AGENTS.md控制在50-100行。超过就说明你在写百科全书了
▲·"你想做什么→去哪里看”比‘这是什么’更有效——面向任务而非面向知识
▲·硬性规则单独列出,这些是CI会强制脸证的,不是"建议"
docs/目录:结构化知识库
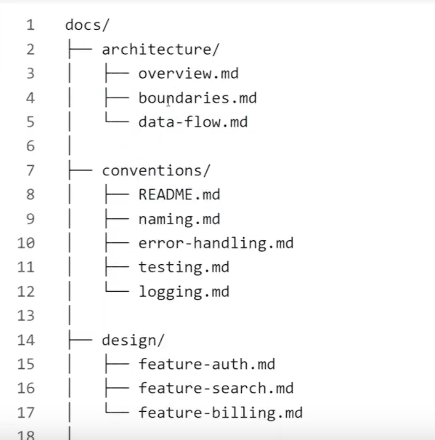

每个文档的头部都加上元信息:

这样 doc-gardening Agent 可以自动扫描过期文档。
设计文档模板
Agent执行复杂功能前,先写设计文档。以下是模板:


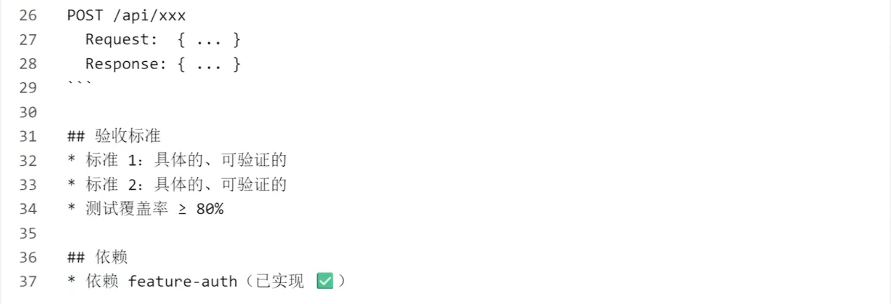
为什么要这么做:Agent拿到一个功能需求后,先填写这个模板(或人工填写),审批通过后再动手写代码。这就是”明确意图"的工程化实现。
阶段2:约束层一让Agent"不能犯错”
Spring boot 2.7工程上的标准包结构:

下面给出具体的Linter配置
分层依赖检查
JAVA 1.8+Spring Boot项目:用ArchUnit
新增依赖(po.xml)
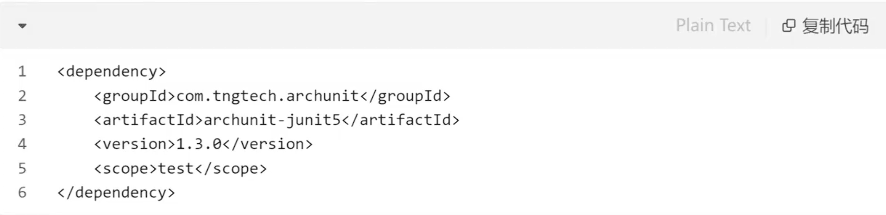
新增架构测试(src/test/java/com/example/app/architecture/LayerDependencyTest.java):
package com.example.app.architecture;
import com.tngtech.archunit.core.importer.ImportOption;
import com.tngtech.archunit.junit.AnalyzeClasses;
import com.tngtech.archunit.junit.ArchTest;
import com.tngtech.archunit.lang.ArchRule;
import static com.tngtech.archunit.library.Architectures.layeredArchitecture;
import static com.tngtech.archunit.lang.syntax.ArchRuleDefinition.noClasses;
@AnalyzeClasses(
packages = "com.example.app",
importOptions = ImportOption.DoNotIncludeTests.class
)
public class LayerDependencyTest {
@ArchTest
public static final ArchRule layered = layeredArchitecture()
.consideringAllDependencies()
.layer("Domain").definedBy("..domain..")
.layer("Config").definedBy("..config..")
.layer("Mapper").definedBy("..mapper..")
.layer("Service").definedBy("..service..")
.layer("Controller").definedBy("..controller..")
.layer("Infrastructure").definedBy("..infrastructure..")
.whereLayer("Controller").mayNotBeAccessedByAnyLayer()
.whereLayer("Service").mayOnlyBeAccessedByLayers("Controller")
.whereLayer("Mapper").mayOnlyBeAccessedByLayers("Service")
.as(
"X 层级依赖违规。\n" +
"☑ FIX: Controller 必须经 Service, Service 通过 MyBatis-Plus Mapper 访问数据。\n" +
"☑ See: docs/architecture/boundaries.md"
);
@ArchTest
public static final ArchRule controllerMustNotUseMapper = noClasses()
.that().resideInAPackage("..controller..")
.should().dependOnClassesThat().resideInAPackage("..mapper..")
.as(
"X Controller 不得直接依赖 Mapper。\n" +
"☑ FIX: 在 Service 中编排数据访问,Controller 仅持有 Service 引用。\n" +
"☑ See: docs/architecture/boundaries.md"
);
@ArchTest
public static final ArchRule noFieldInjection = noClasses()
.should().beAnnotatedWith("org.springframework.beans.factory.annotation.Autowired")
.as(
"X 禁止字段级 @Autowired。\n" +
"☑ FIX: 构造器注入:\n" +
"☑ @RequiredArgsConstructor\n" +
"☑ public class UserService {\n" +
"☑ private final UserMapper userMapper; \n" +
"☑ } \n" +
"☑ See: docs/conventions/di.md"
);
}注意:示例中字段一律用 public static final (而不是包私有),是因为Java 8+JUnit 5 的字段访问要求;Spring Boot 2.7 + ArchUnit 1.3 在 Java 8 上完可用.
自定义 Linter 规则:错误信息即 Prompt
这是Hamness Engineering最有杠杆的实践之一。核心思路:每条Linter 报错都必须包含三要素--问题是什么、怎么修、去哪看文档。
以ArchUnit自定义规则为例,禁止直接使用 RestTemplate / HttpURLConnection(要求统一通过 ApiClient):
@ArchTest
public static final ArchRule noRawHttpClient = noClasses()
.should().dependOnClassesThat()
.haveFullyQualifiedName("org.springframework.web.client.RestTemplate")
.orShould().dependOnClassesThat()
.haveFullyQualifiedName("java.net.HttpURLConnection")
.orShould().dependOnClassesThat()
.haveFullyQualifiedNames("org.apache.http.client.HttpClient")
.as(
"X 禁止直接使用 RestTemplate / HttpURLConnection / Apache HttpClient。\n" +
"☑ FIX: 注入统一的 API Client: \n" +
"☑ private final ApiClient apiClient; // 构造器注入\n" +
"☑ Foo foo = apiClient.get(\"/endpoint\", Foo.class);\n" +
"☑ See: docs/conventions/api-calls.md"
);或用 Checkstyle 的E则规则, 禁止 System.out.println / e.printStackTrace()
(注意Java8兼容须用Checkstyle,9.3)
<module name="RegexpSingleLineJava">
<property name="format" value="System\.out\.println"/>
<property name="message"
value="✖ 禁止 System.out.println。
☑ FIX: private static final Logger log = LoggerFactory.getLogger(X.class);
☑ log.info("message {}", arg);
☑ See: docs/conventions/logging.md"/>
</module>
<module name="RegexpSingleLineJava">
<property name="format" value="\.printStackTrace(\()"/>
<property name="message"
value="✖ 禁止 e.printStackTrace()。
☑ FIX: log.error("context message", e);
☑ See: docs/conventions/logging.md"/>
</module>一个万能公式:
1. ❌ [什么错了]
2. ✅ FIX: [怎么改,给出代码片段]
3. ✅ See: [哪个文档有详细说明]Agent看到这种报错,不需要任何额外提示就能自动修复,你写的每一条Linter 规则,本质上都是一个自动触发的Prompt.。
完整 pom.xml 关键片段
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.18</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>taskapp</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- 工具版本(均锁定为 Java 8 兼容版本) -->
<archunit.version>1.3.0</archunit.version>
<checkstyle.version>9.3</checkstyle.version>
<maven-checkstyle-plugin.version>3.3.1</maven-checkstyle-plugin.version>
<spotbugs-maven-plugin.version>4.7.3.6</spotbugs-maven-plugin.version>
<jacoco.version>0.8.11</jacoco.version>
<maven-enforcer-plugin.version>3.4.1</maven-enforcer-plugin.version>
<lombok.version>1.18.30</lombok.version>
<mybatis-plus.version>3.5.3.2</mybatis-plus.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 持久化:MyBatis-Plus(替代 Spring Data JPA + Hibernate) -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.tngtech.archunit</groupId>
<artifactId>archunit-junit5</artifactId>
<version>${archunit.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 锁定 Maven 与 JDK 版本:不达标直接构建失败 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-enforcer-plugin</artifactId>
<version>${maven-enforcer-plugin.version}</version>
<executions>
<execution>
<id>enforce-tooling</id>
<goals><goal>enforce</goal></goals>
<configuration>
<rules>
<requireMavenVersion>
<version>[3.6.3,)</version>
<message>
✖ Maven 版本过低。
✅ FIX: 使用 Maven 3.6.3 及以上(项目基线)。
☑ See: docs/conventions/build.md
</message>
</requireMavenVersion>
<requireJavaVersion>
<version>[1.8,9)</version>
<message>
✖ JDK 版本不符。
✅ FIX: 使用 JDK 1.8 编译;不要升级到 9+。
☑ See: docs/conventions/build.md
</message>
</requireJavaVersion>
</rules>
</configuration>
</execution>
</executions>
</plugin>
<!-- Checkstyle: 必须显式指定 9.3,否则 maven-checkstyle-plugin 会拉取 Java 11+ -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
<version>${maven-checkstyle-plugin.version}</version>
<dependencies>
<dependency>
<groupId>com.puppycrawl.tools</groupId>
<artifactId>checkstyle</artifactId>
<version>${checkstyle.version}</version>
</dependency>
</dependencies>
<configuration>
<configLocation>config/checkstyle/checkstyle.xml</configLocation>
<consoleOutput>true</consoleOutput>
<failsOnError>true</failsOnError>
<violationSeverity>warning</violationSeverity>
</configuration>
<executions>
<execution>
<phase>verify</phase>
<goals><goal>check</goal></goals>
</execution>
</executions>
</plugin>
<!-- SpotBugs -->
<plugin>
<groupId>com.github.spotbugs</groupId>
<artifactId>spotbugs-maven-plugin</artifactId>
<version>${spotbugs-maven-plugin.version}</version>
<configuration>
<effort>Max</effort>
<threshold>Low</threshold>
<failOnError>true</failOnError>
</configuration>
<executions>
<execution>
<phase>verify</phase>
<goals><goal>check</goal></goals>
</execution>
</executions>
</plugin>
<!-- JaCoCo 覆盖率 ≥ 80% -->
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>${jacoco.version}</version>
<executions>
<execution><goals><goal>prepare-agent</goal></goals></execution>
<execution>
<id>jacoco-check</id>
<phase>verify</phase>
<goals><goal>check</goal></goals>
<configuration>
<rules>
<rule>
<element>BUNDLE</element>
<limits>
<limit>
<counter>LINE</counter>
<value>COVEREDRATIO</value>
<minimum>0.80</minimum>
</limit>
</limits>
</rule>
</rules>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>CI管线配置:完整的Agent护栏
name: Agent Guardrails
on: [pull_request]
jobs:
quality-gates:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up JDK 1.8
uses: actions/setup-java@v4
with:
distribution: 'temurin'
java-version: '8'
cache: maven
# GitHub Actions runner 默认 Maven 版本可能与基线不一致,强制对齐 3.6.3
- name: Set up Maven 3.6.3
uses: stCarolas/setup-maven@v5
with:
maven-version: 3.6.3
- name: Verify tooling
run: |
java -version
mvn -v
# 编译 + 单测 + Checkstyle + SpotBugs + JaCoCo (>= 80%) + ArchUnit
# 全部绑定到 verify 阶段,一次执行;enforcer 会顺带验证 Maven/JDK 版本
- name: Build & Verify
run: mvn -B clean verify
- name: Architecture Check (ArchUnit, 单独打日志)
run: mvn -B test -Dtest='*ArchTest,LayerDependencyTest'
- name: File Size Check
shell: bash
run: |
find src/main/java -name '*.java' | while read f; do
lines=$(wc -l < "$f")
if [ "$lines" -gt 300 ]; then
echo "✖ $f 有 $lines 行(上限 300)"
echo "☑ FIX: 拆分为更小的类,将辅助方法移至 *Helper 或 infrastructure。"
echo "☑ See: docs/conventions/file-size.md"
exit 1
fi
done
- name: Doc Freshness
shell: bash
run: |
find docs/design/ -name '*.md' | while read f; do
last_mod=$(git log -1 --format=%ct "$f")
now=$(date +%s)
days_old=$(((now - last_mod) / 86400))
if [ "$days_old" -gt 60 ]; then
echo "⚠️ $f 已 ${days_old} 天未更新,可能已过期"
fi
done把主观品味翻译成机械规则
| 主观品味(团队口头约定) | 机械化规则 | 实现方式 |
|---|---|---|
| "方法要短" | 单方法 ≤ 50 行 | Checkstyle MethodLength |
| "文件要短" | 单文件 ≤ 300 行 | Checkstyle FileLength |
| "日志要规范" | 禁止 System.out / printStackTrace | Checkstyle 正则规则 |
| "HTTP 调用要统一" | 禁止裸 RestTemplate / HttpURLConnection | ArchUnit 自定义规则 |
| "Controller 要纯" | Controller 不得直接调用 Mapper | ArchUnit 分层规则 |
| "依赖要构造器注入" | 禁止字段级 @Autowired | ArchUnit 注解检查 |
| "不要污染全局" | 禁止 public static 非 final 字段 | SpotBugs MS_* 规则族 |
| "测试要充分" | 行覆盖率 ≥ 80% | JaCoCo coverage check |
| "锁定构建工具版本" | Maven ≥ 3.6.3, JDK = 1.8 | maven-enforcer-plugin |
经验法则:如果一条规则在Code Review中被提过3次以上,就应该写成Linter规则。
阶段3:自动化层一-让Agent自我验证和自我修复
后台清理Agent:定时任务模板
# 任务:代码库卫生清理
请执行以下检查,对每个发现的问题生成独立的修复 PR:
## 检查清单
1. **超长文件**:找出 src/main/java/ 下超过 300 行的 .java 文件,拆分为更小的类
2. **缺失测试**:找出 src/main/java/ 下没有对应 *Test.java 的类,补充基础测试
3. **未使用的 import**:清理所有未使用的 import 语句
4. **TODO/FIXME**:列出所有 TODO 和 FIXME,超过 30 天未处理则生成清理 PR
5. **重复代码**:找出高度相似的代码段(>10 行),提取为共享工具类(infrastructure/)
6. **过时文档**:检查 docs/design/ 中状态为 Draft 但已超过 30 天的文档
7. **Checkstyle/SpotBugs 历史告警**:清理 mvn verify 中累积的非阻塞告警
## 约束
- 每个修复作为独立 PR,不要混在一起
- 每个 PR 修改后必须确保 `mvn -B clean verify` 通过
- PR 标题格式:`chore(cleanup): [具体描述]`
- 不允许使用 Java 9+ 语法 (record/var/text blocks),保持 JDK 1.8 兼容
- 不允许升级 Spring Boot 主版本 (保持 2.7.x)
- 如果不确定某个修改是否安全,跳过并在 PR 中标注原因Git Worktree 自动化脚本
#!/bin/bash
BRANCH=$1
WORKTREE_DIR="/tmp/agent-verify-$(date +%s)"
echo "创建 worktree: $WORKTREE_DIR"
git worktree add "$WORKTREE_DIR" "$BRANCH"
cd "$WORKTREE_DIR"
echo "校验工具链版本..."
java -version 2>&1 | grep "1.8" || { echo "必须使用 JDK 1.8"; exit 1; }
mvn -v | grep 'Apache Maven 3.6.3' || { echo "必须使用 Maven 3.6.3"; exit 1; }
echo "编译并跑全量校验(enforcer + Checkstyle + SpotBugs + ArchUnit + 单测 + JaCoCo)..."
mvn -B clean verify || { echo "失败"; exit 1; }
echo "启动 Spring Boot 应用做健康检查..."
mvn -B spring-boot:run > /tmp/app.log 2>&1 &
APP_PID=$!
# 等待应用启动(默认 8080,actuator 健康检查)
for i in {1..30}; do
sleep 2
if curl -sf http://localhost:8080/actuator/health | grep -q '"status":"UP"'; then
echo "✅ 健康检查通过"
kill $APP_PID 2>/dev/null
cd -
git worktree remove "$WORKTREE_DIR"
echo "✅ 所有验证通过"
exit 0
fi
done
echo "❌ 应用启动失败或健康检查未通过,最近日志:"
tail -n 50 /tmp/app.log
kill $APP_PID 2>/dev/null
exit 1可观测性接入:让Agent能"看日志”
在本地开发环境部署一个轻量级的可观测性堆栈:
version: '3.8'
services:
loki:
image: grafana/loki:2.9.0
ports: ["3100:3100"]
promtail:
image: grafana/promtail:2.9.0
volumes:
- ./logs:/var/log/app
- ./promtail-config.yml:/etc/promtail/config.yml
prometheus:
image: prom/prometheus:latest
ports: ["9090:9090"]
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana:latest
ports: ["3001:3000"]
depends_on: [loki, prometheus]Spring Boot 2.7 侧只需开启 Actuator + Micrometer Prometheus (含在 actuator starter 中) :
# application.yml
management:
endpoints:
web:
exposure:
include: health,info,metrics,prometheus
metrics:
tags:
application: ${spring.application.name}同时在 application.yml 中给出 MyBatis-Plus 与数据源的最小可工作配置(与 Hiberate MySQL570ialect无关;不再使用spring.jpa.*):
spring:
datasource:
url: jdbc:mysql://localhost:3306/taskapp?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8mb4&allowPublicKeyRetrieval=true
username: app
password: ${DB_PASSWORD}
driver-class-name: com.mysql.cj.jdbc.Driver
flyway:
enabled: true
locations: classpath:db/migration
baseline-on-migrate: true
mybatis-plus:
mapper-locations: classpath*:/mapper/**/*.xml
type-aliases-package: com.example.app.domain.model
global-config:
db-config:
id-type: auto
logic-delete-field: deleted
logic-not-delete-value: 0
logic-delete-value: 1
configuration:
map-underscore-to-camel-case: true
cache-enabled: false@MapperScan 与分页插件单独放在 config/MybatisPlusConfig.java ,以便 ArchUnit 仅在 ...config... 这一层看到它:
@Configuration
@MapperScan("com.example.app.mapper")
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}并在 1ogback-spring.xml 中启用JSON结构化日志(logstash-logback-encoder),落盘到./logs/ 供
Promtail 抓取。
Agent排错时可以用这样的Prompt:
1. 应用在 /api/users 端点返回 500 错误。
2. 请查看 Loki 日志(http://localhost:3100)中最近 5 分钟的错误日志。
3. 对照 Spring Boot 的 traceId 找到完整调用链。
4. 定位根因并修复。修复后重新跑 `mvn -B clean verify` 与对应的 `*Test` 验证。开源工具推荐:按落地阶段选择
工具全景图
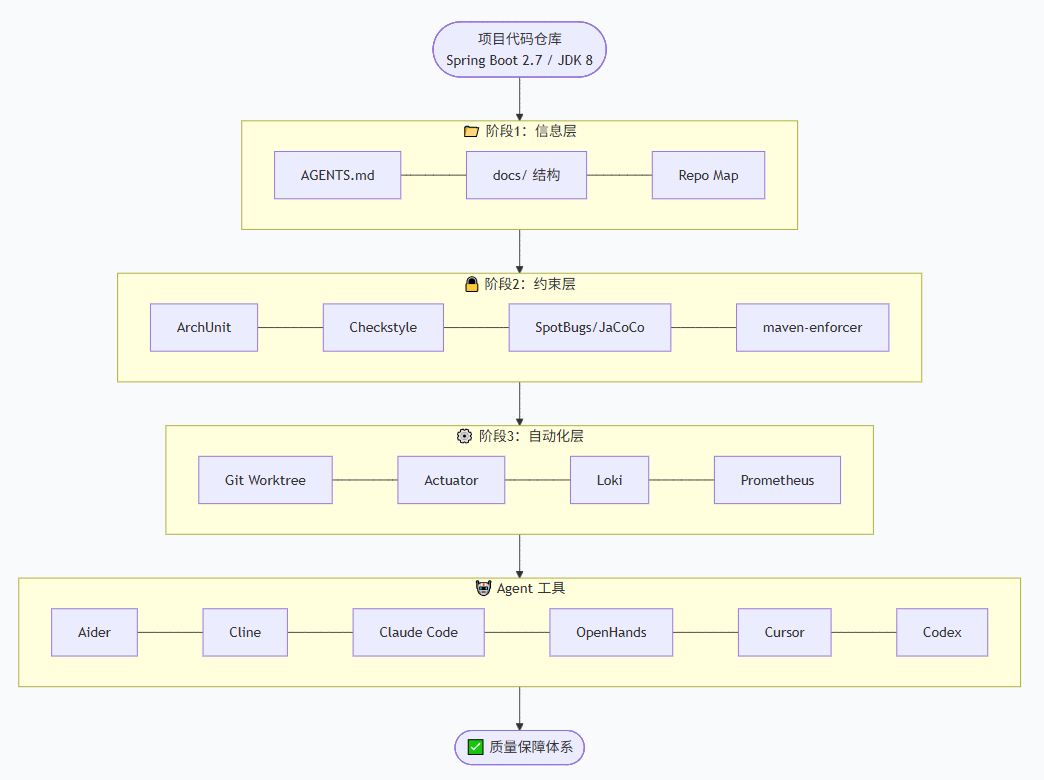
Agent工具对比与选型
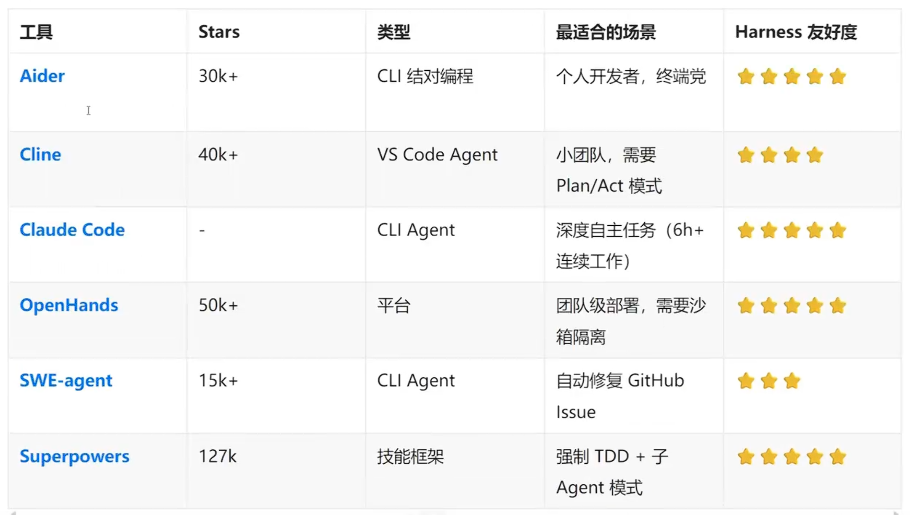
怎么选:
▲个人项目,想快速体验一Aider。30分钟上手,Repq Map天然实现"渐进式披露",可配置作为自mvn verify动反馈回路。
pip install aider-chat
cd your-spring-project && aider --model gpt-4o --test-cmd "mvn -B clean verify"▲团队项目,需要流程控制→Cline +Superpowers。Plar/Act 模式让你审批 Agent 的计划再执行,Superpowers强制TDD,
▲生产级,需要完全隔离→OpenHands。Docker沙箱确保Agent操作不影响主环境,模型无关.。
Superpowers 深度解析
Superpowers 是目前 Harness Engineering思想最完整的开源实现.
核心流程:

杀手特性一-强制TDD:如果检测到Agent在测试之前写了实现代码,直接删除那段代码,强制从测试开始。这保证每段代码都有验证。正是Harness Engineering"Verify’环节的核心。
学习资源
| 资源 | 类型 | 适合谁 | 链接 |
|---|---|---|---|
| deusyu/harness-engineering | GitHub 学习指南 | 从零入门 | deusyu/harness-engineering: Harness Engineering 学习指南 — 从概念理解到独立实践的深度学习档案 |
| harness-engineering.ai | 知识图谱(883 实体) | 快速了解生态全景 | Website |
| OpenAI 原文 | 博客 | 理解原始思想 | OpenAI |

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)