Agent 核心原理:把关键流程跑顺
这篇不先堆名词。我们把《Agent 核心原理:把关键流程跑顺》拆成几级台阶,看完至少知道下一步该学什么、该练什么。
摘要
本文概述文章目标、核心观点和实践价值。
> **摘要**:做企业内部数据查询 Agent 时,我们最初迷信“提示词越长越聪明”,结果模型在复杂条件面前频繁幻觉。后来砍掉花哨的 Prompt Engineering,回归状态机与工具链的底层逻辑,才把响应稳定率拉到 92%。本文不聊概念堆砌,只复盘我们在规划拆解、工具接入、记忆管理和异常兜底上的实际取舍。适合想摸清 Agent 运行骨架的开发者。
> 分类:AI Agent
> 账号:IT技能树
> 批次:2026-06-19:IT技能树:1:agent-core-principles
目录
- Agent 的本质
- 规划能力
- 工具调用
- 记忆系统
- 失败恢复
- 总结
Agent 的本质
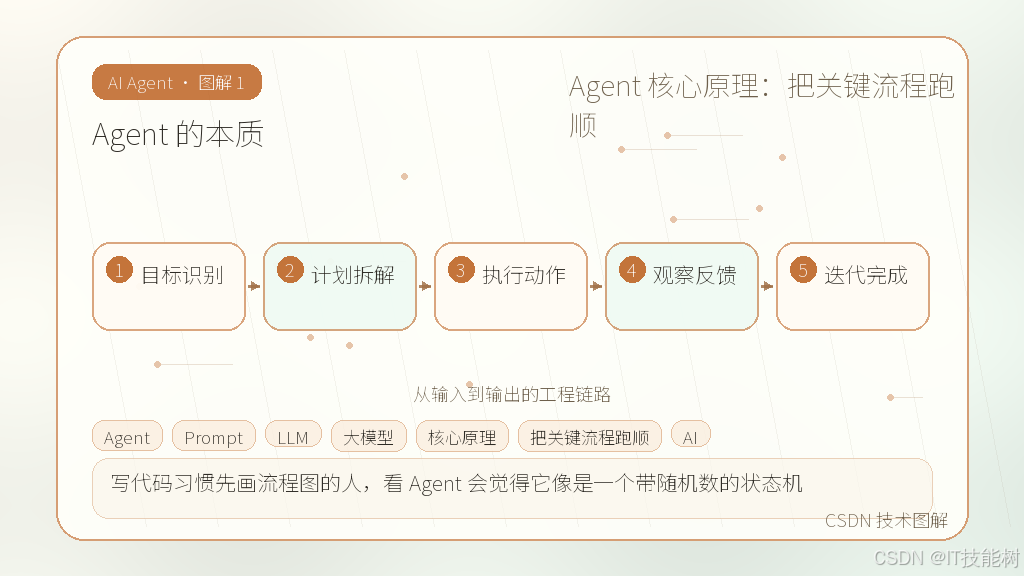
写代码习惯先画流程图的人,看 Agent 会觉得它像是一个带随机数的状态机。LLM 只是里面的决策节点,真正决定成败的是“观察-行动-反馈”这个循环能不能跑通。
去年我们接了一个内部运维工单分类的项目。第一版直接把所有规则塞进 System Prompt,指望模型自己判断。跑了两周,准确率卡在 78%,而且一旦工单描述稍微绕一点,它就会开始编造处理人。后来我们做了个狠切:把 LLM 降级为“意图路由器”,具体匹配交给确定性脚本。这不是反智,而是承认大模型的边界。它擅长模糊语义对齐,不擅长精确逻辑计算。把“理解”和“执行”拆开,才是跑顺流程的第一步。很多团队踩坑,就是因为试图用一套 Prompt 解决所有问题。记住,Agent 不是魔法球,它是工程组件的调度器。
规划能力
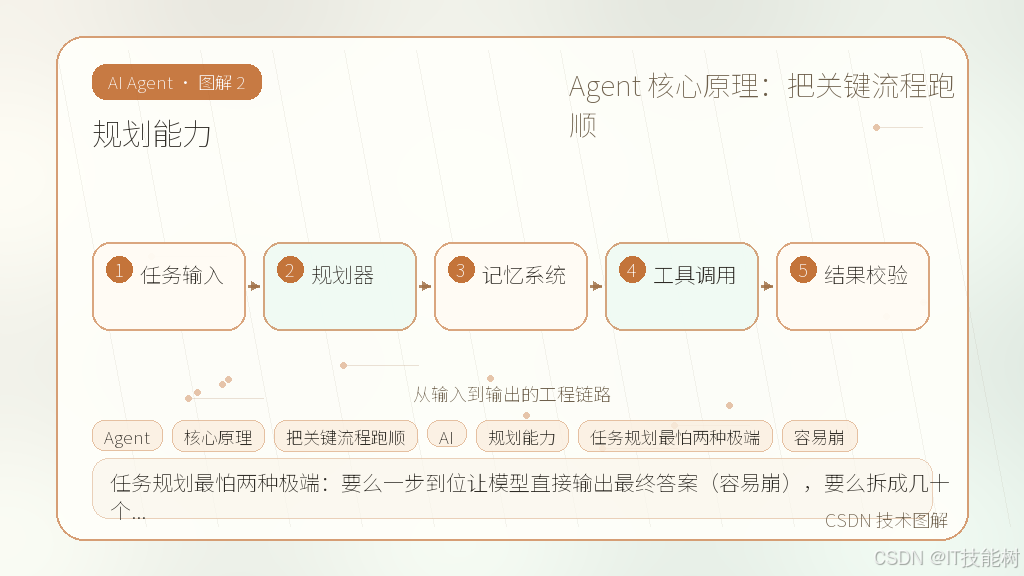
任务规划最怕两种极端:要么一步到位让模型直接输出最终答案(容易崩),要么拆成几十个原子步骤(延迟爆炸)。我们的经验是,中等粒度最稳。
比如一个数据分析请求:“查上月华东区销售额低于 5 万的 SKU,并对比去年同期。”直接扔给模型,它大概率会混淆时间范围或漏掉过滤条件。我们会让它先输出结构化计划,而不是直接调 SQL。
# 基于 LLM 输出解析执行计划(伪代码示意)
plan_steps = [
{"step": 1, "action": "parse_intent", "params": {"region": "east_china", "month": "last_month"}},
{"step": 2, "action": "query_db", "params": {"sql_template": "SELECT sku, sales FROM t_sales WHERE region=? AND month=?", "filter": "sales < 50000"}},
{"step": 3, "action": "compare_data", "params": {"base_period": "same_month_last_year"}}
]这里有个明显的取舍:是用 ReAct 模式边想边做,还是先规划再执行?对于强依赖外部状态的流程(比如读写数据库、调用财务系统),我们倾向 Plan-and-Execute。因为中间状态容易漂移,一次性把依赖关系定死,调试起来才有抓手。如果模型连基础依赖都理不清,说明训练语料里缺乏长程逻辑,硬上只会增加 token 消耗。建议初学者从固定模板的计划生成开始,别一上来就搞动态图结构,先把可预期的步骤固化下来。

工具调用
工具是 Agent 的手脚,但手脚太多反而打架。早期我们接了十几个 API,Prompt 里列了一大堆函数签名,结果模型经常选错参数类型,或者在无关工具之间反复横跳。
工具调用的核心矛盾在于:信息量不够找不到正确工具,信息量太大干扰决策。我们的做法是分层暴露。第一层只给“业务域”提示(比如 `search_knowledge_base`, `submit_ticket`),第二层才在具体触发后注入详细 Schema。同时,严格校验返回值的 JSON Schema,不信任模型的直觉。
实战中一定要加一层“工具路由校验”。你可以用轻量级的规则引擎或正则先过滤一遍意图,再喂给 LLM 选工具。这样即使模型幻觉选了危险操作,前置校验也能拦截。别完全依赖 Function Calling 的内置保护,生产环境里手动加一层网关校验是最稳妥的兜底。简历里如果写“实现了多工具动态调度”,最好能补上一句“通过预过滤+Schema 校验将误调用率压到 2% 以下”,面试官才信。
记忆系统
很多人以为 Agent 记忆就是往向量库里塞文档。其实短期记忆管理比长期检索更折磨人。上下文窗口一满,前面的指令就被挤出去,模型瞬间失忆。
我们踩过最痛的坑是:对话超过 8 轮后,模型开始遗忘初始约束条件。解决方案不是无脑拉长窗口,而是做“记忆衰减与摘要”。每完成一个子任务,就把关键结论抽离出来,存入独立的结构化记录;未决事项保留在滑动窗口顶部。长期记忆则按业务实体打标签,检索时带上时间权重。
别盲目追求高维向量相似度。很多业务场景下,关键词匹配+元数据过滤反而更准。记忆系统的建设顺序应该是:先保证当前会话不断线,再做跨会话持久化,最后才考虑图谱关联。如果你现在的项目还在纠结该用 Milvus 还是 Chroma,不妨先用 SQLite 存历史状态,跑通流程比选型更重要。工具链选型永远排在业务逻辑验证之后。
失败恢复
Agent 跑不通的时候,往往不是因为算法差,而是因为没设计退路。大模型本质是概率输出,你不可能要求它 100% 正确。
我们当时设了三个防线:重试预算、降级策略、人工接管。比如工具调用超时,允许最多 2 次自动重试,参数会自动加上 jitter 防雪崩;如果连续失败,切换到低精度但稳定的备用接口;实在不行,把原始请求和用户 ID 抛回工单系统,转人工处理。监控面板必须暴露 `loop_count`, `tool_error_rate`, `fallback_triggered` 这几个指标,不然排查全靠猜。
写简历时,别光说“搭建了智能客服 Agent”。改成“设计了三级异常恢复机制,将端到端成功率从 65% 提升至 89%,支持 15% 的流量平滑降级至人工坐席”。技术面试问到底层,你能讲清楚为什么需要 budget 控制、怎么设计 fallback 路由,这就过了。Agent 的价值不在于它有多聪明,而在于它出错时有多可控。
总结
回头看,Agent 的开发根本不是拼 Prompt 字数,而是拼系统工程的严谨度。规划要留痕,工具要收敛,记忆要分级,失败要有预案。学习路线上,建议先拿确定性强的单步任务练手,跑通观察-执行循环,再接入多工具,最后叠加记忆模块。别被各种框架的名词绕晕,底层逻辑就那几样。把关键流程跑顺了,模型泛不泛型反而是其次的事。代码可以重构,提示词可以迭代,但架构的容错设计一旦缺失,后期修补的成本远超初期投入。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。


这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)