论文浅尝 | 基于知识图谱的检索增强生成是否真的能检索到你需要的内容?(NeurIPS2025)

笔记整理:王浩,浙江大学硕士,研究方向为大模型智能体、AI for Science
论文链接:https://openreview.net/forum?id=po0eyoYFUa
发表会议:NeurIPS 2025
1. 动机
随着大模型(LLMs)在问答、推理、生成任务中的广泛应用,RAG(Retrieval-Augmented Generation)成为减少幻觉、补充外部知识的重要手段。传统 RAG 多依赖向量数据库,但越来越多的任务需要:
-
结构化关系(如作者–论文–机构)
-
节点文本内容(如论文摘要、商品描述)
-
多跳推理能力
因此,知识图谱(KG)成为更强的外部知识源。然而现有 KG-RAG 方法存在显著不足:
(1). 对复杂查询检索不准确
简单关系查询(如“谁是 Alice 的父亲”)只需结构信息即可解决。 但复杂查询(如“列出某大学发表的与某主题相关的论文”)需要同时理解:作者关系、机构关系、论文文本内容、主题相关性,现有方法难以同时利用结构与文本。
(2). 检索结果缺乏多样性
复杂查询往往需要多个答案,但模型容易只找到单一结果。
(3). PRM(过程奖励模型)成本高
PRM 能提供逐步指导,但需要昂贵的过程级监督数据,在 KG 中几乎无法获得。因此,作者提出 GraphFlow,希望在没有过程监督的情况下,实现高准确性、高多样性、高泛化能力、高效率。
2. 贡献
(1) 提出 GraphFlow 框架,通过联合优化检索策略和流估计器,在无显式过程级奖励的情况下,实现复杂查询的精准多样检索。
(2) 引入局部探索策略与详细平衡目标,减少对低奖励区域的访问,提升训练效率并引导检索策略向高奖励区域探索。
(3) 在 STaRK 基准测试中,GraphFlow 在检索准确率和多样性指标上超越包括 GPT-4o 在内的强基线,且在未见过的知识图谱上展现出优异的跨域泛化能力。
3. 方法
总体框架如图 1 所示,GraphFlow 通过流估计器
将轨迹结果奖励
分解为中间状态流值
,引导检索策略学习;(b) 基于 LLM 的 GraphFlow 实现,适配富含文本的知识图谱检索场景。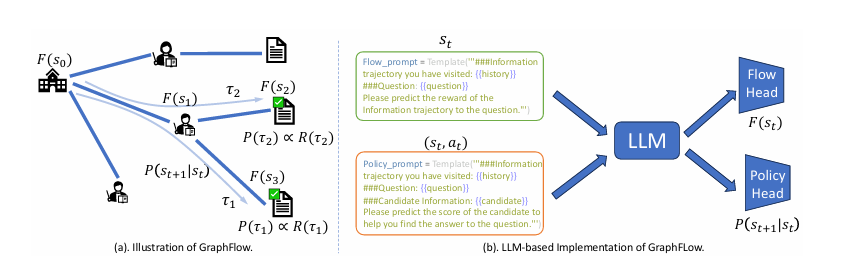
图1 总体框架图
3.1 问题建模
知识图谱定义为G=V,E,D,其中V为实体节点集,E为关系边集,D为节点关联的文本文档集。检索目标是从G中获取K个目标节点及对应文档,以支撑复杂查询的回答。
3.2 多步决策过程设计
-
状态:初始状态 , 为查询, 为初始节点关联文档;第t步状态, 包含累计文档集。
-
动作:从当前节点 移动到相邻节点 ,并获取对应文档。
-
转移:状态随动作更新为 ,直至文档满足查询需求或达到最大步数。
-
奖励:轨迹终止时,根据终端节点文档是否支持查询分配结果奖励 。
3.3 核心组件
-
流估计器:为每个中间状态分配非负流值 ,将最终结果奖励分解到中间步骤,提供隐式过程级监督。
-
检索策略:通过详细平衡目标联合训练,使轨迹生成概率与奖励成比例,即
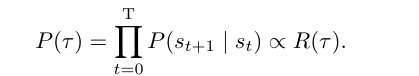
其中, 为检索轨迹, 为状态转移概率, 为轨迹结果奖励。
-
局部探索:对每个非终端状态生成k个探索动作,聚焦高价值区域优化,提升训练效率。
3.4 损失函数与训练配置
采用详细平衡与局部探索(DBLE)目标函数:
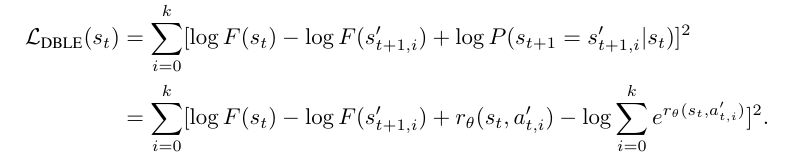
边界条件设为 ,通过 LoRA 适配器优化 LLM backbone,联合训练流头和策略头。
4. 实验
4.1 数据集
采用 STaRK 基准测试,涵盖三个富含文本的知识图谱领域:
-
STaRK-AMAZON:电商领域,含产品信息与共购关系,用于推荐查询检索。
-
STaRK-MAG:学术领域,含作者、机构、出版物信息,用于论文检索等学术查询。
-
STaRK-PRIME:生物医学领域,含药物、疾病、基因等实体及关系,用于生物医学查询。
4.2 实验任务与基线
-
任务:评估复杂查询下的检索准确率(Hit@1、Hit@5、MRR)和多样性(R@20、D-R@20)。
-
基线:检索式方法(DenseRetriever、G-Retriever、SubgraphRAG)、智能体方法(ToG+LLaMA3、ToG+GPT4o、SFT、PRM)。
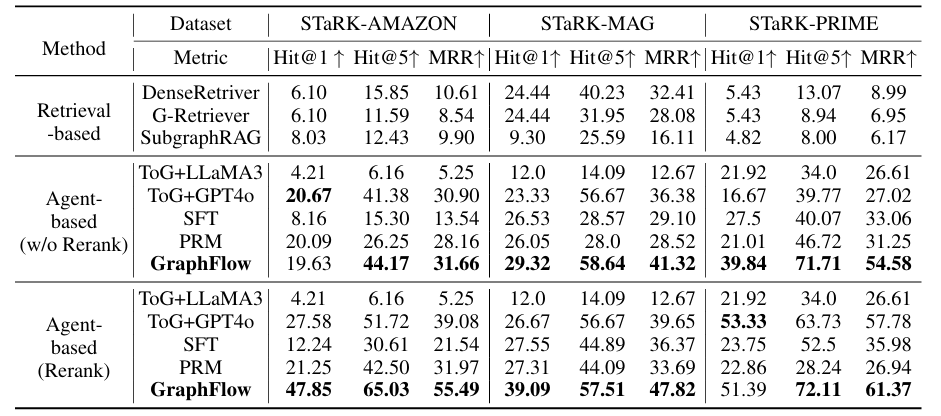
表1 实验结果-检索准确性表现
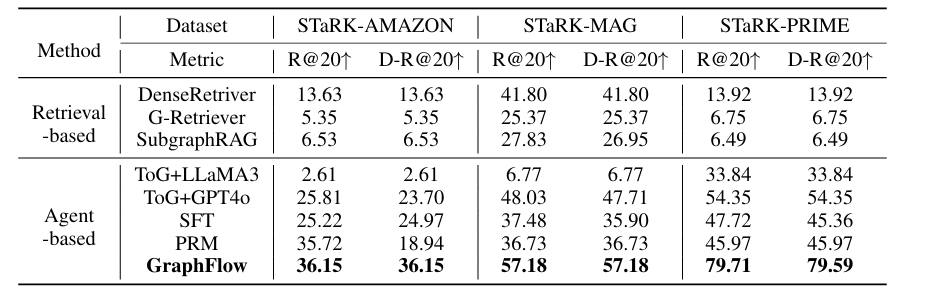
表2 实验结果-检索多样性表现
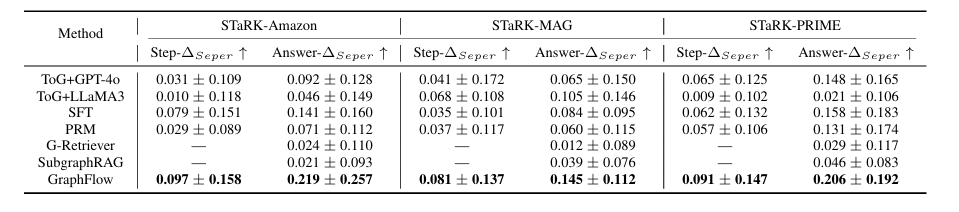
表3 实验结果-定量检索质量
4.3 实验结果
-
准确率:GraphFlow 在所有数据集上显著优于基线,与 ToG+GPT4o 相比平均提升 10%,STaRK-PRIME 的 Hit@1 达 39.84%、MRR 达 54.58%。
-
多样性:GraphFlow 的 R@20 和 D-R@20 指标均为最优,STaRK-PRIME 的 D-R@20 达 79.59%,避免冗余且覆盖更多目标。
-
泛化能力:在跨域检索任务中表现突出,尤其在重排序设置下,Hit@5 指标显著超越其他方法。
5. 总结
本文提出 GraphFlow 框架,通过流估计器分解奖励信号和局部探索策略,解决了知识图谱驱动 RAG 在复杂查询下的精准性和多样性难题。实验表明,该框架无需显式过程级监督,即可在 STaRK 基准上超越强基线,且具备优异的跨域泛化能力。未来可结合因果推理进一步提升 LLM 的推理能力,探索更多科学领域的应用场景。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)