CVPR & ICCV|医工交叉文章速览
下面是从CVPR与ICCV中挑选的另外五篇与医学相关的文章(之前已经分享过十篇,可以在主页中查看),每篇文章的分享大致分为核心梗概、提出方法、验证结果三个部分。

第一篇 |BoMD: Bag of Multi-label Descriptors for Noisy Chest X-ray Classification
项目地址:https://github.com/cyh-0/BoMD
核心梗概
本文聚焦胸部 X 光(CXR)多标签分类任务,针对该领域 “标签噪声普遍(多来自 NLP 提取,易含错误)”“现有噪声标签方法适配性差(多为多类别设计,无法处理多标签样本的多标签错误)”“缺乏系统的多标签噪声评估基准” 的问题,开展以下工作:
提出方法
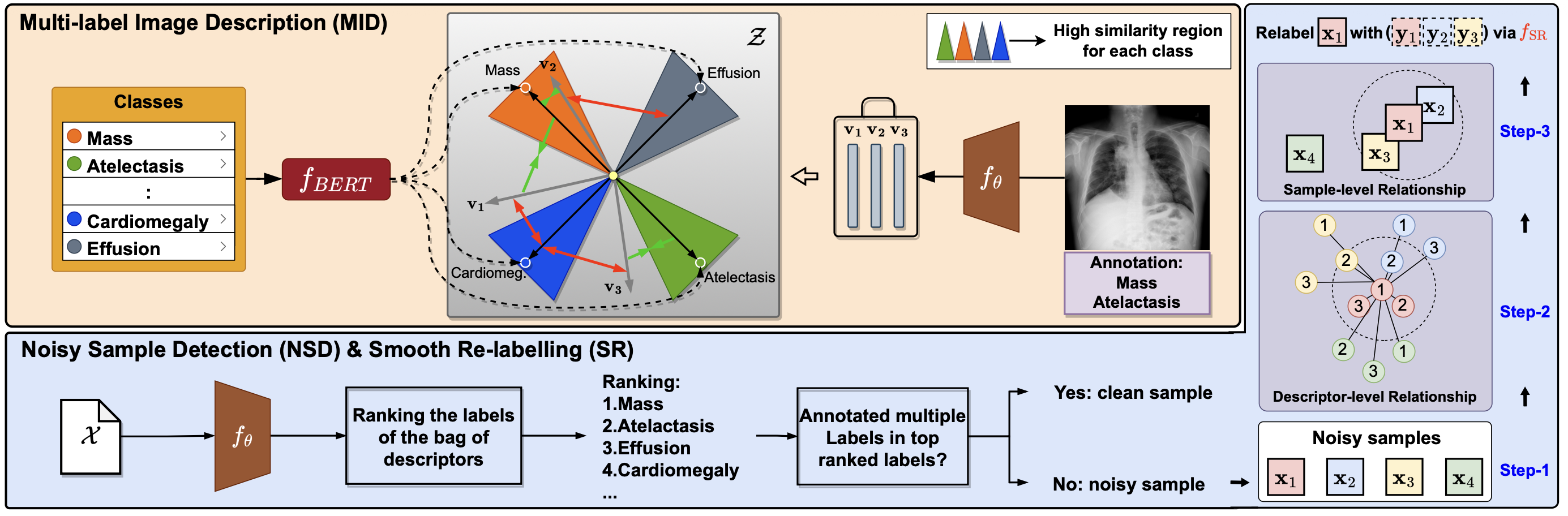
提出 BoMD(多标签描述符袋)框架,核心含两阶段三关键模块:
-
多标签图像描述(MID)模块:
- 借鉴 “词袋(BoW)” 思想,为每张 CXR 生成一组(默认 M=3)全局视觉描述符,使描述符与医学语言模型的语义嵌入对齐;
- 用 BlueBERT(预训练于 PubMed 和临床笔记)生成疾病标签的语义嵌入(如 “肺炎” 对应临床语义向量),通过排序损失训练视觉描述符:让正标签语义嵌入与描述符的相似度高于负标签,同时用正则项降低描述符间冗余;
- 作用:将图像映射到临床语义空间,为噪声检测和图构建提供细粒度特征。
-
噪声样本检测与图平滑重标注模块:
- 噪声检测:根据 MID 描述符与语义嵌入的相似度对标签排序,若原标注的正标签排序低于负标签,则判定为噪声样本;
- 图构建:以每张图的 M 个描述符为节点,节点间权重为描述符欧氏距离的倒数,构建全局图;
- 平滑重标注:对噪声样本,取其 K(默认 10)个最近邻样本的标签均值,结合原标签和均匀分布(避免过度自信),通过掩码(过滤高置信负标签)生成新标签。
-
最终多标签分类器模块: 用重标注后的干净数据集训练基于 DenseNet121 的多标签分类器,损失函数为二元交叉熵(BCE),实现疾病类别预测。
验证效果
-
真实数据集验证: 在 “NIH/CXP(噪声训练集)→OpenI/PadChest/NIH-Google(干净测试集)” 任务中,BoMD 的 AUC 均优于 NVUM、ELR 等 SOTA 方法;
-
系统基准验证: 提出新基准 NIHxPDC(NIH+PadChest 干净样本,控制噪声样本比例和标签翻转概率,在多数噪声场景,BoMD 较 NVUM、BCE 基线 AUC 提升 3%-5%,仅极端噪声下略逊;
-
消融与噪声检测: 验证 BlueBERT 等医学语言模型较随机初始化 / 通用语言模型提升 AUC 1.5%-2.5%;MID 描述符较 NVUM 单描述符提升 AUC 2%-3%;噪声样本检测的精度 / 召回均优于 DivideMix 的 “小损失” 方法,且重标注后标签分布更接近干净集。
第二篇|Anatomical Invariance Modeling and Semantic Alignment for Self-supervised Learning in 3D Medical Image Analysis
项目地址:https://github.com/alibaba-damo-academy/alice
核心梗概
本文聚焦3D 医学图像自监督学习(SSL)任务,针对现有方法沿用自然图像 SSL 范式、未充分利用跨图像固有相似解剖结构(易导致空间错位 / 语义差异特征被强制相似),且掩码视图与完整视图存在语义鸿沟(大掩码比例下语义差异显著,直接强制相似会损害表征质量)的问题,开展以下工作:
提出方法
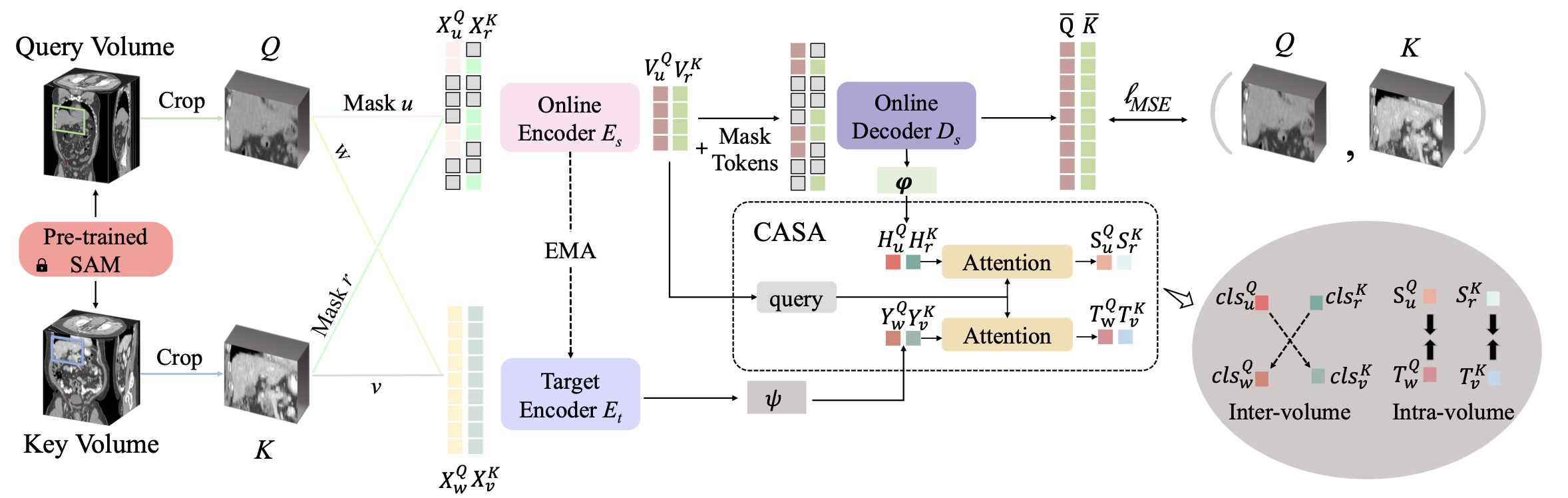
提出Alice(Anatomical Invariance Modeling and Semantic Alignment)两阶段 SSL 框架,核心含 “视图挖掘 - 网络组件 - 关键优化目标” 三大模块:
-
语义一致视图挖掘: 基于预训练 SAM(解剖嵌入自监督模型)定位不同 3D CT volume 的相同身体部位,生成Q和 K;对 Q/K 分别施加随机掩码(用于在线编码器)和强数据增强(用于目标编码器),得到 4 个语义关联视图,避免传统随机裁剪的语义错位。
-
核心网络组件:
- 在线编码器:输入掩码视图,仅处理未掩码 patch,输出可见特征,下游任务仅保留此编码器;
- 在线解码器:接收可见特征与掩码 token,重构掩码 patch 像素,用 MSE 损失学习局部解剖细节;
- 目标编码器:与在线编码器结构一致,通过 EMA 更新参数,输入未掩码增强视图,输出语义完整特征。
-
关键优化目标:
- 解剖不变性建模:通过投影头将在线解码器 / 目标编码器特征映射为对比对,用余弦相似损失最大化跨 volume 相同解剖结构的特征相似性,学习类特异性解剖不变性;
- 条件解剖语义对齐(CASA):以在线编码器特征为查询,通过缩放点积注意力匹配在线解码器 / 目标编码器特征中的高相关语义,生成对齐的师生特征对,用余弦相似损失优化 intra-volume 语义一致性,避免掩码与完整视图的语义错位。
验证效果
-
3D 器官分割任务: 在 FLARE 2022(13 个腹部器官)和 BTCV(13 个腹部器官)数据集上,以 UNETR、Swin UNETR、nnFormer 为 backbone,Alice 均刷新 SOTA——FLARE 2022 离线测试集 DSC 达 86.87%(超第二名 CMAE 2.22%),BTCV 在线测试集 DSC 达 88.58%(超 UniMiSS 1.53%),且仅用 40% 预训练数据(2000 个 CT)即优于用 5000+CT 预训练的方法;
-
COVID-19 分类任务: 在 MosMedData 胸部 CT 数据集上,Alice 的 AUC 达 90.88%,较 CNN-based SOTA(PCRLv2,88.36%)提升 2.52%,较 ViT-based SOTA(IBOT,87.55%)提升 3.33%,验证跨场景泛化能力。
第三篇|Dynamic Graph Enhanced Contrastive Learning for Chest X-ray Report Generation
项目地址:https://github.com/mlii0117/DCL
核心梗概
本文聚焦胸部 X 光报告生成(CRG)任务,针对该领域现有方法依赖固定医学知识图谱(覆盖不全、无法适配具体病例,如 “积液提示水肿” 的临床关联未建模)、数据存在严重视觉 - 文本偏差(图像相似性高但异常区域小且无标注,正常描述重复导致关键异常缺失),且对比学习未与动态知识融合的问题,开展以下工作:
提出方法
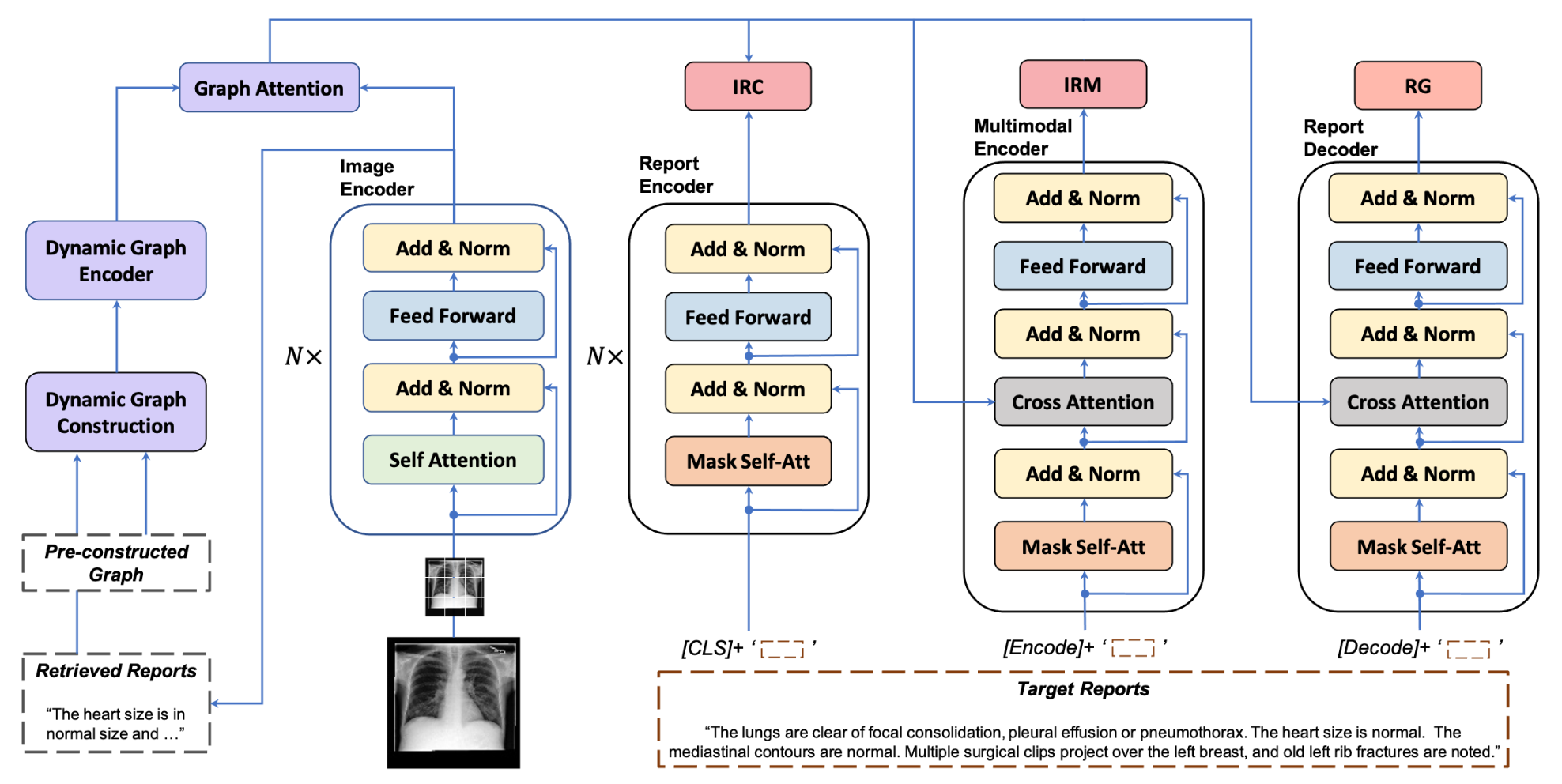
提出 DCL(Dynamic Graph Enhanced Contrastive Learning)框架,核心含 “动态图模块” 与 “对比学习模块” 两大组件,结合基础编码器 - 解码器实现高质量报告生成。
-
动态图模块(解决固定图谱局限): 以 “自下而上” 方式融合通用与特定知识,含三部分:
- 动态图构建:先基于预构建图谱(28 个实体:1 个全局节点、7 个器官 / 组织、20 个病症关键词)搭建基础结构;再通过视觉特征检索训练集中 Top-3 语义相似报告,用 RadGraph 提取特定知识三元组(<主体实体,关系,客体实体>,如 < 胸骨切开术,提示,冠状动脉搭桥术 >),动态添加新节点或修正实体关系(如 “位于” 关系的客体实体归为器官节点);
- 动态图编码器(DGE):基于 Transformer 设计关系自注意力(RSA),以图谱邻接矩阵为掩码,确保节点仅与关联实体交互;节点特征用预训练 SciBert 初始化(多词实体取平均),并添加层级编码(区分全局 / 器官 / 病症节点),实现知识传播与节点特征优化;
- 图注意力(GA):通过跨注意力融合视觉特征与图特征 ——Query 来自图像编码器输出,Key/Value 来自优化后的图特征,最终得到动态知识增强的视觉特征,突出临床关键信息;
-
对比学习模块(解决数据偏差与表征质量): 含两种损失函数,提升视觉 - 文本表征一致性并保障报告检索准确性:
- 图像 - 报告对比损失(IRC):用 ViT(图像编码器)与 SciBert(报告编码器)提取单模态表征,维护队列存储最近 M 组图像 - 报告表示;通过余弦相似度计算正负对相似性,用交叉熵损失鼓励正样本(匹配的图像 - 报告)表征相近、负样本(不匹配对)表征疏远;
- 图像 - 报告匹配损失(IRM):用多模态编码器(含跨注意力)提取图像 - 报告联合表征,通过线性层预测 “匹配 / 不匹配” 二分类概率,用交叉熵损失强化跨模态一致性(多模态编码器仅训练用,推理阶段不参与)。
-
基础生成模块: 图像编码器采用预训练 ViT(输入切分为 196 个 patch+[CLS] token),报告解码器为两层 Transformer(含掩码自注意力与跨注意力),以交叉熵损失实现自回归报告生成;
验证效果
-
描述准确性(NLG 指标): 在 IU-Xray 和 MIMIC-CXR 两大基准数据集上均刷新 SOTA:
- IU-Xray:CIDEr 达 0.586(超此前 SOTA 方法 MGSK 的 0.382),ROUGE-L 0.383(与 MGSK 持平),BLEU-4 0.163(保持竞争力);
- MIMIC-CXR:CIDEr 达 0.281(超 MGSK 的 0.203),METEOR 0.150(超 R2Gen 的 0.142),证明模型可生成更精准的临床主题词,而非重复高频句子;
-
临床有效性(CE 指标): 在 MIMIC-CXR 上,14 类病症预测的 F1-score 达 0.373(超 MGSK 的 0.371),部分关键病症(如胸腔积液、胸膜异常)的 ROC-AUC 达 0.82,生成报告的临床术语准确性显著提升。
第四篇|Towards Trustable Skin Cancer Diagnosis via Rewriting Model’s Decision
核心梗概
本文聚焦皮肤癌诊断领域,针对深度神经网络(DNN)常依赖数据集混淆因素(如暗角、尺子、毛发等无关痕迹或肤色偏差)决策,导致模型不可信、实际部署风险高,且缺乏可控数据集评估混淆行为的问题,提出人机协同框架实现混淆因素发现与去除,构建专属数据集 ConfDerm,最终提升模型诊断准确性与可信度。
提出方法
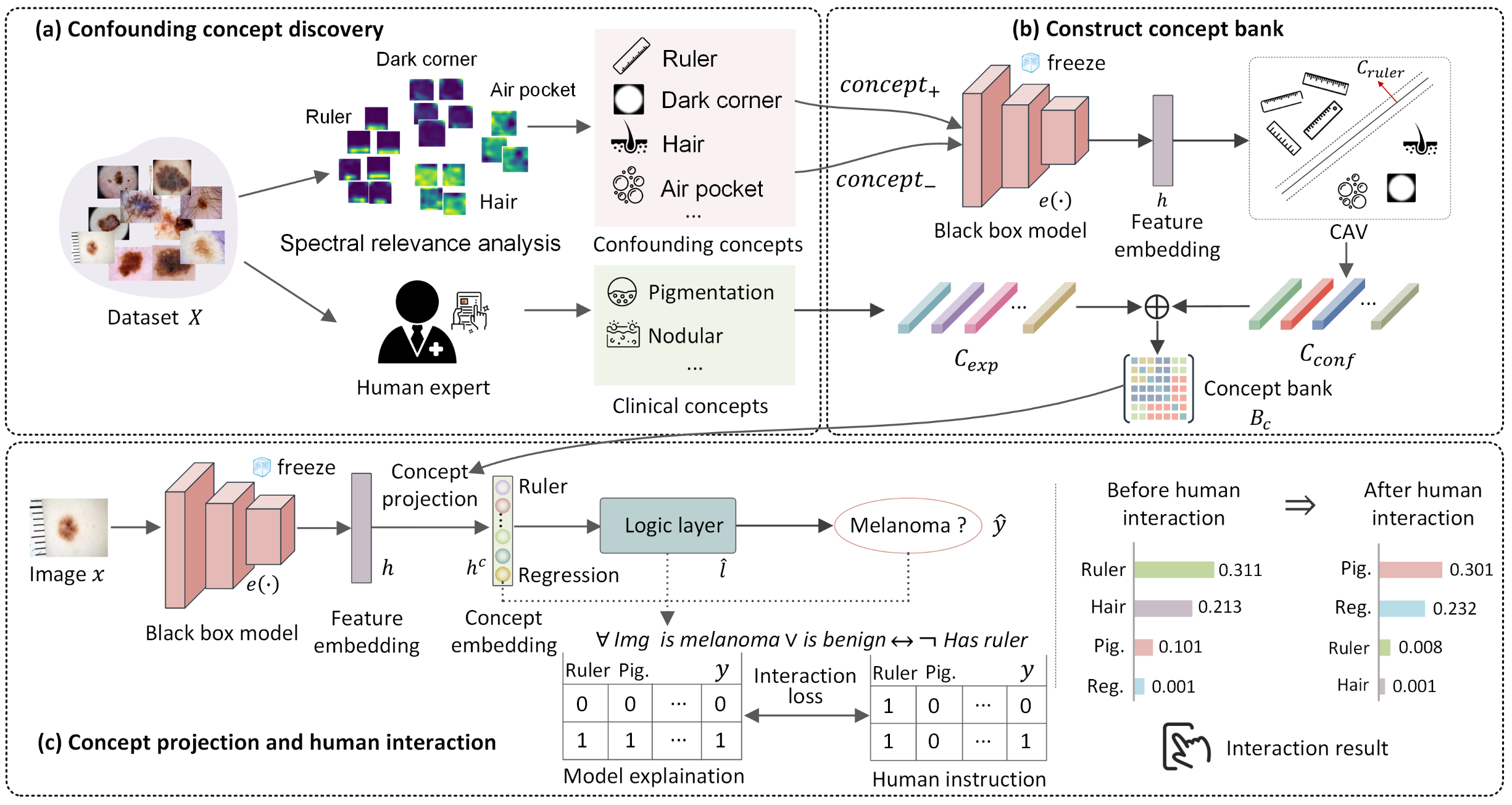
-
全局混淆概念发现(GCCD): 基于谱相关性分析(SpRAy)改进,通过 GradCAM 生成热力图,结合离散傅里叶变换、图像 - 热力图拼接,经谱聚类与 t-SNE 降维,实现无先验知识下混淆概念的半自动发现。
-
概念库构建: 基于概念激活向量(CAVs),混淆概念来自 GCCD 聚类(人类确认),临床概念来自专家标注数据集,两类概念组合成可解释概念库。
-
模型逻辑重写: 将黑箱模型特征投影到概念空间得概念得分,用熵基逻辑层替换原分类层,引入带弹性网正则的 “正确原因损失(RRR Loss)”,通过人类一阶逻辑指令修正模型决策。
-
ConfDerm 数据集: 基于 ISIC2019/2020 构建,含 3576 张图像(黑色素瘤 / 良性平衡),5 个子数据集对应不同混淆场景,用于定量评估。
验证效果
-
混淆发现有效: 在 ISIC2019-2020 发现 ResNet50 依赖暗角等诊断;在 SynthDerm 发现 VGG16 依赖手术标记,精准定位混淆行为。
-
决策重写提升性能: ConfDerm 中,“黑色素瘤 - 暗角” 子集中黑色素瘤类准确率从 23.48%(CNN)升至 84.95%(XIL),全类准确率从 60.86% 升至 83.16%,模型转向关注临床特征。
-
肤色去偏有效: DDI 数据集上,深色皮肤(FST (V-VI))ROC-AUC 从 57.93%(CNN)升至 60.03%(XIL),提升模型鲁棒性。
-
消融实验结论: 75 个概念样本性能饱和,λ2=1000 时人类指令权重足够,逻辑层 + RRR 损失组合最优。
第五篇|MRM: Masked Relation Modeling for Medical Image Pre-Training with Genetics
项目地址:https://github.com/CityU-AIM-Group/MRM
核心梗概
本文聚焦医学图像自监督预训练任务,针对现有掩码图像建模(MIM)方法面向自然图像、忽略医学数据特性(语义区域少:疾病区域微小易被掩码;语义关系有限:同器官数据解剖模式冗余,疾病关联信息不足),导致下游医疗诊断泛化性能差的问题,结合遗传学数据开展以下工作。
提出方法
提出 MRM(Masked Relation Modeling)框架,核心含两大关键设计。
-
关系掩码(Relation Masking): 不直接掩码输入数据,而是在自模态(计算单模态内 token 特征关系,掩码高强度关联)和跨模态(计算图像 - 遗传学 token 特征关系,掩码强语义对应)层面掩码 token 级特征关系,保留完整疾病语义;
-
关系匹配(Relation Matching): 在自模态(对齐完整与掩码特征的样本级相似度)和跨模态(对齐完整与掩码的图像 - 遗传学样本级关系)层面,通过全局约束利用样本间关系,补充语义关联,与重建损失互补优化。
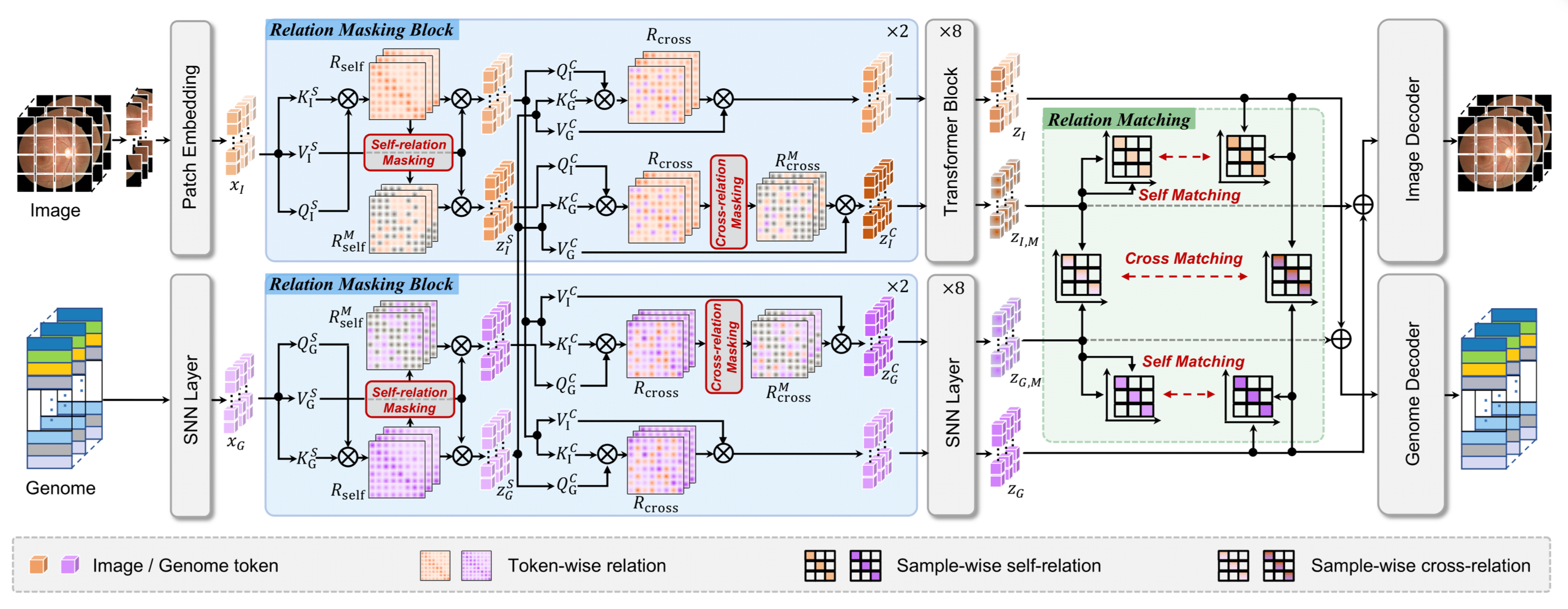
验证效果
在 UKB(视网膜图像 + 遗传学)、TCGA-GBM/LGG(病理图像 + 遗传学)数据集上验证。
-
下游任务表现: 视网膜下游(APTOS 糖尿病视网膜病变检测、RFMiD 多疾病分类等)及病理下游(胶质瘤分级)任务中,MRM 均优于现有对比学习(如 SimCLR)、MIM 方法(如 MAE、AttMask),如 APTOS 的 QwKappa 达 89.83%、胶质瘤分级 Acc 达 76.17%;
-
组件有效性: 消融实验证明自 / 跨模态关系掩码、自 / 跨模态关系匹配均能提升性能;
-
扩展性: 单模态(仅图像)预训练时,MRM 仍在视网膜下游任务中表现最优,验证方法灵活性。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)