【全网最详细】保姆级教程:LLaMaFactory训练踩过的坑
一、设备详情
上次由于个人电脑配置原因,未能成功执行LLaMaFactory微调模型。为了能够顺利微调模型,发动微弱的人脉,整了台笔记本,参数和配置如下:
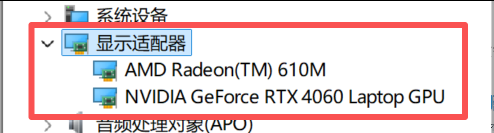
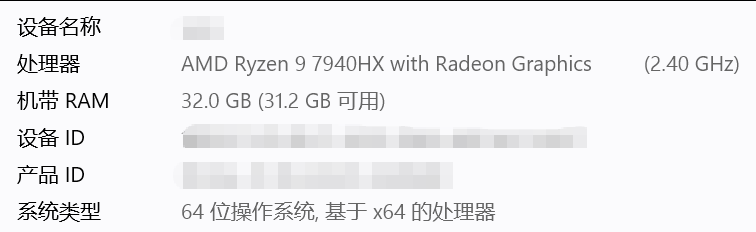
二、安装
LLaMaFactory安装详情见:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/installation.html
访问 https://developer.nvidia.com/cuda-gpus 下载对应的CUDA
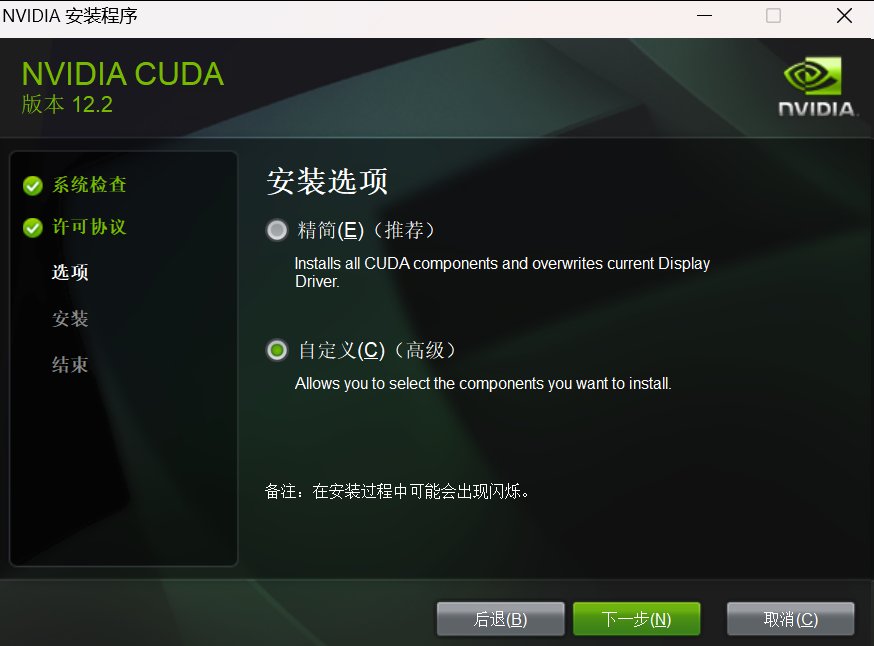
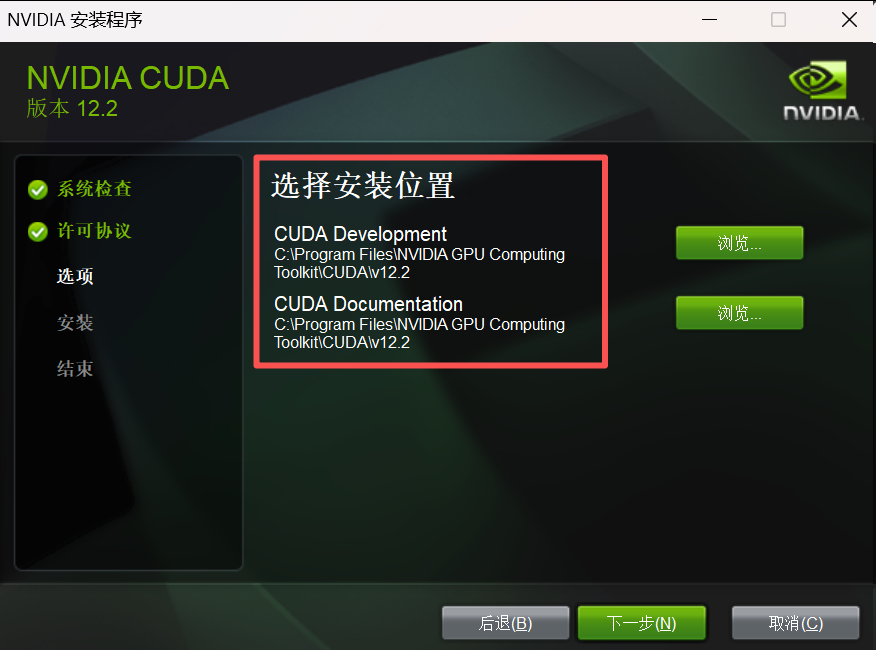
安装程序时,选择【自定义】,建议将安装位置改成【非系统盘】,因为执行大模型训练时,当GPU显存不够用时,计算机会尝试使用系统内存来分担压力。
而当系统内存也不够用时,Windows会启动虚拟内存的机制,强制将一部分硬盘空间(通常是系统盘C盘)当做“慢速内存”来使用。
如果C盘空间不足会导致 【RuntimeError: CUDA error: out of memory】,所以此处尽可能的给C盘留足够的空间。
最后执行 nvcc -V 看到如下结果表示安装成功;
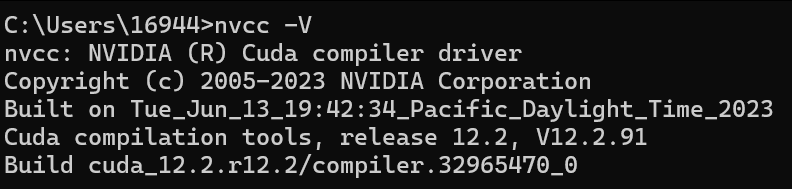
接着开始启动LLaMaFactory,步骤如下:
使用git下载项目:git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
pip install -r requirements/metrics.txt
最后通过使用 llamafactory-cli version 校验安装成功;
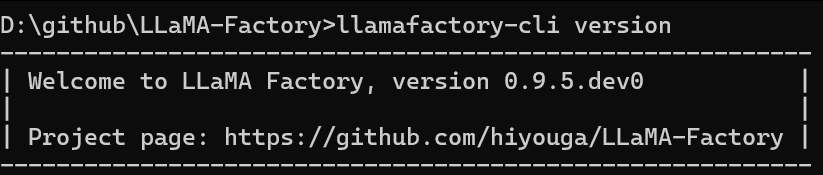
三、启动
LLaMa Factory 支持通过WebUI微调大语言模型,使用指令:llamafactory-cli webui
访问:http://localhost:7860/ 可以进入页面;
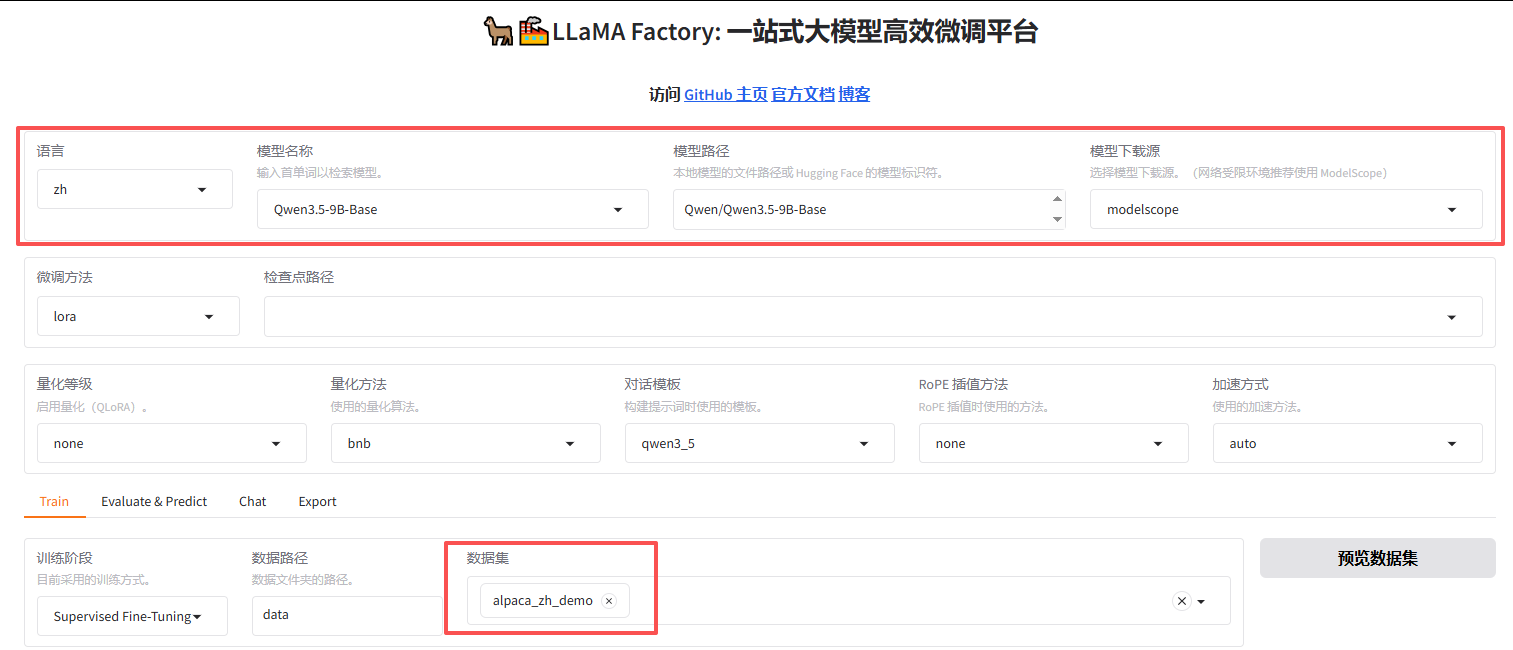
这里选择魔搭社区的Qwen3.5-9B-Base;【数据集】先随便选一个,其他参数默认;
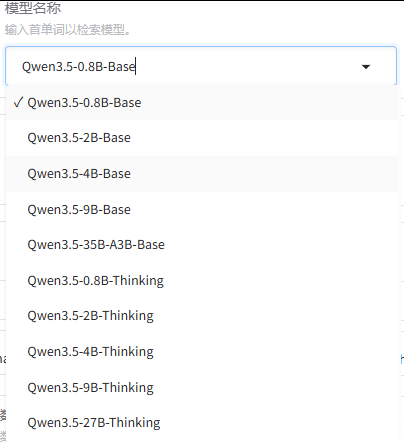
其中3.5=版本号;B表示Billion十亿,指模型的参数量,参数量越大,模型越聪明,同样也越消耗计算资源;
35B-A3B 表示混合专家模型结构:35B总参数,激活参数量为3B(每次只用其中3B部分);
Base = 基础版本,适合继续微调或用于通用生成任务;Thinking = 针对推理、逻辑、数学等任务优化的版本;
四、常见问题
4.1. 点击【开始】执行,结果和我们预想的不一样,还是弹出提示【未检测到CUDA环境】;
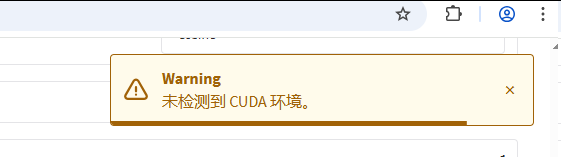
核心原因通常是软件环境(PyTorch、CUDA工具包)没有正确配置以调用硬件(NVDIA显卡);此时需要验证Python环境中PyTorch是否正确连接到CUDA,执行如下命令:
python
import torch
print(torch.__version__) # 查看 PyTorch 版本
print(torch.cuda.is_available()) # 检查GPU是否可用
print(torch.cuda.device_count()) # 检查GPU数量
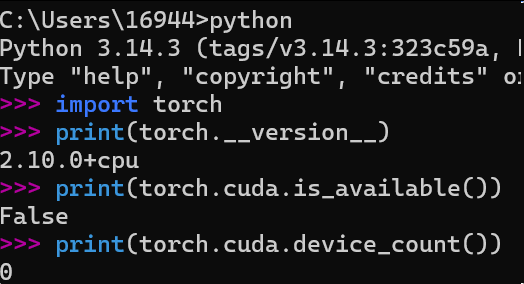
这里可以看出这台电脑的Python版本是【3.14.3】,安装的PyTorch是CPU版本(2.10.0+cpu);
4.1.1. 首先,卸载当前的CPU版本:pip uninstall torch torchvision torchaudio -y
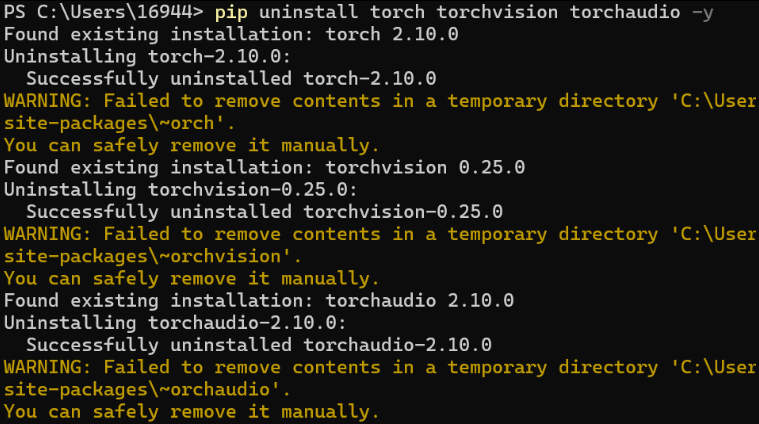
4.1.2. 接着,安装正确的GPU版本,可以使用pip安装,pip命令行如下,分别是官方索引源和国内镜像源,但我个人建议使用Conda;
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pip install torch torchvision torchaudio -f https://mirrors.aliyun.com/pytorch-wheels/cu124/
Conda是一个强大的环境管理工具,对PyTorch提供支持。安装 MiniConda 下载地址见:https://repo.anaconda.com/miniconda/
4.1.2.1. 安装Miniconda
Miniconda 是一个轻量级的 Python 环境管理工具,可以简单理解为:Python 的"虚拟机"管理器。仅包含核心功能,可创建多个独立环境;
安装路径记得选【非系统盘】,同样是为了给C盘留足够的空间,防止【RuntimeError: CUDA error: out of memory】;
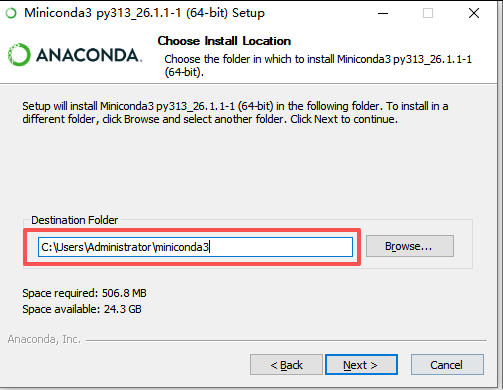
安装时勾选【Add installation to my_PATH environment variable】,目的是让系统能够在命令行窗口中直接识别并使用 conda、python等命令;
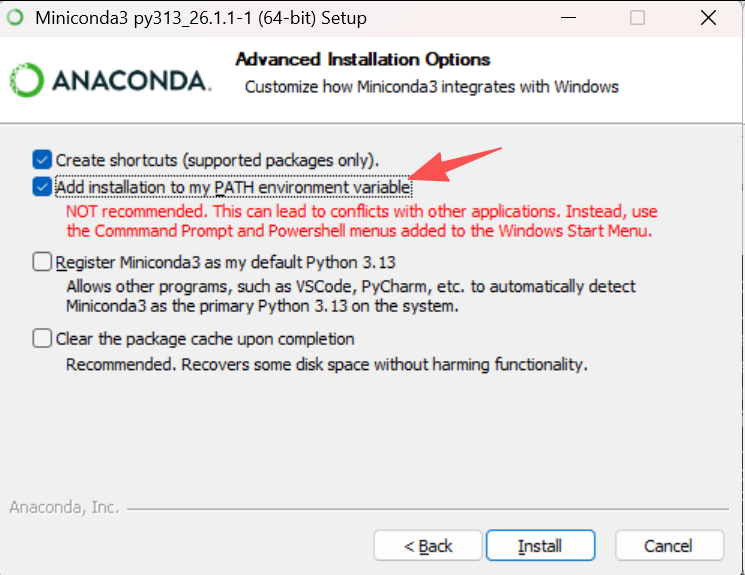
4.1.2.2. 调整python版本
这里建议将Python降至【3.12版本】,否则会出现PyTorch没有为Python【3.13和3.14】提供CUDA版本的预编译包的错误;或者可以使用虚拟环境的安装Python 3.12;
①、创建虚拟环境
创建python 3.12环境用于PyTorch(其中【pytorch-env】是环境名,可自定义):conda create -n pytorch-env python=3.12
切换至PyTorch环境: conda activate pytorch-env
退出当前环境:conda deactivate
删除旧的虚拟环境:conda remove --name pytorch-env --all
②、使用conda直接安装python3.12:conda install python=3.12
在python3.12环境下安装PyTorch:conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
安装成功后执行python能够打印出如下信息:
>>>import torch
>>>print(torch.__version__)
2.5.1
>>>print(torch.cuda.is_available())
True
>>>print(torch.cuda.device_count())
1
4.1.2.3. 环境已准备完毕,回到刚才LLaMaFactory微调平台;
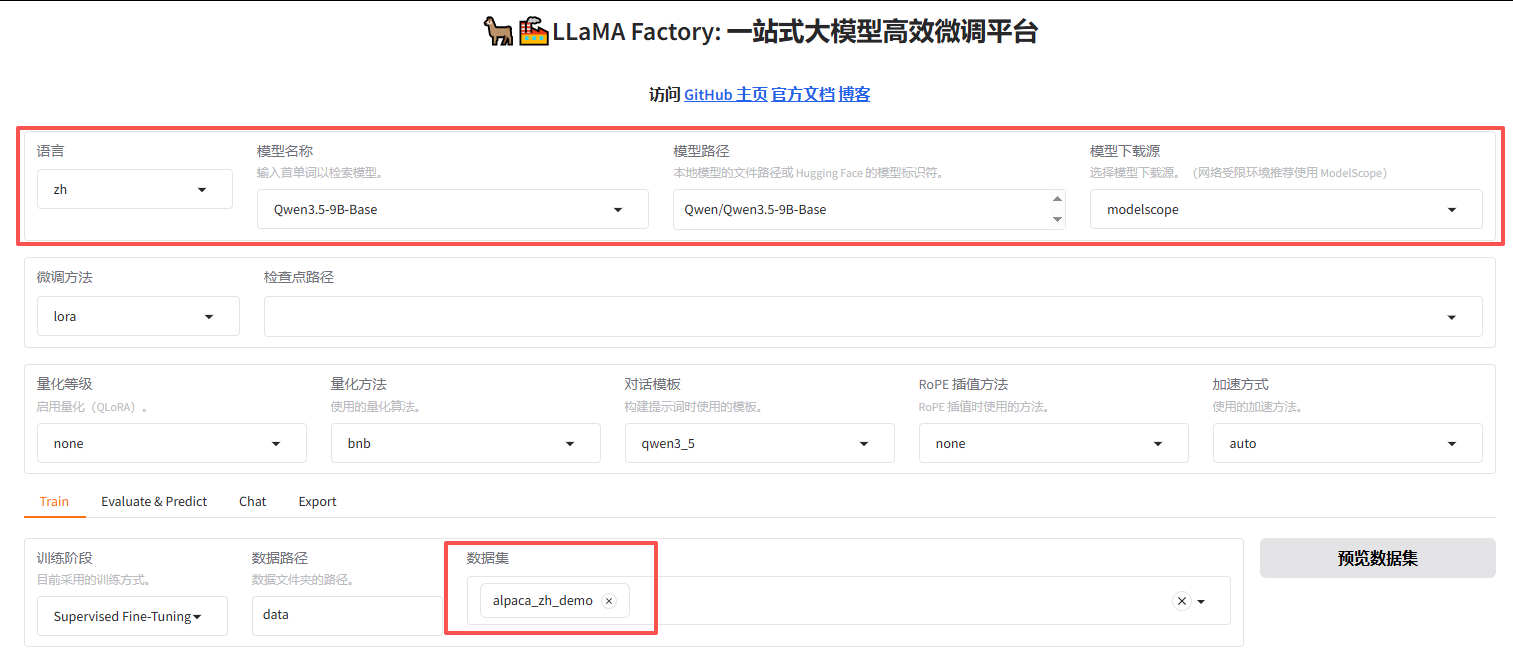
执行【开始】后会自动下载模型,默认存储路径在【C:\Users\Administrator\.cache\modelscope\hub\models\Qwen】,如果C盘空间不足,可将整个文件夹移动至其他盘;
如果是选择本地模型的文件,如下配置,注意本地路径最后要带上反斜杠【\】;(此处使用Qwen3.5-9B-Base举例)

4.2. 资源不足问题
4.2.1.平台页面控制台输出 Windows 系统的内存不足错误(os error 1455),系统的“页面文件”(虚拟内存)太小,无法完成当前操作。
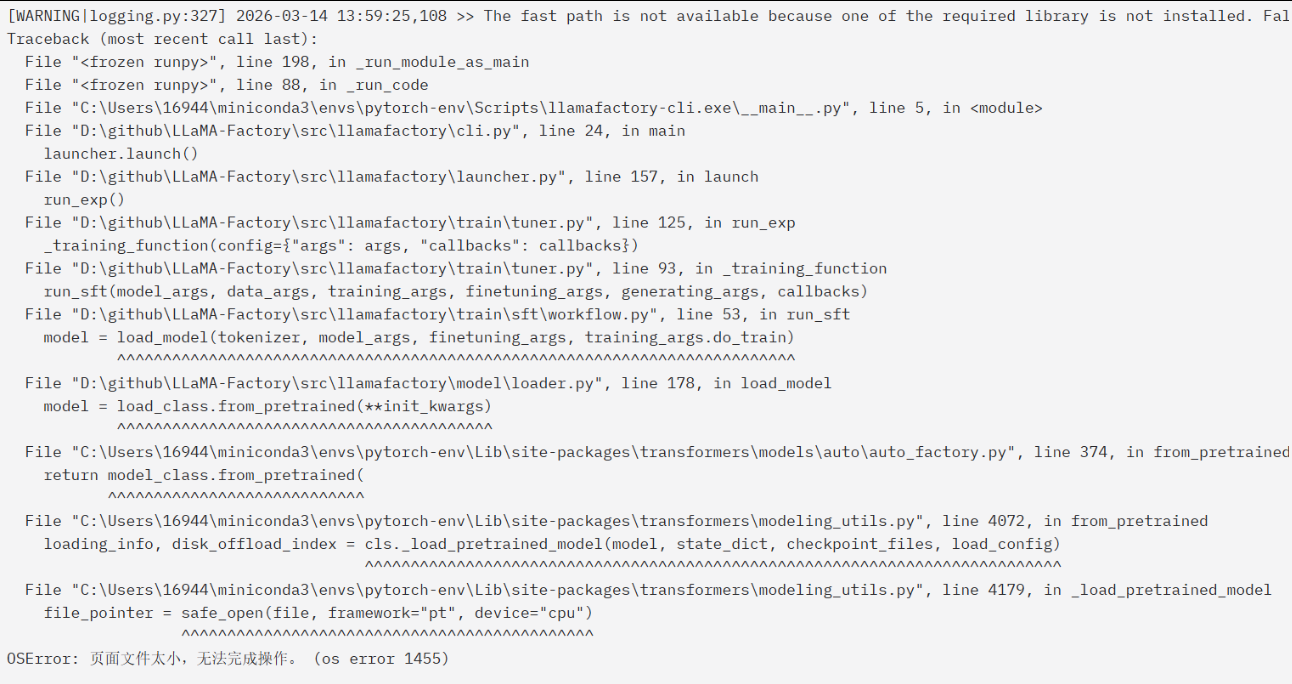
命令行窗口会输出:
RuntimeError: CUDA error: out of memory
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
解决方案:
①、很简单,加钱,上更好的显卡(手动狗头);
②、释放C盘的空间,将大型数据、输出日志和模型存储的路径改为【非系统盘】;
③、降低模型参数量,例如将9B降为4B;
我这里将【方法2和3】一起实行,亲测有效。
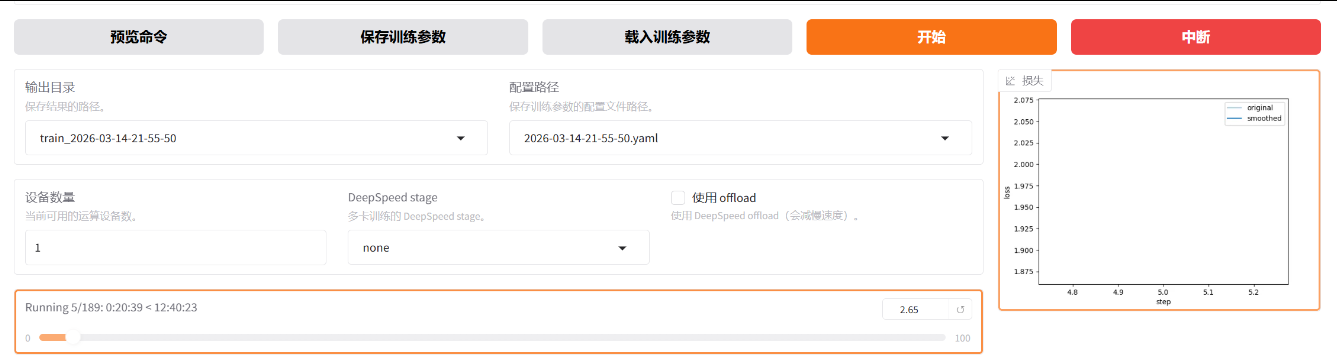
上图解析:
5/189:当前正在处理的批次/总批次数(第5批,共189批);
0:20:39:已经运行了20分钟39秒;
< 12:40:23:预计还需要12小时40分钟23秒才能完成;
五、总结
通过上述步骤,我们终于成功执行LLaMaFactory微调模型,虽然训练过程可能需要较长时间,但是相信大家的电脑一定比我这台更好(手动狗头)。希望本文能帮助大家顺利解决大模型微调遇到的坑,接下来会继续分享平台中相关参数的选择和使用。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)