Triton&九齿系列(六)《DLCompiler 的高性能算子开发实践》
·
目录
Qwen3 Next-AttentionProlog 的高性能实现
• 通过上述优化,千问3 Next Attention Prolog 在 8 K输入场景下,相比不融合方案,速度提升约 1.8 倍。
DeepSeek V3 attention prolog的高性能实现
DeepSeek V3 Attention Prolog 计算流程
本文讲解包括大 kernel 写法、GroupMatmul 优化、千问3 Next Attention Prolog 优化以及DeepSeek V3 Attention Prolog 优化。
基于绑核优化实现 MegaKernel 总体思路

GroupMatmul的高性能实现
1. GroupMatmul的计算流程
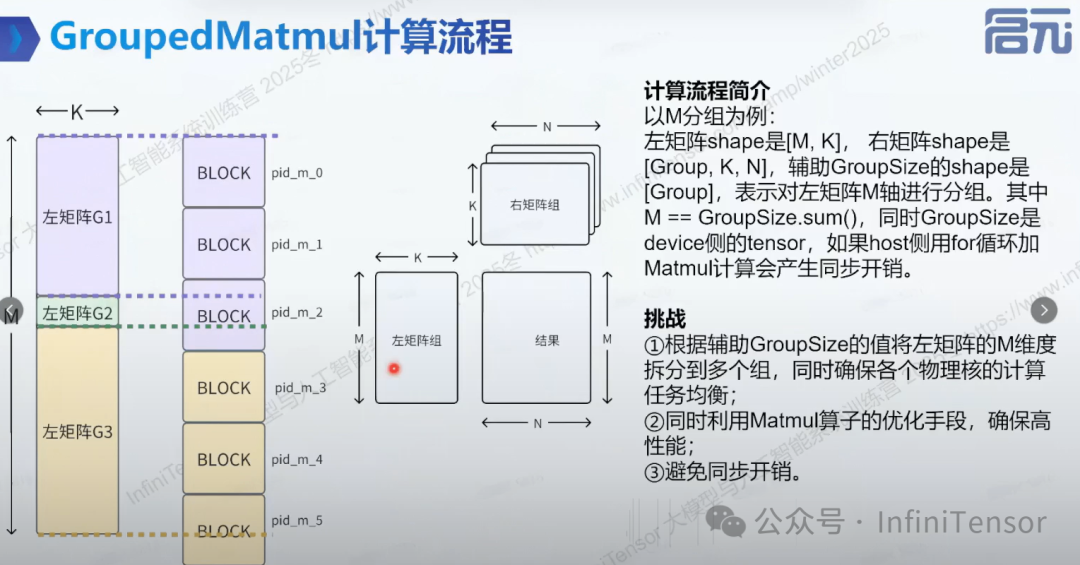
2. 传统实现的问题
传统实现方式存在:
-
• 通过host侧循环处理group
-
• 产生同步开销
-
• 计算核空闲,资源利用率低
3. 高性能实现
(1) 动态确定分组边界
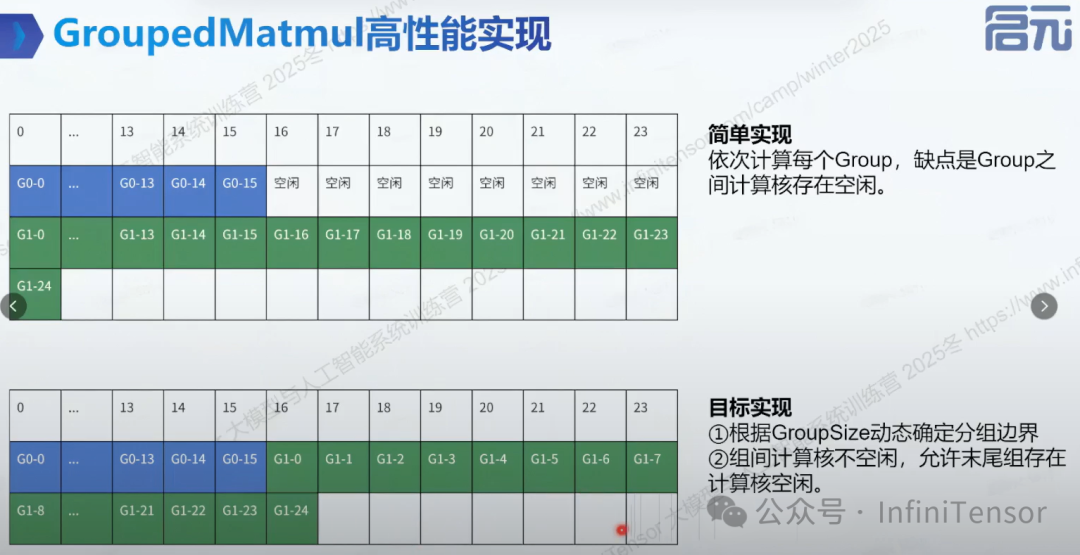

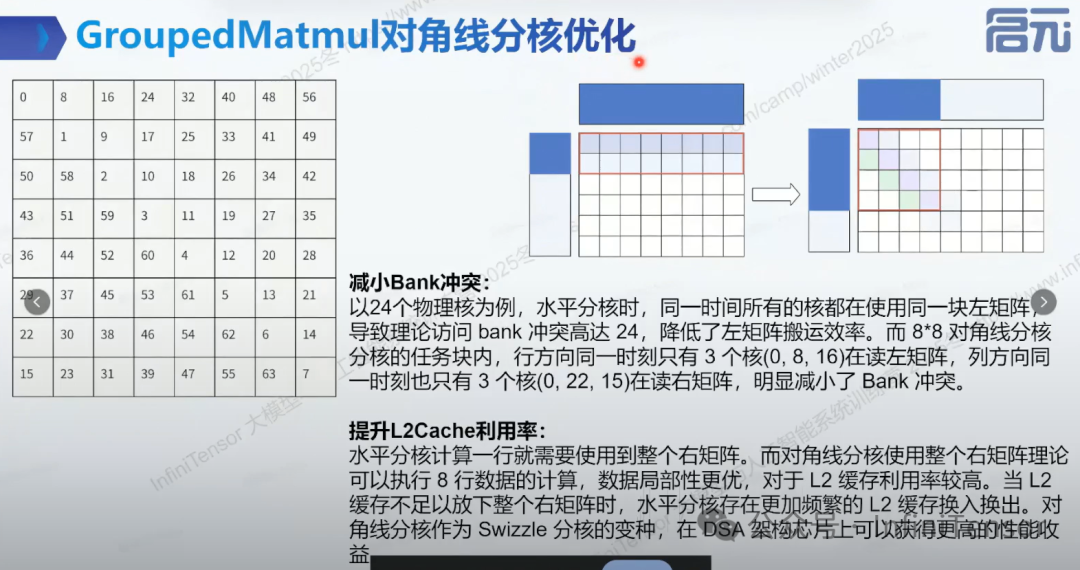
(2) 对角线分核优化
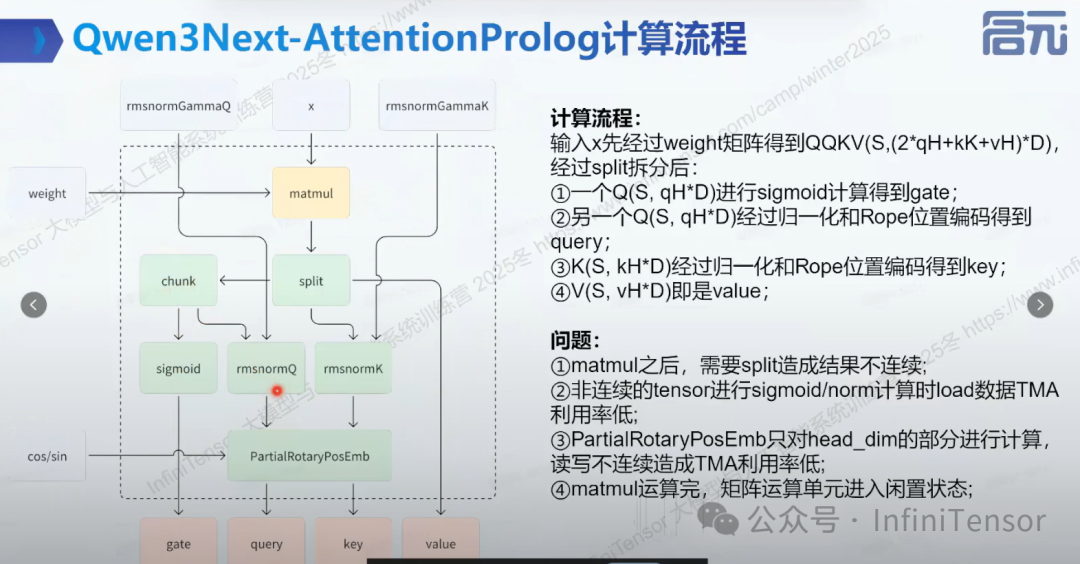
Qwen3 Next-AttentionProlog 的高性能实现
计算流程
- • 输入 x 经过 weight 矩阵得到 QQKV,经过 split 拆分
-
• 数据拆分过程:

融合思路
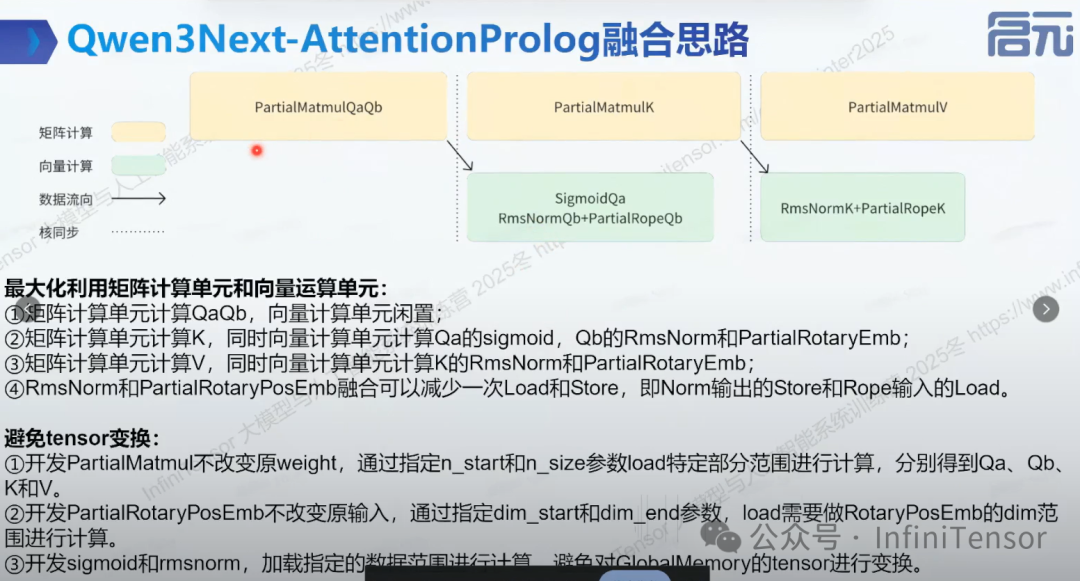
1.融合思路
-
• 最大化利用矩阵计算单元和向量运算单元
- • 避免 tensor 变换
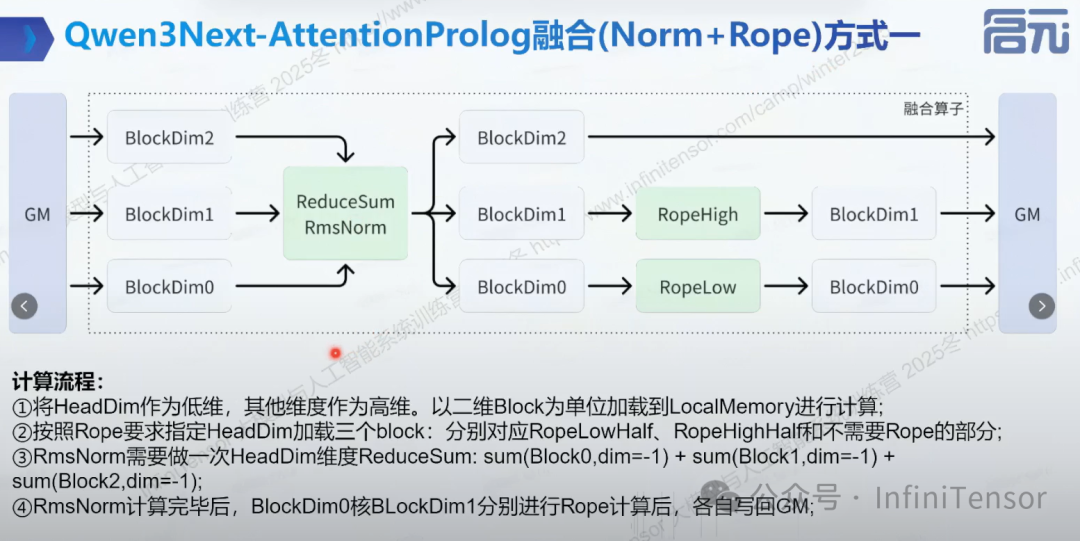
2. 融合(Norm+Rope)方式一
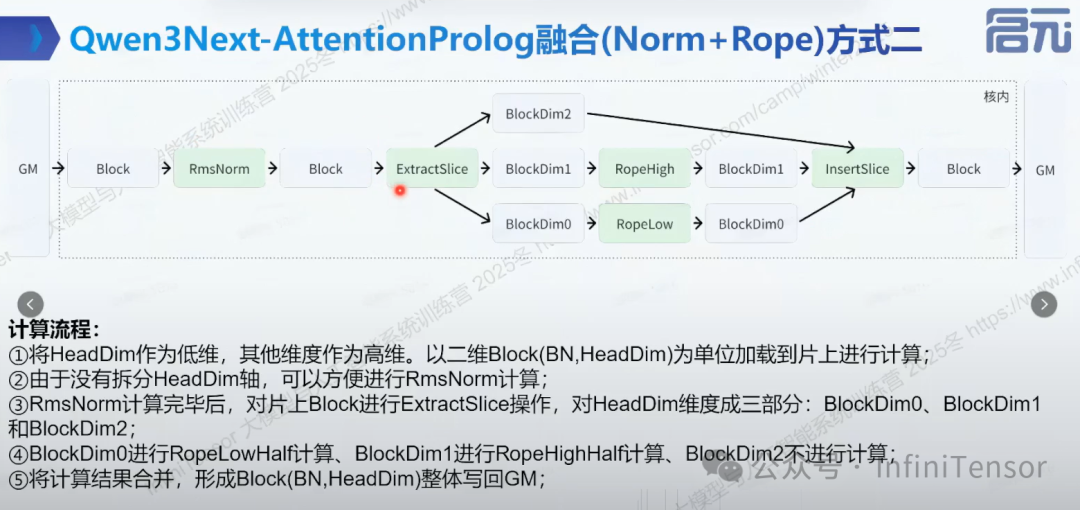
3. 融合(Norm+Rope)方式二
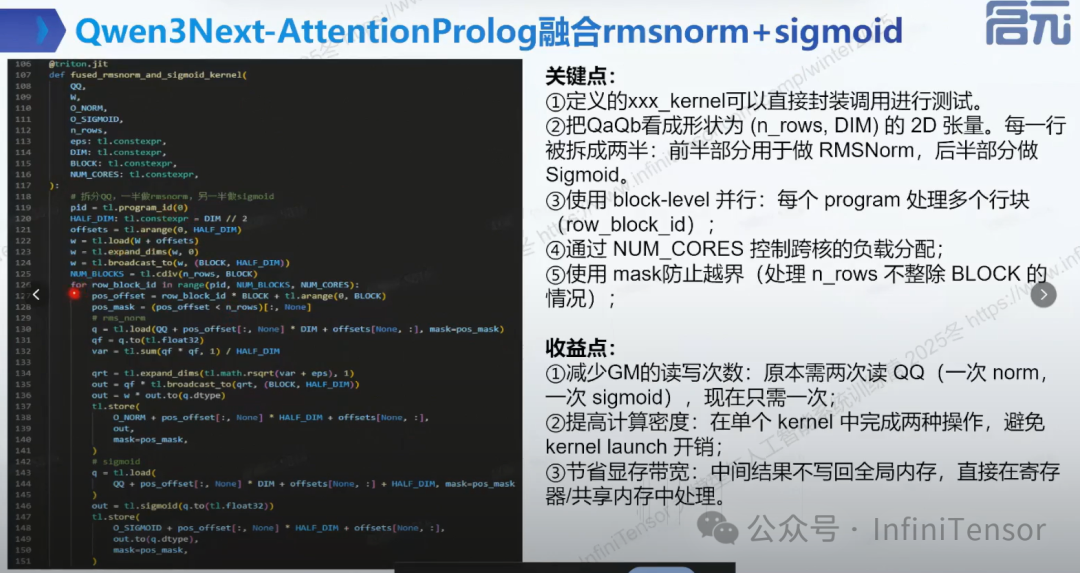
4. 融合 rmsnorm+sigmoid
5. 异步编程

6. PartialROPE
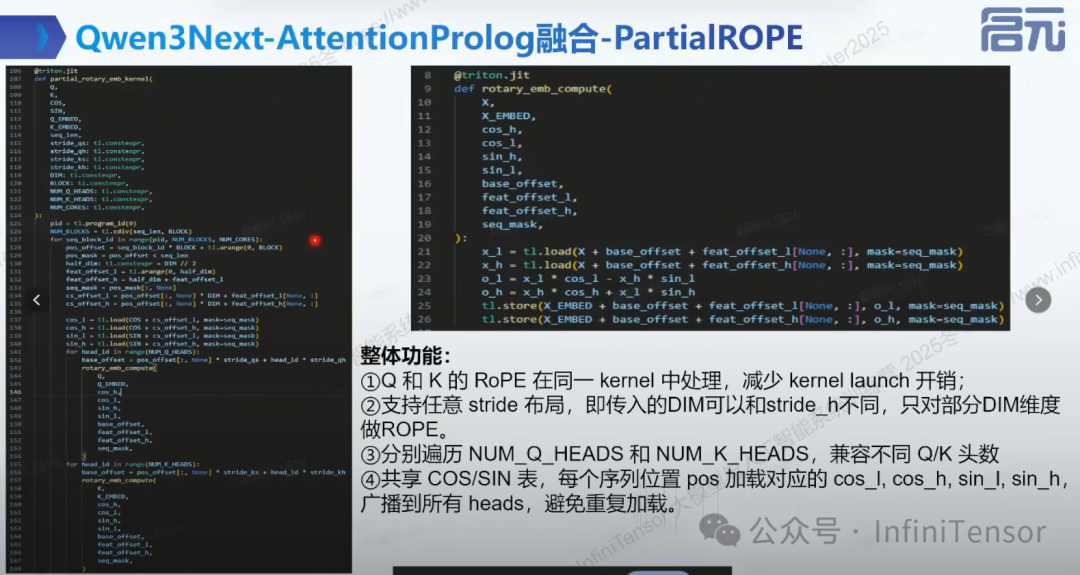
7. 实现效果
-
• 通过上述优化,千问3 Next Attention Prolog 在 8 K输入场景下,相比不融合方案,速度提升约 1.8 倍。
DeepSeek V3 attention prolog的高性能实现
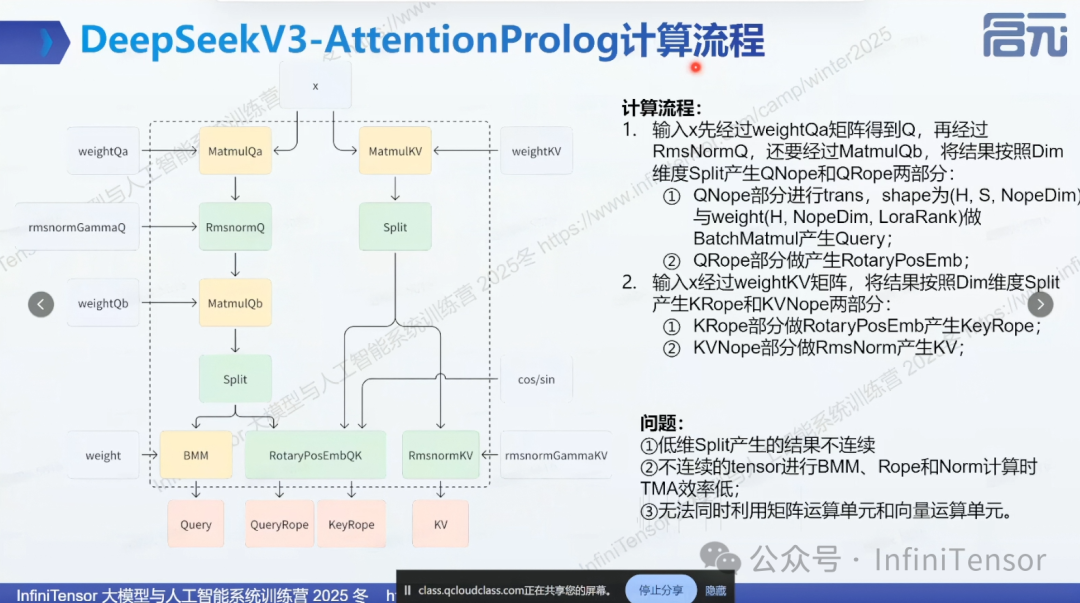
DeepSeek V3 Attention Prolog 计算流程
-
• x 经过 weight 得到q、k、v
-
• 独立运行 RMSNorm
-
• split 后,部分进入 BMM,部分进入 RPE
优化策略
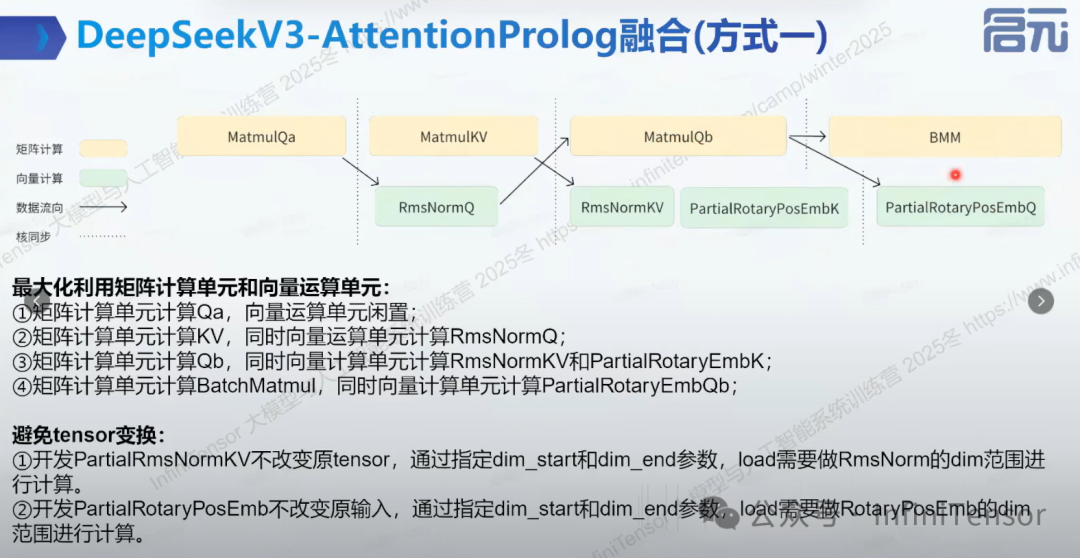
1. 融合方式一
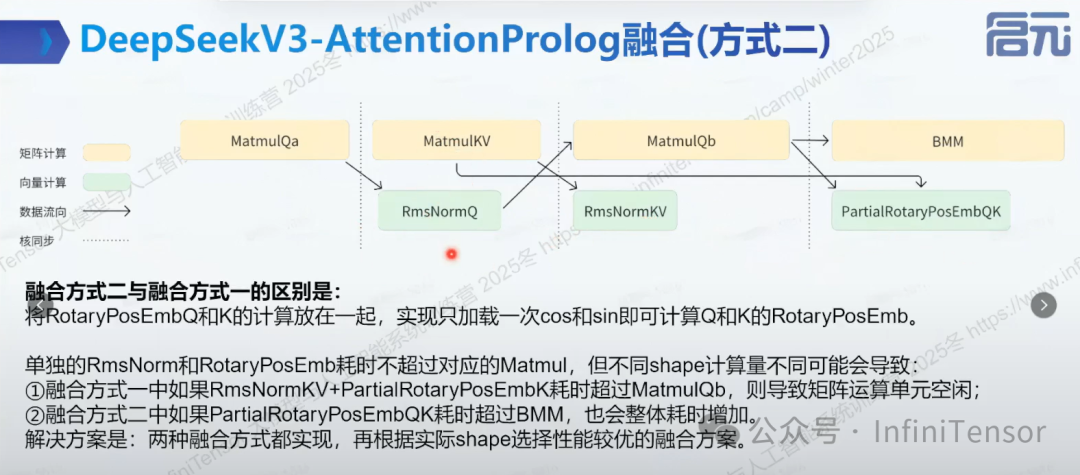
2. 融合方式二
实现效果
DeepSeek V3 的 Attention Prolog 优化后,相比单算子实现,加速比达到170%。
总结
DLCompiler 通过创新的算子开发方法和优化策略,显著提升了国产芯片上的算子性能。DLCompiler 为开发者提供了一套高效、易用的工具链,助力国产芯片在 AI 时代发挥更大价值。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)