【Kimi最新技术报告解读】Attention Residual:用注意力机制重构Transformer残差连接
【Kimi最新技术报告解读】Attention Residual:用注意力机制重构Transformer残差连接

在现代大语言模型(LLM)的架构中,带有 PreNorm 的标准残差连接(Residual Connections)几乎是不可或缺的基石。然而,这一习以为常的基础结构是否存在底层的数学缺陷?
2026年3月16日,Kimi 团队发布了技术报告《Attention Residuals》,直接向这一经典结构提出了挑战。该研究指出,传统的残差连接会导致深层网络出现严重的“幅值膨胀”与“信息稀释”问题。为此,作者提出了一种名为 注意力残差(Attention Residuals, AttnRes) 的新架构,并辅以系统级(Sys-ML)的工程优化方案,使得该架构能够在千亿级模型中高效落地。
这篇报告一经发出,得到了马斯克等硅谷顶尖 AI 人物的点赞背书。前 OpenAI 联创 Andrej Karpathy 说「看来我们还没把“Attention is All You Need”这句话按字面意思理解透。
但比起这些夸奖,技术论文背后的信号或许更值得关注:深度学习最基础的范式,正在发生变化。自2015年resnet提出,至今十年没人动过的地基,现在被撬动了。本文将结合论文原稿与底层数学逻辑,尝试解读该研究的核心动机、算法机制以及工程实现细节。
先放上论文中的核心图片。
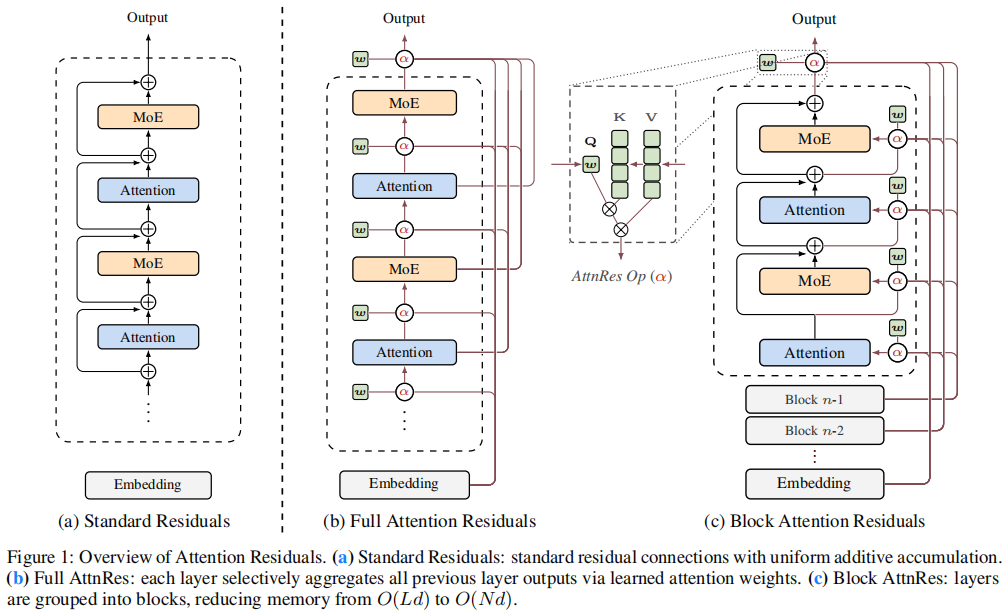
论文中的图1讲清楚了这篇论文的“What”和“How”。它展示了残差连接从**(a) 盲目的线性累加**,升级为**(b) 全局的智能检索**,并最终优化为**© 高效的分块检索的完整技术演进路线。在正式解读报告前,有必要先把这个图说清楚。从 (a) 到 (b) 是算法理论的突破**,从 (b) 到 © 是向工程落地的妥协与优化。
(a) 标准残差连接 (Standard Residuals)。这是目前所有主流大模型(如 Transformer)都在使用的默认残差结构。在 Attention 层或 MoE 层之间,信息是通过一个简单的加号圆圈 (⊕\oplus⊕) 向上单向传递的。这种结构执行的是均匀、无权重的加法累加 (uniform additive accumulation) 。每一层只能被动地接收上一层传来的唯一状态。这种粗暴的累加正是导致深层网络幅值膨胀、早期层信息被严重稀释的“元凶”。
(b) 全注意力残差 (Full Attention Residuals)。将原有的简单加号 (⊕\oplus⊕) 替换为了一个带有 α\alphaα 标记的注意力操作符 (AttnRes Op)。最显著的变化是连线:每一层的注意力节点,都向下拉出了多条长长的连接线,直接越级连接到了它下面所有历史层的输出(甚至直接连到了最底部的 Embedding 层)。图中央的虚线框展示了这个 α\alphaα 操作的具体内部逻辑。它完全借鉴了 Transformer 的注意力机制:当前层会生成一个伪查询向量 (Query, Q),去和所有历史层的输出特征 (Keys, K) 进行点积匹配,算出注意力权重后,再对历史层的特征 (Values, V) 进行加权求和。这意味着每一层不再吃前一层的“大锅饭”,而是通过学习到的注意力权重,选择性地、动态地聚合所有历史层的信息 。
© 块注意力残差 (Block Attention Residuals)。 全注意力残差 (b) 虽好,但让每一层都保存所有历史输出,会造成 O(Ld)O(Ld)O(Ld)(层数 ×\times× 维度)的极高显存和通信灾难 。因此,作者将网络划分为多个块 (Blocks)。注意力机制只在“块与块”之间进行历史检索,从而极大地压缩了需要保存和传输的上下文数量,将显存和通信瓶颈骤降至 O(Nd)O(Nd)O(Nd) 。
一、 传统残差连接的隐藏缺陷:深度的“诅咒”
在深入探讨新架构之前,我们需要先理解标准残差连接在深度增加时暴露出的局限性。
现代大模型普遍使用的 PreNorm 残差公式为:hl=hl−1+fl−1(Norm(hl−1))h_l = h_{l-1} + f_{l-1}(\text{Norm}(h_{l-1}))hl=hl−1+fl−1(Norm(hl−1))。如果将其沿深度方向展开,第 LLL 层的输入 hLh_LhL 实际上是初始词嵌入与前面所有层输出的直接累加:
hL=h1+f1+f2+⋯+fL−1h_L = h_1 + f_1 + f_2 + \dots + f_{L-1}hL=h1+f1+f2+⋯+fL−1
这种无权重的均匀累加会带来两个严重的数学与物理后果:
1. 早期信息的“稀释”与幅值膨胀
随着网络深度的增加,hLh_LhL 向量的绝对幅值(Magnitude)会以 O(L)O(L)O(L) 的速度不断膨胀。
我们可以用**“向水缸中加水”**来做比喻:第1层的输出就像是倒入水缸的第一杯水;而到了第100层,水缸中已经累积了99杯水。此时,第1层那杯水在整体中的比例被严重“稀释”。深层网络为了对最终结果产生影响,其输出值被迫变得越来越大,这不仅容易导致训练不稳定,也限制了网络深度的进一步扩展。
2. 信息的“过度压缩”与回溯困难
在时间序列模型(如早期的RNN)中,历史信息被压缩成单一隐藏状态,导致“长程遗忘”。作者敏锐地指出,标准残差在深度维度上存在同样的对偶问题:第10层能接收到的只有第9层传来的 h9h_9h9。这个 h9h_9h9 就像是一个“混合了各种颜料的画桶”,把前面所有的特征暴力融合在了一起。如果第10层此时只想提取第1层的某种特定特征(比如“提取特定词性”),它已经无法从混合状态中将其单独分离出来。
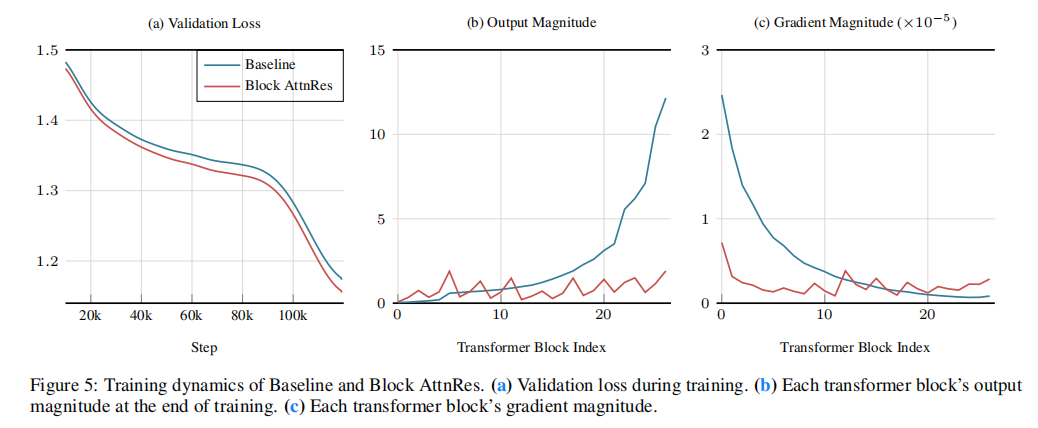
图5(b)中 绿线(Baseline)随深度呈指数级上扬的曲线,直观地印证了“幅值膨胀”与“早期信息被稀释”的数学诅咒。而红线(Block AttnRes)被死死压制在一个极小的周期范围内,证明了新架构对该问题的根治。(c)直观展示了标准残差在浅层产生的巨大梯度(容易导致训练不稳定),以及 AttnRes 如何让梯度在不同层之间分布得更加均匀。
二、核心创新:从“线性累加”到“注意力检索”
既然 Transformer用注意力机制解决了RNN在时间维度上的信息压缩问题,为何不用相同的机制解决残差在深度维度上的压缩问题?这便是 全注意力残差(Full AttnRes) 的核心思想。
该机制放弃了上一层对下一层的单一传递,而是允许每一层通过注意力权重,选择性地、动态地聚合前面所有历史层的输出。在此设计中,有两处极其关键的数学细节:
1. 伪查询向量(Pseudo-Query, wlw_lwl)
在标准的自注意力中,查询向量(Query)是根据当前输入动态计算的。但在 AttnRes 中,第 lll 层的 Query 被设定为一个独立于输入的、静态的可学习参数 wlw_lwl。
固定的 Query 会不会丧失注意力机制的动态表达能力?其实不会完全丧失。可以将 wlw_lwl 比作一个“固定岗位的招聘官”(例如其职责固定为寻找包含局部边缘信息的特征),而前面各层的实际输出(Key / Value)是随着输入数据(如不同的句子)不断变化的“应聘者”。固定招聘官(wlw_lwl)去面试动态的应聘者(kik_iki),其计算出的注意力得分依然是高度依赖当前输入的,从而保留了模型在不同语境下动态路由历史层信息的能力。
2. 键(Key)的 RMSNorm 归一化
在计算注意力得分时,论文强制要求对历史层的输出(Key)进行 RMSNorm 处理:ϕ(ql,ki)=exp(wlT⋅RMSNorm(vi))\phi(q_l, k_i) = \exp(w_l^T \cdot \text{RMSNorm}(v_i))ϕ(ql,ki)=exp(wlT⋅RMSNorm(vi))。
这是一个挽救模型免于崩塌的关键设计。如前所述,深层网络的输出幅值远大于浅层网络。向量点积的数学本质是:长度 ×\times× 长度 ×cos(θ)\times \cos(\theta)×cos(θ)。如果不做归一化,深层网络仅仅凭借庞大的“向量长度”,就能在点积计算中获得极高的绝对数值,从而在 Softmax 后垄断绝大部分的注意力权重。RMSNorm 的作用相当于**“剥夺向量的长度特权”**,将所有层的特征向量强制拉伸或压缩到同一个高维单位球面上。这就迫使注意力机制只能根据向量的语义方向(即 cos(θ)\cos(\theta)cos(θ),特征匹配度)来进行公平的权重分配,真正实现了“按需提取”。
三、工业级工程落地:块注意力与两阶段推理
全注意力残差在理论上十分优雅,但在大规模分布式训练中,要求每一层都保存并读取所有历史输出,会导致显存和通信开销随着层数呈 O(Ld)O(Ld)O(Ld) 级别的爆炸。为了解决这一工程瓶颈,作者提出了 块注意力残差(Block AttnRes) 及其配套的硬件优化策略。
1. 块注意力残差 (Block AttnRes)
该方案采取了“分而治之”的策略:
(1)将总计 LLL 层的网络划分为 NNN 个块(Block),每个块包含若干层。
(2)块内局部累加: 在一个块的内部,层与层之间依然采用普通的加法残差,最终融合成一个浓缩的“块级表示(Block-level representation)”。
(3)块间全局检索: 注意力机制主要在“块与块”之间进行。当前层只需检索之前已经计算完的少数几个“块级表示”,外加当前块内的局部累加值。
这一设计在几乎不损失模型性能的前提下,将显存和通信复杂度从 O(Ld)O(Ld)O(Ld) 大幅压缩至 O(Nd)O(Nd)O(Nd)。论文进一步提出利用交错流水线(Interleaved Pipeline)的跨阶段缓存,使得 GPU 之间仅需传输新生成的“增量块”,彻底掩盖了流水线并行的通信延迟。
2. 两阶段推理策略
在自回归推理(逐字生成)时,如果每一层都要重新去显存中读取历史块,访存带宽(Memory I/O)将成为致命瓶颈。
此时,前文提到的静态参数 wlw_lwl 展现出了其在系统优化上的巨大价值。因为 wlw_lwl 是在推理前就已知的静态权重,模型无需等待上一层算完,即可进行解耦计算:
阶段一(块间并行): GPU 提前把一个块内所有层的 wlw_lwl 拼装成一个大矩阵,只需访问一次显存读取历史块数据,通过一次批量矩阵乘法,瞬间算出该块内所有层对历史块的宏观注意力。
阶段二(块内串行与合并): 对于块内必须串行计算的数据依赖部分,GPU 逐层计算后,利用在线 Softmax(Online Softmax)技术,将第一阶段的宏观结果与第二阶段的微观结果在寄存器层面高效合并。
将动态 Query 改为静态 Query,本质上是算法团队在“极致的数学表达力”与“底层硬件的极致并发效率”之间做出的严谨权衡。
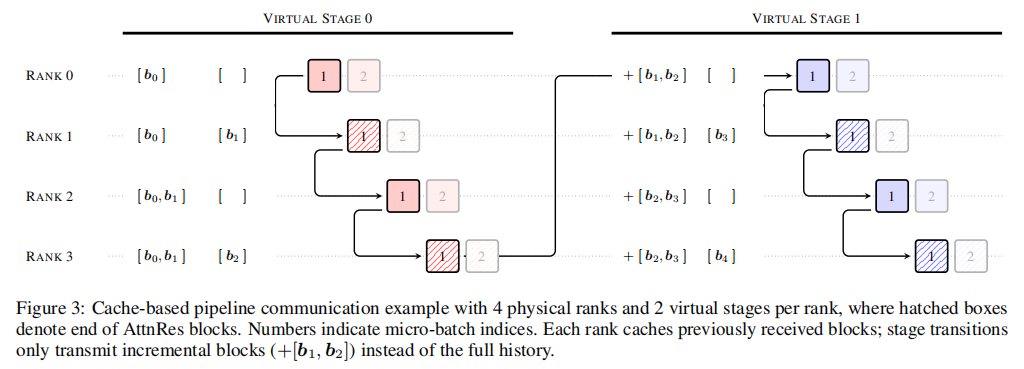
图3展示了作者化解该瓶颈的工程巧思:利用交错流水线(Virtual Stages)的特性,让各个 GPU 节点(Rank)在本地显存中缓存已经接收过的历史块 。在后续的计算交接时,GPU 之间只需传输新生成的“增量块”(如图中的 +[b1, b2])。这种机制将原本随层数爆炸的通信开销大幅缩减,实现了通信与计算时间的完美重叠。
四、实验验证
基于 Kimi Linear 架构(48B总参数)并在1.4T tokens 上进行的预训练实验表明,引入 Block AttnRes 后,深层网络输出的幅值膨胀问题得到了根本性遏制,梯度分布更加均匀。在相同的算力预算下,该架构在多项评测(特别是多步逻辑推理与代码数学任务)中展现出了持续的性能提升。
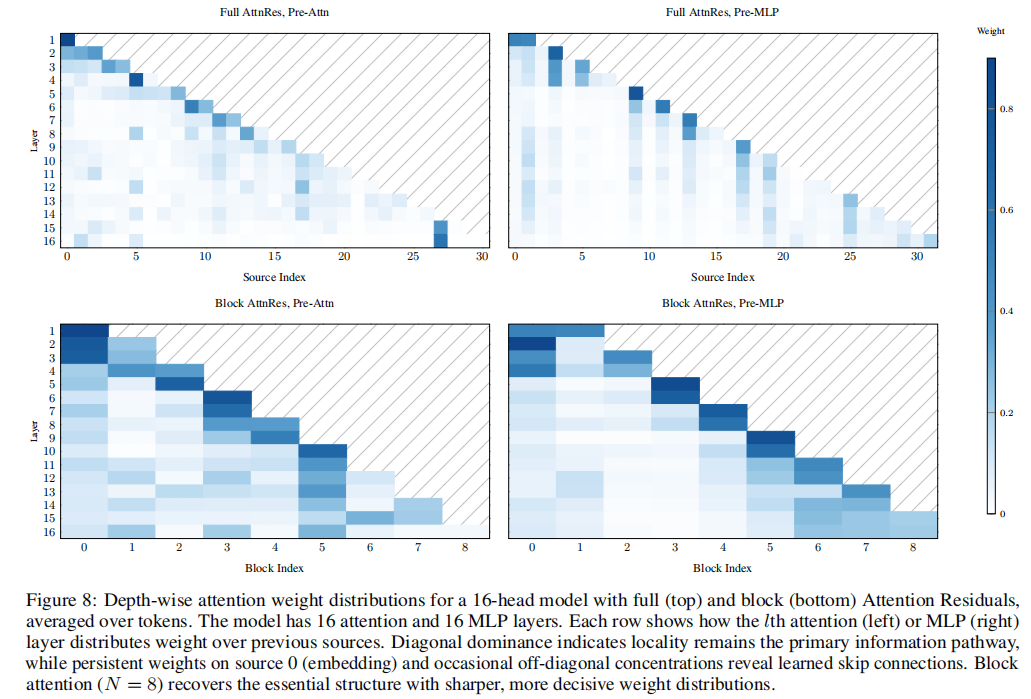
论文图8给出了深度注意力权重的宏观分布热力图。该热力图展示了模型在训练完成后,实际学到的层间特征检索模式 。图中对角线区域的深蓝色表明,当前层依然最关注其紧邻的前一层,保留了优秀的基础局部性 ;而最左侧列(Source 0,代表初始词嵌入)的持续高亮,以及偏离对角线的离散亮斑,则证明模型成功建立起了超越标准残差的“长程跳跃连接(Skip Connections)” 。它能按需越级提取远端历史层的特定特征。对比上下两图可以看出,底部的块注意力(Block AttnRes)在大幅降低显存开销的同时,继承并锐化了全注意力的结构化路由模式 。
五、小结
Attention Residuals的学术价值不仅在于揭示了标准残差结构的理论盲区,更在于它提供了一个经典的 Sys-ML(系统与机器学习协同设计) 范式:通过算法设计上的巧妙妥协(如静态伪查询与分块机制),配合底层硬件特性的极致压榨(两阶段访存与跨阶段缓存),最终将一个看似在千亿模型上计算不可行的学术构想,转化为了实际可部署的工业级方案。

这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)