LangChain开发实战教程(非常详细),从LLM调用到Agent架构精通,收藏这一篇就够了!
一、为什么要用 LangChain?
自从 OpenAI 推出 ChatGPT 之后,大模型能力迅速普及。越来越多的开发者开始将 LLM 接入业务系统,但很快会遇到三个现实问题:
1、模型接口不统一 —— 今天用 OpenAI,明天换国内模型,代码要大改
2、Prompt 难管理 —— 提示词到处拼字符串,无法版本控制
3、业务流程复杂 —— RAG、Agent、多工具调用,全是胶水代码
这时候,LangChain 就登场了。
LangChain 本质是一套 “面向大模型应用开发的工程化框架”,它把模型调用、Prompt 管理、知识检索、流程编排、Agent 调度全部抽象成可组合模块,让你像搭积木一样构建 AI 应用。
二、LangChain 架构全景
LangChain 可以理解为五大核心能力层:
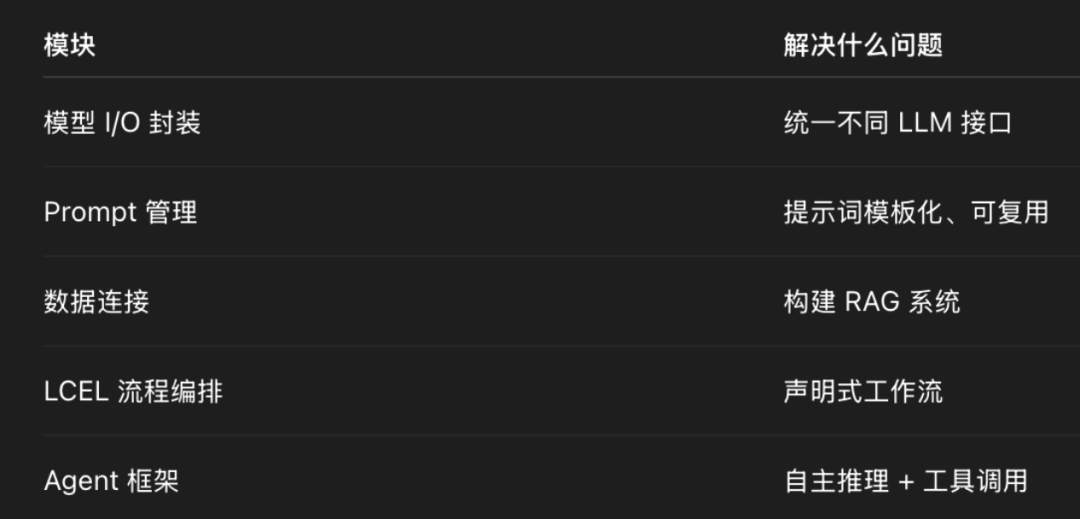
记住一句话:
LangChain = LLM 调用标准化 + RAG 工程化 + Agent 自动化
三、模型封装:统一不同大模型接口
LangChain 最大的优势之一,是统一模型接口。
你可以在不修改业务逻辑的前提下,在不同模型之间切换:
1、OpenAI GPT 系列
2、Anthropic Claude
3、国内文心一言
4、本地模型(Ollama / Llama)
你只需要更换模型初始化方式,其余调用方式一致。
这在企业级项目里极其重要 —— 模型可替换性 = 风险可控性。
四、Prompt 工程:把提示词变成函数
很多开发者刚开始接触 LLM 时,喜欢直接写:
f"给我讲一个关于{topic}的笑话"
问题是:
Prompt 无法版本管理
逻辑和提示词耦合
难以团队协作优化
LangChain 提供 PromptTemplate 和 ChatPromptTemplate:
- 支持变量占位
- 支持多角色(system / user / assistant)
- 支持文件加载
- 支持 Few-shot 示例
最佳实践是:Prompt 与代码彻底解耦,单独维护。
在中大型 AI 项目中,Prompt 甚至应该像 SQL 一样被当作核心资产管理。
五、RAG:给大模型注入私有知识
很多人说“模型不准”,其实问题不在模型,而在没有给模型知识。
RAG(Retrieval Augmented Generation)就是解决方案。
LangChain 的 RAG 流程通常包括:
1、文档加载(PDF / Word / 网页 / 数据库)
2、文本切分
3、向量化
4、存入向量数据库(如 FAISS)
5、检索 + 生成回答
在这里,LangChain 和 LlamaIndex 经常被拿来对比。
简单总结:
- LangChain 强在流程编排 + Agent
- LlamaIndex 强在数据索引能力
很多项目会:
用 LlamaIndex 做数据层
用 LangChain 做应用层
六、LCEL:LangChain 的灵魂
如果说 LangChain 是一套大模型应用框架,
那么 LCEL(LangChain Expression Language) 就是它的核心编排能力。
很多人学 LangChain 只关注模型调用和 RAG,但真正决定工程质量的,是 LCEL。
6.1 为什么需要 LCEL?
假设我们要做一个最简单的流程:
1、接收用户输入
2、构造 Prompt
3、调用 LLM
4、解析输出
传统写法是“按步骤调用函数”。
而 LCEL 的思路是:
用“管道”把各个组件连接起来,描述数据如何流动。
6.2 LCEL 的核心写法
在 LCEL 里:
Prompt 是一个可运行组件
LLM 是一个可运行组件
Parser 也是一个可运行组件
它们都实现了统一接口,所以可以用 | 连接:
chain = prompt | llm | StrOutputParser()
调用时:
chain.invoke({"topic": "程序员"})
这行代码的含义非常清晰:
输入 → Prompt → LLM → 解析输出
比传统“手动 format + invoke + parse”,逻辑更直观、结构更干净。
6.3 LCEL 的优势在哪里?
1.自动支持流式输出
同一条链可以直接流式执行:
for chunk in chain.stream(input):
print(chunk)
无需改内部逻辑。
2.自动支持异步
同步调用:
chain.invoke()
异步调用:
await chain.ainvoke()
流程不需要重写。
3.自动并行执行
在 RAG 场景中,如果有多个 Retriever:
{
"context1": retriever1,
"context2": retriever2,
"question": RunnablePassthrough()
}
| prompt
| llm
retriever1 和 retriever2 会自动并行执行。
不需要写 asyncio,也不需要手动调度。
6.4 一句话理解 LCEL
普通写法是:按顺序写函数调用
LCEL 写法是:声明一条数据流管道
它把“步骤式代码”升级为“数据流架构”。
这也是为什么说:LCEL 是 LangChain 的灵魂。
小结
1、如果你只是调用模型,你只是“在用 API”。
2、如果你掌握 LCEL,你是在“设计 AI 工作流”。
3、建议所有做 RAG 或 Agent 的开发者,都优先用 LCEL 组织流程。
4、它会让你的代码更清晰、更可维护,也更适合生产环境。
七、对话历史管理:控制 Token 成本
真实业务中,多轮对话会带来一个问题:
上下文越来越长 → Token 成本暴涨
LangChain 提供:
- 历史裁剪(保留最近消息)
- 类型过滤(只保留 human)
- 持久化存储(SQL / Redis)
在企业场景里,这一点非常关键:
- 控制成本
- 避免超过模型上下文长度
- 保证系统稳定性
八、Agent:让模型自己思考与行动
如果说 RAG 是“查资料回答问题”,
那么 Agent 是:
给一个目标,让模型自己规划步骤。
最经典的是 ReAct 模式:
思考 → 行动 → 观察 → 再思考 → 输出结果
举个例子:
问:2024年某明星演唱会是星期几?
模型会:
1、搜索日期
2、解析日期
3、调用“星期计算工具”
4、输出答案
整个过程自动完成。
这就是 Agent 的价值 —— 让模型具备“任务执行能力”。
九、LangServe:快速部署 API
当你构建好一个 LCEL 流程后,LangChain 提供 LangServe,可以一行代码生成 REST API。
你不需要写路由、序列化、异常处理逻辑。
直接部署成可调用服务。
在微服务架构下,这非常适合快速构建 AI 中台。
十、文档
功能模块:
https://python.langchain.com/docs/get_started/introduction
API 文档:
https://api.python.langchain.com/en/latest/langchain_api_reference.html
三方组件集成:
https://python.langchain.com/docs/integrations/platforms/
官方应用案例:
https://python.langchain.com/docs/use_cases
调试部署等指导:
https://python.langchain.com/docs/guides/debugging
十一、LangChain 适合什么场景?
企业知识库问答系统
- AI 客服系统
- 智能文档助手
- 代码生成平台
- 多工具自动执行系统
- 内部数据分析 Agent
不适合:
- 只做简单聊天(直接调用 API 更轻量)
- 极端高性能推理系统(需自定义架构)
十二、企业级最佳实践
结合实际项目经验,总结几点:
1.Prompt 必须独立管理
不要写死在代码里。
2.RAG 参数要反复调优
chunk_size、overlap 直接影响效果。
3.尽量使用 LCEL
不要回到命令式“胶水代码”。
4.严格做日志追踪
生产环境一定接入 LangSmith。
5.版本锁定
LangChain 更新快,升级前一定看 breaking change。
十三、总结
LangChain 并不是“又一个 AI 库”。
它是一次:
面向大模型时代的软件工程抽象升级。
它告诉我们三件事:
1、把 Prompt 当函数
2、把流程当管道
3、把模型当可调度执行器
理解这三点,比会写 API 更重要。
如果你准备入门 AI 工程化开发,建议路线:
1、先做一个 RAG 问答系统
2、加入对话历史管理
3、用 LCEL 重构流程
4、最后引入 Agent 能力
当你走完这条路径,你对大模型应用开发的理解会完全不同。
LangChain RAG 示例:
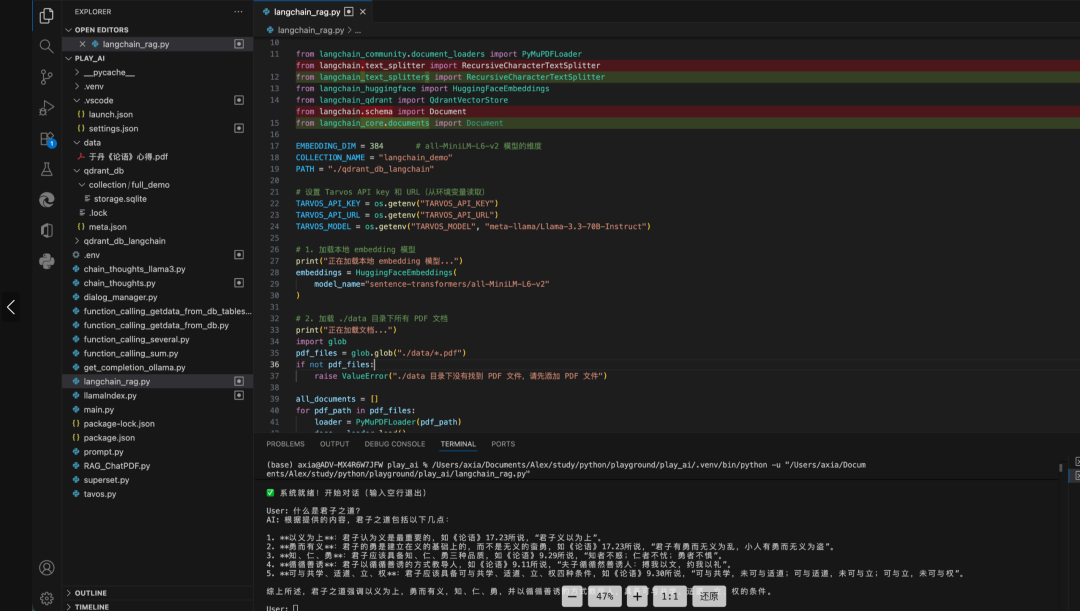
LangChain RAG 示例源码:
from dotenv import load_dotenv
import os
import requests
# Load environment variables from .env file
load_dotenv()
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_qdrant import QdrantVectorStore
from langchain_core.documents import Document
EMBEDDING_DIM = 384 # all-MiniLM-L6-v2 模型的维度
COLLECTION_NAME = "langchain_demo"
PATH = "./qdrant_db_langchain"
# 设置 Tarvos API key 和 URL(从环境变量读取)
TARVOS_API_KEY = os.getenv("TARVOS_API_KEY")
TARVOS_API_URL = os.getenv("TARVOS_API_URL")
TARVOS_MODEL = os.getenv("TARVOS_MODEL", "meta-llama/Llama-3.3-70B-Instruct")
# 1. 加载本地 embedding 模型
print("正在加载本地 embedding 模型...")
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 2. 加载 ./data 目录下所有 PDF 文档
print("正在加载文档...")
import glob
pdf_files = glob.glob("./data/*.pdf")
if not pdf_files:
raise ValueError("./data 目录下没有找到 PDF 文件,请先添加 PDF 文件")
all_documents = []
for pdf_path in pdf_files:
loader = PyMuPDFLoader(pdf_path)
docs = loader.load()
all_documents.extend(docs)
print(f"共加载 {len(all_documents)} 页文档")
# 3. 文档切片(chunk_size=300, chunk_overlap=100,与 llamaIndex.py 一致)
print("正在切片文档...")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=100
)
chunks = text_splitter.split_documents(all_documents)
print(f"共切分为 {len(chunks)} 个块")
# 4. 创建 Qdrant Collection
print("正在创建向量数据库...")
qdrant_client = QdrantClient(path=PATH)
if qdrant_client.collection_exists(collection_name=COLLECTION_NAME):
qdrant_client.delete_collection(collection_name=COLLECTION_NAME)
qdrant_client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE)
)
# 5. 将文档向量存入 Qdrant
print("正在创建索引...")
vector_store = QdrantVectorStore(
client=qdrant_client,
collection_name=COLLECTION_NAME,
embedding=embeddings
)
vector_store.add_documents(chunks)
# 6. 创建检索器
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
# 7. Tarvos API 问答函数(与 llamaIndex.py 完全一致)
def ask_tarvos(question, context):
headers = {
"Content-Type": "application/json",
"Authorization": TARVOS_API_KEY,
}
body = {
"model": TARVOS_MODEL,
"messages": [
{"role": "system", "content": "你是一个专业的AI助手,请根据提供的检索内容回答用户问题。如果检索内容与问题无关,请说明无法回答。"},
{"role": "user", "content": f"参考内容:\n{context}\n\n问题:{question}"}
]
}
try:
resp = requests.post(TARVOS_API_URL, json=body, headers=headers, timeout=60)
return resp.json()["choices"][0]["message"]["content"]
except Exception as e:
return f"调用 Tarvos API 失败: {str(e)}"
# 8. 主对话循环
print("\n✅ 系统就绪!开始对话(输入空行退出)\n")
while True:
question = input("User: ")
if question.strip() == "":
break
# 检索 top-k 文档
docs = retriever.invoke(question)
context = "\n\n".join([doc.page_content for doc in docs])
# 调用 Tarvos API 生成答案
answer = ask_tarvos(question, context)
print(f"AI: {answer}\n")
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐


 10
10 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)