Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing
1.introduction
rl依赖奖励模型来提供优化信号,但关键瓶颈是the unreliability of the critics。多模态大语言模型在作为zero-shot奖励模型用于精细图像编辑和生成任务时会遇到困难,这些模型固有的存在严重的幻觉,物体忽视和缺乏精确的空间推理的问题,导致不合理和噪杂的奖励得分。

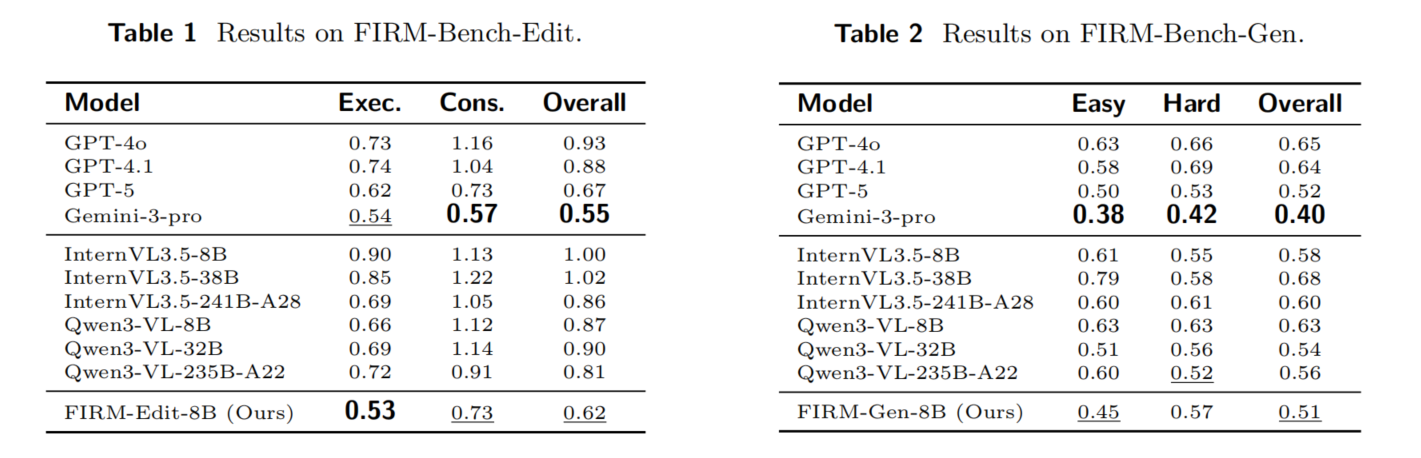
FIRM(Faithful image reward modeling)旨在训练稳健的、针对特定任务的奖励模型,作为图像编辑和生成的可靠评估者。FIRM引入了量身定制的数据管道,以合成高质量的奖励数据。对于图像编辑,我们观察到,虽然mllm在直接判断编辑后的图像是否完美遵循指令并保持一致性方面存在困难,但它们在识别两幅图之间的差异方面表现出色。我们利用一个mllm对源图像和编辑图像之间的精确视觉差异进行描述,然后将这一文本差异反馈给一个mllm,以可靠的推导出执行和一致性的最终得分。构建了高质量的奖励数据集:FIRM-Edit-370k和FIRM-Gen-293K,以及相应的模型,FIRM-Edit-8B和FIRM-Gen-8B,这些模型是从Qwen3-VL-8B-Instruct模型初始化的,还构建了一个人类标准的基准FIRM-Bench。

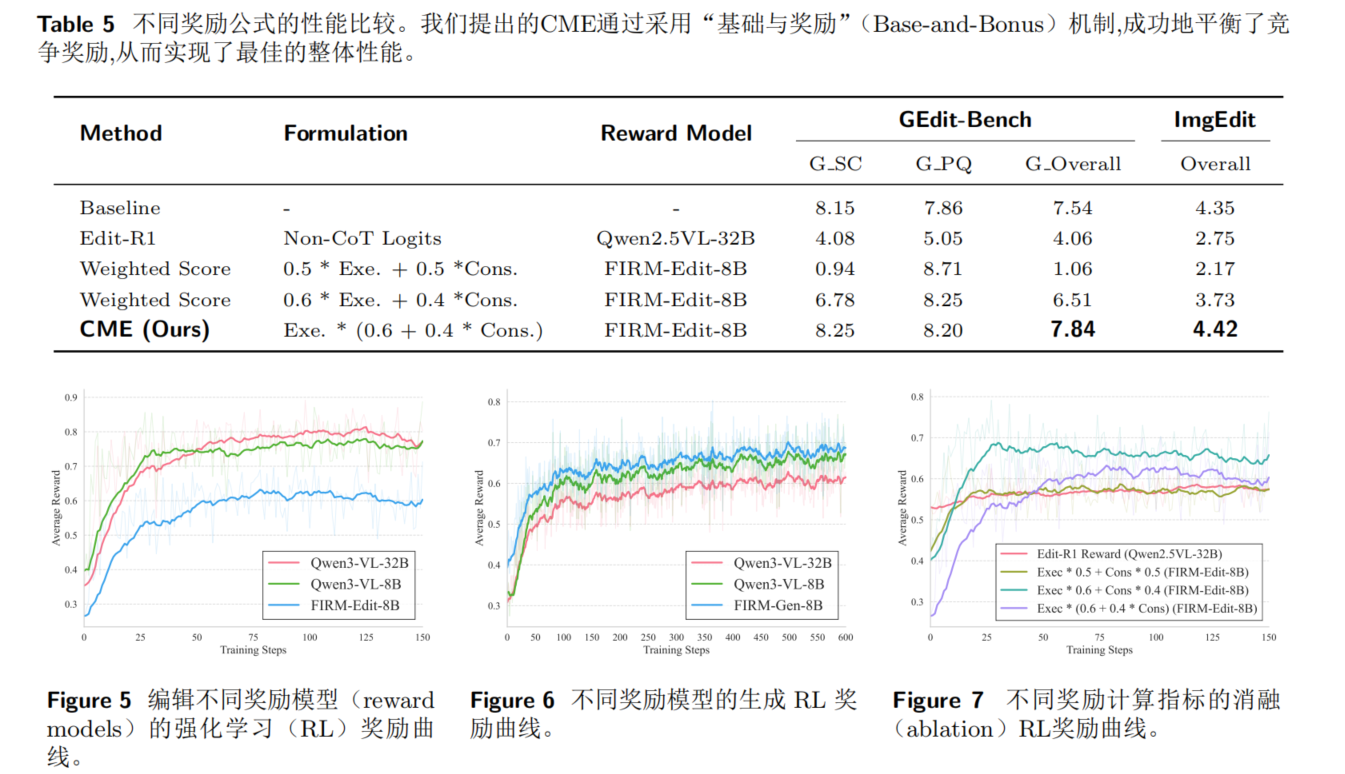
在这些值得信赖的评论者基础上,进一步执行rl以优化生成模型,rl中的挑战是,简单的最大化多个通常相互竞争的奖励往往会导致优化崩溃或严重的奖励黑客行为,为了探索这个问题,我们广泛探索了基础与奖励 奖励加权策略,并确定了一种协同奖励结构,称之为一致性调制执行。
2.Related work

3.Method
3.1 FIRM-edit pipeline
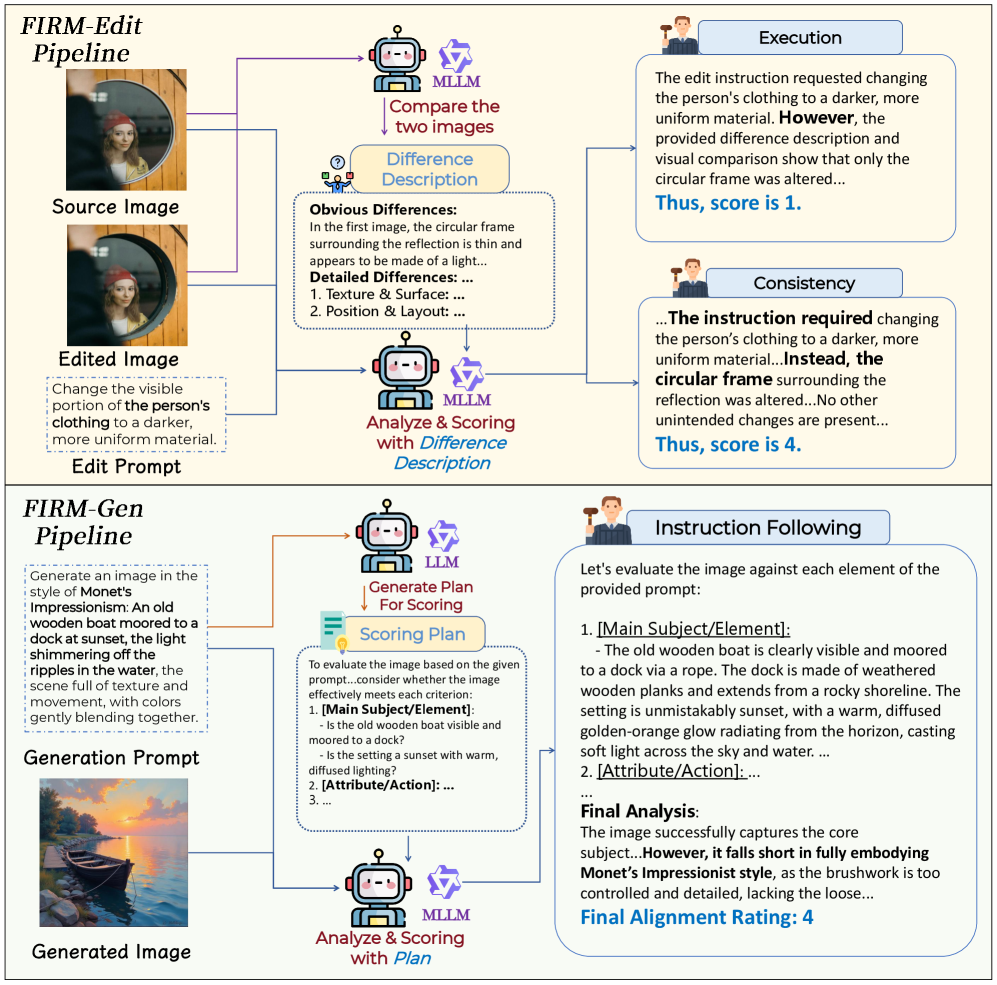



3.3 Construction of FIRM-Bench


3.4 Rewards Design in RL


4. Experiment Results
4.1 Experiment Settings


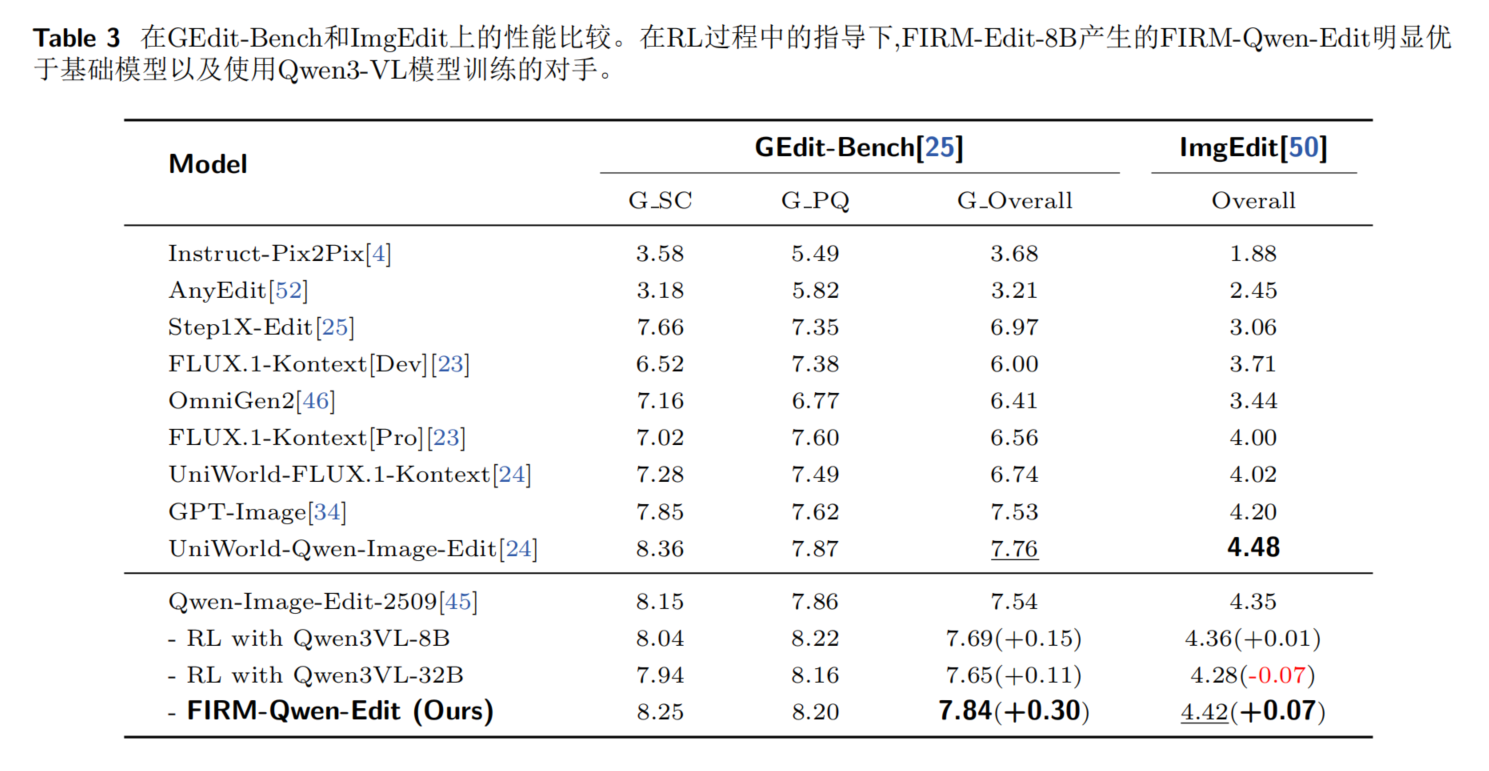
4.3 Image editing performance via RL process

4.5 Ablation on Reward Formulation



这里是“一人公司”的成长家园。我们提供从产品曝光、技术变现到法律财税的全栈内容,并连接云服务、办公空间等稀缺资源,助你专注创造,无忧运营。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)